
この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「OpenMP* Code Analysis Method」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピは、OpenMP* または OpenMP* – MPI ハイブリッド・アプリケーションの CPU 利用率を解析して、潜在的な非効率性の原因を特定します。
コンテンツ・エキスパート: Dmitry Prohorov (英語)
OpenMP* はフォーク・ジョイン並列モデルであり、OpenMP* プログラムは単一のマスター・シリアルコード・スレッドで実行を開始します。並列領域に到達すると、マスタースレッドは複数のスレッドにフォークして並列領域を実行します。各スレッドは並列領域の最後にあるバリアでジョインして、その後マスタースレッドがシリアルコードの実行を続行します。マスタースレッドが並列領域にフォークし、barrier や single などの構造でワークを調整する、MPI プログラムのように OpenMP* プログラムを記述することもできます。しかし、シリアルコードが点在する並列領域のシーケンスで構成される OpenMP* プログラムの方が一般的です。
理想的には、並列化されたアプリケーションは利用可能な CPU コアの処理時間を 100% 利用して、実行開始から終了まで有用なワークを実行するワーカースレッドを持ちます。実際には、ワーカースレッドがアクティブスピンで待機している場合 (待機時間は短くなることが予想されます)、または受動的に待機して CPU を消費していない場合は、有効な CPU 利用率は低くなります。ワーカースレッドが待機し、有用なワークを実行していない理由はいくつかあります。
- シリアル領域の実行 (並列領域外): マスタースレッドがシリアル領域を実行している場合、ワーカースレッドは OpenMP* ランタイムで次の並列領域を待機しています。
- ロード・インバランス: スレッドは並列領域でワークロードの実行を終了すると、他のスレッドが終了するのをバリアで待機します。
- 並列ワーク不足: ループの反復回数がワーカースレッド数よりも少ないため、チームのいくつかのスレッドはバリアで待機しており、有用なワークを実行していません。
- ロックでの同期: 並列領域内で同期オブジェクトが使用されると、ほかのスレッドとの共有リソースへのアクセス競合を避けるため、スレッドはロックが開放されるまで待機します。
インテル® Composer XE 2013 Update 2 以降とともにインテル® VTune™ プロファイラーを使用すると、
アプリケーションが利用可能な CPU をどのように利用し、CPU が未使用である原因を特定できます。
インテル® VTune™ プロファイラーで OpenMP* アプリケーションを解析するには、次の操作を行います。
- 推奨オプションでコードをコンパイルする
- OpenMP* 領域解析を設定する
- アプリケーション・レベルの OpenMP* メトリックを調査する
- シリアルコードを特定する
- 潜在的なゲインを予測する
- 制限事項を理解する
推奨オプションでコードをコンパイルする
コンパイル時に並列領域とソース解析を有効にするには、次の手順に従ってください。
- OpenMP* 並列領域を解析するには、インテル® コンパイラー 13.1 Update 2 以降 (インテル® Composer XE 2013 Update 2 に含まれます) でコードがコンパイルされていることを確認してください。古いバージョンの OpenMP* ランタイム・ライブラリーが検出されると、インテル® VTune™ プロファイラーは警告メッセージを出力します。この場合、収集結果は不完全な可能性があります。
ドキュメントに記載されている最新の OpenMP* 解析オプションを使用するには、常に最新バージョンのインテル® コンパイラーを使用していることを確認してください。
- Linux* 上で、GCC でコンパイルされた OpenMP* アプリケーションを解析するには、GCC OpenMP* ライブラリー (libgomp.so) にシンボル情報が含まれていることを確認してください。これを確認するには、libgomp.so を検索して nm コマンドでシンボルをチェックします。次に例を示します。
nm libgomp.so.1.0.0
ライブラリーにシンボル情報が含まれていない場合、シンボル付きの新しいライブラリーをインストールまたはコンパイルするか、ライブラリーのデバッグ情報を生成してください。例えば、Fedora* では yum リポジトリーから GCC デバッグ情報をインストールできます。
yum install gcc-debuginfo.x86_64
OpenMP* 解析を設定する
ターゲットの OpenMP* 解析を行うには、次の操作を実行します。
インテル® VTune™ プロファイラーのツールバーにある
 (スタンドアロン GUI)/
(スタンドアロン GUI)/  (Visual Studio* IDE) [Configure Analysis (解析の設定)] ボタンをクリックします。
(Visual Studio* IDE) [Configure Analysis (解析の設定)] ボタンをクリックします。[Configure Analysis (解析の設定)] ウィンドウが表示されます。
[HOW (どのように)] ペインで、
 [Browse (参照)] ボタンをクリックして OpenMP* 解析をサポートする解析タイプ (スレッド化、HPC パフォーマンス特性、メモリーアクセス、またはカスタム解析タイプ) を選択します。
[Browse (参照)] ボタンをクリックして OpenMP* 解析をサポートする解析タイプ (スレッド化、HPC パフォーマンス特性、メモリーアクセス、またはカスタム解析タイプ) を選択します。- [Analyze OpenMP regions (OpenMP* 領域を解析)] オプションが選択されていない場合は選択します ([Details (詳細)] セクションを確認)。
 [Start (開始)] ボタンをクリックして、解析を実行します。
[Start (開始)] ボタンをクリックして、解析を実行します。
インテル® コンパイラーの OpenMP* ランタイム・ライブラリーは、プロファイル・モードで実行中のアプリケーション向けに特別なマーカーを提供します。これを利用して、インテル® VTune™ プロファイラーは OpenMP* 並列領域の統計を解読し、アプリケーション・コードのシリアル領域を区別できます。
アプリケーション・レベルの OpenMP* メトリックを調査する
解析ターゲットの CPU 利用率を理解してから解析を始めます。HPC パフォーマンス特性 (英語) ビューポイントを使用する場合、[Summary (サマリー)] ウィンドウの [Effective Physical Core Utilization (効率的な物理コア利用率)] セクションで、使用されている論理コア数と物理コア数、および CPU 利用率の効率 (パーセント) の予測に注目します。低いコア利用率は、パフォーマンスの問題としてフラグが付けられます。
他のビューポイントでは、アプリケーションの経過時間を CPU 利用率レベルまで細分化した [CPU Utilization Histogram (CPU 利用率の分布図)] が表示されます。分布図には有効な利用率しか表示されないため、アプリケーションがスピンループ (アクティブ待機) で CPU を使用した CPU サイクルはカウントされません。利用可能なハードウェア・スレッド数よりも少ない OpenMP* ワーカースレッドを意図的に使用する場合、スライドバーを使用してデフォルトレベルから調整できます。
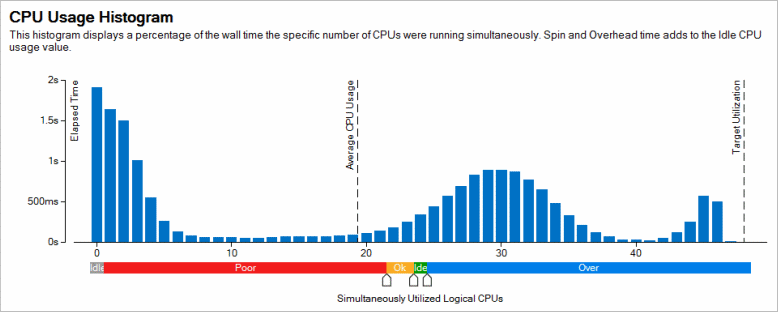
バーが理想的な利用率に近い場合、パフォーマンス向上の可能性を見つけるには、アルゴリズムまたはマイクロアーキテクチャーのチューニングを検討する必要があります。アプリケーションの非効率な並列化については、[Summary (サマリー)] ウィンドウの [OpenMP Analysis (OpenMP* 解析)] セクションを調査します。
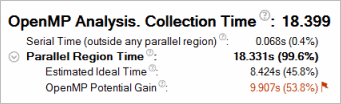
[Summary (サマリー)] ウィンドウのこのセクションには、収集時間とプログラムのシリアル領域 (並列領域外) と並列領域の持続期間が表示されます。シリアル領域が長い場合、さらに並列処理を導入するか、並列化が困難なシリアル領域ではアルゴリズムやマイクロアーキテクチャーのチューニングを行って、シリアル実行を短縮することを検討してください。スレッドカウントの多いマシンのシリアル領域は、潜在的なスケーリングに深刻な悪影響を与えるため (アムダールの法則)、可能な限り最小にすべきです。
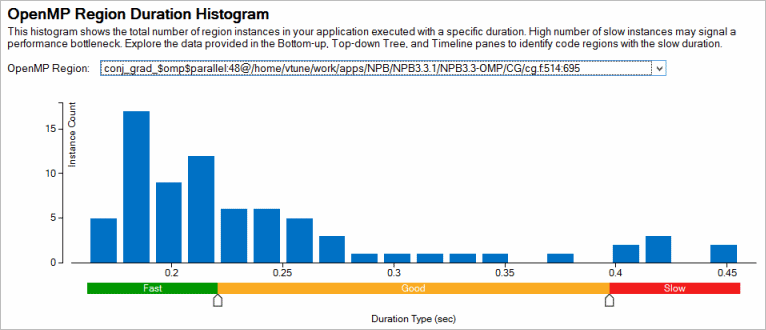
[Summary (サマリー)] ウィンドウの [OpenMP Region Duration Histogram (OpenMP* 領域持続分布図)] を参照して、OpenMP* 領域のインスタンスを解析し、インスタンスの持続期間の分布を調査して、高速/良好/低速領域のインスタンスを識別します。デフォルトの分布図では、最小領域時間と最大領域時間の間が 20/40/20 の比率で高速/良好/低速に分類されます。必要に応じて、しきい値を調整します。
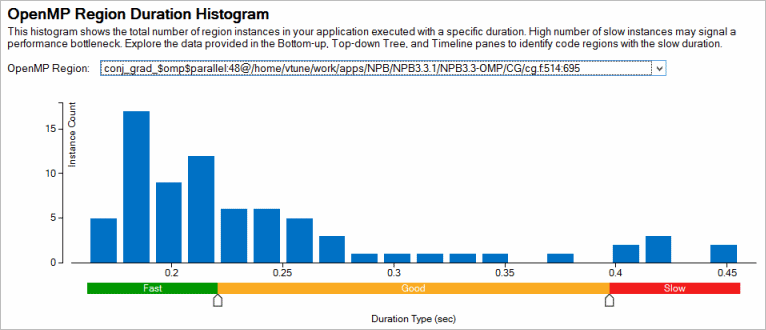
このデータを使用して、[OpenMP Region/OpenMP Region Duration Type/… (OpenMP* 領域/OpenMP* 領域持続タイプ/…)] グループ化レベルでグリッドをさらに詳しく解析します。
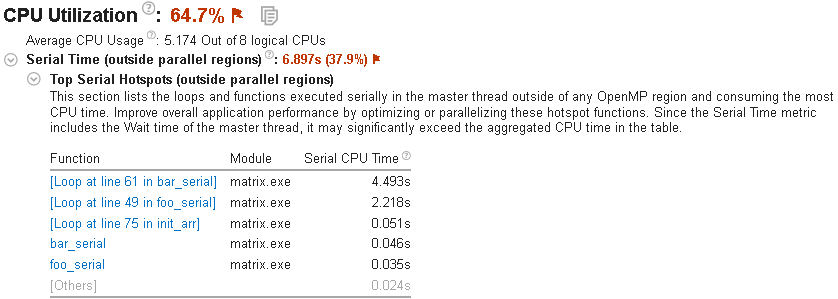
シリアルコードを特定する
シリアル実行されたコードを解析するには、[Summary (サマリー)] ウィンドウの [Serial Time (outside parallel regions) (シリアル時間 (並列領域外))] セクションを展開して、[Top Serial Hotspots (outside parallel regions) (上位のシリアル・ホットスポット (並列領域外))] を確認します。関数名をクリックすると、[Bottom-up (ボトムアップ)] ウィンドウでその関数の詳細を確認できます。
潜在的なゲインを予測する
コードの並列領域で CPU 利用率の効率を予測するには、潜在的なゲインメトリックを使用します。このメトリックは、並列領域の実測された経過時間と理想化された経過時間 (スレッドのバランスが完璧で OpenMP* ランタイムのオーバーヘッドがゼロであると仮定) の差を予測します。このデータを使用して、並列実行を改善することで短縮できる最大時間を見積ることができます。
[Summary (サマリー)] ウィンドウには、[Potential Gain (潜在的なゲイン)] メトリック値が最も高い 5 つの並列領域が表示されます。#pragma omp parallel で定義された並列領域ごとに 、このメトリックは並列領域のすべてのインスタンスの潜在的なゲインの合計を示します。
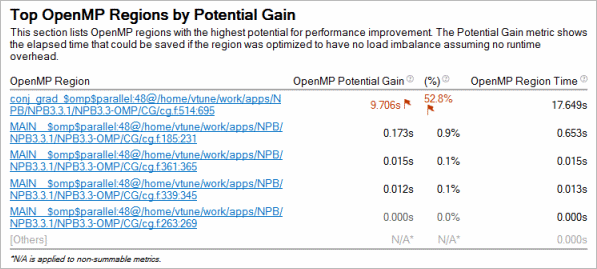
領域の潜在的なゲインが顕著である場合、領域名のリンクをクリックして [Bottom-up (ボトムアップ)] ウィンドウに移動し、バリアによるインバランスなどの非効率なメトリックの詳細な解析を示す [/OpenMP Region/OpenMP Barrier-to-Barrier Segment/.. (/OpenMP* 領域/OpenMP* バリアからバリアのセグメント/..)] グループ化を使用して、さらに深く調査できます。
インテル® コンパイラーの OpenMP* ランタイムは、インテル® VTune™ プロファイラー向けにバリアをインストルメントします。インテル® VTune™ プロファイラーは、領域のフォーク位置または以前のバリアからセグメントを定義するバリアまでの、バリア間の OpenMP* 領域セグメントの概念を導入しています。
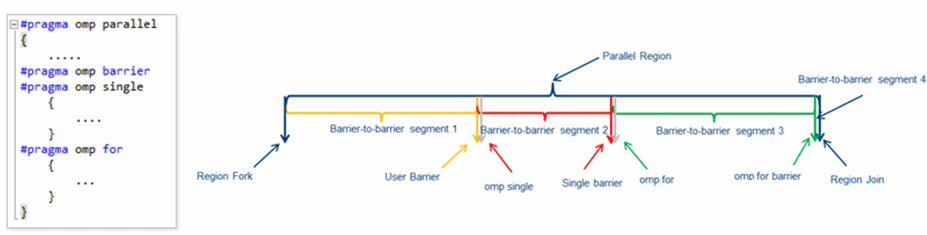
上記の例では、user barrier、暗黙的な single barrier、暗黙的な omp for ループバリアと region join バリアとして定義された 4 つのバリアからバリアへのセグメントがあります。
OpenMP* 領域に、並列ループや #pragma single sections などの暗黙のバリア、または明示的なユーザーバリアが複数定義されている場合、特定の構造の影響や非効率なメトリックに対するバリアを解析します。
バリアタイプはセグメント名に組込まれます (例えば、loop、single、reduction など)。また、暗黙のバリアを持つ並列ループについて、ループのスケジュール、チャンクサイズ、および最小/最大/平均ループ反復カウントなど、インバランスやスケジュールのオーバーヘッドを理解するのに役立つ追加の情報を出力します。ループ反復カウント情報は、外部ループの並列化により、反復回数が少ないワーカースレッドの利用率が低下する問題を識別するのにも役立ちます。この場合、内部ループを並列化するか、collapse 節を使用してワーカースレッドを飽和させることを検討してください。
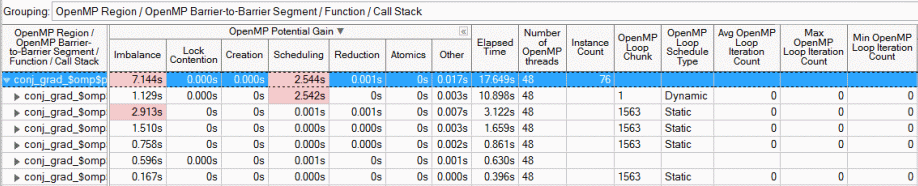
OpenMP* スレッド数で正規化した非効率のコスト (経過時間) を表示することで、領域の潜在的なゲインの内訳を示す [Potential Gain (潜在的なゲイン)] カラムのデータを解析します。経過時間コストは、特定の非効率性タイプに対応すべきかどうかを判断するのに役立ちます。インテル® VTune™ プロファイラーは、次の非効率性タイプを認識できます。
- Imbalance (インバランス): スレッドは異なる時間でワークを終え、バリアで待機しています。インバランス時間が顕著である場合、動的なスケジュールの導入を検討してください。インテル® Parallel Studio Composer Edition の OpenMP* ランタイム・ライブラリーはインバランスを正確にレポートし、メトリックはサンプリングに基づいて計算される他の非効率性のように統計の精度に依存しません。
- Lock Contention (ロック競合): スレッドは、競合するロック、または “ordered” 節が指定された並列ループで待機しています。ロック競合の時間が顕著である場合、リダクション操作、スレッド・ローカル・ストレージ、または低コストのアトミック操作を使用することで、並列構造内での同期を回避してください。
- Creation (生成): 並列ワークの配置に関連したオーバーヘッド。並列ワークの配置時間が顕著である場合、並列領域を外部ループに移動して、並列処理の粒度を粗くしてください。
- Scheduling (スケジュール): ワーカースレッドへの並列ワークの割り当てに関連した OpenMP* ランタイム・スケジューラーのオーバーヘッドです。スケジュールの時間が顕著である場合 (動的スケジュールでよく見られます)、大きなチャンクサイズの “dynamic” スケジュール、または “guided” スケジュールを使用します。
- Atomics (アトミック): アトミック操作の実行に関連した OpenMP* ランタイムのオーバーヘッド。
- Reduction (リダクション): リダクション操作で費やされた時間。
インテルの OpenMP* ランタイムのバージョンが古く、[Potential Gain (潜在的なゲイン)] カラムを拡張できない場合、対応する CPU 時間メトリックの内訳を解析してください。
パフォーマンスが重要な OpenMP 並列領域のソースを解析するには、[OpenMP Region/.. (OpenMP* 領域/..)] グループ化レベルでソートしたグリッドで領域識別子をダブルクリックします。インテル® VTune™ プロファイラーは、ソースビューを開いて、インテル® コンパイラーが生成した疑似関数内の選択された OpenMP* 領域の先頭を表示します。
注
デフォルトでは、インテル® コンパイラーは領域名にソースファイル名を追加しません。そのため、OpenMP* 並列領域名が [unknown (不明)] と表示されます。領域名のソースファイル名を取得するには、コンパイルオプションに -parallel-source-info=2 を追加します。
制限事項を理解する
インテル® VTune™ プロファイラーの並列 OpenMP* 領域の解析には、次のような制限があります。
- サポートされる語彙的な並列領域の最大数は 512 です。512 個を超える並列領域にスコープが到達すると、並列アノテーションは出力されません。
- 入れ子になった並列領域はサポートされません。最上位の項目のみが領域を生成します。
- インテル® VTune™ プロファイラーは、静的リンクされた OpenMP* ライブラリーをサポートしません。
関連クックブック・レシピ
- チューニング・レシピ: OpenMP* インバランスとスケジュール・オーバーヘッド
- チューニング・レシピ: 低いプロセッサー・コア利用率: OpenMP* シリアル時間
- 設定レシピ: MPI アプリケーションのプロファイル
関連情報
- knob analyze-openmp=true (英語) vtune オプション
- MPI コード解析 (英語)
