
この記事は、インテルの The Parallel Universe Magazine 27 号に収録されている、マシンラーニング向けの小規模行列に対応する新機能に関する章を抜粋翻訳したものです。
汎用行列-行列乗算 (GEMM) は、多くの科学、工学、マシンラーニング・アプリケーションで利用される基本操作であり、BLAS (Basic Linear Algebra Subprograms) ドメインの重要なルーチンの 1 つです。GEMM には 4 つの精度 (実数単精度、実数倍精度、複素数単精度、複素数倍精度) があります。この記事では、SGEMM (実数単精度) について取り上げます。
SGEMM の Fortran API は次のとおりです。
SGEMM(transa, transb, m, n, k, alpha, A, lda, B, ldb, beta, C, ldc)
この API は次の計算を実行します。
C := alpha * op(A) * op(B) + beta * op(C)
(op(X) は X または XT、transx パラメーターの値に依存)
配列 A と B は入力で、C は入力および出力です。配列 A は m x k 行列、配列 B は k x n 行列、配列 C は m x n 行列をそれぞれ含みます。リーディング・ディメンジョン (lda、ldb、ldc) は、GEMM が大きな行列の一部を処理できるように、ある列から次の列へのストライドを決定します。リーディング・ディメンジョンは、後続列をキャッシュラインにアライメントしたり、8 ウェイ 1 次キャッシュの同じセットにマップすると、パフォーマンスにも影響します。
インテル® マス・カーネル・ライブラリー (インテル® MKL) は、ハイパフォーマンスな GEMM 実装を提供します。行列-行列乗算を最適化する一般的なアプローチは、オリジナルの入力行列のブロックを内部データ形式 (パックド形式など) に変換して、手書きのアセンブリー・カーネルで変換されたブロックを乗算した後、出力行列を更新します。1 ブロックサイズはキャッシュとレジスターの使用率が最大になるように選択されます。パックする理由はさまざまです。
- A および B から多くのデータをキャッシュに格納できる (ブロックを大きくするとより多くのデータを再利用できる)。
- 連続し、アライメントされた、予測可能なアクセス (キャッシュおよびデータ・トランスレーション・ルックアサイド・バッファー (DTLB) のミスを最小限に抑えることができる)。
- ループのオーバーヘッドの軽減。
ハイパフォーマンス・コンピューティングの従来のサイズでは、このパックベースのアプローチは適切に動作します。一般に、m および n は比較的大きく、k は中程度 (外積) または同様に比較的大きい (正方) ため、入力行列のパックで費やされる時間は計算カーネルで費やされる時間に比べるとわずかです。しかし、一部のマシンラーニング・アプリケーションで一般的な、m または n のサイズが比較的小さい場合は、パックのオーバーヘッドが大きく影響します。その結果、明示的なパックに依存しない GEMM 実装のほうが、従来のパックベースの GEMM 実装よりもパフォーマンスが高くなることがあります。インテル® MKL 11.3 Update 3 には、インテル® アドバンスト・ベクトル・エクステンション 2 (インテル® AVX2)、インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512)、第 2 世代インテル® Xeon Phi™ プロセッサー (http://www.intel.co.jp/content/www/jp/ja/processors/xeon/xeon-phi-detail.html) 向けに、これらのいくつかのサイズを最適化した {S,D}GEMM カーネルが含まれています。以降のインテル® MKL バージョンでも、これらのカーネルは引き続き改良されています。
これらの新しいカーネルが有効な例を示すため、図 1 では、マシンラーニングで利用されるサイズで、インテル® MKL 2017 Update 1 とインテル® MKL 11.3 Update 2 の SGEMM のパフォーマンスを比較しています。ここで、m と k はそれぞれ 1000 と 256 に固定されていますが、n は可変です。パフォーマンスは GFLOPS (1 秒間に 10 億回の浮動小数点演算を実行) で表されるため、数値が高いほうが優れています。
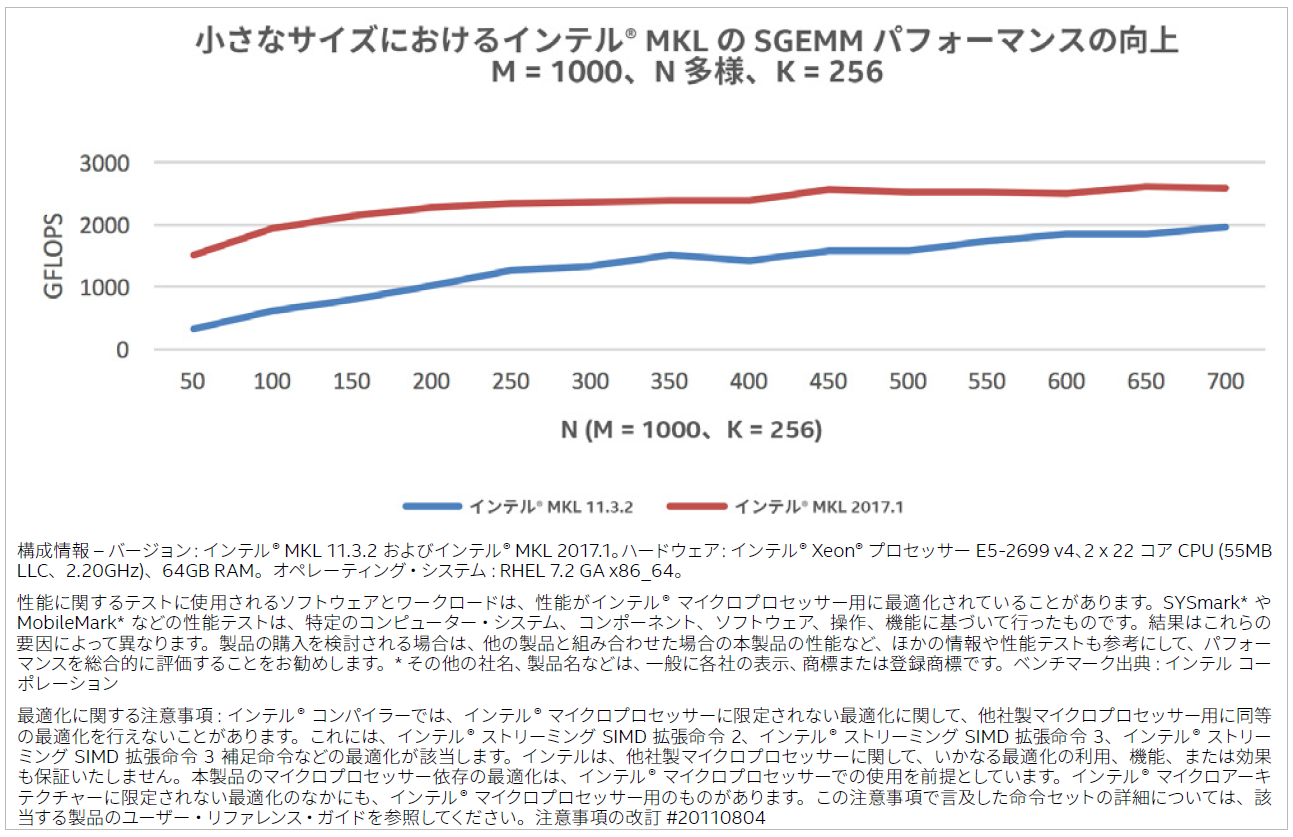
図 1. 小さなサイズにおけるインテル® MKL の SGEMM パフォーマンスの向上
SGEMM 呼び出しの情報 (プロセッサーの種類とスレッド数、問題サイズとリーディング・ディメンジョン、転置パラメーターを含む) に基づいて、インテル® MKL は従来のカーネルと新しいパックフリー・カーネルのどちらを使用するか決定します。インテル® MKL のSGEMM パフォーマンスを利用するディープラーニング・フレームワークは、フレームワークの修正を行うことなく、これらの最適化の恩恵を受けることができます。
例えば、反復性ニューラル・ネットワークのように入力行列 (A または B) が複数の行列乗算で再利用される場合、別の方法でパックのオーバーヘッドを最小限に抑えます。この方法では、再利用される行列を 1 回パックし、複数の SGEMM 計算でパックドバージョンを使用します。インテル® MKL 2017 では、複数の行列乗算でパックのオーバーヘッドを相殺できる、{S,D}GEMM のパックド API が追加されました。単精度の場合、新しいパックド API は次の 4 つです。
dest = sgemm_alloc (identifier, m, n, k)
sgemm_pack (identifier, trans, m, n, k, alpha, src, ld, dest)
sgemm_compute (transa, transb, m, n, k, A, lda, B, ldb, beta, C, ldc)
sgemm_free (dest)
パラメーターは SGEMM とほぼ同じで、パックする行列 (A または B) を示すパラメーター identifier が追加されています。sgemm_compute の transa および transb パラメーターは、通常どおり、“T” (転置する) または “N” (転置しない) に設定します。値 P は、対応する行列が内部パックド形式であることを示します。パックド API は、入力行列が複数回使用される場合に恩恵が得られます。そのため、sgemm_alloc と sgemm_pack をそれぞれ呼び出して、メモリーの割り当てと行列のパックを行い内部パックド形式にした後、sgemm_compute を複数回呼び出して、パックド行列を入力行列の 1 つとして渡します。最後に、sgemm_free を呼び出してメモリーを解放します。(詳細は、「インテル® MKL デベロッパー・リファレンス」を参照してください。)
