 インテル® oneMKL
インテル® oneMKL SYCL とインテル® oneMKL による定量金融の高速化
この記事は、The Parallel Universe Magazine 58 号に掲載されている「Accelerate Quantitative Finance with SYCL* and oneMKL」の日本語参考訳です。原文は更新さ...
 インテル® oneMKL
インテル® oneMKL  インテル® oneMKL
インテル® oneMKL  インテル® oneAPI
インテル® oneAPI  インテル® oneMKL
インテル® oneMKL  インテル® oneMKL
インテル® oneMKL  インテル® oneMKL
インテル® oneMKL  インテル® oneMKL
インテル® oneMKL  インテル® IPP
インテル® IPP 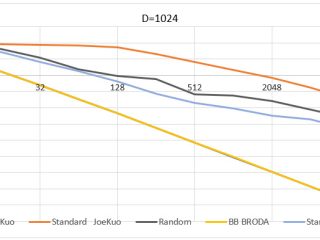 インテル® oneMKL
インテル® oneMKL  HPC インテル® oneAPI AI インテル® oneAPI
HPC インテル® oneAPI AI インテル® oneAPI  インテル® oneMKL インテル® IPP
インテル® oneMKL インテル® IPP 