
この記事は、インテル® デベロッパー・ゾーンに公開されている「Memory-Level Roofline Analysis in Intel® Advisor 」の日本語参考訳です。
この記事の PDF 版はこちらからご利用になれます。
はじめに
インテル® Parallel Studio XE 2020 Update 2 から、インテル® Advisor は、メモリーレベルのルーフライン・モデルと呼ばれる強力な新機能を実装しています。この新機能は、キャッシュ・シミュレーションに基づいて、システムで利用可能な異なるメモリー階層間のデータ・トランザクションを評価して、アプリケーションのパフォーマンス向上に対する自動ガイダンスを提供します。
メモリーレベルのルーフラインは、DRAM データ転送のみに注目することで、古典的なルーフライン・モデルに近い機能を実装します。この記事では、古典的なルーフライン・モデル・ビューを生成する方法を説明します。
注: このバージョンのメモリーレベルのルーフライン・モデルは、ハイパフォーマンス・コンピューティングに多いキャッシュまたはメモリー依存のアプリケーションに適用されます。今後のリリースでは、計算依存のアプリケーションに注目する予定です。
メモリーレベルのルーフライン・モデルの設定
- インテル® Advisor を開いて、新規プロジェクトを作成し、実行ファイルとパラメーターを設定します。
- [Project Properties (プロジェクトのプロパティー)] で、[Trip Counts and FLOP Analysis (トリップカウント & FLOP 解析)] に移動します。
- スクロールダウンして、キャッシュ・シミュレーションを有効にします。デフォルトでは、インテル® Advisor はシステムのキャッシュ構成を適用します。カスタムのキャッシュ構成は、テキストボックスに入力できます。
イメージをクリックして拡大表示 - プロジェクトを適切に設定したら、[OK] をクリックします。
メモリーレベルのルーフラインの実行
GUI から
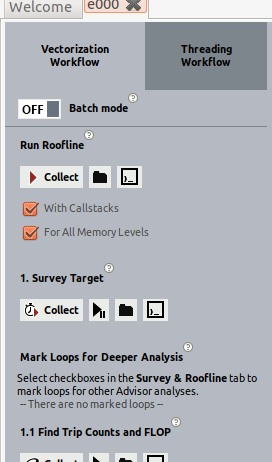
- 左ペインの [Vectorization Workflow (ベクトル化ワークフロー)] タブで、[With Callstacks (コールスタック付き)] チェックボックス (ループのコールスタックに関する詳細情報を取得) と [For All Memory Levels (すべてのメモリーレベル)] チェックボックスをオンにしてメモリーレベルのルーフラインを有効にします。
- [Collect] をクリックして、インテル® Advisor が必要なデータを収集するのを待機します。
インテル® Advisor は、バックグラウンドで 2 つの解析を実行します。
- 1 つ目の [Survey analysis (サーベイ解析)] は、サンプリングを使用して関数とループの実行時間を測定します。このステップでは、実行時間にわずかなオーバーヘッド (2% 未満) が生じます。サーベイ解析は、バイナリーからベクトル化と命令セットに関する情報も取得します。
- 2 つ目の [Trip Counts and FLOP Analysis (トリップカウント & FLOP 解析)] 解析は、実行される命令の種類を評価します。この解析は、ループの反復回数、整数操作の数、および浮動小数点操作の数をカウントします。また、このステップで、インテル® Advisor はキャッシュ・シミュレーションを実行して、異なるメモリー・サブシステムのミスとヒットを予測します。現在、インテル® Advisor は、L1、L2、LLC、および DRAM のキャッシュ・シミュレーションをサポートしています。2 つ目の解析では、1 つ目の解析よりもオーバーヘッドがかなり大きくなります (パフォーマンスが最大 1/30 に低下します)。
コマンドラインから
コマンドラインからメモリーレベルのルーフライン・モデルを実行するには、次のいずれかの操作を行います。
- 2 つのコマンドラインを 1 つずつ実行して、サーベイデータとトリップカウント & FLOP データを収集します。トリップカウント & FLOP 解析は、–enable-cache-simulation オプションを指定して実行します。
advixe-cl --collect=survey --project-dir=./my_project -- ./myapp param1 param2 .... advixe-cl --collect=tripcounts -flop --enable-cache-simulation --project-dir=./my_project -- ./myapp param1 param2 ....
- –enable-cache-simulation オプションを指定して、自動的にこの 2 つの解析を実行するルーフライン・コマンドを実行します。
advixe-cl --collect=roofline -enable-cache-simulation --project-dir=./my_project -- ./my_app parm1 parm2 ....
結果の解釈
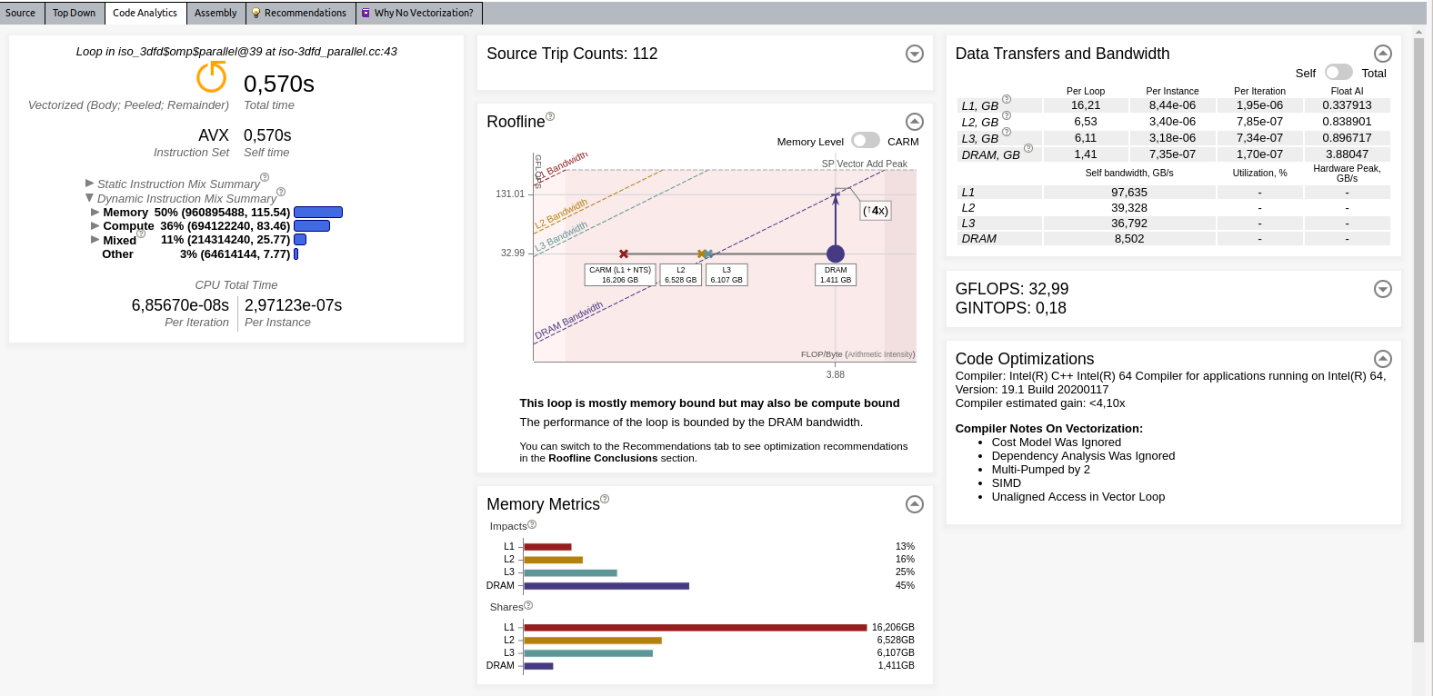
解析が完了すると、インテル® Advisor はルーフライン・グラフを表示します。デフォルトでは、インテル® Advisor は、ループごとに 1 つのドット (点) を持つキャッシュを意識したルーフライン・モデル (CARM) のみ表示します。[Code Analytics (コード解析)] タブでは多くのメトリックを利用できます。
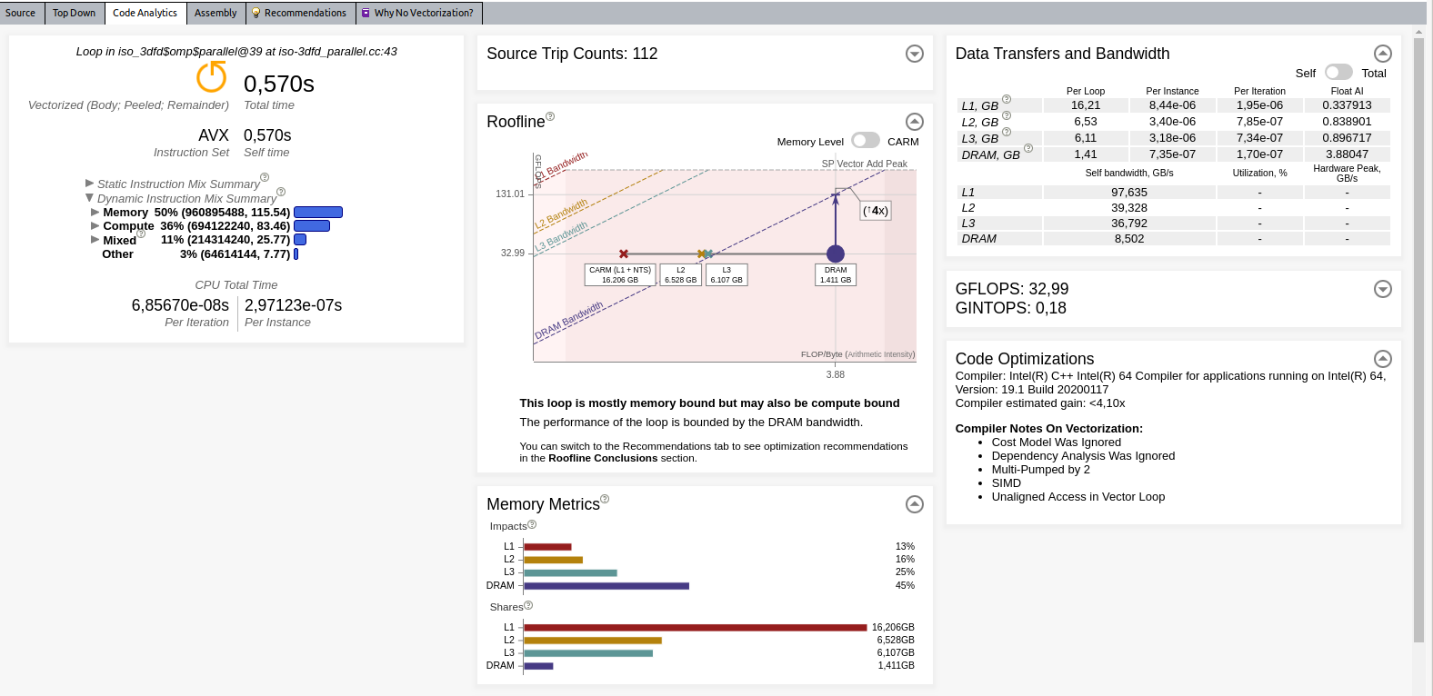
イメージをクリックして拡大表示
以降のセクションでは、利用可能なメトリック/情報のいくつかを説明します。
ルーフライン
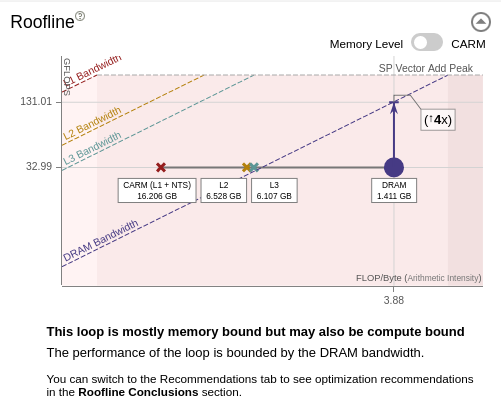
イメージをクリックして拡大表示
[Code Analytics (コード解析)] タブにあるこのペインは、メモリーレベルのルーフライン解析に基づいて自動ガイダンスを提供します。上記の例では、インテル® Advisor は DRAM の潜在的なスピードアップが 4 倍のみであることを検出しています。
注: [Recommendation (推奨事項)] タブは、DRAM からのメモリー転送を軽減するキャッシュ・ブロッキングの実装やデータ構造の変更など、より詳細なアドバイスを提供します。
このビューは、単一のループのドットを表示します。各ドットのパフォーマンス (垂直位置) は同じですが、演算強度 (水平位置) は異なります。
ルーフライン・モデル理論に基づいて、演算強度は FLOP をバイト数で割った比率 (操作数÷メモリー移動量) となります。単一ループのこれらのドットを表示するため、インテル® Advisor は、キャッシュ・シミュレーションのデータと以下のメモリー転送を考慮して演算強度を計算します。
- レジスターと L1 間のメモリー転送 (CARM ドット)
- L1 と L2 間のメモリー転送 (L2 ドット)
- L2 と LLC 間のメモリー転送 (L3 ドット)
- LLC と DRAM 間のメモリー転送 (DRAM ドット)
メモリーメトリック
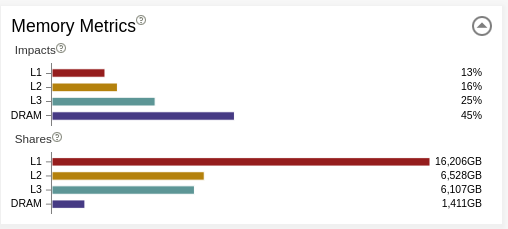
[Memory Metrics (メモリーメトリック)] には 2 つのセクションがあります。
- [Impacts (影響)] は、システムが異なるメモリーレベル (L1、L2、L3、DRAM) からの要求処理に費やした時間のパーセンテージを示します。最も長いバーは、実際のボトルネックを示しています。上位の 2 つのバーの差から、メインのボトルネックへの影響を軽減することで得られるスループットを把握できます。また、最も長いバーの問題を解決したら、次に 2 番目に長いバーの問題を調査するというように、長期的なプランが得られます。理想的には、アプリケーションの各ループで最も影響のあるメモリーは L1 になるべきです。
- [Shares (共有)] は、データがどのメモリー階層で最も頻繁に検出されたかを示します。
データ転送と帯域幅
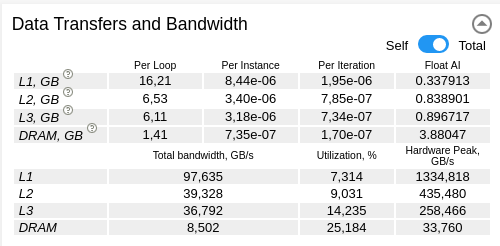
[Data Transfers and Bandwidth (データ転送と帯域幅)] は、異なるレベル (L1、L2、L3、および DRAM) のメモリーメトリックを提供します。単一のスレッド (セルフ) またはすべてのスレッド (合計) のデータ転送量と帯域幅を示します。
メモリーレベルのルーフラインの設定
メモリーレベルのルーフラインの表示
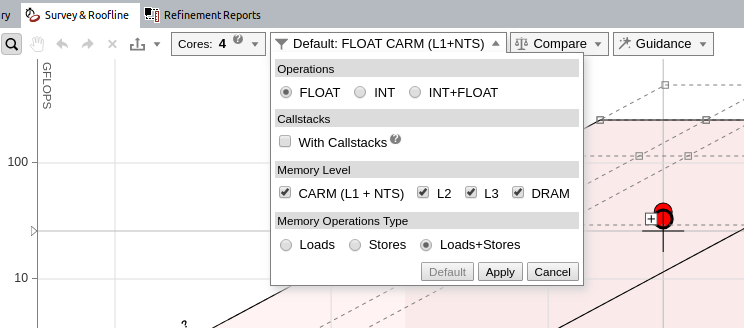
イメージをクリックして拡大表示
デフォルトでは、インテル® Advisor は CARM レベルのみ表示します。メモリーレベルのルーフラインを有効にするには、ルーフライン・グラフのフィルター・ドロップダウンからメモリーレベルを選択して、[Apply (適用)] をクリックします。
これで、ループごとに最大 4 つのドットが表示されます。
メモリーレベルの関連性の表示
メモリーレベルのルーフラインは、単一のループまたは関数について、すべてのメモリーレベル間の相互作用を表示できます。これは、[Memory Metrics (メモリーメトリック)] の [Impacts (影響)] と同様の情報を、異なる方法で提供します。
単一カーネルのルーフライン・ドット間の関連性を表示するには、[Guidance (ガイド)] ドロップダウンから [Show memory level relationships (メモリーレベルの関連性を表示)] を選択して、[Apply (適用)] をクリックします。また、フィルター・ドロップダウンですべてのメモリーレベルが選択されていることを確認してください。
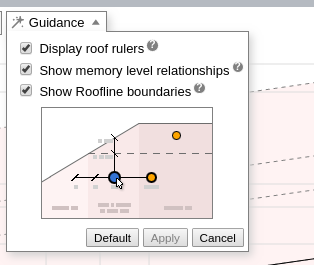
グラフ上のドットをダブルクリックすると、すべてのメモリーレベルを展開できます。

イメージをクリックして拡大表示
- 各ドット間の水平距離は、キャッシュの利用効率を示します。例えば、単一ループで L3 ドットと DRAM ドットの水平距離が近い場合、L3 と DRAM の利用状況は類似しており、L3 と DRAM が効率良く使用されていないことを意味します。DRAM にあるデータの再利用を高めることで、アプリケーションのパフォーマンスを向上できます。
- それぞれのルーフラインにドットを表示することで、特定のメモリー・サブシステムによってどれだけ制限されているかが分かります。ドットがルーフに近い場合、カーネルはそのメモリーレベルのパフォーマンスによって制限されます。
- また、ドットの順序はメモリーアクセスの問題 (一定または不規則なストライド) を示唆している可能性があります。ほとんどのケースでは、ループの L1、L2、L3、および DRAM ドットは左から右へ表示されることが想定されます。これは上級者向けですが、L1->L2->L3->DRAM 順でない場合は、メモリー・アクセス・パターン解析を実行すると良いでしょう。
HTML ルーフライン・レポートのエクスポート
ルーフライン・レポートが生成されたら、HTML 形式でエクスポートできます。これは、特定の最適化ステップのルーフラインを保存する非常に効率良い方法です。HTML でエクスポートするアイコンをクリックするだけでエクスポートできます。
古典的なルーフライン・モデル
イメージをクリックして拡大表示
メモリーレベルのルーフライン・モデルでは、カリフォルニア大学バークレー校によって発表された、DRAM データ転送に基づく古典的なルーフライン・モデルを生成することができます。多くのハイパフォーマンス・コンピューティング・アプリケーションは、DRAM からのデータ転送に依存しています。古典的なルーフラインは、DRAM 帯域幅に近いカーネルを特定するのに役立ちます。ループが DRAM パフォーマンスに近づいたら、キャッシュ・ブロッキングを実装したり、データ構造を変更するなどして、このループのメモリーの影響を軽減する方法を見つけるべきです。
古典的なルーフラインを表示するには、フィルター・ドロップダウンから DRAM メモリーレベルのみを選択します。ドットにポインターを合わせると、DRAM メモリーアクセス数に基づく、最大パフォーマンスに到達するまでの距離を確認できます。
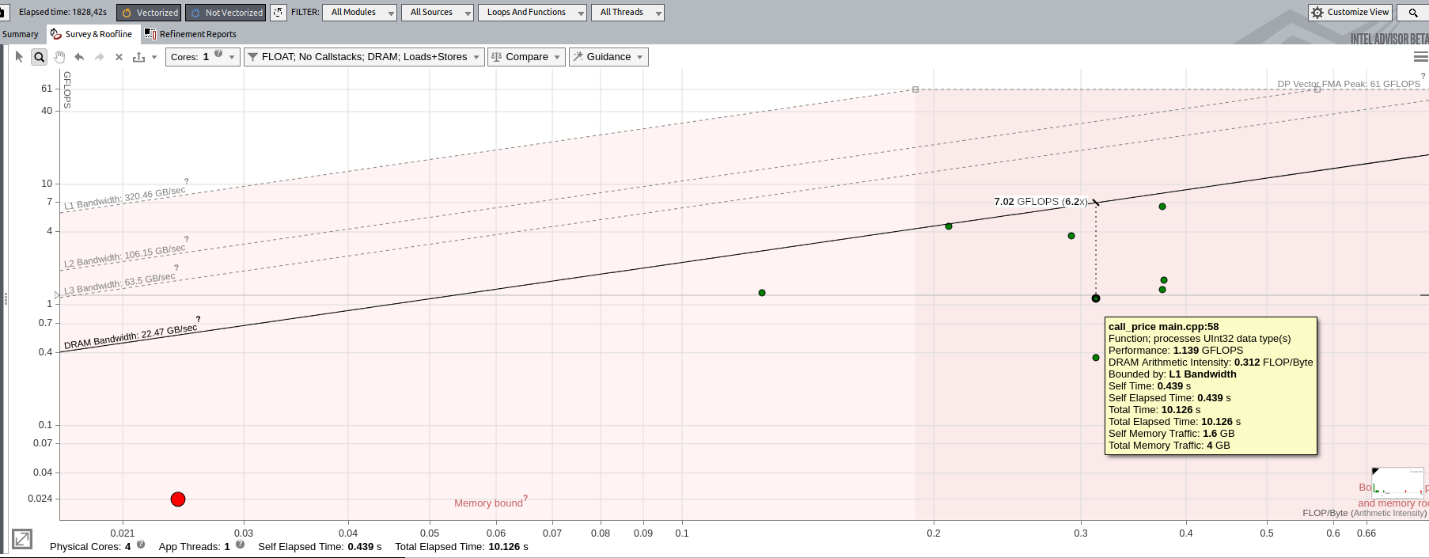
イメージをクリックして拡大表示
使用モデル
インテル® Advisor のメモリーレベルのルーフライン・モデルは、新しいインターフェイス機能を備えています。次の 2 つの使用モデルを推奨します。
- ルーフライン・グラフに注目して、異なるホットスポットを調査し、メモリーの影響を理解します。この使用モデルは、ルーフライン・グラフと [Memory Metrics (メモリーメトリック)] の [Impacts (影響)] の両方を使用し、アプリケーションとループ/関数を高レベルで分類するのに適しています。
- ルーフライン・グラフと [Code Analytics (コード解析)] タブを使用して、選択したループのパフォーマンスを向上する高度な詳細と推奨事項を得ます。
最初に、ルーフラインのみの表示から開始してアプリケーションの特性を理解し、その後ルーフラインとコード解析に進むことを推奨します。
ルーフライン・レポートのみ使用
ルーフライン・データが収集されたら、ルーフラインと [Code Analytics (コード解析)] の間の垂直バーを移動してルーフライン・ビューを拡張します。
メモリーの影響と共有を表示するには、以下のスクリーンショットに示すように、ルーフライン・グラフの右端にある垂直バーをクリックします。すると、追加のメトリックを含むペインが表示されます。
ルーフライン・ビューから不要なすべての情報や不要なルーフラインなどをクリアするには、グラフの右上にある [ルーフライン・ビューの設定] メニューを開いて、項目を無効にします。
以下のスクリーンショットに示すように、このテスト例では倍精度のみを使用して、FMA ピークのみに注目しています。そして、L1、L2、L3、および DRAM 帯域幅と FMA ピークのみを表示しています。
変更が反映されると、ルーフライン・ビューがより見やすくなります。DRAM からのデータのみを有効にすると、古典的なルーフライン・モデルを表示できます。
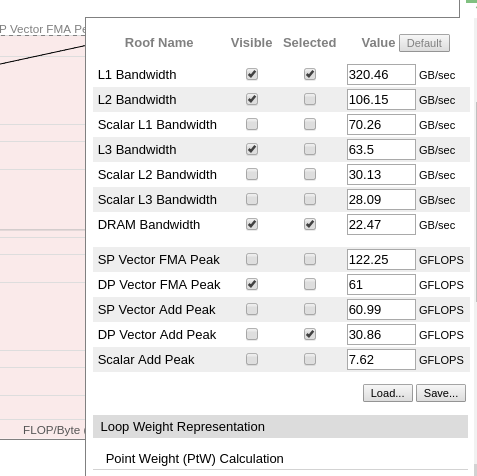
このビューでは、ドットで表される各ループや関数を選択して、カーネルが異なるメモリー・サブシステムからのデータをどのように使用しているかを確認できます。カーネル間を移動することで、アプリケーションがメモリーアクセスと計算のどちらに制限されているかが分かります。大きな赤色のループは、アプリケーションが最も多くの時間を費やしているコード領域を表します。

イメージをクリックして拡大表示
この例では、ループの 1 つを選択すると、DRAM からの影響が 61% であることが分かります。つまり、現在のボトルネックは DRAM からデータにアクセスしているか、読み書きしています。このループを改善する次のステップに関する詳細を得るため、画面下部の [Code Analytics (コード解析)] を開いて、2 つ目の使用モデルを使用します。
ルーフライン・グラフとコード解析の使用
この使用モデルでは、ルーフライン・グラフとコード解析を確認して、制限の原因を理解します。このモデルは、現在のボトルネックを解消するための推奨事項も提供します。
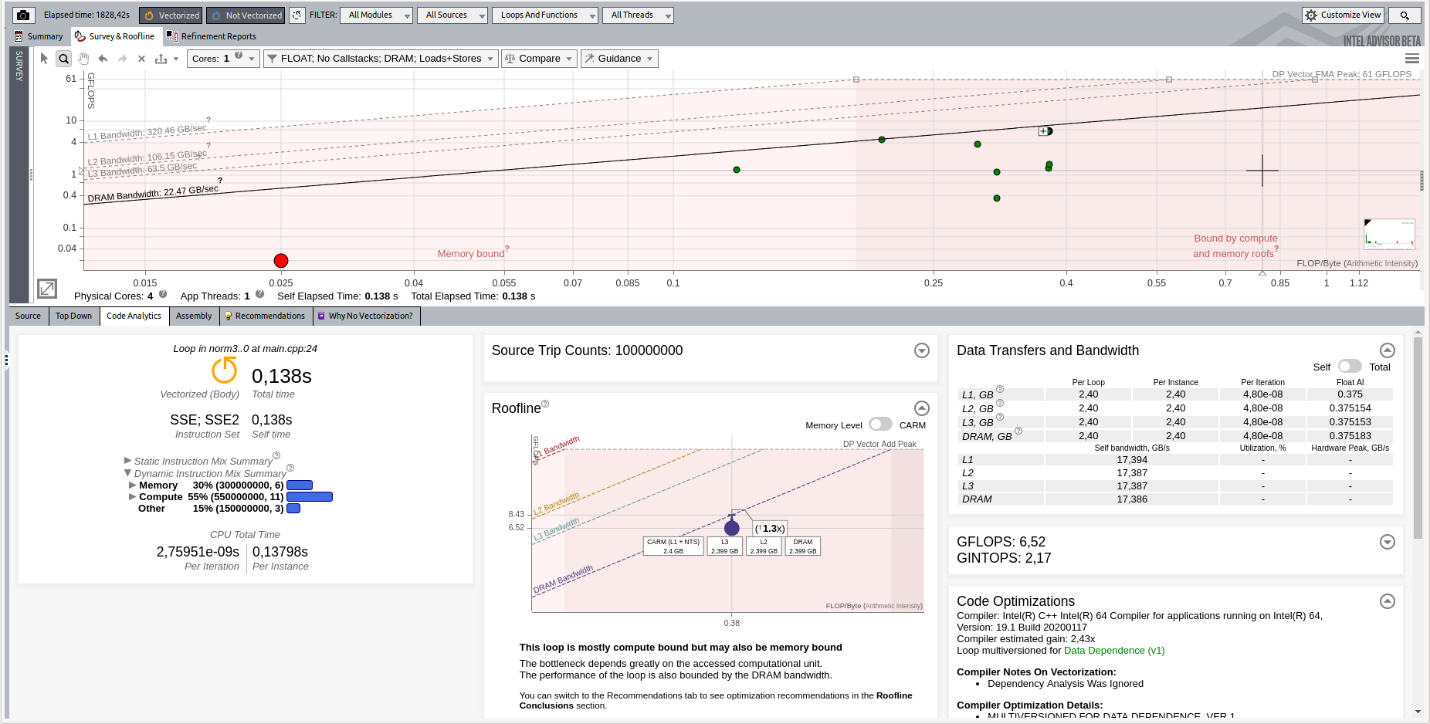
イメージをクリックして拡大表示
[Code Analytics (コード解析)] の [Roofline (ルーフライン)] から、ループは現在計算依存ですが、メモリーによってもパフォーマンスが制限されていることが分かります。インテル® Advisor は、[Recommendation (推奨事項)] タブでこの問題を解決するための推奨を提供します。
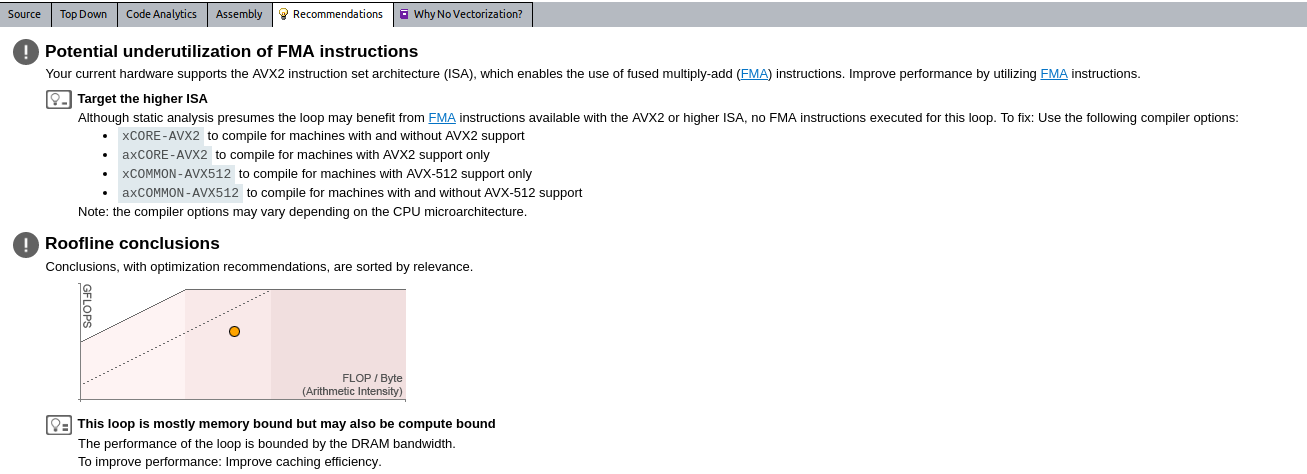
イメージをクリックして拡大表示
この例では、インテル® Advisor は 2 つの潜在的な問題を検出しました。
- 命令セットがプラットフォームと一致していません。より効率良い計算が可能です。
- ループはメモリー依存であり、キャッシュ効率の向上が推奨されています。例えば、キャッシュ・ブロッキングを実装できます。
推奨事項は各ループに固有であり、ルーフライン・グラフで別のループを選択すると変わります。
iso3DFD アプリケーションでのルーフラインの使用
はじめに
Iso3dfd は、有限差分に基づく波動伝播カーネルです。小さなコードですが、いくつかの最適化を適用できます。この例では、インテル® Advisor の推奨事項のみを使用して、いくつかのパフォーマンス問題の検出と解決を試みます。
ベースライン結果の収集
最適化前のオリジナルコードでは、1 つの関数でほとんどの計算が行われています。
void iso_3dfd_it(float *ptr_next, float *ptr_prev, float *ptr_vel, float *coeff,
const int n1, const int n2, const int n3, const int num_threads,
const int n1_Tblock, const int n2_Tblock, const int n3_Tblock){
int dimn1n2 = n1*n2;
for(int ix=HALF_LENGTH; ix<n1-HALF_LENGTH; ix++) {
for(int iy=HALF_LENGTH; iy<n2-HALF_LENGTH; iy++) {
for(int iz=HALF_LENGTH; iz<n3-HALF_LENGTH; iz++) {
int offset = iz*dimn1n2 + iy*n1 + ix;
float value = 0.0;
value += ptr_prev[offset]*coeff[0];
for(int ir=1; ir<=HALF_LENGTH; ir++) {
value += coeff[ir] * (ptr_prev[offset + ir] + ptr_prev[offset - ir]);
value += coeff[ir] * (ptr_prev[offset + ir*n1] + ptr_prev[offset - ir*n1]);
value += coeff[ir] * (ptr_prev[offset + ir*dimn1n2] + ptr_prev[offset - ir*dimn1n2]);
}
ptr_next[offset] = 2.0f* ptr_prev[offset] - ptr_next[offset] + value*ptr_vel[offset];
}
}
}
}
オリジナルコードのベースライン結果を取得するには、次の操作を行います。
- コードをコンパイルします。最初のテストでは、次のオプションを使用します。
- -O2: 適度な最適化を要求します。コンパイラーによる最適化のよい出発点です。
- -g: デバッグ情報を有効にします。
- -xCORE-AVX2: インテル® アドバンスト・ベクトル・エクステンション 2 (インテル® AVX2) 命令セットを有効にします。
- -qopenmp: スレッド化を有効にします。
- インテル® Advisor を起動して、メモリーレベルのルーフライン・モデル解析を設定します。
- ルーフライン・ビューに切り替えて、メインループを選択します。次のような表示になります。
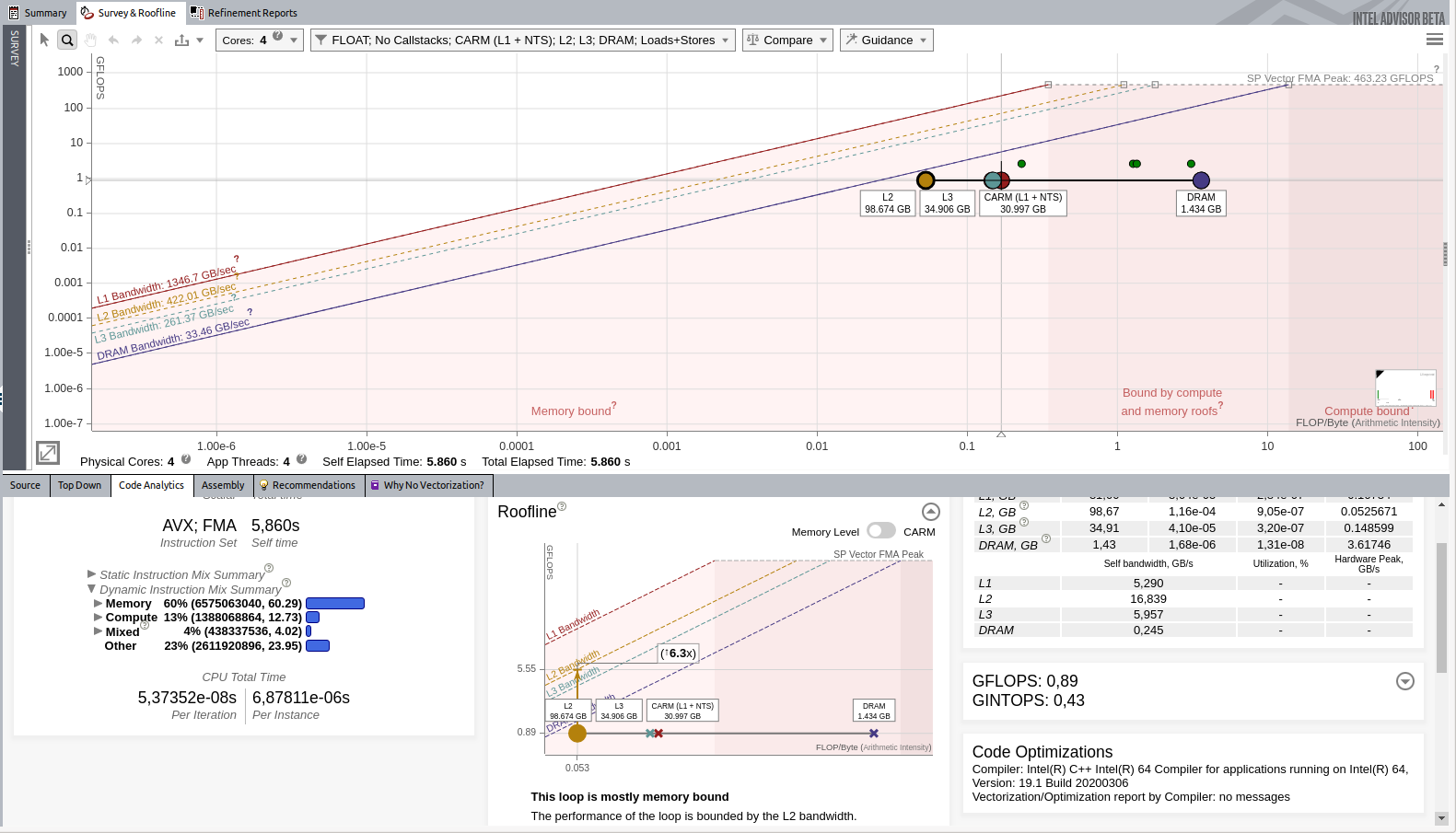
イメージをクリックして拡大表示
次の重要なデータを確認します。
- インテル® Advisor は、このループが「スカラー」 (ベクトル化されていない) であると報告しています。「ベクトル化を強制する」ことで改善できる可能性があります。
- インテル® Advisor は、ほとんどのループがメモリー依存であり、L2 に問題があるように見えると報告しています。
ここでは、1 つ目のデータに注目します。[Why No Vectorization (ベクトル化できない理由)] タブに切り替えて、効率良いベクトル化を妨げる要因について追加情報を確認します。
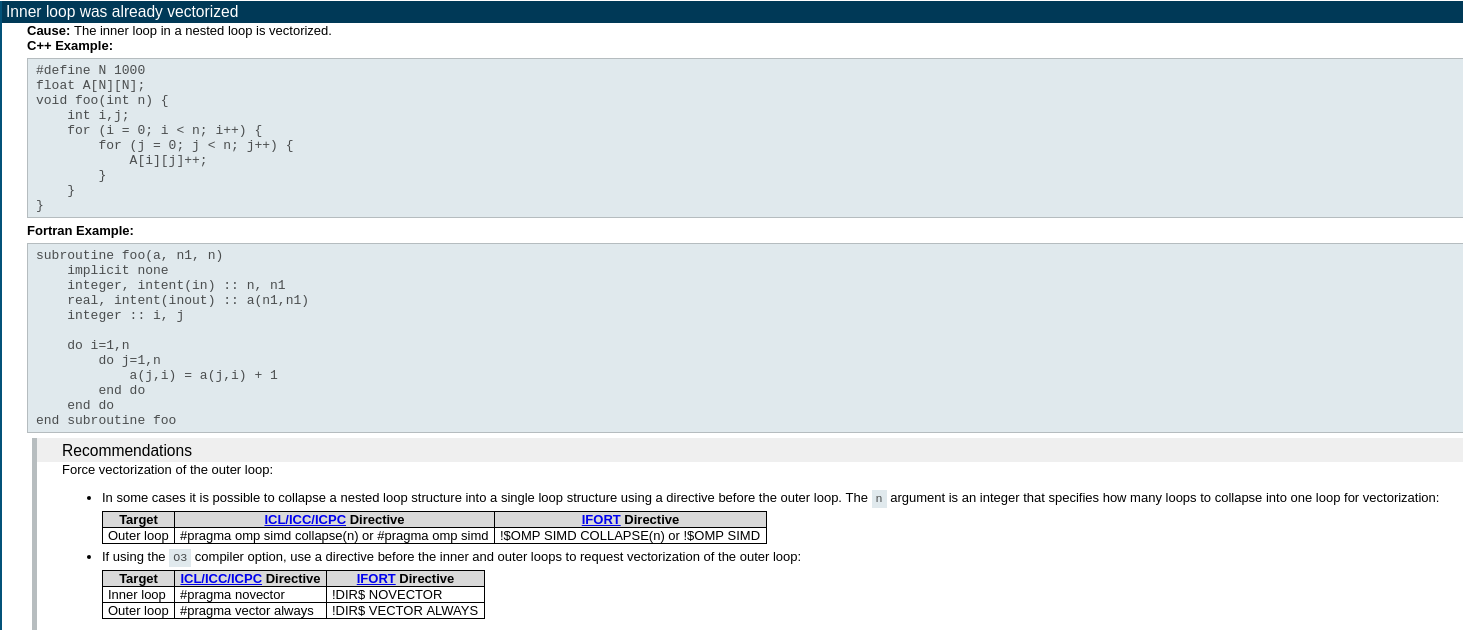
イメージをクリックして拡大表示
上記のスクリーンショットから、コンパイラーはすでに内部ループをベクトル化しており、インテル® Advisor は外部ループがベクトル化できるか確認することを推奨しています。外部ループのベクトル化を有効にするには、コードをわずかに変更して、OpenMP* ディレクティブを追加する必要があります。
ベクトル化の強制が安全かどうか分からない場合は、データ依存関係が存在すると結果が正しく生成されないため、インテル® Advisor の [Dependency Analysis (依存関係解析)] を実行します。[Survey (サーベイ)] ビューでループを選択して、[Vectorization Workflow (ベクトル化ワークフロー)] タブの [Check Dependencies (依存関係の確認)] の下にある [Collect] ボタンをクリックします。
この解析の結果は、依存関係がないことを示しています。外部ループは安全にベクトル化を強制できます。
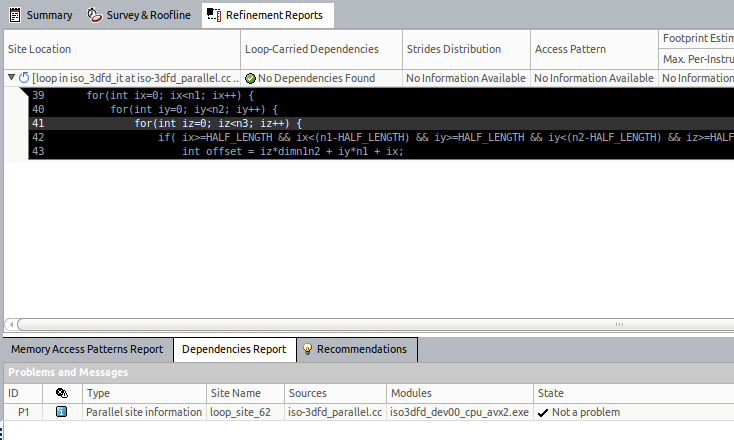
イメージをクリックして拡大表示
ベクトル化する
外部ループをベクトル化するには、ベクトル化するループの直前に次のディレクティブを追加します。
#pragma omp simd
注: このディレクティブを使用する場合、-qopenmp または -qopenmp-simd を指定してアプリケーションをコンパイルする必要があります。
コードは次のようになります。
void iso_3dfd_it(float *ptr_next, float *ptr_prev, float *ptr_vel, float *coeff,
const int n1, const int n2, const int n3, const int num_threads,
const int n1_Tblock, const int n2_Tblock, const int n3_Tblock){
int dimn1n2 = n1*n2;
for(int ix=HALF_LENGTH; ix<n1-HALF_LENGTH; ix++) {
for(int iy=HALF_LENGTH; iy<n2-HALF_LENGTH; iy++) {
#pragma omp simd
for(int iz=HALF_LENGTH; iz<n3-HALF_LENGTH; iz++) {
int offset = iz*dimn1n2 + iy*n1 + ix;
float value = 0.0;
value += ptr_prev[offset]*coeff[0];
for(int ir=1; ir<=HALF_LENGTH; ir++) {
value += coeff[ir] * (ptr_prev[offset + ir] + ptr_prev[offset - ir]);
value += coeff[ir] * (ptr_prev[offset + ir*n1] + ptr_prev[offset - ir*n1]);
value += coeff[ir] * (ptr_prev[offset + ir*dimn1n2] + ptr_prev[offset - ir*dimn1n2]);
}
ptr_next[offset] = 2.0f* ptr_prev[offset] - ptr_next[offset] + value*ptr_vel[offset];
}
}
}
}
最適化後のパフォーマンスを確認するには、コードをコンパイルしてルーフライン解析を再度実行します。
メモリーアクセスの向上
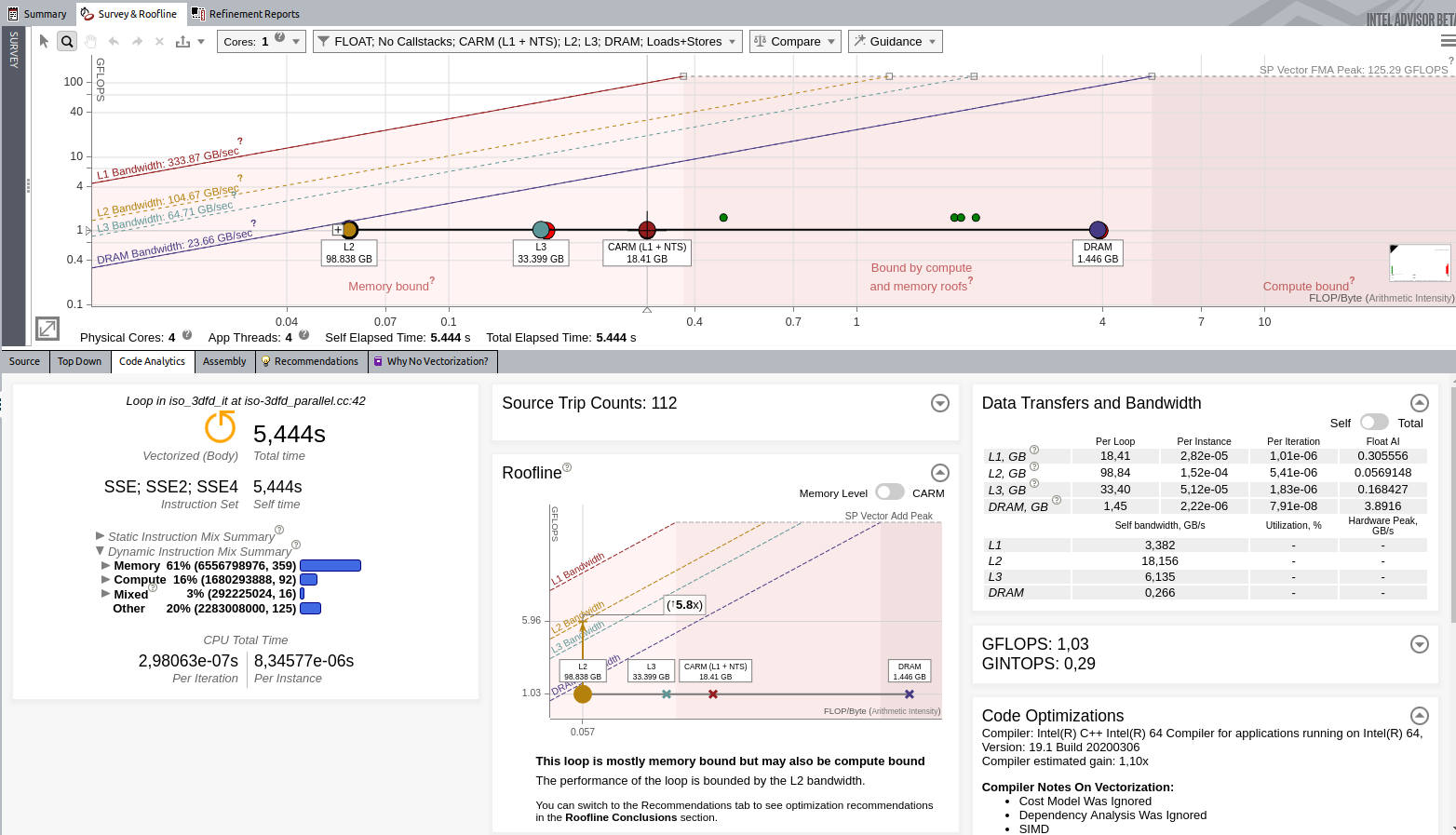
イメージをクリックして拡大表示
ルーフライン解析を再度実行すると、メインループがベクトル化され、ベースライン結果は 0.89GFLOP/秒でしたが、1.03GFLOP/秒に向上していることが分かります。
インテル® AVX2 は単精度で 8 倍 の潜在的なスピードアップを達成できることを考慮すると、この結果は十分ではないと言えます。
インテル® Advisor は、今回もメモリーの問題を報告しています。アプリケーションは L2 キャッシュによって制限されています。[Recommendation (推奨事項)] タブを開いて、コードのパフォーマンスを向上する最適化に関する推奨を確認します。今回は、インテル® Advisor はメモリー・アクセス・パターン解析の実行を推奨しています。

イメージをクリックして拡大表示
メモリー・アクセス・パターン解析を実行するには、次の操作を行います。
- [Survey (サーベイ)] レポートに移動します。
- メインのホットスポットを選択します。
- [Vectorization Workflow (ベクトル化ワークフロー)] タブの [Check Memory Access Patterns (メモリー・アクセス・パターンの確認)] の下にある [Collect] ボタンをクリックします。
この解析は、すべてのメモリーアクセスを監視してパターンを検出します。次の 4つのパターンを検出できます。
- Uniform stride (均一ストライド): 各反復で、ループ/関数は同じアドレスにアクセスします。
- Unit stride (ユニットストライド): メモリーセルは、メモリー内で連続した順序でアクセスされます。これはキャッシュの再利用を高めます。通常、このパターンになるようにすべきです。
- Constant stride (一定ストライド): 新しい反復ごとに、プログラムは一定のパディングで同じデータ構造にアクセスします。一般に、構造体配列モデルのデータ構造で見られるパターンです。できるだけこのパターンは避けて、ユニットストライドになるようにデータレイアウトを変更します。第 2 または第 3 配列の反復順序が正しくないことも、このパターンのもう 1 つの原因です。これはパフォーマンスの低下につながります。
- Random accesses (不規則なアクセス): これは良いメモリーアクセス方法ではありませんが、通常、回避するのが困難です。このパターンの原因の 1 つは、間接アドレス指定です。

イメージをクリックして拡大表示
この例では、インテル® Advisor は多くの一定ストライドを報告しています。3 つの一定ストライドが報告されている行から、反復が最適な順序で行われていないことが分かります。新しい反復ごとにアドレスを 1 つ増やすのが理想的です。つまり、ループ P9 は最内ループであるべきです。
次のようにループの順序を逆にして、アクセスの問題を解決します。
void iso_3dfd_it(float *ptr_next, float *ptr_prev, float *ptr_vel, float *coeff,
const int n1, const int n2, const int n3, const int num_threads,
const int n1_Tblock, const int n2_Tblock, const int n3_Tblock){
int dimn1n2 = n1*n2;
for(int iz=HALF_LENGTH; iz<n3-HALF_LENGTH; iz++) {
for(int iy=HALF_LENGTH; iy<n2-HALF_LENGTH; iy++) {
#pragma omp simd
for(int ix=HALF_LENGTH; ix<n1-HALF_LENGTH; ix++) {
int offset = iz*dimn1n2 + iy*n1 + ix;
float value = 0.0;
value += ptr_prev[offset]*coeff[0];
for(int ir=1; ir<=HALF_LENGTH; ir++) {
value += coeff[ir] * (ptr_prev[offset + ir] + ptr_prev[offset - ir]);
value += coeff[ir] * (ptr_prev[offset + ir*n1] + ptr_prev[offset - ir*n1]);
value += coeff[ir] * (ptr_prev[offset + ir*dimn1n2] + ptr_prev[offset - ir*dimn1n2]);
}
ptr_next[offset] = 2.0f* ptr_prev[offset] - ptr_next[offset] + value*ptr_vel[offset];
}
}
}
}
スレッド化の追加
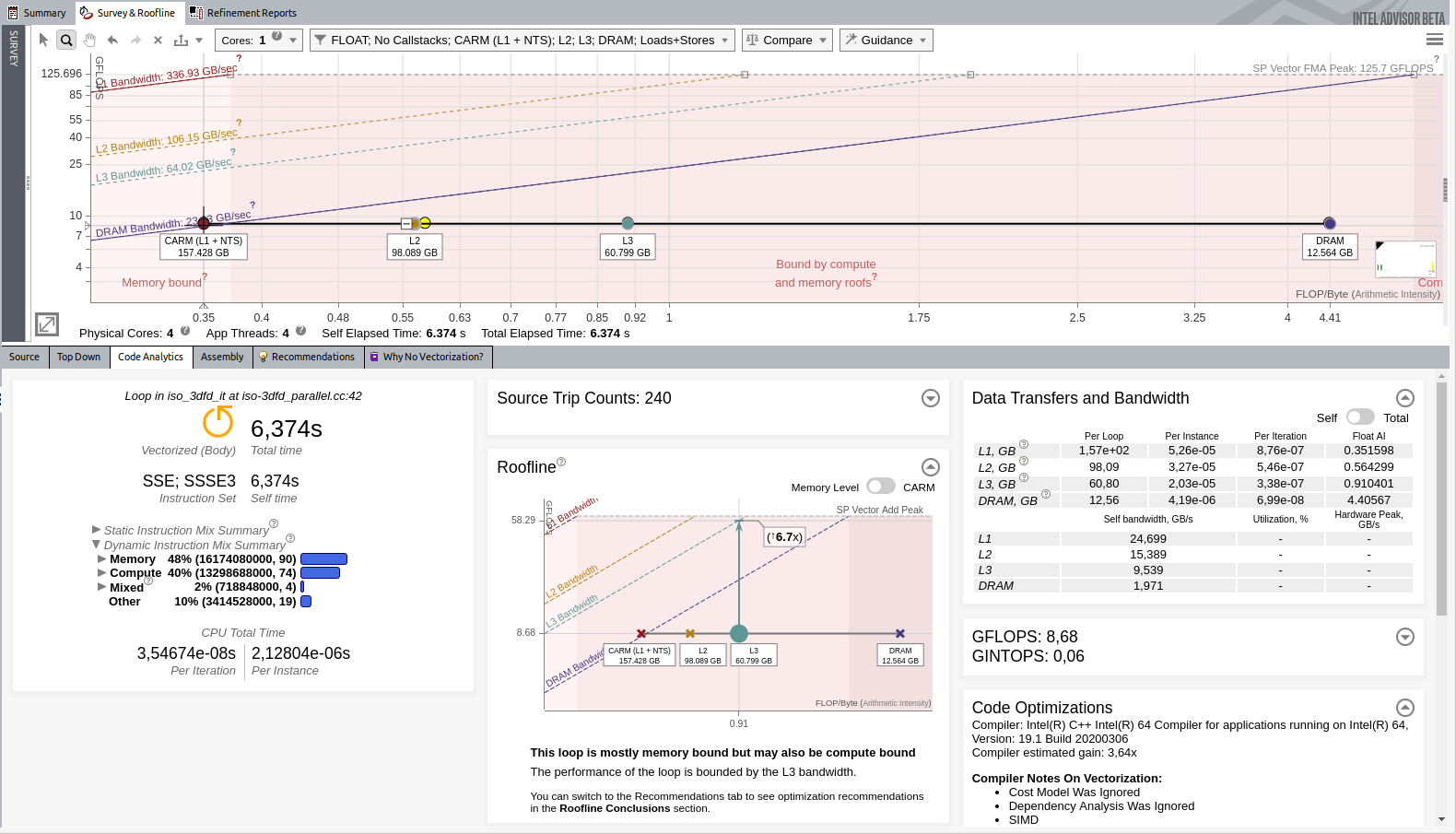
イメージをクリックして拡大表示
メモリー・アクセス・パターンの改善により、8.68GFLOP/秒になりました。L3 の制限により、潜在的なスピードアップは 6.7 倍です。この問題については後で対応します。アプリケーションがコアの処理能力を最大限に引き出せていないため、先に並列処理を実装します。
void iso_3dfd_it(float *ptr_next, float *ptr_prev, float *ptr_vel, float *coeff,
const int n1, const int n2, const int n3, const int num_threads,
const int n1_Tblock, const int n2_Tblock, const int n3_Tblock){
int dimn1n2 = n1*n2;
#pragma omp parallel for
for(int iz=HALF_LENGTH; iz<n3-HALF_LENGTH; iz++) {
for(int iy=HALF_LENGTH; iy<n2-HALF_LENGTH; iy++) {
#pragma omp simd
for(int ix=HALF_LENGTH; ix<n1-HALF_LENGTH; ix++) {
int offset = iz*dimn1n2 + iy*n1 + ix;
float value = 0.0;
value += ptr_prev[offset]*coeff[0];
for(int ir=1; ir<=HALF_LENGTH; ir++) {
value += coeff[ir] * (ptr_prev[offset + ir] + ptr_prev[offset - ir]);
value += coeff[ir] * (ptr_prev[offset + ir*n1] + ptr_prev[offset - ir*n1]);
value += coeff[ir] * (ptr_prev[offset + ir*dimn1n2] + ptr_prev[offset - ir*dimn1n2]);
}
ptr_next[offset] = 2.0f* ptr_prev[offset] - ptr_next[offset] + value*ptr_vel[offset];
}
}
}
}
キャッシュの再利用の最適化
この最適化バージョンでルーフライン解析を再度実行します。
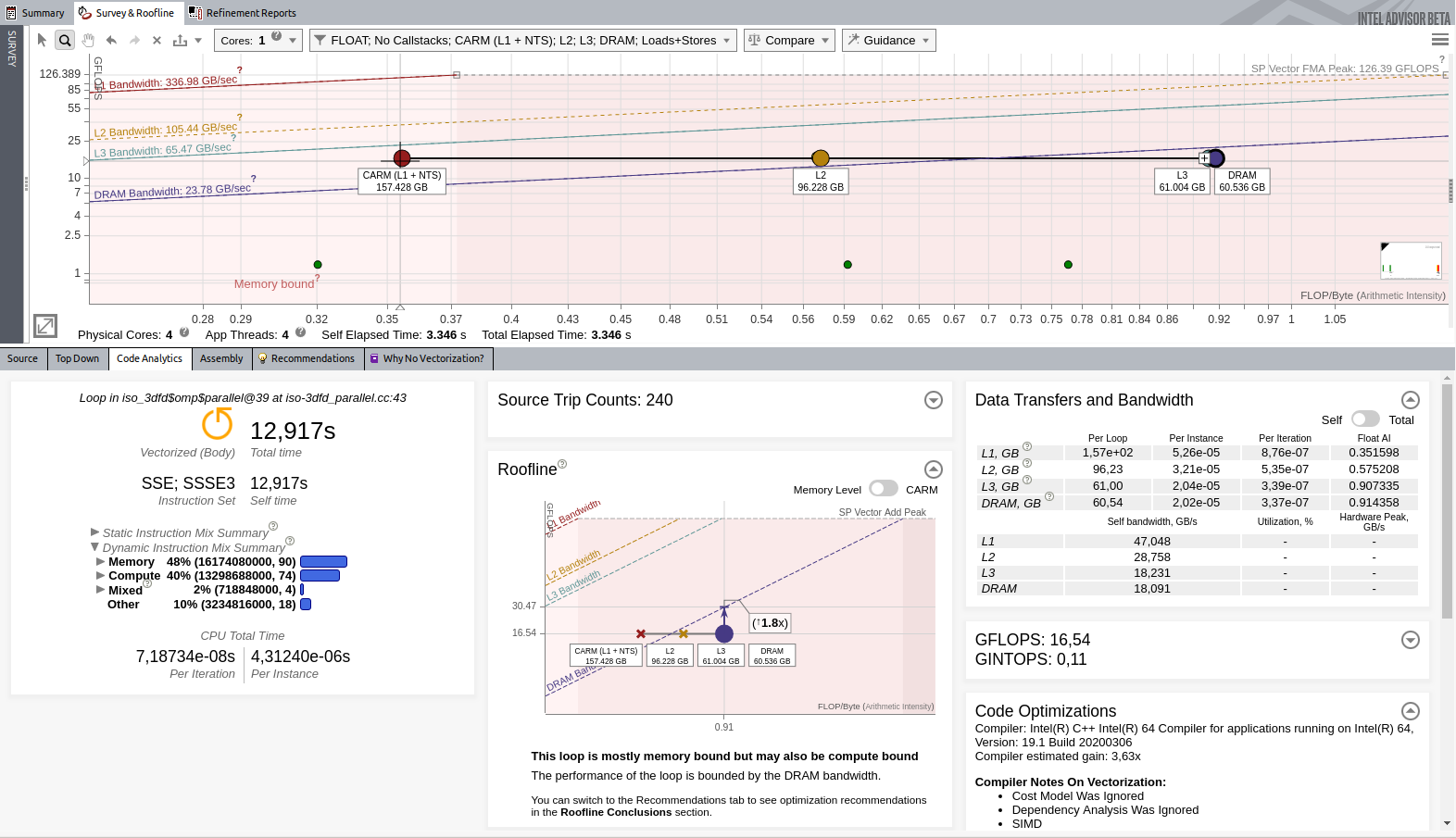
イメージをクリックして拡大表示
スレッド化したことで、パフォーマンスが 8.68GFLOP/秒から 16.54GFLOP/秒に向上しました。アプリケーションは 4 つの物理コアを搭載したマシンで実行されましたが、約 2 倍のスピードアップしか達成できませんでした。これは、パフォーマンスを制限する要因がほかにもあることを意味します。ルーフライン・レポートから、ループは DRAM ルーフラインに非常に近いことが分かります。
つまり、ループは DRAM との間のデータ・ストリーミングに時間を費やしています。インテル® Advisor は、キャッシュ効率の向上を推奨しています。次のように、キャッシュ・ブロッキングを行い、キャッシュ効率を向上します。
void iso_3dfd_it(float *ptr_next, float *ptr_prev, float *ptr_vel, float *coeff,
const int n1, const int n2, const int n3, const int num_threads,
const int n1_Tblock, const int n2_Tblock, const int n3_Tblock){
int dimn1n2 = n1*n2;
#pragma omp parallel for
for(int cbZ=HALF_LENGTH; cbZ<n3-HALF_LENGTH; cbZ+=n3_Tblock){
for(int cbY=HALF_LENGTH; cbY<n2-HALF_LENGTH; cbY+=n2_Tblock){
for(int cbX=HALF_LENGTH; cbX<n1-HALF_LENGTH; cbX+=n1_Tblock){
int izend = (cbZ + n3_Tblock) > n3-HALF_LENGTH ? n3-HALF_LENGTH : cbZ + n3_Tblock;
int iyend = (cbY + n2_Tblock) > n2-HALF_LENGTH ? n2-HALF_LENGTH : cbY + n2_Tblock;
int ixend = (cbX + n1_Tblock) > n1-HALF_LENGTH ? n1-HALF_LENGTH : cbX + n1_Tblock;
for(int iz=cbZ; iz<izend; iz++) {
for(int iy=cbY; iy<iyend; iy++) {
#pragma omp simd
for(int ix=cbX; ix<ixend; ix++) {
int offset = iz*dimn1n2 + iy*n1 + ix;
float value = 0.0;
value += ptr_prev[offset]*coeff[0];
for(int ir=1; ir<=HALF_LENGTH; ir++) {
value += coeff[ir] * (ptr_prev[offset + ir] + ptr_prev[offset - ir]);
value += coeff[ir] * (ptr_prev[offset + ir*n1] + ptr_prev[offset - ir*n1]);
value += coeff[ir] * (ptr_prev[offset + ir*dimn1n2] + ptr_prev[offset - ir*dimn1n2]);
}
ptr_next[offset] = 2.0f* ptr_prev[offset] - ptr_next[offset] + value*ptr_vel[offset];
}
}
}
}
}
}
}
最適なスピードを達成するには、cbZ=16、cbY=2、および cbX=[whole dimension] に設定します。
ルーフライン解析を再度実行して、最適化を適用後のパフォーマンスを評価します。次のような結果になります。
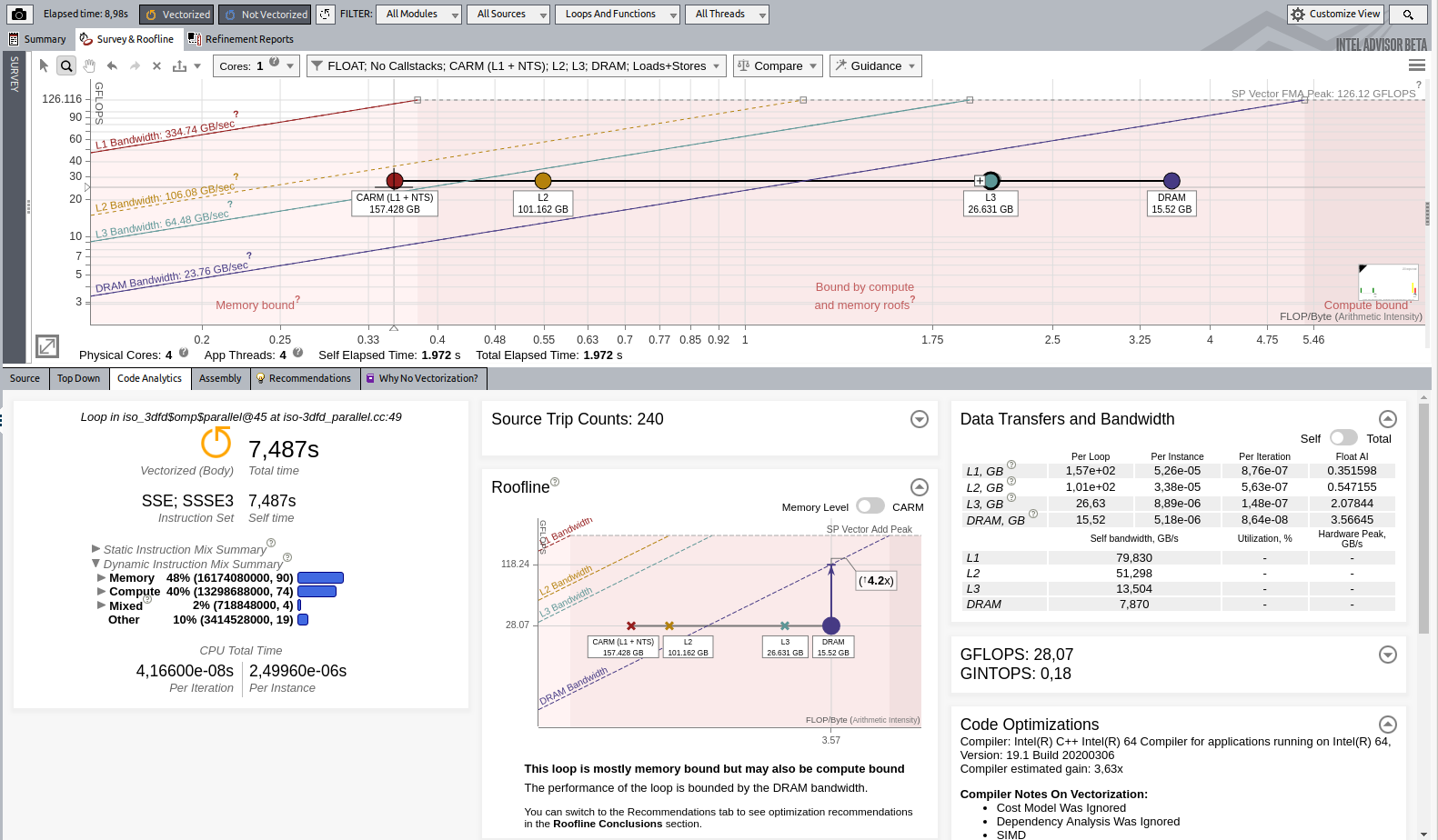
イメージをクリックして拡大表示
最終的な結果は 28.07 GFLOP/秒になりました。
ルーフライン結果の比較
インテル® Advisor では、ルーフライン・レポートを比較できます。最後の 2 つのレポートを比較すると、興味深い情報が得られます。
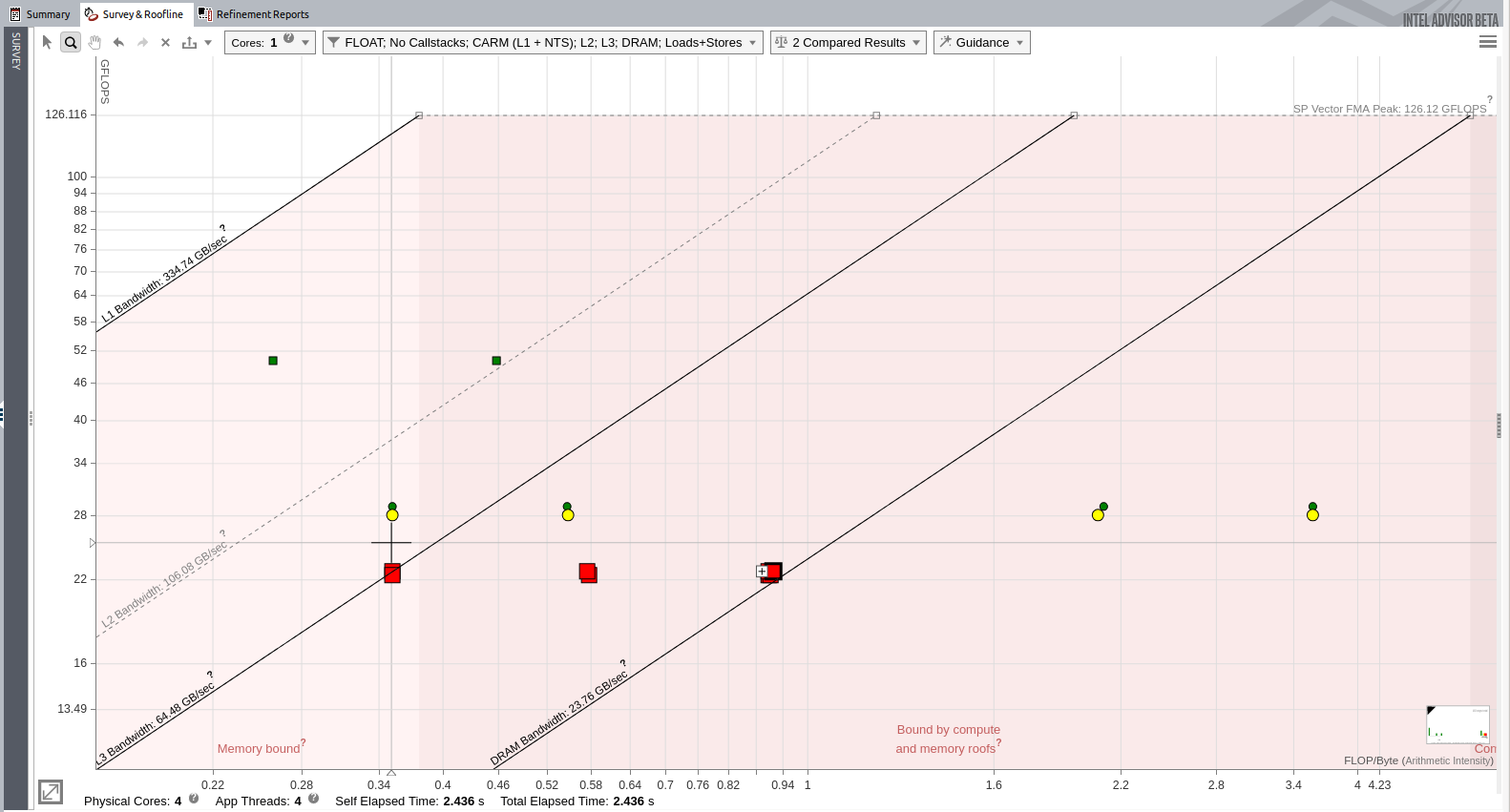
イメージをクリックして拡大表示
ドットはキャッシュ・ブロッキングを追加した最後のバージョンを示し、四角はその前のスレッド化後のバージョンを示します。キャッシュ・ブロッキングにより L3 ドットと DRAM ドットが右に移動して、スピードアップの余地が増えたことが分かります。
まとめ
この記事では、インテル® Advisor を使用してアプリケーションを最適化し、パフォーマンスを 0.89GFLOP/秒から 28GFLOP/秒に向上しました。ハードウェアの知識がなくても、推奨に従うことでコードのパフォーマンスを大幅に向上できます。ルーフライン・モデルは、アプリケーションの問題の理解に役立つ多くの利点を提供します。最適化した最終バージョンでは、マシンのピーク性能に非常に近いことが分かります。次の最適化ステップでは、小さなゲインを得るために多くの労力が必要になるかもしれません。
製品とパフォーマンス情報
1 インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。
注意事項の改訂 #20110804
