

この記事は、インテルの The Parallel Universe Magazine 27 号に収録されている、インテル® Advisor の新しいルーフライン解析機能を利用して、パフォーマンス最適化のトレードオフを視覚化する方法に関する章を抜粋翻訳したものです。
現在、そして将来のハードウェアを最大限に活用するためには、ソフトウェアはスレッド化およびベクトル化されていなければなりません。データに基づくベクトル化設計は、長期間にわたって優れたパフォーマンスを達成可能で、少ないリスクで大きな効果が得られます。ベクトルレベルおよびスレッドレベルで完全に並列化されている場合であっても、開発者が CPU/ベクトル/スレッドの使用状況とメモリー・サブシステムのボトルネックを調整しなければならないことはよくあります。多くの場合、ルーフラインの「依存とボトルネック」パフォーマンス・モデルを使用することで、この最適化に対応できます。
この記事では、インテル® Advisor 2017 の概要を提供し、新しいルーフライン解析 (Roofline Analysis) 機能を説明します。ルーフライン・モデルは、アプリケーションのパフォーマンスの問題に対応するための最良の方法を、直感的かつ強力に表現します。ケーススタディーでは、実際の例を用いて最適化プロセスを紹介します。
ルーフライン・モデル
ルーフライン・モデルは、カリフォルニア大学バークレー校の研究者 Samuel Williams、Andrew Waterman、David Patterson により、2009 年に「Roofline: An Insightful Visual Performance Model for Multicore Architectures」(href=”http://www.eecs.berkeley.edu/~waterman/papers/roofline.pdf) で提案されました。近年、このモデルは、Aleksandar Ilic、Frederico Pratas、Leonel Sousa の論文「Cache-Aware Roofline Model: Upgrading the Loft」(http://www.inesc-id.pt/ficheiros/publicacoes/9068.pdf) で、メモリー・サブシステムのすべてのレベルに対応するように拡張されました。
ルーフライン・モデルは、開発者が次の質問に答えられるように支援することで、アプリケーションの動作に関する詳細を提供します。
- アプリケーションは現在のハードウェアで最適に動作していますか? そうでない場合、最も活用されていないハードウェア・リソースは何ですか?
- パフォーマンスを制限している要因は何ですか? アプリケーションのワークロードはメモリー依存または計算依存ですか?
- アプリケーションのパフォーマンスを向上する適切な方法は何ですか?
モデルは、次の 2 つのパラメーターを測定し、アプリケーションの計算とメモリー帯域幅の上限を視覚化できるようにデータをグラフ化します。
- 演算密度 (CPU とメモリー間で転送されたバイトあたりの浮動小数点演算数)
- 浮動小数点パフォーマンス (GFLOPS)
データポイントがモデルライン (ルーフライン) に近いほど、適切に最適化されていることを示します (図 1)。青色の領域にあるカーネルのほうが計算への依存度が高く、Y 軸の上方向にあるカーネルのほうがピーク浮動小数点パフォーマンスに近くなります。これらのカーネルのパフォーマンスは、プラットフォームの計算能力に依存します。カーネル 3 のパフォーマンスを高めるには、インテル® Xeon Phi™ プロセッサーのような計算能力とメモリー・スループットが高い高度な並列プラットフォームへの移行を検討してください。カーネル 2 は、上限からほど遠く離れているため、ベクトル化によりパフォーマンスを向上できるでしょう。
グラフの赤色の領域にあるカーネルはメモリーに依存します。Y 軸の上方向になるほど、カーネルはプラットフォームの DRAM とキャッシュのピーク帯域幅により制限されます。これらのカーネルのパフォーマンスを向上するには、データ項目ごとの計算量を増やして、パフォーマンスの上限が高いグラフの右側に移動するように、アルゴリズムまたはその実装を再検討してください。これらのカーネルも、インテル® Xeon Phi™ プロセッサーの高いメモリー帯域幅により、高速に実行できる可能性があります。
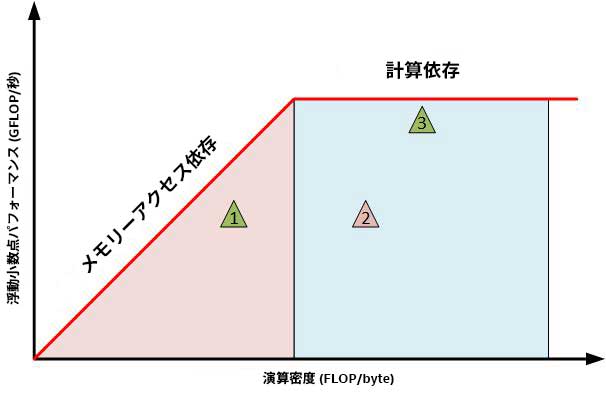
図 1. ルーフライン・グラフ
インテル® Advisor の概要
インテル® Advisor は、強力なソフトウェア設計とアプリケーション・パフォーマンスの特徴付けを支援するソフトウェア解析ツールです。スレッド並列処理のプロトタイプ生成 (スレッド化アドバイザー)、ベクトル並列処理の最適化 (ベクトル化アドバイザー)、メモリーと計算の特徴付け (ルーフライン・オートメーション) 機能を提供します。
この記事では、主にインテル® Advisor のルーフライン解析とベクトル化解析を取り上げます。インテル® Advisor の GUI では、ワークフロー・セレクターを使用してベクトル化アドバイザーとスレッド化アドバイザーのワークフローを切り替えることができます。ルーフライン・グラフは、[ROOFLINE] サイドバーからアクセスできます (図 2)。
図 2. インテル® Advisor のワークフロー・セレクター
ベクトル化アドバイザーは、次のステップを使用してコードのパフォーマンスを向上できるように支援します。
- サーベイ (Survey) は、最も時間を費やしているループと詳細な SIMD 統計を表示します。
- FLOPS とトリップカウント (Trip Counts) は、各ループと関数の反復回数、呼び出し回数、および正確なFLOPS を測定します。
- 推奨事項 (Recommendations) は、パフォーマンスの問題を解決するための具体的なアドバイスを示します。
- 依存性解析 (Dependencies Analysis) は、ループにベクトル化や並列化の妨げとなる反復間の依存性がないか、動的な依存性解析を行います。
- メモリー・アクセス・パターン解析 (Memory Access Patterns Analysis) は、ベクトル化に適した方法でメモリーを参照しているか確認します。
ベクトル化アドバイザーとルーフライン解析を組み合わせることで、パフォーマンスと設計に関する多くの重要な洞察を得ることができます。例えば、ルーフライン・グラフのデータを解釈するには、ベクトル化アドバイザーの [Survey Report (サーベイレポート)] で提供されるベクトル化の効率メトリックを把握しておく必要があります。
インテル® Advisor のルーフライン解析
インテル® Advisor は、「キャッシュを意識した」ルーフライン・モデルを実装し、メモリー/ キャッシュ階層のすべてのレベルにわたる詳細を提供します。
- ルーフラインの傾斜部分は、すべてのデータが該当キャッシュに収まる場合のピーク・パフォーマンスを示します。
- 水平線は、ベクトル化やその他の CPU リソースが効率良く利用されている場合に達成可能なピーク・パフォーマンスを示します。
インテル® Advisor は、各ループに対応する点をルーフライン・グラフ上に描画します (図 3)。点の大きさと色は、ループの相対的な実行時間を示します。ほとんどのループは、キャッシュメモリーを効率良く利用できるように、さらなる最適化が必要です。いくつかのループ (例えば、グラフ中央の垂直線の右側で、水平の破線 ScalarAddPeak 上にある緑色の点) は、効率良くベクトル化されていません。このように、ルーフライン・グラフを利用することで、アプリケーション・パフォーマンス向上の可能性を簡単に見つけることができます。
