

この記事は、インテルの The Parallel Universe Magazine 27 号に収録されている、NUMA 向けの最適化を行う開発者必見の章を抜粋翻訳したものです。
システムの計算コア数が増え続ける中、効率良く並列化されたソフトウェアでは、コア数の増加に伴ってパフォーマンスが直線的に向上することが望まれます。しかし、いくつかの要因により、マルチコアシステムの並列性とスケーラビリティーが妨げられることが分かっています。この記事では、ほとんどのケースで原因となる、並列処理の実装について取り上げます。
- ロードインバランスにより、スレッドと CPU コアがアイドル状態になります。
- 過度の同期により、スピン待機やその他の非生産的なワークに CPU 時間が費やされます。
- 並列ランタイム・ライブラリーのオーバーヘッドが、適切でないライブラリー API の使用により発生します。
これらの要因を排除することで、並列処理の効率が大幅に向上し、すべての CPU コアが有用なワークを実行するためビジー状態になります。STREAM や LINPACK のような最適なチューニングが行われているベンチマークでは、ほぼ直線的なスピードアップを達成できます。しかし、システムのコア数の増加に伴い (または、コア数の多い新しいシステムでコードを実行した場合に)、アプリケーションのパフォーマンスが線形に向上しなかったり、並列パフォーマンスが伸び悩むことがあります (図 1)。
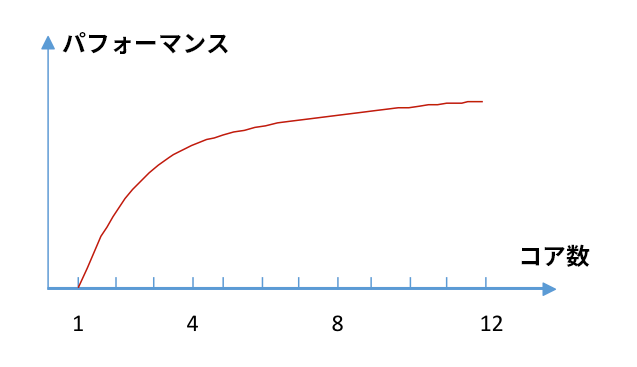
図 1. コア数とパフォーマンスの変化
トップダウンのパフォーマンス解析アプローチ1 では、最初にほかのコンポーネントによりパフォーマンスが妨げられていないかチェックすべきです。次のことを確認します。
- ほかのプロセスによってシステムが常にビジー状態でない: リソースを消費するほかのアプリケーションやサービスに計算時間が費やされていることがあります。
- アプリケーションがシステムの I/O に依存していない: 例えば、ディスク、ほかのファイルシステム、ネットワーク・システムの処理が完了するのを待っていないか確認します。
- システムに十分な物理メモリー容量がある: ハードディスク・ドライブとのスワップが頻発するのを防ぎます。
一般に、ハードウェアが適切に構成され、メモリー・サブシステムが想定するパフォーマンス特性を提供しているかどうか把握しておくと良いでしょう。例えば、すべてのメモリースロットにマザーボードの特性 (チャネル数、メモリー速度など) に対応した DIMM が搭載されている場合、一般的なベンチマークを使用してハードウェアのパフォーマンスを簡単にチェックできます。問題の修正は、ソフトウェアを最適化するよりもハードウェアで行ったほうが容易なため、このようなチェックを行うことが重要です。
これらのチェックが終わったら、並列処理がスケーリングしない主な原因の 1 つであるメモリー・レイテンシーを確認します。x86 システム・アーキテクチャーでは、CPU はキャッシュ・サブシステムからデータを読み取ります。命令で必要なときに、CPU に最も近いキャッシュ (L1 データキャッシュ) にデータがあることが理想的です (図 2)。要求されたデータが CPU から離れた場所にある場合、データが CPU コアの実行ユニットに到達するのに長い時間がかかります。CPU ハードウェア・プリフェッチャーは、迅速にデータを取得できるように支援しますが、常に適切に動作するとは限りません。データの遅延はよくあることで、CPU のストールを引き起こします。2
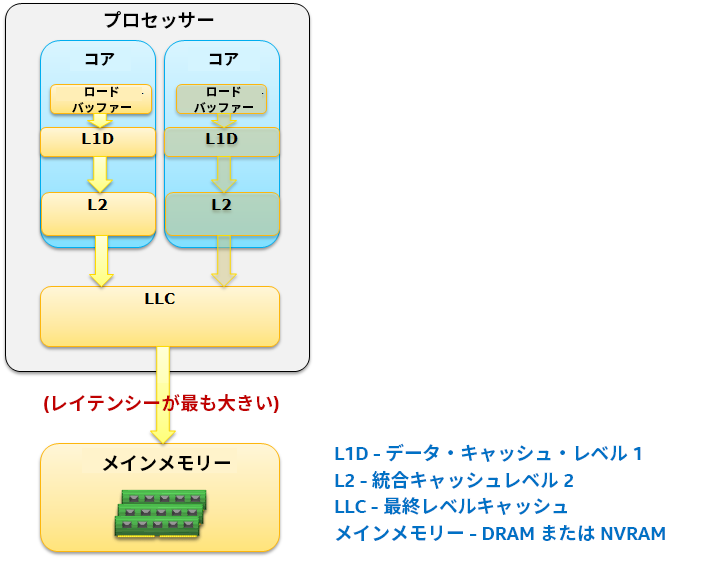
図 2. メモリー・サブシステムからのデータの読み取り
基本的に、データが遅延する理由は 2 つあります。
- CPU の実行ユニットで実行される命令がデータを要求し、プリフェッチャーが適切に動作しない場合、メインメモリーやほかのキャッシュから CPU の L1D にデータが読み込まれます。これにより、メモリー・レイテンシーの問題が生じます。
- プリフェッチャーが適切に動作し、データが事前に要求されても、転送インフラストラクチャーの処理能力が原因で CPU への転送が遅れることがあります。この場合、メモリー帯域幅の問題が生じます。
複数のソースから複数の要求があった場合、両方の問題が発生する可能性があります。これらの問題を回避するには、データを上手く利用することが重要です。メモリー・レイテンシーの問題を解決するには、アドレスを使用してインクリメンタルにデータにアクセスします。シーケンシャル・データ・アクセス (または一定の短い距離のユニットストライド) を使用すると、プリフェッチャーによって適切に処理され、迅速にデータにアクセスできます。メモリー帯域幅の問題を解決するには、データを再利用し、できる限りキャッシュに保持するようにします。そのためには、データ・アクセス・パターンの見直しや、場合によってはアルゴリズム全体の実装の見直しが必要になります。
