
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「Profiling an Application for Performance Anomalies」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
バージョン: 2020 (最終更新日: 2021 年 3 月 26 日)
このレシピは、インテル® VTune™ プロファイラーの異常検出解析を使用して、いくつかの要因によるパフォーマンス異常を特定する方法を紹介します。また、これらの異常を修正するための提案も提供します。
コンテンツ・エキスパート: Vasily Starikov
パフォーマンス異常は、無視すると取り返しのつかない損失をもたらす散発的な問題です。望ましくない動作を引き起こす可能性のあるパフォーマンス異常には、いくつかの種類があります。
- ビデオフレームが遅い/スキップする
- 画像のトラッキングに失敗する
- 金融取引に想定外の時間がかかる
- ネットワーク・パケット処理に長い時間がかかる
- ネットワーク・パケットの紛失
これらの動作は、従来のサンプリングベースの手法では見つけることができませんが、異常検出解析タイプを使用して検出できます。この解析では、次の原因による異常を調査します。
- 制御フローの逸脱
- スレッドのコンテキスト・スイッチ
- 想定外のカーネル・アクティビティー (割り込みやページフォールトなど)
- CPU 周波数の低下
異常検出は、インテル® Processor Trace (インテル® PT) テクノロジーを使用して、プロセッサーからの粒度の細かい情報をナノ秒レベルで提供します。
使用するもの
以下は、このパフォーマンス解析の最小ハードウェアおよびソフトウェア要件です。
- アプリケーション: 任意のサンプル・アプリケーション。
- マイクロアーキテクチャー: インテル® Xeon® プロセッサー開発コード名 Skylake 以降。
- ツール: インテル® VTune™ プロファイラー 2021 以降の異常検出解析。
注
- バージョン 2020 から、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。
- インテル® VTune™ プロファイラー・パフォーマンス解析クックブックのほとんどのレシピは、異なるバージョンのインテル® VTune™ プロファイラーにも適用できます。バージョンにより、わずかな調整が必要になる場合があります。
- 最新バージョンのインテル® VTune™ プロファイラーは以下から入手できます。
- オペレーティング・システム:
- Linux* Fedora* 31 (Workstation エディション) – 64 ビット・バージョン
- Windows* 10
インテル® PT の要件
- オペレーティング・システム: 任意のバージョンの Windows* または Linux*。
- マイクロアーキテクチャー: インテル® プロセッサー開発コード名 Skylake 以降。
解析用にアプリケーションを準備する
通常、ソフトウェアのパフォーマンス解析では大量のデータを収集します。パフォーマンス異常は稀で短期間であるため、これらのデータセットに占める割合はごくわずかであり、気付かれないこともあります。インテルのインストルメンテーションおよびトレーシング・テクノロジー (ITT) API を使用して、特定のコード領域に絞って解析すると良いでしょう。
コード領域を選択してアプリケーションを準備します。
- サンプル・アプリケーションがあるディレクトリーに移動します。
- プロファイルするコード領域の名前を登録します。
__itt_pt_region region=__itt_pt_region_create("region of interest"); - サンプルの中で、異常が発生しやすい操作を行うループを探します。begin および end 関数を使用してループの反復をマークします。次に例を示します。
double process(std::vector<double> &cache) { double res=0; for (size_t i=0; i<ITERATIONS; i++) { __itt_mark_pt_region_begin(region); res+=calculate(i, cache); __itt_mark_pt_region_end(region); } return res; }
異常検出を実行する
- [Welcome (ようこそ)] 画面で [Configure Analysis (解析の設定)] をクリックします。
- 解析ツリーで [Algorithm (アルゴリズム)] グループの [Anomaly Detection (異常検出)] 解析タイプを選択します。
- [WHAT (何を)] ペインで、アプリケーションと関連するアプリケーション・パラメーターを指定します。
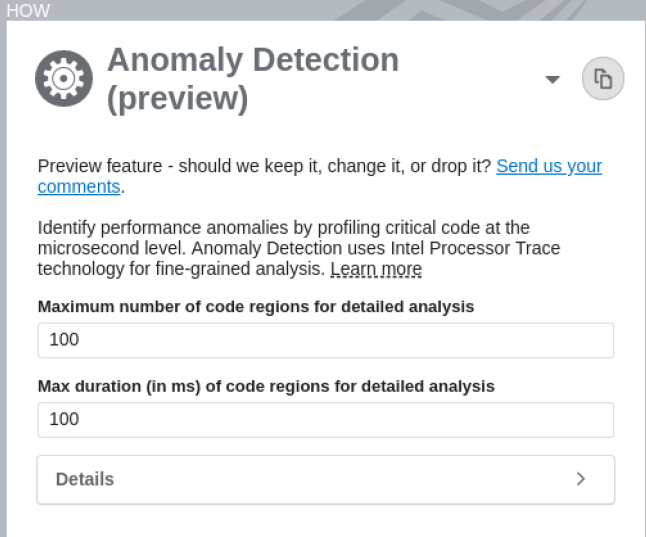
- [HOW (どのように)] ペインで以下のパラメーターを指定して、解析で収集するデータの量を定義します。
引数 説明 範囲 推奨値 Maximum number of code regions for detailed analysis (詳細に解析するコード領域の最大数) 結果を解析するため、同時に詳細をロードするアプリケーションのコード領域インスタンスの最大数を指定します。 10-5000 詳細をより速く表示するには、1000 以下の値を選択してください。 Maximum duration of code regions for detailed analysis (詳細に解析するコード領域の最大時間) コード領域の各インスタンスの解析に費やす最大時間 (ミリ秒) を指定します。指定した時間よりも長い時間を必要とするインスタンスは、無視されるか、ロードされません。 0.001-1000 1000 ミリ秒以下の任意の値。また、大量のデータは処理効率を低下させる可能性があるため、データ収集を制限するオプション (英語) も検討してください。 
- [Start (開始)] ボタンをクリックして、解析を実行します。
異常を特定する
- 解析が完了したら [Summary (サマリー)] ウィンドウに切り替えます。[Code Region of Interest Duration Histogram (注目するコード領域の時間ヒストグラム)] を確認します。
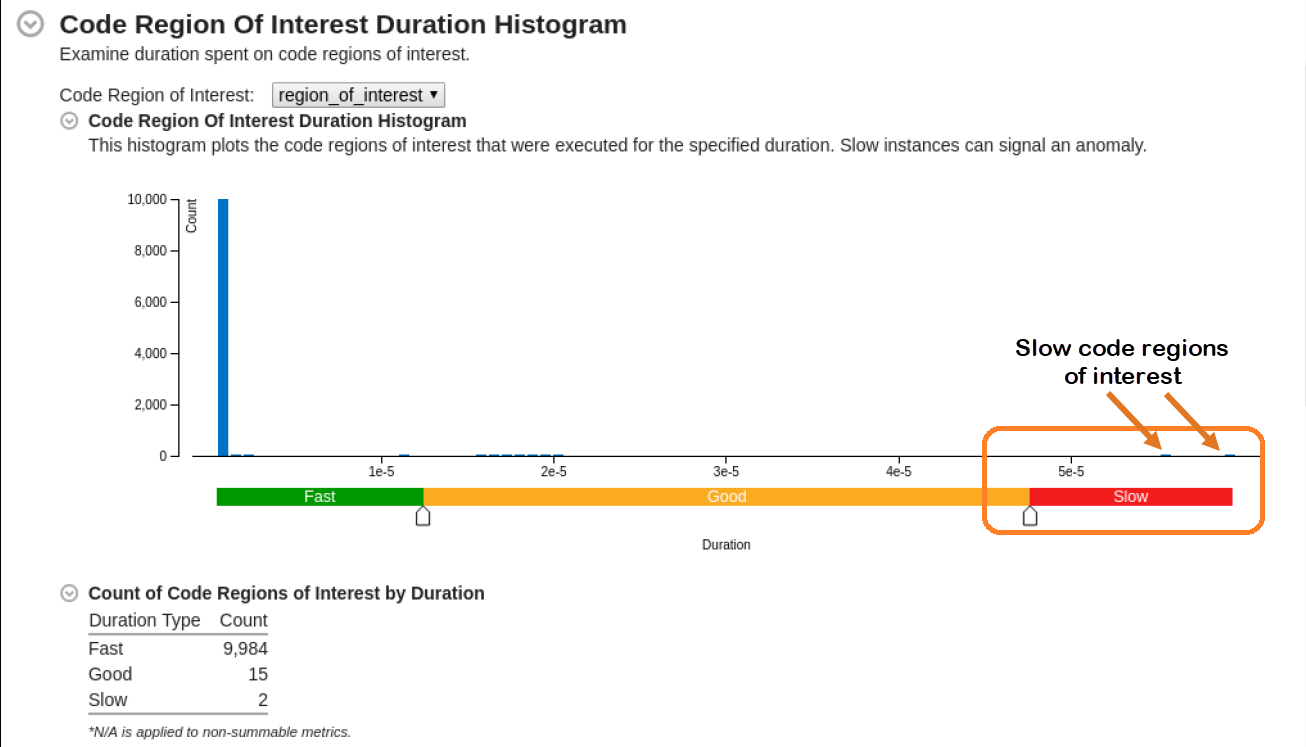
- パフォーマンスが低い場合は、ヒストグラムのスライダーを動かして、パフォーマンスの異常値を表示します。
- [Bottom-up (ボトムアップ)] ウィンドウに切り替えます。
- グループ化したテーブルに注目する遅いコード領域の詳細をロードします。
- 表示を展開して [Fast (高速)] と [Slow (低速)] 領域を表示します。
- テーブルの [Slow (低速)] 領域を右クリックします。
- ポップアップ・メニューで [Load Intel Processor Data by Selection (選択したインテル(R) プロセッサー・データをロード)] を選択します。
調査する異常を選択する
データをロードしたら [Intel Processor Trace Details (インテル(R) Processor Trace の詳細)] ビューに切り替えます。遅いコード領域で収集された情報を調査します。
この例では、Inactive Time (インアクティブ時間) と Wait Time (待機時間) メトリックがゼロです。これは、コンテキスト・スイッチが発生しなかったことを示しています。

非ゼロのカーネル時間は、予期しないカーネル・アクティビティーを見つける手掛かりになります。
この例では、[Code Region of Interest Duration Histogram (注目するコード領域の時間ヒストグラム)] から、2 つの注目する遅いコード領域が見つかりました。カーネル CPU 時間の値が大きいコード領域インスタンス 10001 から調査を開始します。
カーネル・アクティビティーの異常を調査する
最初の異常は領域 10001 にあります。
各コード領域の実行内容を見てみます。テーブルで領域のノードを展開して、ノードで実行された関数のリストを確認します。
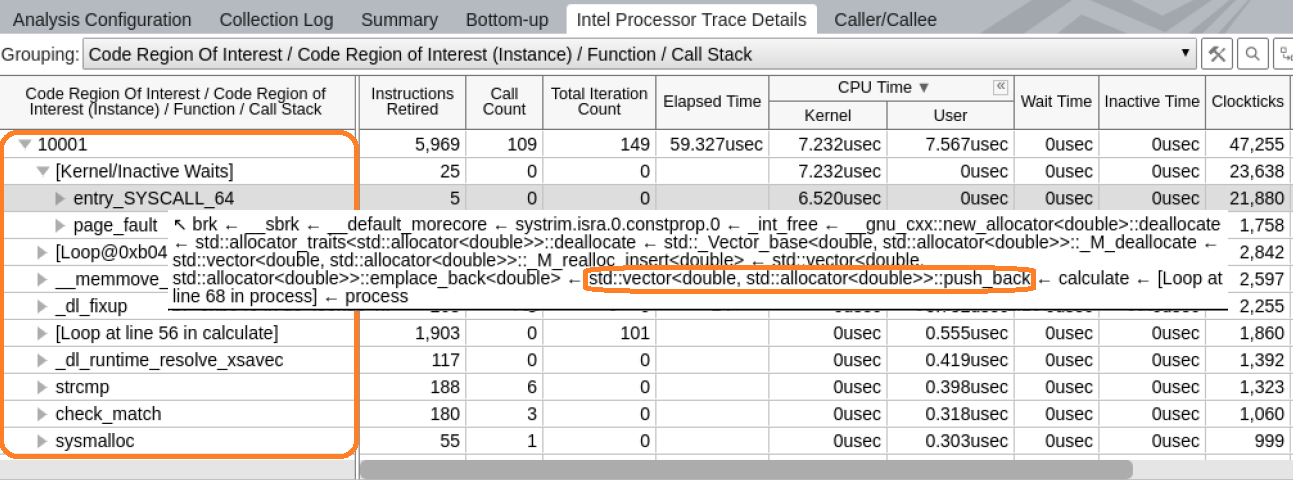
この例では、Kernel/Inactive Waits 要素が関数リストのトップにあります。Linux* カーネルは動的なコード変更を採用しているため、カーネルのバイナリーを静的に解析しても、カーネルの制御フローを完全に再構築することはできません。このノードは、特定の注目するコード領域を実行中に発生したカーネル・アクティビティーのすべてのパフォーマンス・データを集約しています。
カーネルのバイナリーは処理されていないため、Call Count (呼び出し回数)、Iteration Count (反復回数)、Instructions Retired (リタイアした命令) などの制御フローメトリックを再構築することはできません。Call Count (呼び出し回数) と Iteration Count (反復回数) はゼロですが、Instructions Retired (リタイアした命令) はカーネルへのエントリー数を示しています。
このノードのスタックには、カーネル・エントリー・ポイントを含む完全な関数呼び出しシーケンスが含まれます。この情報からアプリケーションがカーネルへ制御を移した理由が分かります。
Kernel/Inactive Waits 要素のコールスタックは、calculate メソッドから std::vector の push_back メソッドを呼び出すことで増えています。この関数をダブルクリックして [Source (ソース)] ビューで開きます。
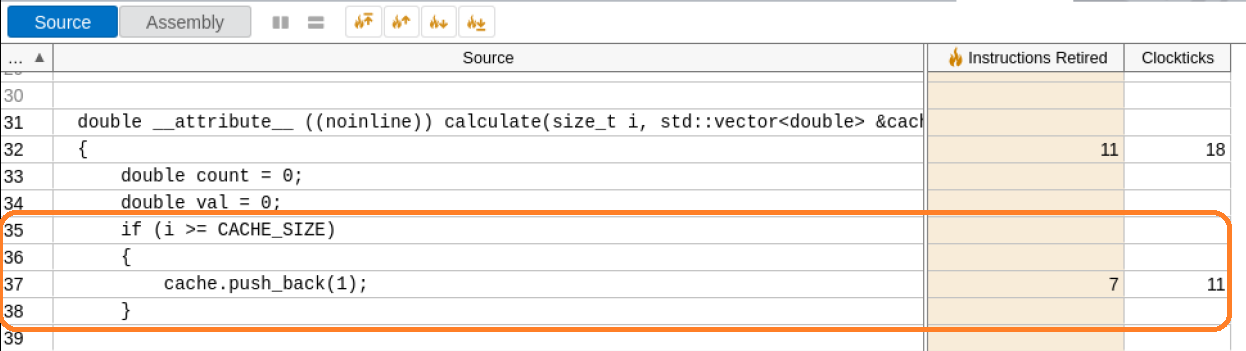
詳しく調査することで異常の原因が分かります。
問題
計算が内部ソフトウェア・キャッシュ・サイズを超過して、キャッシュに新しい要素を追加しています。
解決策
ソフトウェア・キャッシュのサイズを増やします。
制御フローの逸脱異常を調査する
次に、ヒストグラムで見つけた別の種類の異常を調査します。この場合、Instruction Retired (リタイアした命令) メトリックが異常に高いです。
これは、そのコード領域の実行中に制御フローの逸脱があったことを示しています。グリッド内のノードを展開して実行された関数を確認すると、一見何も異常がないように見えます。
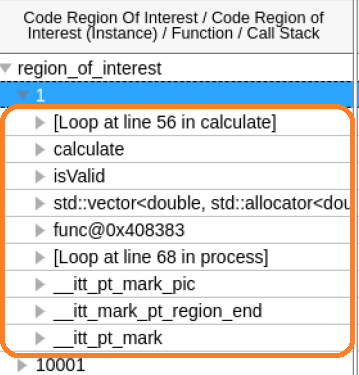
速い反復と遅い反復の詳細を一緒ロードして比較します。
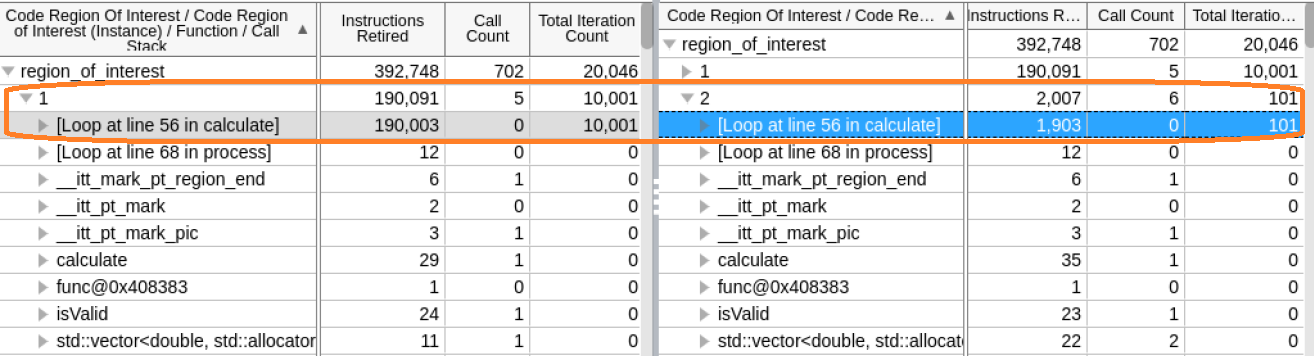
実行された関数のリストは同じですが、異常なインスタンスでは calculate 関数のループ反復回数が多いことが分かります。
[Source (ソース)] ビューで calculate 関数を開いて、速いインスタンスと遅いインスタンスの両方を確認します。
速いインスタンスでは、isValid 条件が満たされ、データ要素がキャッシュにあります。

遅いインスタンスでは、isValid 条件が満たされず、キャッシュ内のデータ要素の検証に失敗します。else 節が有効になり、追加の計算が実行されます。

問題
キャッシュに有効なデータがない遅い反復では、追加の計算が発生しています。
解決策
計算を開始する前にキャッシュデータを更新するか、キャッシュ・アルゴリズムを変更します。
注
このレシピの情報は、インテル® VTune™ プロファイラー・デベロッパー・フォーラム (英語) を参照してください。
関連情報
インテル® VTune™ プロファイラー・パフォーマンス解析クックブックのトップに戻る
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
