
この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「Frequent DRAM Accesses」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピは、インテル® VTune™ Amplifier のマイクロアーキテクチャー全般解析とメモリーアクセス解析を使用してメモリー依存の matrix アプリケーションをプロファイルし、頻繁な DRAM アクセスの原因を理解します。
コンテンツ・エキスパート: Dmitry Ryabtsev (英語)
- 使用するもの
- 手順:
使用するもの
以下は、パフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: 2048×2048 サイズの 2 つの行列を乗算する行列乗算サンプル (要素は double 型)。matrix_vtune_amp_axe.tgz サンプルパッケージは、製品の <install-dir>/samples/en/C++ ディレクトリーに含まれています。https://software.intel.com/en-us/product-code-samples (英語) からダウンロードすることもできます。
- パフォーマンス解析ツール:
- インテル® VTune™ Amplifier 2019: マイクロアーキテクチャー全般解析 (旧: 全般解析)、メモリーアクセス解析
注
- インテル® VTune™ プロファイラー評価版のダウンロードと製品サポートについては、https://www.isus.jp/intel-vtune-amplifier-xe/ を参照してください。
- このクックブックのレシピはすべてスケーラブルであり、インテル® VTune™ Amplifier 2018 以降に適用できます。バージョンにより設定がわずかに異なることがあります。
- ベータ版インテル® oneAPI ベース・ツールキット向けのバージョンから、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。引き続き、インテル® Parallel Studio XE またはインテル® System Studio のコンポーネントとして、あるいはスタンドアロン版のインテル® VTune™ プロファイラーをご利用いただけます。
- インテル® VTune™ Amplifier 2019: マイクロアーキテクチャー全般解析 (旧: 全般解析)、メモリーアクセス解析
- オペレーティング・システム: Ubuntu* 16.04 64 ビット
- CPU: インテル® Core™ i7-6700K プロセッサー
ベースラインを作成する
サンプルコードの初期バージョンは、次のコードにより、メインカーネルに単純な乗算アルゴリズムを実装しています。
void multiply1(int msize, int tidx, int numt, TYPE a[][NUM], TYPE v[][NUM], TYPE c[][NUM], TYPE t[][NUM])
{
int i,j,k;
// Naive implementation
for(i=tidx; i<msize; i=i+numt) {
for(j=0; j<msize; j++) {
for(k=0; k<msize; k++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
}
}
}
}
コンパイルしたアプリケーションの実行には約 22 秒かかります。これが、以降の最適化で使用するパフォーマンスのベースラインとなります。
マイクロアーキテクチャー全般解析を実行する
サンプル・アプリケーションの潜在的なパフォーマンス・ボトルネックを理解するため、まず、インテル® VTune™ プロファイラーのマイクロアーキテクチャー全般解析を実行します。
- ツールバーの
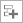 [New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: matrix) を指定します。
[New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: matrix) を指定します。 - [Configure Analysis (解析の設定)] ウィンドウの [WHERE (どこを)] ペインで、[Local Host (ローカルホスト)] ターゲット・システム・タイプを選択します。
- [WHAT (何を)] ペインで、[Launch Application (アプリケーションを起動)] ターゲットタイプを選択して、解析するアプリケーションを指定します。
- [HOW (どのように)] ペインで、[…] ボタンをクリックして [Microarchitecture (マイクロアーキテクチャー)] グループから [Microarchitecture Exploration (マイクロアーキテクチャー全般)] 解析を選択します。
 [Start (開始)] ボタンをクリックします。
[Start (開始)] ボタンをクリックします。
インテル® VTune™ Amplifier は、アプリケーションを起動してデータを収集し、収集したデータをファイナライズして、シンボル情報を解決します。この情報は、ソース解析で必要になります。
ハードウェアの hotspot を特定する
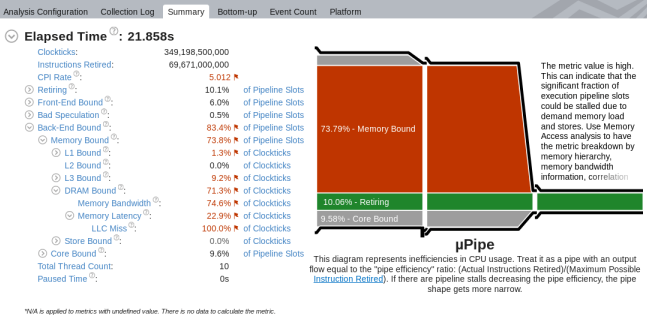
マイクロアーキテクチャー全般解析を実行すると、コードの主要なボトルネックを確認できます。解析したアプリケーションの CPU マイクロアーキテクチャーの効率と CPU パイプライン・ストールが表示される [Summary (サマリー)] ビューの [µPipe (µ パイプ)] から解析を始めます。以下の [µPipe (µ パイプ)] では、出力パイプのフローが非常に狭いため、アプリケーションのパフォーマンスを向上するには、[Retiring (リタイア)] メトリックの値を増やす必要があります。このパイプの主な問題は、[Memory Bound (メモリー依存)] メトリックの値です。
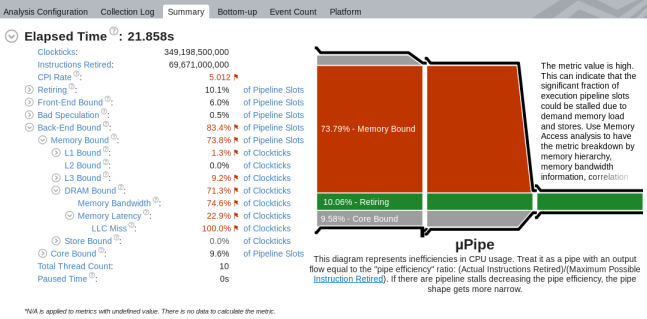
左側のメトリックツリーから、パフォーマンスは主に DRAM アクセスによって制限されていることが分かります。
[Bottom-up (ボトムアップ)] ビューに切り替えると、アプリケーションに 1 つの大きな hotspot 関数 multiply1 があることが分かります。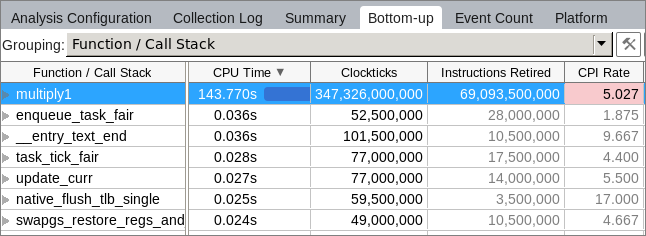
この関数をダブルクリックして [Source (ソース)] ビューを開きます。最もパフォーマンス・クリティカルなコード行がハイライトされます。
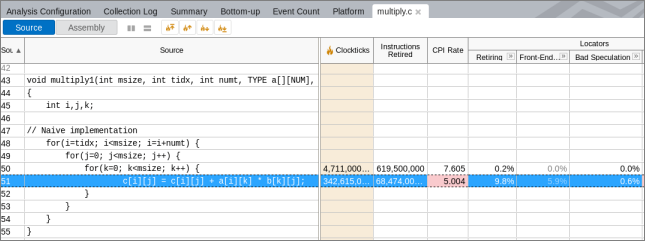
ほとんどの時間が、3 つの配列 (a、b、および c) を操作しているソース行 51 で費やされています。
メモリーアクセス解析を実行する
最も時間がかかった配列アクセスを調べるため、[Analyze dynamic memory objects (動的メモリー・オブジェクトを解析)] オプションを有効にしてメモリーアクセス解析を実行します。
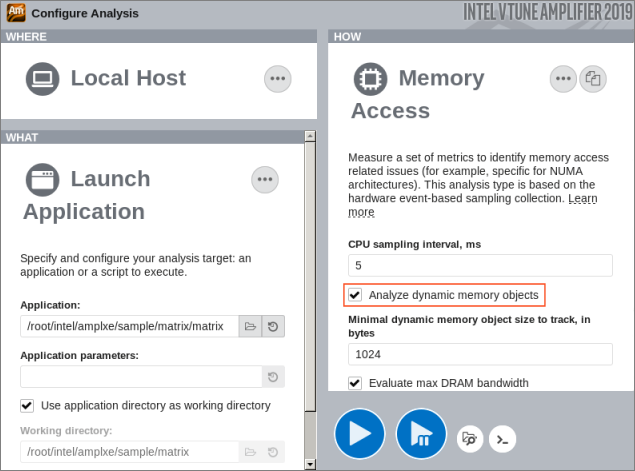
ホットなメモリーアクセスを特定する
次のように、メモリーアクセス解析結果の [Summary (サマリー)] ウィンドウに、上位のメモリー・オブジェクトが表示されます。

リストの最初の hotspot オブジェクト matrix.c:121 をクリックして [Bottom-up (ボトムアップ)] ビューに切り替えた後、グリッドでハイライトされているこのオブジェクトをダブルクリックして [Source (ソース)] ビューを開き、このメモリー・オブジェクトの行を確認します。
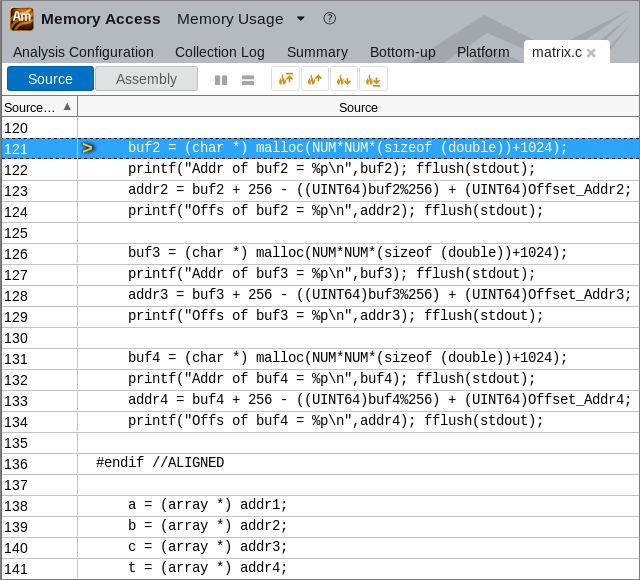
buf2 変数が addr2 に代入され、それが配列 b に代入されていることが分かります。つまり、問題のある配列は b と考えられます。ツールバーの ![]() [Open Source File Editor (ソース・ファイル・エディターを開く)] ボタンをクリックして、コードを再度確認します。
[Open Source File Editor (ソース・ファイル・エディターを開く)] ボタンをクリックして、コードを再度確認します。
void multiply1(int msize, int tidx, int numt, TYPE a[][NUM], TYPE v[][NUM], TYPE c[][NUM], TYPE t[][NUM])
{
int i,j,k;
// Naive implementation
for(i=tidx; i<msize; i=i+numt) {
for(j=0; j<msize; j++) {
for(k=0; k<msize; k++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
}
}
}
}
問題の根本的な原因が分かりました。最内サイクルが非効率な方法で配列 b を反復しているため、各反復で大きなメモリーチャンクにジャンプしています。
ループ交換の最適化を適用する
次のように、j と k にループ交換アルゴリズムを適用します。
for(i=tidx; i<msize; i=i+numt) {
for(k=0; k<msize; k++) {
for(j=0; j<msize; j++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
}
}
}
新しいコードをコンパイルして実行すると、実行時間は 1.3 秒になり、オリジナル (26 秒) の 20 倍にパフォーマンスが向上しました。
次のステップ
最適化したコードでマイクロアーキテクチャー全般解析を再度実行します。[µPipe (µ パイプ)] 図の [Retiring (リタイア)] メトリックの値が 10.06% から 63.28% へ大幅に増加しました。
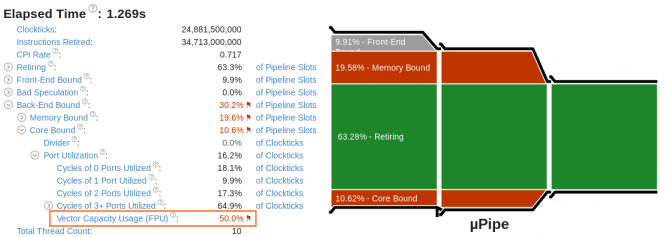
その他のフラグの付いているメトリックに注目して、さらなるパフォーマンス向上の可能性 (例えば、低いポート使用率) を特定します。
