
この記事は、インテル® デベロッパー・ゾーンに公開されている「Breaking Cross-Architecture Barriers with oneAPI: Libraries for Easy Heterogeneous Compute」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
この記事の PDF 版はこちらからご利用になれます。
原文公開日: 2022年10月7日
新しいハードウェア・アクセラレーターが次々と登場していることは周知のとおりです。開発者はさまざまな新しいハードウェア環境のイノベーションを活用したいと考えており、またそうする必然があります。
ソフトウェア実行フローは、より多様なアーキテクチャーを採用し、タスクはこれらのアーキテクチャー間でフォーク、スポーン、マージされます。
最も簡単で一般的なシナリオは、行列乗算中心のワークロードを並列化し、専用 GPU にオフロードすることです。しかし、すでにかなりの数のワークロードが、複数の多様な計算ノードを同時に利用しています。2021年、Evans Data Corporation の報告1 では、開発者の 40% がすでに、所定の機能を実行するため 2 種類以上のプロセッサー、プロセッサー・コア、またはコプロセッサーを使用するヘテロジニアス・システムをターゲットにしていることが判明しています。
最近まで、ほとんどの開発者は特定のアーキテクチャーに縛られていたため、ターゲットとするアーキテクチャーごとにアプリケーションをコーディングし直し、異なるライブラリーを使用する必要がありました。同じ機能を異なるアーキテクチャーで実現するために必要なコードの手直しの規模により、パフォーマンスが犠牲になることもしばしばでした。
これらを克服するのが、オープンで標準ベースの、マルチアーキテクチャー、マルチベンダーのプログラミング・モデルである oneAPI (英語) と、アーキテクチャーの違いを問わず一貫した C++/SYCL* 抽象レイヤーとパフォーマンス・ライブラリー API を使用するように設計された、補完的なインテル® oneAPI ツールキットです。
oneAPI を使用すると、ソフトウェア開発のパラダイムが変化し、特定のワークロードに対して複数の実行環境をターゲットとし、維持することが容易になります。開発者は、CPU、GPU、FPGA のハードウェア・アクセラレーションを活用しながら、異なるアーキテクチャー間でコードを再利用できます。
クロスプラットフォーム・アプリケーションの開発期間とパフォーマンスの両方を加速するため、インテルは、SYCL* と oneAPI のクロスプラットフォーム、標準ベースの技術を統合して、パフォーマンス・ライブラリーの強化と拡張を進めています。
インテル® oneAPI DPC++/C++ コンパイラー (C++、SYCL*、OpenMP* を実装したクロスプラットフォーム・コンパイラー) と豊富なパフォーマンス・ライブラリー群からなる LLVM プロジェクトを中心に、インテル® oneAPI 製品およびその基盤となる oneAPI オープン業界仕様は、開発コミュニティーに 3 つの大きな利点を提供します。
- 独自の言語、ツール、アーキテクチャーの縛りからの解放
- 各プラットフォームのハードウェアの価値を最大限に引き出す
- ハイパフォーマンスのコードを迅速かつ正確に開発
Microsoft* Visual Studio*、Microsoft* VS Code、Eclipse* などの一般的な統合開発環境に完全に統合して、これらすべてを実現できます。
図 1: インテル® oneAPI DPC++/C++ コンパイラーの Microsoft* Visual Studio* 2022 統合
ライブラリーのクロスアーキテクチャー化の必要性
HPC、IoT、AI に目を向けてみましょう。
ヘテロジニアス環境では、これらのユースケースをターゲットとするアクセラレーターが増加し、その課題も深刻になっています。開発者は、この多様化するハードウェアを活用する能力を必要としています。不明なのは、多様な環境間でコードをサポートしない場合の影響です。移植性がなければ、最高のコードでさえも取り残されてしまう可能性があります。単一のアーキテクチャーに縛られたコードは、将来のハードウェアの進歩に対応できず、その結果、より移植性の高い代替品に遅れをとることでしょう。
クロスプラットフォーム開発の真の障害は、アーキテクチャーの違いを抽象化し、開発者が多様なアーキテクチャー間でコードを再利用できる統一されたライブラリーのセットがないことです。適切なライブラリーのセットがあれば、「今のコードはこれで動いている」と諦めるのではなく、パフォーマンス、価格、可用性、その他の要件に応じてプラットフォームを選択できます。
oneAPI のパフォーマンス・ライブラリー群は、この選択を可能にします。これらのライブラリーは、C++ や SYCL* を単独で使用した場合のパフォーマンスを維持または上回りながら、市場投入までの期間を短縮する API ベースのクロスアーキテクチャー・プログラミングを提供します。
インテル® oneAPI DPC++ ライブラリー (インテル® oneDPL)
インテル® oneDPL (英語) は、ソフトウェア開発におけるこの新しい、共通の、API ベースのアプローチの基礎となるものです。インテル® oneAPI DPC++ コンパイラーを補完し、CPU、GPU、FPGA において生産性とパフォーマンスを最大化するため、以下のような使い慣れた標準化に基づく生産性の高い API を提供します。
- C++ 標準テンプレート・ライブラリー (STL) ― SYCL* カーネルで検証済み
- Parallel STL (PSTL) アルゴリズム ― SYCL* デバイス・アーキテクチャーで実行する実装ポリシー
- Boost.Compute
- SYCL*
特定のターゲット・アーキテクチャーを選択するには、SYCL* キュー sycl::queue への並列オフロードを目的としたタスクに、デバイスセレクターを渡すだけです。
直接使用できるさまざまな事前定義済みデバイスセレクターがあります。
|
default_selector |
実装定義のヒューリスティックに応じてデバイスを選択し、デバイスが見つからない場合はホストを選択します。 |
|
gpu_selector |
GPU を選択します。 |
|
accelerator_selector |
アクセラレーターを選択します。 |
|
cpu_selector |
CPU デバイスを選択します。 |
|
host_selector |
ホストデバイスを選択します。 |
表 1: 事前定義済み SYCL* デバイスセレクターのリスト
(デバイスセレクター演算子により、これらから新しいデバイスを派生させることができます。詳細は、oneAPI (英語) と SYCL* 仕様 [英語 | 日本語] を確認してください。)
デバイスセレクターは、以下に示すように簡単に利用できます。
// 標準の SYCL* ヘッダー
#include <CL/sycl.hpp>
int main() {
sycl::device d;
// 利用可能な GPU をチェックする例外処理
try {
d = sycl::device(sycl::gpu_selector());
} catch (sycl::exception const &e) {
std::cout << "Cannot select a GPU\n" << e.what() << "\n";
std::cout << "Using a CPU device\n";
d = sycl::device(sycl::cpu_selector());
}
std::cout << "Using " << d.get_info<sycl::info::device::name>();
}
コードの再設計を行わずにこのアプローチを利用し、今後のソフトウェア・アーキテクチャーの変更に対応するエンジニアリングの投資を将来にわたって保証する最善の方法は、最新のテクノロジーの進歩を採用してきた実績のある、ハイパフォーマンスなライブラリーでワークロード・ソフトウェア・スタックを構築することです。
インテルが膨大な API ライブラリーを公開し、その多くをクロスプラットフォーム oneAPI 仕様に提供していることは重要です。これにより、インテル以外のプロセッサー・アーキテクチャー向けの oneAPI ライブラリーの開発も可能になりました。特に、oneAPI レベルゼロ (英語) は、サードパーティー・デバイス・ベンダーやオープンな開発者コミュニティー向けに、基礎となるプログラミング・モデルをオープンにしています。
インテル® oneAPI スレッディング・ビルディング・ブロック (インテル® oneTBB)
インテル® oneTBB は、インテル® oneDPL と同様に、最新の Parallel STL (英語) を組み込んだ C++ 標準準拠のクラスをベースに、並列実行ポリシーをサポートした C++ 標準ライブラリーのアルゴリズム実装です。
そのため、oneAPI エコシステムの一部としてインテル® oneDPL と共存し、複雑なアプリケーションの並列化を簡素化する柔軟なパフォーマンス・ライブラリーでその機能を拡張しています。インテル® oneTBB は、コアやアーキテクチャーをまたいだ並列コード実行フローの最適化を簡略化できるため、産業界や研究機関において、数値気象予測、海洋学、天体物理学、遺伝子工学、地震探査、自動エネルギー資源探査、社会経済学などの計算量の多い分野で広く利用されています。
インテル® oneTBB では、プログラムを機能ブロックに分割し、それぞれにスレッドを割り当てるのではなく、データ並列プログラミングを重視し、複数のスレッドがコレクションの異なる部分を処理します。そのため、プロセッサーの数が増えても、コレクションをより小さく分割することで、プロセッサーやアクセラレーターの数が大きくなるほど、プログラムのパフォーマンスは向上します。
この設計原理により、ライブラリーはほかのスレッドパッケージとシームレスな互換性があり、oneAPI やレガシーコードと簡単に統合できます。
インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL)
インテル® oneMKL は、2015年以降、業界で最も広く使用されている数学ライブラリーであるインテル® マス・カーネル・ライブラリー (インテル® MKL) の後継です1。線形代数、高速フーリエ変換、ベクトル乱数生成、統計、ベクトル数学、複素幾何学など、数学、科学、データ解析で使用される機能を幅広くカバーしています (図 2)。
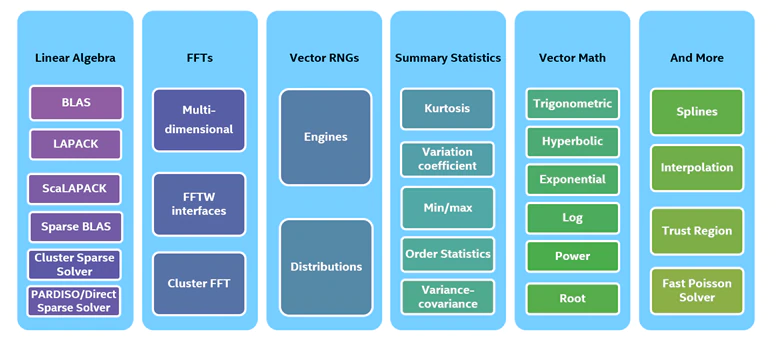
図 2: インテル® oneMKL の関数ドメイン
複数のアーキテクチャー (CPU、GPU など) で実行可能な複雑な数学処理ルーチンを実現するため、クロスアーキテクチャー・パフォーマンスを最適化したインテル® oneMKL は、GPU への数学関数のオフロードを大幅に簡素化します。
CPU と GPU アーキテクチャー向けに最適化された新しい SYCL* インターフェイスが、以下の主要な計算分野の主要機能に追加されています。
- BLAS と LAPACK 密線形代数ルーチン
- スパース BLAS 疎線形代数ルーチン
- 乱数ジェネレーター (RNG)
- ベクトル演算が最適化されたベクトル数学 (VM) ルーチン
- 高速フーリエ変換 (FFT)
さらに、SYCL* インターフェイスとともに OpenMP* オフロードを使用して、インテル® GPU で標準的なインテル® oneMKL 計算を実行することができます。
インテル® oneMKL を oneAPI SYCL* インターフェイスとともに利用するには、まず両方のヘッダーファイルをインクルードします。
// 標準の SYCL* ヘッダー
#include <CL/sycl.hpp>
// インテル oneMKL の SYCL*/DPC++ API 宣言
#include "oneapi/mkl.hpp"
. . .
// デフォルトデバイス上にキューを作成
sycl::queue device_queue{sycl::default_selector{}};
std::cout << "Device: "
<< device_queue.get_device().get_info<sycl::info::device::name>()
<< std::endl;
// 行列の共有メモリーを割り当て
auto A = sycl::malloc_shared<double>(m * k, device_queue);
auto B = sycl::malloc_shared<double>(k * n, device_queue);
auto C = sycl::malloc_shared<double>(m * n, device_queue);
auto C_reference = (double *) calloc(m * n, sizeof(double));
. . .
// GEMM を呼び出して行列乗算を非同期実行
std::cerr << "Launching oneMKL GEMM calculation..." << std::endl;
oneapi::mkl::blas::row_major::gemm(device_queue, transA, transB, m, n, k,
alpha, A, lda, B, ldb, beta, C, ldc);
. . .
そして、定義した特定の SYCL* キューのコンテキストで、これまでと同様にインテル® oneMKL ライブラリー関数呼び出しを行います。今後登場する GPU やアクセラレーターに対応するため、変更は必要ありません。
インテル® oneMKL を使用した API ベースのプログラミングの詳細なコード例は、「インテル® oneAPI プログラミング・ガイド」 (英語) および GitHub* (英語) を参照してください。
インテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP)
すぐに使用でき、高度に最適化された画像、信号、データ処理関数の広範なライブラリーであるインテル® IPP なくして、インテルの包括的なパフォーマンス・ライブラリー群の概要を語ることはできません。
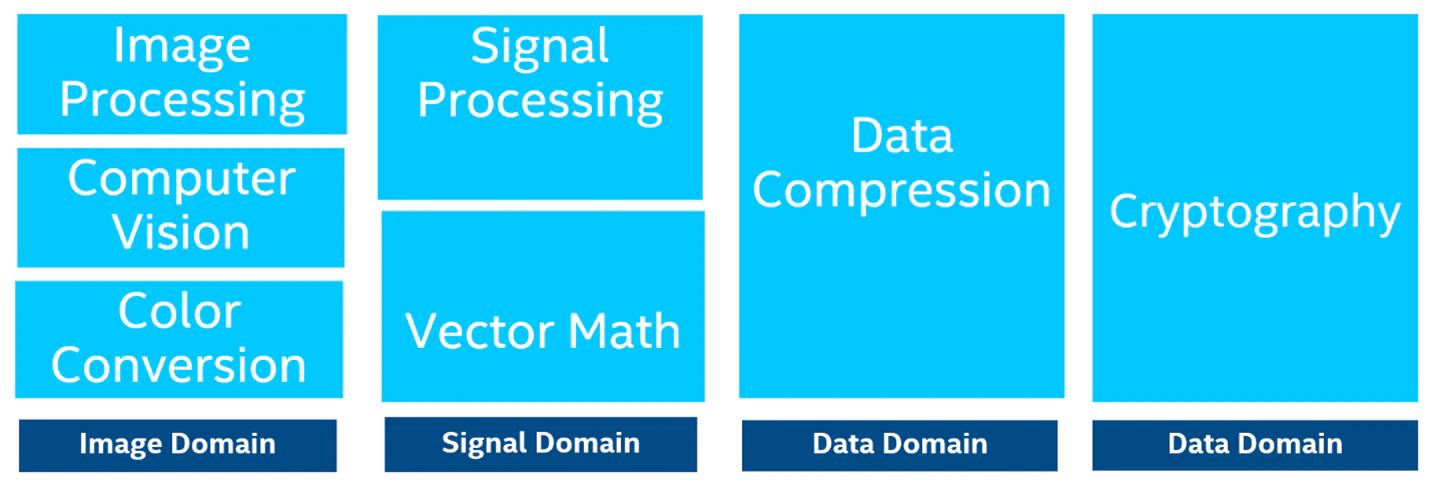
図 3: インテル® IPP ライブラリーの関数ドメイン
インテル® IPP は、クラウドおよびサーバー・アプリケーション、医療用画像処理、デジタル監視、生体認証、ワイヤレス通信などに使用されています。
インテルのほかのパフォーマンス・ライブラリーと同様に、インテル® IPP は安定した API を維持しながら、最新のアーキテクチャーの進歩と並列データおよび並列実行フローの改善に合わせて常に最適化および適応しています。
インテル® oneAPI ビデオ・プロセシング・ライブラリー (インテル® oneVPL)
インテル® oneAPI は、クロスアーキテクチャー・ソフトウェア開発にオープンスタンダードと選択の自由をもたらすだけではありません。メディアとビデオ処理において、システムのインテル® GPU から最高のパフォーマンスを引き出します。
インテル® oneVPL はインテル® メディア SDK (インテル® MSDK) の後継製品で、統合グラフィックスの抽象化から、より幅広いアクセラレーターでのメディア機能の活用まで、幅広く対応できます。
以下は、インテル® IPP の主な機能です。
- 使い慣れたインテル® MSDK コア API との下位互換性を提供します。
- レガシー・ツールキットと同じビデオコーデックとフィルターを含みます。
- インテル® プロセッサー上でハードウェア・アクセラレーションされたコーデックとプログラマブル・グラフィックスにより、メディアおよびビデオ・アプリケーションのパフォーマンスを向上します。
- 高フレームレートと高解像度への移行をスピードアップします。
- ビデオ品質を向上し、クラウド・グラフィックスとメディア解析を革新します。
- 第 12 世代インテル® Core™ プロセッサー、インテル® Iris® Xe グラフィックス、インテル® Arc™ シリーズ・グラフィックスでは、インテル® oneVPL とシステムメモリー、Linux* VA サーフェスとバッファー、DX9 サーフェス、DX11 テクスチャー、DX12 リソース間の低レイテンシー同期と効率良いゼロコピーメモリー相互作用を実現します。
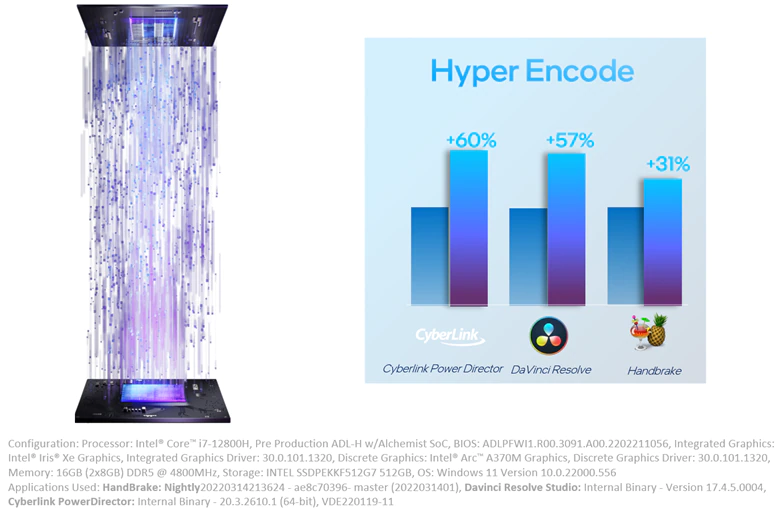
図 4: インテル® oneVPL を使用したインテル® Deep Link テクノロジーによるハイパーエンコード
さらに、インテル® oneVPL がインテル® Deep Link テクノロジーを使用することで、API ベースのプログラミングの利点を生かしながらエンコードを大幅に高速化し、インフラストラクチャーや開発のコストを軽減できます。
AI におけるヘテロジニアス・コンピューティング向けライブラリー
クロスアーキテクチャー・コンピューティング向けのハイパフォーマンス・ライブラリー群に加え、oneAPI プログラミング・モデル仕様 (英語) には、以下のものが含まれます。
- インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) (英語) は、インテルの CPU および GPU 上でのアプリケーション・パフォーマンス向上に関心があるディープラーニング (DL) アプリケーションおよびフレームワーク開発者向けに設計されています。C および C++ インターフェイス、OpenMP*、インテル® oneTBB ランタイムなどの機能を引き続きサポートします。
- インテル® oneAPI コレクティブ・コミュニケーション・ライブラリー (インテル® oneCCL) (英語) は、ディープラーニング・モデルのトレーニングを複数ノードに分散する通信パターンの最適化を支援します。
- インテル® oneAPI データ・アナリティクス・ライブラリー (インテル® oneDAL) は、マシンラーニングおよびディープラーニング・アプリケーションの基盤となる大規模データセット解析アルゴリズムを高速化するため、高度に最適化された機能とソルバーを提供する強力なライブラリーです。
これらは、対応するライブラリー実装とともに、クロスアーキテクチャーのソフトウェア開発を AI や DL に適用する基盤となります。
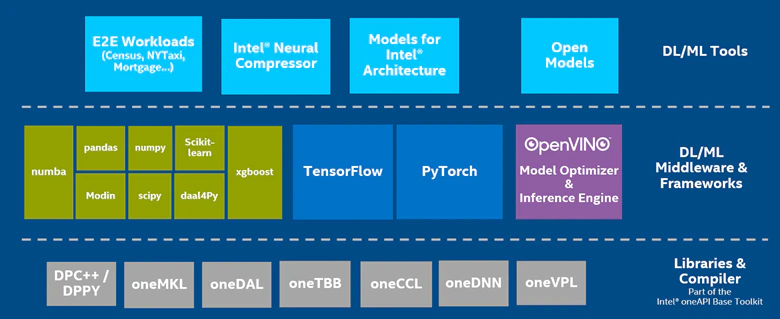
図 5: AI ソフトウェア・スタックとインテル® AI アナリティクス・ツールキット
インテル® AI アナリティクス・ツールキットの追加機能により、インテル® oneAPI ベース・ツールキットは、包括的なクロスアーキテクチャー・ソフトウェア開発ソリューションから、強力な AI トレーニングおよび推論ツールキットへと変わります。
オープンでクロスプラットフォームな解析およびデバッグツール
oneAPI ライブラリーは、ライブラリー、コンパイラー、ツール、パフォーマンス・アナライザー、デバッガーを含む、初の包括的なクロスプラットフォーム・ソリューションの一部です。
多様なヘテロジニアス・プラットフォーム上で動作するように設計され、保守が容易なハイパフォーマンスのワークロードに対して、コードベースの保守が容易な API ベースのプログラミング・モデルを提供します。
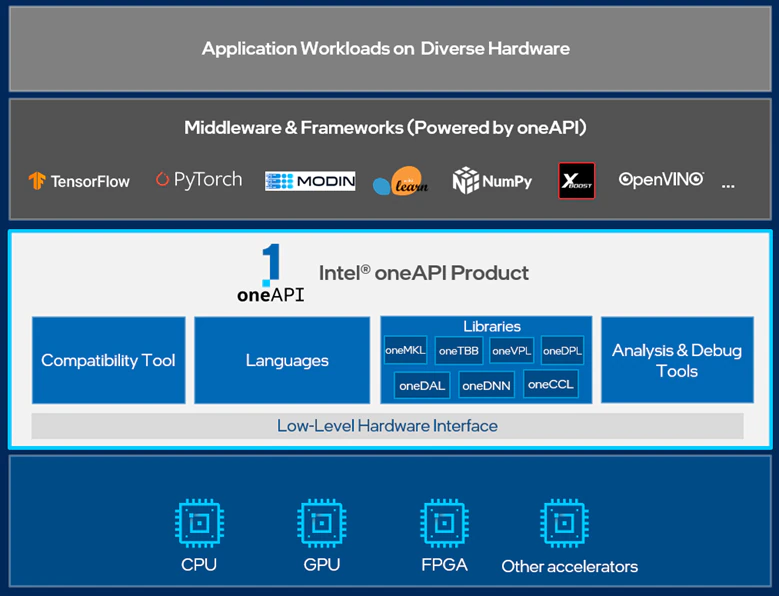
図 6: ライブラリーを含むインテル® oneAPI の概要
oneAPI プログラミング・モデルを利用したアプリケーションは、GPU や FPGA など、複数のターゲット・ハードウェア・プラットフォームで実行できます。
「ホモジニアス・システムの並列プログラミングがユビキタスになったように、ヘテロジニアス・システムの並列プログラミングも同様にユビキタスへの道を歩んでいると考えられます。マルチコアの並列処理とは異なり、ヘテロジニアス・プログラミングは、複数のベンダーの計算能力を利用します。そのため、ライブラリー、コンパイラー、フレームワークにおいて、共通の、オープンな、マルチベンダーのアプローチがなければ、プログラミングが断片化する恐れがあります。」
James は次のようにも述べています。
「インテルは、ヘテロジニアス並列処理に対する oneAPI のオープンなアプローチを強調するため、この次世代の人気ツールを oneAPI と名付けました。oneAPI は、業界が何十年も信頼してきた高品質の製品ツールをベースとしながら、oneAPI 仕様と SYCL* 標準を採用することでヘテロジニアス・プログラミングをサポートするように拡張されています。」
インテルがインテル® Parallel Studio XE で先導したように、oneAPI は数学、ニューラル・ネットワーク、ディープラーニング、レンダリングなど向けに高度に最適化されたマルチベンダー・ライブラリーで、並列処理をさらに一歩進めています。各ライブラリーの標準プリミティブは、CPU コードだけでなく、ほぼすべてのワークロードとフレームワーク向けのマルチアーキテクチャーの世界にまで拡張しています。
3 種類のライブラリー、コンパイラー、デバッガーを必要とする開発者は本当にいるのでしょうか? ほとんどいないでしょう。
oneAPI は、開発者がヘテロジニアス環境であることを理由に新しいツールを学ぶ必要がないため、効率的です。
新しい oneAPI ツールの最大のメリットは、無料で使用でき、マルチベンダーの組織によってサポートされているため、アーキテクチャーを超えたオープン性を確保できることです。
ソフトウェアを入手
この記事で紹介したソフトウェアをダウンロードして、活用してください。
- インテル® oneAPI ベース・ツールキット: クロスアーキテクチャー・アプリケーションを作成するコンパイラー、ライブラリー、言語、フレームワーク、解析およびデバッガーを含む基本ツールセットです (現在 15 種類のツールが含まれており、今後さらに追加される可能性があります)。
- インテル® AI アナリティクス・ツールキット: データサイエンス (AI/ML/DL) ワークロードのエンドツーエンドのパフォーマンスを実現するツールです。
クラウド上の新しいインテル® テクノロジーのベータアクセスを取得
インテル® Developer Cloud (英語) アカウントは、最新のインテル® ハードウェアとインテル® oneAPI ソフトウェアにアクセス可能な無料の開発用サンドボックスです。
登録申請が承認されると、製品発売の数カ月から 1 年前に、インテルのテクノロジーに早期にアクセスし、インテルの強化されたクラウドベースのサービス・プラットフォーム上でそれらを試し、テストし、評価できます。
ベータアクセスには、以下のような新しいインテルのコンピュートおよびアクセラレーター・プラットフォームが含まれます。
- 第 4 世代インテル® Xeon® スケーラブル・プロセッサー (開発コード名 Sapphire Rapids)
- 第 4 世代インテル® Xeon® プロセッサー、高帯域幅メモリー (HBM) 搭載
- インテル® Data Center GPU (開発コード名 Ponte Vecchio)
- インテル® Data Center GPU フレックス・シリーズ
- インテル® Xeon® D プロセッサー (開発コード名 Ice Lake D)
- Habana* Gaudi*2 ディープラーニング・アクセラレーター
ベータアクセスには、登録と事前審査が必要です。
cloud.intel.com (英語) にアクセスして始めましょう。
まとめ
ヘテロジニアス環境向けのアプリケーション構築をサポートするツールやライブラリーの需要が高まっています。インテル® oneAPI ツールおよび仕様は、異なるアーキテクチャーでコードの再利用をサポートするプログラミング・モデルと、一般的な並列ワークロード向けに高度に最適化されたライブラリーを開発者に提供します。
これにより、最終的にアプリケーションの効率と開発者のワークフローの両方が改善されます。開発者はコードを一度書けば、価格、可用性、パフォーマンスの要件に応じて異なるアーキテクチャーで実行できます。
並列プログラミングは、現在、ホモジニアス・システムでユビキタスになっており、論理的な次のステップは、これをヘテロジニアス・システムに拡大することです。これは、oneAPI のような、異なるアーキテクチャーの複雑性から抽象化されたレイヤーを提供するツールによってのみ達成することができます。
関連情報
オンデマンド・ウェビナー
- 高速化なクロスプラットフォームの AI ワークロードをワンステップで起動
https://www.intel.com/content/www/us/en/developer/videos/launch-accelerated-ai-workloads-in-one-step.html - ヘテロジニアス・ワークロードにおける CPU、GPU、FPGA の利点を比較する (英語)
- 新しいインテル® oneAPI DPC++/C++ コンパイラーへの移行 (英語)
- DPC++ プログラミング入門 (英語)
記事
- oneAPI で言語とアクセラレーターのサポートを拡大 (英語)
- oneDPL による C++ プログラミングの生産性とパフォーマンスの向上
- SYCL* と C++ を補完する新しいオープンな DPC++ 拡張
- ヘテロジニアスな処理にはデータ並列化が必要
ソフトウェアを入手
インテル® oneAPI ベース・ツールキット
ハイパフォーマンスなデータセントリックのアプリケーションを多様なアーキテクチャー向けに開発してデプロイするのに必要なツールとライブラリーの基本セットを提供します。
今すぐ入手 (英語)
すべてのツールを見る (英語)
