
この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「Processor Cores Underutilization: OpenMP* Serial Time」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピは、OpenMP* で並列化されたアプリケーションのシリアル実行部分を特定し、追加の並列化の機会を見つけ、アプリケーションのスケーラビリティーを向上します。
コンテンツ・エキスパート: Dmitry Prohorov (英語)
並列アプリケーションのシリアル時間は、アプリケーションが利用可能なハードウェア・リソース (アプリケーション・コードを実行するコアなど) を利用する能力である、アプリケーションのスケーラビリティーを妨げる要因の 1 つです。並列アプリケーションの最大スピードアップは、アムダールの法則で 1/((1-P)+(P/N)) と表されます。ここで、P はアプリケーション実行の並列部分であり、N はプロセッサー・エレメントです。そのため、P (アプリケーション実行のシリアル部分) が大きくなるほど、実行のシリアル部分によって制限される N (プロセッサー・エレメント) の数が多くなります。
ユーザー・アプリケーションが OpenMP* で並列化されている場合、シーケンシャル・コードの実行は、OpenMP* 領域外のコード実行、または #pragma omp master や #pragma omp single 構造内のコード実行の可能性があります。このレシピでは、1 つ目のケースの検出に注目します。このレシピを参考にして、インテル® VTune™ Amplifier で OpenMP* 領域外のコードの実行時間を検出して、シリアル・ホットスポット関数/ループの分布を解析し、コードの並列化の可能性を理解します。
使用するもの
以下は、パフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: miniFE 有限要素ミニアプリケーション (OpenMP* バージョン)。https://github.com/Mantevo/miniFE (英語) からダウンロードできます。
- コンパイラー: インテル® コンパイラー 13 Update 5 以降。このレシピは、インテル® VTune™ Amplifier の解析で使用されるインテルの OpenMP* ランタイム・ライブラリー内のインストルメンテーションを実行するため、このコンパイラー・バージョンを必要とします。
- パフォーマンス解析ツール:
- インテル® VTune™ Amplifier 2019: HPC パフォーマンス特性解析
- インテル® Inspector 2019: スレッドエラー解析
注
- インテル® VTune™ Amplifier 評価版のダウンロードと製品サポートについては、https://www.isus.jp/intel-vtune-amplifier-xe/ を参照してください。
- インテル® Inspector 評価版のダウンロードと製品サポートについては、https://www.isus.jp/intel-inspector-xe/ を参照してください。
- オペレーティング・システム: Ubuntu* 16.04 LTS
- CPU: インテル® Xeon® プロセッサー E5-2699 v4 @ 2.20GHz
ベースラインを作成する
openmp/src/Makefile.intel.openmp メイクファイルを使用してアプリケーションをビルドします。インテル® コンパイラーの -g オプションと -parallel-source-info=2 オプションを追加してコンパイルすることで、デバッグ情報が有効になり、OpenMP* 領域名でソースファイル情報が提供され、ユーザーが識別しやすくなります。
引数 nx=200、ny=200、nz=200 でコンパイルしたアプリケーションを、物理コア数に対応する OpenMP* スレッド数とコアごとに 1 スレッド (OMP_NUM_THREADS=44、OMP_PLACES=cores) で実行すると、約 12 秒かかります。これが、以降の最適化で使用するパフォーマンスのベースラインとなります。
HPC パフォーマンス特性解析を実行する
サンプル・アプリケーションの潜在的なパフォーマンス・ボトルネックを理解するため、まず、インテル® VTune™ Amplifier の HPC パフォーマンス特性解析を実行します。
- ツールバーの [New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: miniFE) を指定します。
[Configure Analysis (解析の設定)] ウィンドウが表示されます。
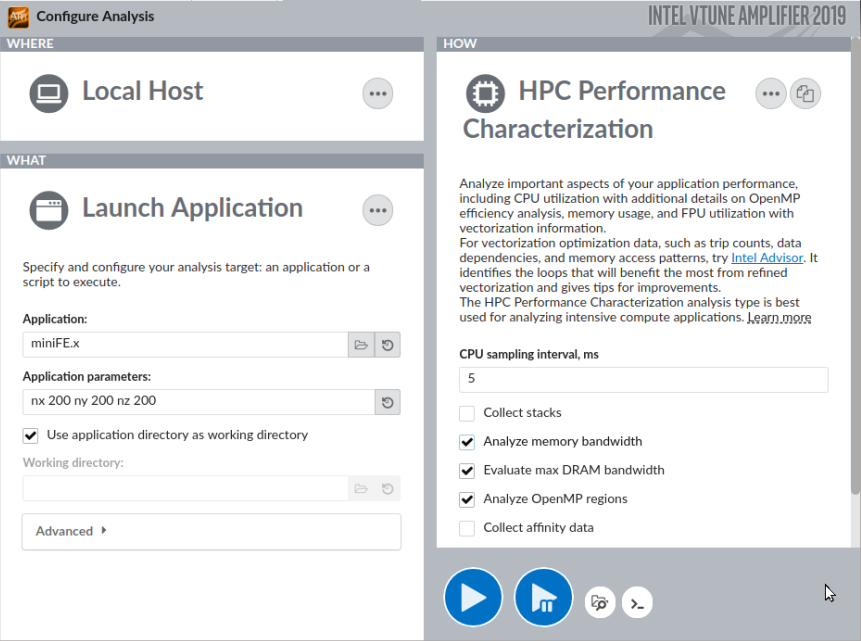
- [WHERE (どこを)] ペインで、[Local Host (ローカルホスト)] ターゲット・システム・タイプを選択します。
[WHAT (何を)] ペインで、[Launch Application (アプリケーションを起動)] ターゲットタイプを選択して、解析するアプリケーションと引数 nx 200 ny 200 nz 200 を指定します。
- [HOW (どのように)] ペインで、[…] ボタンをクリックして [Parallelism (並列処理)] グループから [HPC Performance Characterization (HPC パフォーマンス特性)] 解析を選択します。
 [Start (開始)] ボタンをクリックして、解析を実行します。
[Start (開始)] ボタンをクリックして、解析を実行します。
コマンドラインから解析を実行するには、次の構文を使用します。
amplxe-cl -collect hpc-performance -data-limit=0 ./miniFE.x nx 200 ny 200 nz 200
インテル® VTune™ Amplifier は、アプリケーションを起動してデータを収集し、収集したデータをファイナライズして、シンボル情報を解決します。この情報は、ソース解析で必要になります。
OpenMP* シリアル時間を特定する
HPC パフォーマンス特性解析は、CPU 使用率 (並列性)、メモリーアクセス効率、ベクトル化などのパフォーマンス・ボトルネックの理解に役立つ重要な HPC メトリックを収集して表示します。このレシピのようにインテルの OpenMP* ランタイムを使用するアプリケーションでは、スレッド並列処理の問題の特定を支援する特別な OpenMP* 効率メトリックが役立ちます。
アプリケーション・レベルの統計が表示される [Summary (サマリー)] ビューから解析を始めます。フラグが付いた [Effective Physical Core Utilization (効率的な物理コア利用率)] メトリック (一部のシステムでは [CPU Utilization (CPU 使用率)]) は、調査すべきパフォーマンスの問題を示しています。

メトリックの階層を深く掘り下げると、アプリケーションの [Serial Time (outside parallel regions) (シリアル時間 (並列領域外))] が経過時間の約 25% を占めていることが分かります。主なシリアル hotspot は、行列の初期化コードにあります。
コールスタック付きの HPC パフォーマンス特性解析を実行して、利用可能な最適化の可能性を調査することを検討してください。コールスタックは、適切な粒度で並列化の候補を見つけるのに役立ちます。コールスタック収集はメモリー帯域幅の解析と組み合わせることができないため、必ず [Analyze memory bandwidth (メモリー帯域幅を解析)] 設定オプションを無効にしてください。
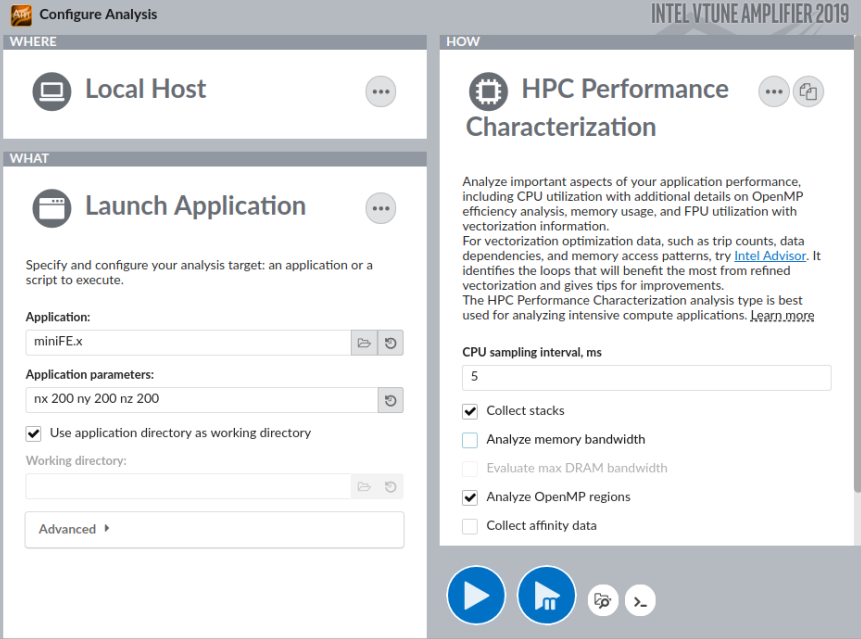
コマンドラインからこの設定を実行するには、次のコマンドを入力します。
amplxe-cl -collect hpc-performance -data-limit=0 -knob enable-stack-collection=true -knob collect-memory-bandwidth=false ./miniFE.x nx 200 ny 200 nz 200
注
[Threading (スレッド化)] 解析を実行して、スタックを使用して OpenMP* シリアル時間を解析することもできます。ただし、どのパフォーマンス特性がボトルネックになっているのか分からない場合は、HPC パフォーマンス特性解析を出発点としたほうが良いでしょう。
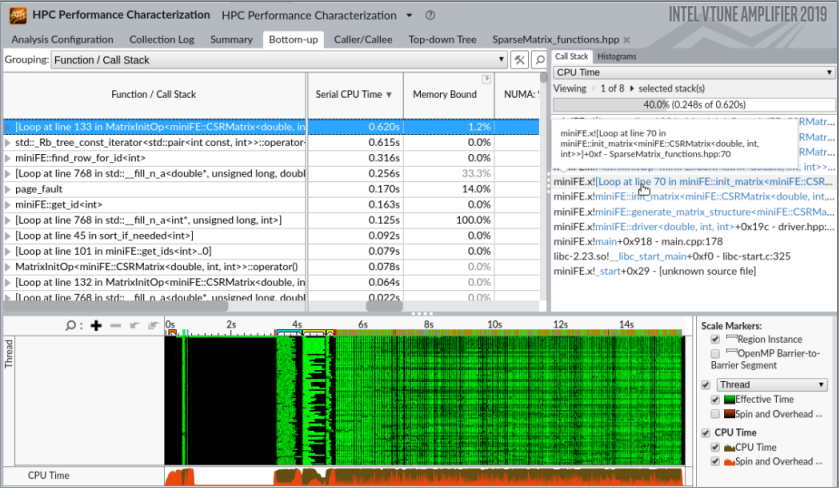
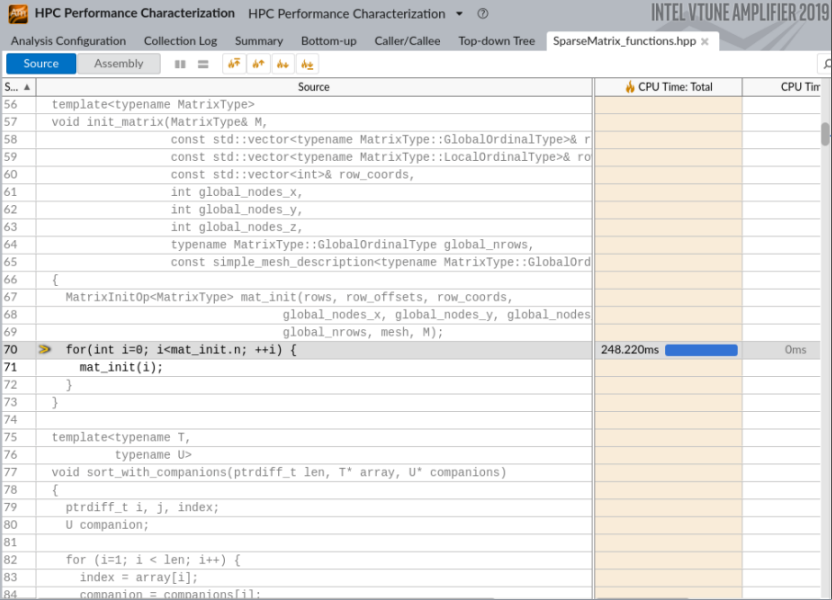
上位の hotspot を特定し、そのコールスタックを調査するには、[Bottom-up (ボトムアップ)] ビューに切り替えて、[Serial CPU Time (シリアル CPU 時間)] カラムでソートします。
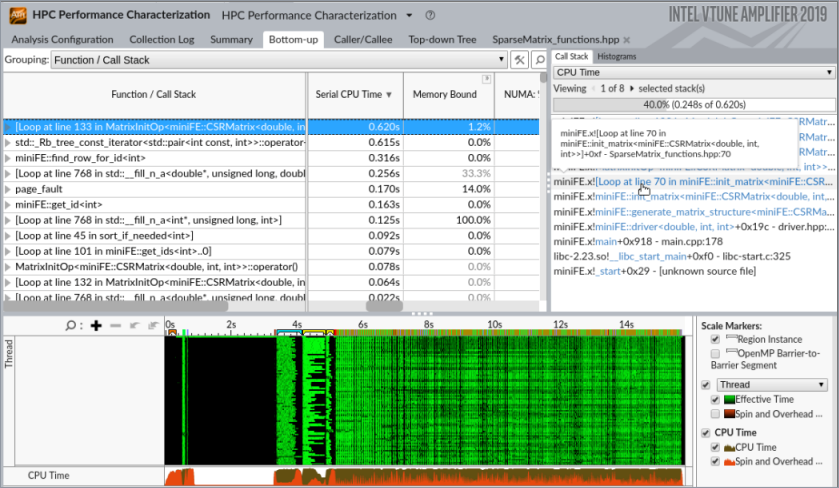
行列要素でループを反復している SparseMatrix_functions.hpp の 70 行目が並列化に適していることが分かります。
[Call Stack (コールスタック)] ペインの行をダブルクリックして、ソースファイルを開きます。上位の hotspot ループの最もホットな行が自動的に表示されます。
コードを並列化する
#pragma omp parallel for を追加して、行列の初期化を OpenMP* で並列化します。
#pragma omp parallel for
for(int i=0; i<mat_init.n; ++i) {
mat_init(i);
アプリケーションを再コンパイルして、その実行時間とオリジナルのパフォーマンス・ベースラインを比較して、最適化を検証します。
このレシピでは、最適化したアプリケーションの経過時間は約 10 秒になり、アプリケーションの実行は約 16% スピードアップしました。
最適化したアプリケーションで HPC パフォーマンス特定解析を再度実行します。

全体的な [Effective Physical Core Utilization (効率的な物理コア利用率)] は 10% 向上しました。OpenMP* シリアル時間は 9% に減り、インテル® VTune™ Amplifier によって問題フラグが付けられなくなりました (メトリックのしきい値は 15% です)。
並列効率をさらに向上するには、「OpenMP*インバランスとスケジュール・オーバーヘッド」クックブック・レシピで示すように、最もバランスの悪いバリアを解析できます。
スレッドエラーを調査する
並列処理の解析を完了するには、データ競合やデッドロックなどのスレッドエラーをチェックします。チェックには、一部のハードウェアでは発生せずに別の環境では問題となる、あるいは同じ環境の異なる設定で発生する潜在的なデータ競合とデッドロックも検出できる、インテル® Inspector を使用します。
コマンドライン・インターフェイスを使用し、ワークロード・サイズを減らすと、チェックを高速に行い代表的な結果が得られます。
inspxe-cl -collect ti3 ./miniFE.x nx 40 ny 40 nz 40
インテル® Inspector は並列コードの問題は検出しません。
注
このレシピの情報は、https://software.intel.com/en-us/forums/intel-vtune-amplifier-xe/topic/754466 を参照してください。
