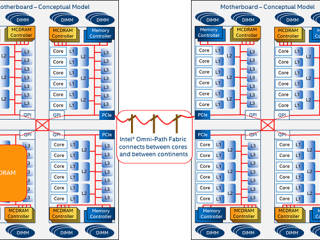
 HPC
HPC NUMA ハードウェアによるパフォーマンスの向上
この記事は、インテル® デベロッパー・ゾーンに公開されている「Performance Improvement Opportunities with NUMA Hardware」( の日本語参考訳です。この記事の PDF 版はこちらからご利用...
 HPC
HPC  インテル® Advisor インテル® Advisor
インテル® Advisor インテル® Advisor  その他
その他 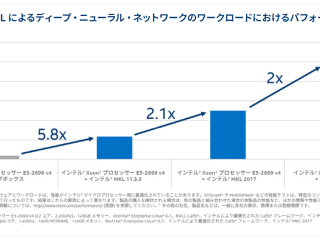 インテル® oneMKL
インテル® oneMKL  インテル® oneMKL
インテル® oneMKL  インテル® oneMKL
インテル® oneMKL  インテル® Advisor
インテル® Advisor  HPC
HPC  HPC
HPC  HPC
HPC  ビッグデータ
ビッグデータ  インテル® Parallel Studio XE
インテル® Parallel Studio XE  インテル® GPA
インテル® GPA  インテル® VTune™ プロファイラー
インテル® VTune™ プロファイラー 