

この記事は、インテルの The Parallel Universe Magazine 27 号に収録されている、インテル® コンパイラーでインテル® AVX-512 命令セットを利用してループをベクトル化し、スピードアップするさまざまな例に関する章を抜粋翻訳したものです。
編集者から: 前号の The Parallel Universe では、インテル® Parallel Studio XE 2017 のベクトル化サポートについて取り上げました。今号では、Martyn Corden が、インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) 命令についてさらに詳しく取り上げ、以前は不可能だったベクトル化を開発者が利用する方法を説明します。
クロック速度を上げるだけで簡単にパフォーマンスを向上できる時代は遠い過去のものとなりました。ムーアの法則は、代わりに、追加のコアと SIMD レジスターの帯域幅の増加による並列処理の向上に適用されます。インテル® AVX-512 (英語) では、SIMD ベクトル幅が 512 ビットに拡張され、以前の命令セットではベクトル化できなかったループのベクトル化や、より効率的なベクトル化を行うことができる新しい命令が含まれています。
この記事では、潜在的なアドレス競合の問題がある、配列を圧縮/ 展開するループや、ヒストグラムの生成とスキャッターを実行するループを、インテル® C/C++ コンパイラーおよびインテル® Fortran コンパイラーでベクトル化してスピードアップする方法を、例とともに説明します。さらに、構造体配列の特定のループ形式について、コンパイラーでストライドロードやギャザーをより効率的なユニットストライド方式の SIMD ロードに変換する方法を説明します。最後に、インテル® Parallel Studio XE 2017 に含まれるインテル® コンパイラー 17.0 の最適化レポートの新しい機能を使用して、この変換を認識する方法を説明します。これらの最適化は、インテル® Xeon Phi™ プロセッサー x200 製品ファミリーだけでなく、インテル® AVX-512 命令セットをサポートする将来のインテル® Xeon® プロセッサーで動作するさまざまなアプリケーションにも役立ちます。
ベクトル化の利点
図 1 は、単純な倍精度浮動小数点ループを示しています。スカラーモードでは、1 つの命令で 1 つの結果が生成されます。ベクトル化を行うと、1 つのインテル® AVX-512 命令で 8 つ (インテル® AVX では 4 つ、インテル® ストリーミング SIMD 拡張命令 (インテル® SSE) では 2 つ) の結果が生成されます。インテル® Xeon Phi™ プロセッサー x200 製品ファミリーは、32 ビットおよび 64 ビットの整数と浮動小数点データを扱うさまざまな演算でインテル® AVX-512 命令をサポートします。将来のインテル® Xeon® プロセッサーでは、8 ビットおよび 16 ビット整数にも対応する予定です。
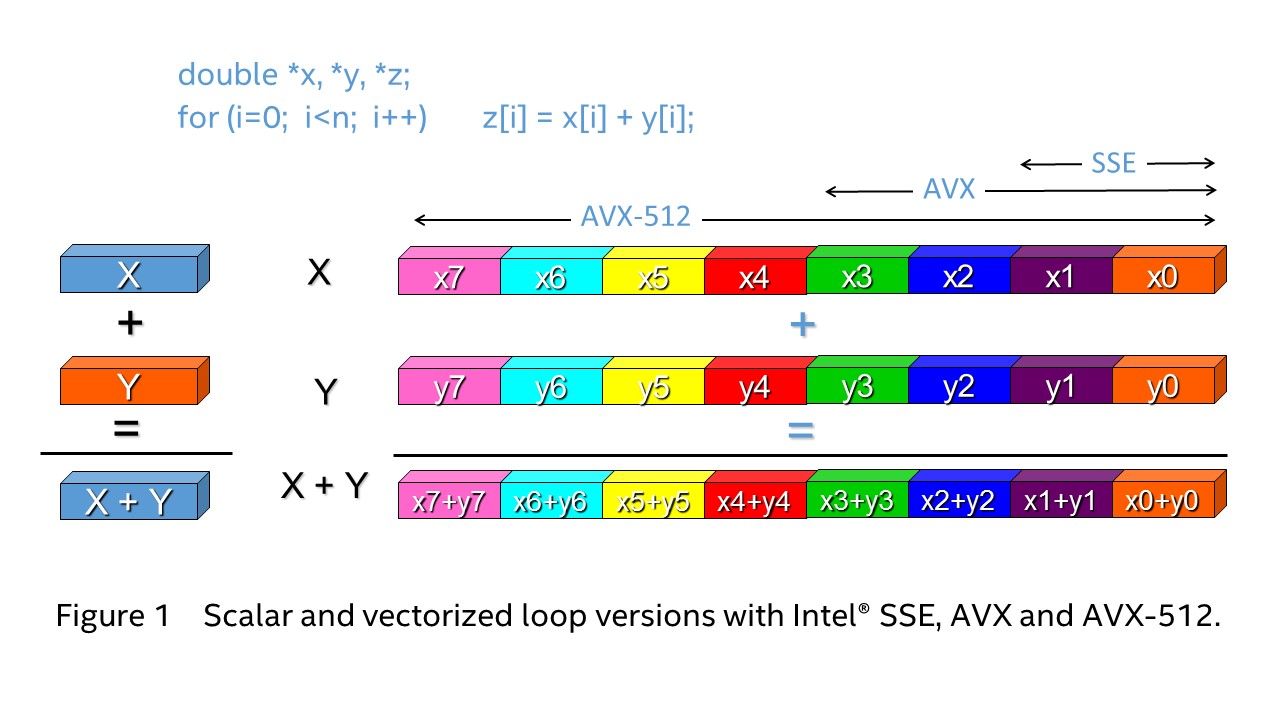
図 1. スカラーおよびインテル® SSE、インテル® AVX、インテル® AVX-512 でベクトル化したループ
インテル® コンパイラーは、デフォルトで自動ベクトル化を有効にしますが、インテル® AVX-512 命令をターゲットにするには、図 2 のいずれかのコンパイラー・オプションを指定する必要があります。
| Linux* および OS X* | Windows® | ターゲット |
|---|---|---|
-xmic-avx512 |
/Qxmic-avx512 |
インテル® Xeon Phi™ プロセッサー x200 製品 ファミリー |
-xcore-avx512 |
/Qxcore-avx512 |
将来のインテル® Xeon® プロセッサー |
-xcommon-avx512 |
/Qxcommon-avx512 |
両方に共通のインテル® AVX-512 のサブセット。 ファットバイナリーではありません。 |
-axmic-avx512 |
/Qaxmic-avx512 |
インテル® Xeon Phi™ プロセッサー x200 製品 ファミリーおよびインテル® Xeon® プロセッサー。 ファットバイナリーです。 |
-xhost |
/Qxhost |
コンパイルを行うホストマシンに搭載される プロセッサー |
表 1. インテル® AVX-512 命令を有効にするコンパイラー・オプション
ループの圧縮と展開
図 2A の Fortran の例は、配列を圧縮します。大きなソース配列から条件を満たす要素のみ、小さなターゲット配列にコピーされます。図 2B の C の例は、逆の操作 (つまり、配列の展開) を行います。小さなソース配列の要素が大きなスパース配列にコピーされます。
nb = 0
do ia=1, na ! 行 23
if (a(ia) > 0.) then
nb = nb + 1 ! 依存関係
b(nb) = a(ia) ! 圧縮
endif
enddo
|
int j = 0
for (int i=0; i < N; i++) {
if (a[i] > 0) {
c[i] = a[k++]; // 展開
}
}
// j と k の繰り返し間の依存関係
|
| 図 2A. 配列の圧縮 | 図 2B. 配列の展開 |
密配列インデックスの条件付きインクリメントを行うと、ループ反復間の依存関係が発生します。以前は、この依存関係が自動ベクトル化を妨げていました。例えば、インテル® AVX2 向けに図 2A のループをコンパイルすると、次のような最適化レポートが表示されます。
ifort -c -xcore-avx2 -qopt-report-file=stderr -qopt-report=3 compress.f90
…
ループの開始 compress.f90(23,3)
リマーク #15344: ループはベクトル化されませんでした: ベクトル依存関係がベクトル化を妨げています。
リマーク #15346: ベクトル依存関係: ANTI の依存関係が nb (25:7) と nb (25:7) の間に仮定されました。
ループの終了
図 2B の C の例も同じようなレポートが出力されます。依存関係により不正な結果が引き起こされる可能性があるため、OpenMP* SIMD ディレクティブは使用できません。
インテル® AVX-512 では、1 つの SIMD レジスターの特定の要素を別の SIMD レジスターの連続する要素またはメモリーに書き込む新しい vcompress 命令により、この依存関係の制約を解消しました。同様に、vexpand 命令は、ソースレジスターまたはメモリーの連続する要素をディスネーション SIMD レジスターの特定の (スパース) 要素に書き込みます。これらの新しい命令により、インテル® AVX-512 が有効な場合、コンパイラーは圧縮の例 (図 2A) をベクトル化することができます。
ifort -c -xmic-avx512 -qopt-report-file=stderr -qopt-report=3 compress.f90
…
ループの開始 compress.f90(23,3)
リマーク #15300: ループがベクトル化されました。
リマーク #15450: マスクなし非アライン・ユニット・ストライド・ロード: 1
リマーク #15457: マスク付き非アライン・ユニット・ストライド・ストア: 1
…
リマーク #15497: ベクトル圧縮: 1
ループの終了
図 3. インテル® AVX-512 を有効にした場合の配列の圧縮
ソース配列のすべての要素がロードされるため、ロードはマスクなしです。選択された要素のみストアされるため、有効なストアはマスク付きです。最適化レポートのリマーク #15497 は、圧縮表現が認識されベクトル化されたことを示しています。-S オプションを指定して取得できるアセンブリー・リストには、次のような命令が表示されます。
vcompressps %zmm4, -4(%rsi,%rdx,4){%k1}
図 2B の配列展開ループについても同様の結果が得られます。
1,000,000 の乱数を含む単精度配列を 1/2 に圧縮する操作をインテル® Xeon Phi™ プロセッサー 7250 で 1000 回繰り返した結果、インテル® AVX-512 はインテル® AVX2 よりも約 16 倍高速でした。このスピードアップは SIMD レジスターと命令の幅の違いによるものと言えます。
