
この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「Core Utilization in DPDK Apps」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピは、DPDK ベースのアプリケーションにおけるパケット受信のコア使用率を特徴付けるメトリックを調査します。
コンテンツ・エキスパート: Ilia Kurakin (英語)、Roman Khatko (英語)
高速なパケット処理が求められるデータ・プレーン・アプリケーションでは、DPDK は特定の論理コアにピニングされた無限ループでパケットを受信するため特定のポートをポーリングします。このようなパケット受信ポーリングモデルは、有効なコア使用率を測定する上で課題となります。ポーリングループを実行するコアの CPU 時間は、DPDK がアイドルのループサイクル数に関係なく、常に 100% 近くになります。そのため、CPU 時間からパケット受信のコア使用率は分かりません。しかし、このポーリングモデルでは、[Rx Spin Time – % of wasted polling loop cycles (Rx スピン時間 – 無駄なポーリング・ループ・サイクルの %)] からコア使用率が分かります。Wasted Cycles (無駄なサイクル) とは、DPDK がパケットを受信しなかった反復を指します。
このレシピは、次のステップに従って、DPDK ベースのワークロードでパケット受信の効率を解析します。
- 使用するもの
- 手順:
使用するもの
- アプリケーション: シングルコアで L2 フォワーディングを実行する DPDK testpmd アプリケーション。インテル® VTune™ Amplifier のプロファイル・サポートが有効な DPDK でコンパイルされています。
- ツール:
- インテル® VTune™ Amplifier のプロファイル・サポートが有効な DPDK。インテル® VTune™ Amplifier 18.11 以降では、プロファイル・サポートが DPDK に統合されます。それよりも古いバージョンを使用する場合、パッチ (17.11、18.02、および 18.05 で利用可能) を適用してください。DPDK でプロファイルを有効にするには、インテル® VTune™ Amplifier が DPDK ポーリングサイクルにアタッチするように、(config/common_base config ファイルで)
CONFIG_RTE_ETHDEV_RXTX_CALLBACKS フラグと CONFIG_RTE_ETHDEV_PROFILE_WITH_VTUNE フラグを有効にして、DPDK (とターゲット・アプリケーション) を再構成し再コンパイルします。 - インテル® VTune™ Amplifier 2019: 入力と出力解析
注
- インテル® VTune™ プロファイラー評価版のダウンロードと製品サポートについては、https://www.isus.jp/intel-vtune-amplifier-xe/ を参照してください。
- このクックブックのレシピはすべてスケーラブルであり、インテル® VTune™ Amplifier 2018 以降に適用できます。バージョンにより設定がわずかに異なることがあります。
- ベータ版インテル® oneAPI ベース・ツールキット向けのバージョンから、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。引き続き、インテル® Parallel Studio XE またはインテル® System Studio のコンポーネントとして、あるいはスタンドアロン版のインテル® VTune™ プロファイラーをご利用いただけます。
- インテル® VTune™ Amplifier のプロファイル・サポートが有効な DPDK。インテル® VTune™ Amplifier 18.11 以降では、プロファイル・サポートが DPDK に統合されます。それよりも古いバージョンを使用する場合、パッチ (17.11、18.02、および 18.05 で利用可能) を適用してください。DPDK でプロファイルを有効にするには、インテル® VTune™ Amplifier が DPDK ポーリングサイクルにアタッチするように、(config/common_base config ファイルで)
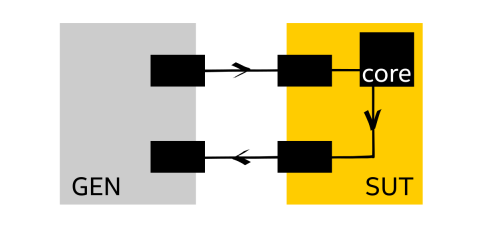
- オペレーティング・システム: 40GbE リンクを介して接続された、64 バイトのフレームを生成するトラフィック・ジェネレーター (以下の図では GEN) とパケットレシーバー (SUT: System Under Test) で構成されたテストシステム。SUT はパケットの L2 フォワーディングを実行します。
- CPU: インテル® Xeon® Platinum 8180 プロセッサー (38.5MB キャッシュ、2.50GHz、28 コア)
入力と出力解析を実行する
DPDK 解析では、インテル® VTune™ Amplifier GUI で入力と出力解析を選択し、[DPDK IO API] を有効にします。
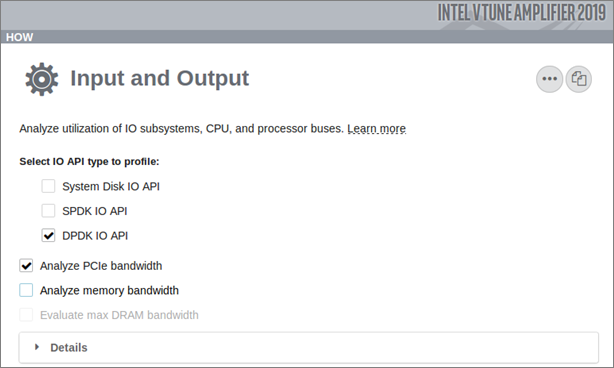
DPDK Rx Spin Time (DPDK Rx スピン時間) などの API 固有メトリックとハードウェア・イベントやハードウェア・イベントベース・メトリックを関連付けることができます。例えば、DPDK Rx スピン時間と [Analyze PCIe bandwidth (PCIe* 帯域幅を解析)] が有効な場合に収集される PCIe* 帯域幅の間には依存関係があります。
コマンドラインから入力と出力解析を実行して PCIe* 帯域幅と DPDK メトリックを取得するには、解読可能な名前でデバイスごとの PCIe* 帯域幅を取得できるように、root 権限で次のコマンドを実行します。
amplxe-cl -collect io -knob kernel-stack=false -knob dpdk=true -knob collect-pcie-bandwidth=true -knob collect-memory-bandwidth=false -knob dram-bandwidth-limits=false --target-process=testpmd
DPDK Rx スピン時間メトリックを使用してコア使用率を解析する
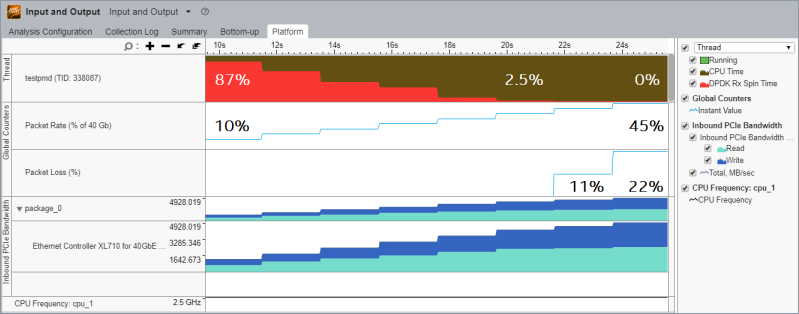
データが収集されたら、[Platform (プラットフォーム)] タブから始め、スレッドの [DPDK Rx Spin Time (DPDK Rx スピン時間)] オーバータイム・メトリックを調査します。このメトリックは、ゼロパケット返す rte_eth_rx_burst(…) 関数呼び出しの割合を (スレッドごとに) 示します。これは、パケットを提供しないポーリングループ反復の割合と同じです。
![]()
注
ここで紹介した結果は合成されたものです。
上記の [Platform (プラットフォーム)] ビューでは、ポーリングスレッドの [CPU Time (CPU 時間)] (茶色) は常に 100% 近くです。[DPDK Rx Spin Time (DPDK Rx スピン時間)] (赤色) は、パケット受信のスレッド使用率です。マウスでグラフをポイントすると、その時点の値がツールヒントに表示されます。
この例では、トラフィック・ジェネレーターを自動化して、2 秒ごとに 40Gbps の 5% ずつトラフィック・レートを増やしてパケット損失データを収集しました。適切にフォーマットされた *.csv ファイル形式のオーバータイム・データは、インテル® VTune™ Amplifier プロジェクトにインポート (英語) してタイムラインに表示できます。
デフォルトでは、インテル® VTune™ Amplifier は上記の [Global Counters (グローバルカウンター)] セクションに表示されている [Packet Rate (パケットレート)] メトリックと [Packet Loss (パケット損失)] メトリックを収集できません。このレシピでは、これらのメトリックは別途収集され、インテル® VTune™ Amplifier によって収集された結果に手動でインポートされました。別の方法として、インテル® VTune™ Amplifier のカスタムコレクター (英語) 機能を使用して追加のメトリックを含む csv ファイルをインポートできます。カスタムコレクターは、収集の開始/停止/一時停止時にインテル® VTune™ Amplifier によって実行される追加のプロセスです。カスタムコレクターを使用して、すべてのシステム自動化を実装し、追加のメトリックを収集できます。これにより、実験が再現可能となり、結果を比較できるようになります。これは、パフォーマンス・チューニングに役立ちます。
[Platform (プラットフォーム)] ビューの下部では、タイムラインで [Inbound PCIe Bandwidth (インバウンド PCIe* 帯域幅)] の変化を確認できます。この解析はインテル® マイクロアーキテクチャー (開発コード名 Skylake) 上で root 権限で実行されたため、PCIe* 帯域幅が PCIe* デバイス別に人間が解読できる名前で表示されています。
上記の入力と出力解析の [Platform (プラットフォーム)] ビューでは、すべてのメトリックに相関性があります。トラフィック生成レートが上昇すると、[Inbound PCIe Bandwidth (インバウンド PCIe* 帯域幅)] は増加し、[DPDK Rx Spin Time (DPDK Rx スピン時間)] は減少します。ある時点で、テストシステムはオーバーロードとなり、非ゼロの [Packet Loss (パケット損失)] 値が見られるようになります。
注
スレッドが複数の Rx キューを処理する場合、[DPDK Rx Spin Time (DPDK Rx スピン時間)] メトリックは複合統計を表します。
DPDK Rx バッチ統計ヒストグラムを使用してパケット受信を解析する
DPDK は、rte_eth_rx_burst(…) 関数を使用して NIC からパケットのバッチを受け取ります。区間 (0, MAX_NB_PKTS) の任意の数のパケットを受信できます。ここで、MAX_NB_PKTS は定数値 (通常 32) です。したがって、固定の [Rx Spin Time (Rx スピン時間)] では、コアのトラフィック処理量が大きく異なる可能性があるため、[Rx Spin Time (Rx スピン時間)] は全体像を表していません。
パケット受信のサマリー統計を表示し、Rx のコア使用率を完全に把握するには、[Summary (サマリー)] タブに切り替えて、[DPDK Rx Batch Statistics (DPDK Rx バッチ統計)] ヒストグラムを調査します。
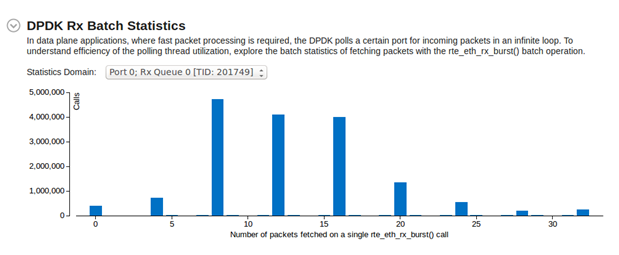
ヒストグラムは、選択した [Port / Rx Queue / TID (ポート/Rx キュー/TID)] グループの受信バッチパケットに関する統計を表します。この例では、すべてのピークが 4 の倍数の値を示しています。これは偶然ではなく、根本的な原因を調査するにはパケット受信の背景を理解する必要があります。
Rx 操作を理解して Rx ピークを調査する
パケットを受信するため、実行コアは Rx 記述子を介して NIC と通信します。Rx 記述子は、アドレスやサイズなどパケットに関する情報を保持するデータ構造で、Rx キューと呼ばれるリングバッファーに結合されます。簡単に言えば、パケット受信はリングバッファー内のレースであり、NIC はリングバッファーの [Head (先頭)] に Rx 記述子を追加し、実行コアは [Tail (末尾)] から Rx 記述子をポーリング、処理、そして解放します。
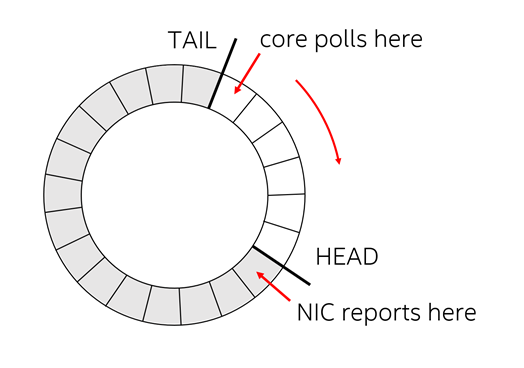
コアは Rx 記述子を解放すると、Tail ポインターを前方に移動します。Tail が Head に到達すると、rte_eth_rx_burst() は 0 パケットを返します。逆に、Head が Tail に到達すると、Rx キューに利用可能な Rx 記述子がなく、パケット損失が発生する可能性があります。
新しいパケットを提供するため、NIC は Rx キューの Head にある Rx 記述子を読み取り、記述子のコアで指定されたメモリーアドレスにパケットを転送します。そして、Rx 記述子を書き戻して、コアに新しいパケットの到着を通知する必要があります。
このレシピのセットアップに使用したインテル® イーサネット・コントローラー XL710 シリーズは、16 バイトと 32 バイトの Rx 記述子をサポートします。どちらもキャッシュラインのサイズよりも小さいため、NIC は PCIe* 帯域幅を抑えるため整数のキャッシュラインへ Rx 記述子をパックして書き込みをまとめる、記述子の書き戻しポリシーを採用しています。主に、インテル® イーサネット・コントローラー XL710 シリーズは、次の条件を満たす場合、完了した Rx 記述子を書き戻します。
- 4 x 32 バイト の記述子または 8 x 16 バイトの記述子が完了した場合
- 内部 NIC キャッシュで記述子が無効にされた場合
詳細は、インテル® イーサネット・コントローラー X710/XXV710/XL710 シリーズのデータシート (英語) を参照してください。
このレシピでは、システムが 32 バイトの Rx 記述子を使用しているため、[DPDK Rx Batch Statistics (DPDK Rx バッチ統計)] のほとんどのピークは 4 の倍数になっています。
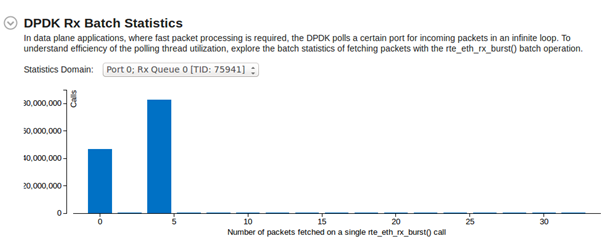
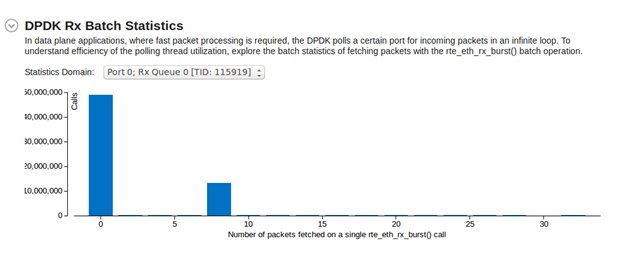
DPDK では Rx 記述子のサイズを切り替えることができます。以下は、testpmd を 32 バイトと 16 バイトの Rx 記述子を使用して中程度の負荷で実行した場合の [DPDK Rx Batch Statistics (DPDK Rx バッチ統計)] の変化です。
- 32 バイトの Rx 記述子: ほとんどの rte_eth_rx_burst() 呼び出しは 4 パケットを受け取ります。
- 16 バイトの Rx 記述子: ほとんどの rte_eth_rx_burst() 呼び出しは 8 パケットを受け取ります。
関連情報
- DPDK アプリケーションの PCIe*トラフィック
- カスタムコレクターの使用 (英語)
- 外部データを含む CSV ファイルの作成 (英語)
- 外部データのインポート (英語)
