
この記事は、インテル® デベロッパー・ゾーンに公開されている「Using Intel® VTune™ Profiler to Optimize Workloads on Intel® Max Series CPUs & GPUs」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
概要
- インテル® oneAPI ツールの 2023.1 リリースには、開発者がインテル® マックス・シリーズ製品ファミリーの CPU および GPU 上でマルチアーキテクチャー・パフォーマンスを最大限に活用できるようにするインテル® VTune™ プロファイラーの機能強化が含まれています。
- インテル® マックス・シリーズ製品ファミリーの CPU および GPU は、画期的なパフォーマンスを提供し、多くの AI および HPC アプリケーションで課題となるメモリー依存ワークロードのボトルネックを解消します。CPU は、高帯域幅メモリー (HBM) を備えた最初で唯一の x86 ベースのプロセッサーです。GPU は、1,000 億個を超えるトランジスターを 1 つのパッケージに詰め込み、最大 128 個の Xe コアを搭載しています。
- インテル® VTune™ プロファイラーは、開発者が CPU、GPU、FPGA 上で実行されるコードの問題を特定できるように最適化されています。インテル® CPU マックス・シリーズでは、ワークロードごとの HBM メモリーの使用状況を特定する HBM 固有のパフォーマンス・メトリックが含まれています。インテル® GPU マックス・シリーズでは、インテル® VTune™ プロファイラーを使用して、Xe リンクのクロスカード・トラフィックを可視化したり、スタック間トラフィック、スループット、帯域幅のボトルネックなどの問題を発見したり、CPU と GPU 間のトラフィックの不均衡を特定できます。
HPC と AI ワークロード向けにメモリーと計算を最大限に活用するインテル® マックス・シリーズ製品ファミリーの CPU と GPU
HPC コードは多種多様であり、ライフサイエンスや製造などのアプリケーションは計算依存で、地球システム、石油ガス、AI などのアプリケーションはメモリー依存である傾向があります。CPU では、メモリー帯域幅の進化が HPC や AI の計算パフォーマンスの進化に追いついていません。ワークロードのパフォーマンスも計算パフォーマンスに追いついておらず、コア数が増え、コアの拡張が進む一方で、コアにデータが効率良く供給されない状況となっています。GPU では、メモリー容量が小さいことが問題です。また、CPU と GPU 間のデータ移動オーバーヘッドが、パフォーマンスの低下と電力の浪費を招いてきました。
インテル® マックス・シリーズ製品ファミリーの CPU と GPU は、これらの課題に対応するため開発されました。
インテル® Xeon® プロセッサー・マックス・シリーズは、高帯域幅メモリー (HBM) を搭載した最初で唯一の x86 ベースのプロセッサーであり、実際の HPC および AI ワークロードにおいて、競合製品と比較して最大 4.8 倍のパフォーマンスを実現します1。次の特長を備えています。
- 4 つのタイルで構成され、インテルのエンベデッド・マルチダイ・インターコネクト・ブリッジ (EMB) テクノロジーを使用して接続された最大 56 個のパフォーマンス・コア。
- 64GB の超高帯域幅インパッケージ・メモリーと PCI Express 5.0 および CXL1.1 I/O のサポート。
- コアあたり最大 1.14GB の HBM 容量。
これにより、CPU 上で実行される HPC コードの大部分に対して、GPU レベルのメモリー帯域幅を供給します。さらに、帯域幅を最大限に活用して、以下の 3 つのメモリーモードでデータを効率良くプロセッサー・コアに提供します。
- HBM 専用 – 64GB 以下のワークロード向け
- HBM フラットモード – 64GB 以上のワークロード向けの HBM と DRAM を組み合わせたフラットメモリー領域
- HBM キャッシュモード – 64GB を超えるワークロードのパフォーマンスを向上する DRAM キャッシュ
インテル® データセンター GPU マックス・シリーズは、インテルで最も高性能かつ高密度の汎用ディスクリート GPU であり、1,000 億個以上のトランジスターを 1 つのパッケージに搭載し、インテルの GPU 計算ビルディング・ブロックである Xe コアを最大 128 個搭載しており、次の特長を備えています。
- ディスクリート SRAM テクノロジーに基づく 408MB の L2 キャッシュと 64MB の L1 キャッシュ。
- 最大 128 基のレイトレーシング・ユニットにより、サイエンティフィック・ビジュアライゼーションやアニメーションを高速化。
- AI を強化するインテル® Xe マトリクス・エクステンション (インテル® XMX) は、ディープ・シストリック・アレイを搭載し、単一のデバイスでベクトルと行列の機能を実現。
インテル® マックス・シリーズ製品ファミリーの CPU と GPU を組み合わせることで、CPU と GPU 間のコードの共有も容易になります。
ワークロードが HBM の恩恵を受けられるかどうか、またどのモードを使用すべきかをどのように判断すればよいのでしょうか? CPU と GPU 間のデータ・トラフィックを最適化するにはどうすればよいのでしょうか? これらの答えを見つけるため、インテル® VTune™ プロファイラーを使用します。
インテル® VTune™ プロファイラー: 1 つのツールで複数の CPU-GPU ワークロードを最適化
インテル® VTune™ プロファイラーは、CPU、GPU、または FPGA 上で実行するコードの速度を低下させる問題を特定する強力なパフォーマンス解析ツールです。
ワークロードは HBM の恩恵を受けらるか?
インテル® VTune™ プロファイラーを使用することで、インテル® Xeon® プロセッサー・マックス・シリーズで HBM を利用する際に、どのメモリーモードが最高のパフォーマンスを提供するかを特定できます。各モード (HBM、フラット、キャッシュ) でワークロードをプロファイルします。
以下の解析タイプを使用して HBM の利点を評価できます。
- メモリーアクセス解析
- マイクロアーキテクチャー全般解析 – [Analyze memory bandwidth (メモリー帯域幅を解析)] オプションをオンにする
- HPC パフォーマンス特性解析 – [Analyze memory bandwidth (メモリー帯域幅を解析)] オプションをオンにする
インテル® VTune™ プロファイラーには、ワークロードごとの HBM メモリーの使用状況の理解に役立つ HBM 固有のパフォーマンス・メトリックがあります。以下のビューポイントを確認して、HBM メモリーに関するワークロードのパフォーマンスを分析できます。
Bandwidth Utilization Histogram (帯域幅使用率のヒストグラム)
[Summary (サマリー)] ウィンドウの [Bandwidth Utilization (帯域幅使用率)] セクションに 2 つの HBM 固有のメトリック 「HBM, GB/sec」と「HBM Single-Package, GB/sec」が追加されました (図 1)。DRAM 帯域幅に似ていますが、HBM に関連したデータが表示されます。
帯域幅使用率のヒストグラムは、HBM メモリーの使用率を「Low (低)」、「Medium (中)」、「High (高)」のカテゴリーで理解するのに役立ちます。
シングルパッケージ・ドメインは、CPU パッケージが 2 つ以上あるシステムで表示され、ヒストグラムは、すべてのパッケージの最大帯域幅使用率ごとの経過時間の分布を示します。このデータから、アプリケーションが CPU パッケージのサブセットでのみ帯域幅を使用している状況を特定できます。
そのような状況では、DRAM のようなドメインで示されるシステム全体の帯域幅使用率は低いかもしれませんが、実際には帯域幅使用率によってパフォーマンスが制限されています。[Bottom-up (ボトムアップ)] ウィンドウに切り替えて、グリッドデータを [../Bandwidth Utilization Type/.. (../帯域幅使用率のタイプ/..)] でグループ化し、特定の帯域幅ドメインで高い帯域幅使用率を持つ関数またはメモリー・オブジェクトを特定できます。
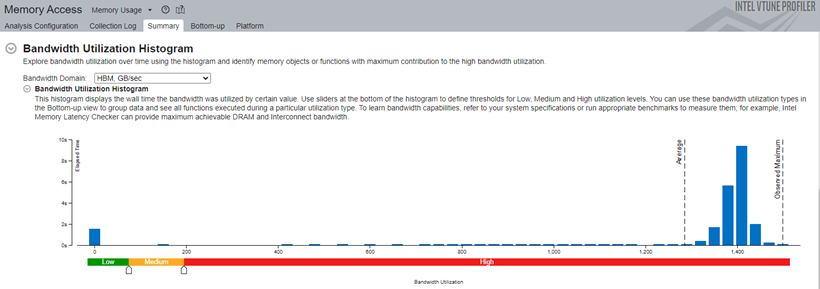
図 1: 帯域幅の分布
[Timeline (タイムライン)] ペイン
ワークロードの帯域幅の問題を経時的に特定するには、[Bottom-up (ボトムアップ)] ウィンドウの上部にある [Timeline (タイムライン)] ペインに注目します (図 2)。
[Timeline (タイムライン)] ペインには、CPU パッケージごとに分割された HBM 帯域幅のタイムライン・ビューがあり、HBM Read/Write Bandwidth (HBM リード/ライト帯域幅) および HBM Bandwidth (total) (HBM 帯域幅 (合計)) グラフが含まれます。領域を選択して帯域幅グラフの特定の部分に注目したり、右側の [HBM Bandwidth (HBM 帯域幅)] チェックボックスを使用してグラフをフィルター処理できます。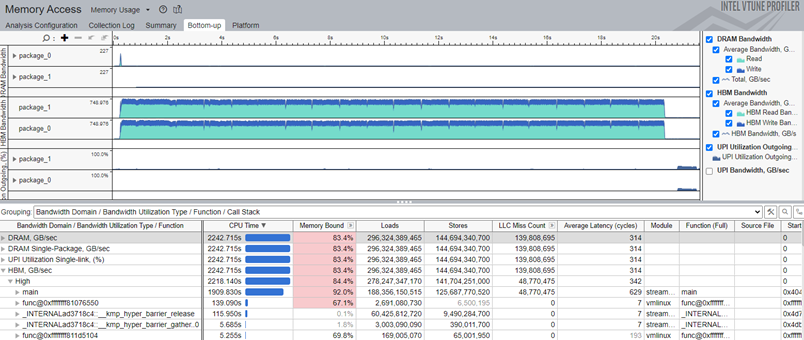
図 2. 各 HBM モードで収集を実行し、前述のように帯域幅を分析することで、各 HBM モードのワークロード・パフォーマンスを評価できます。
CPU と GPU 間のデータ・トラフィックを最適化するには?
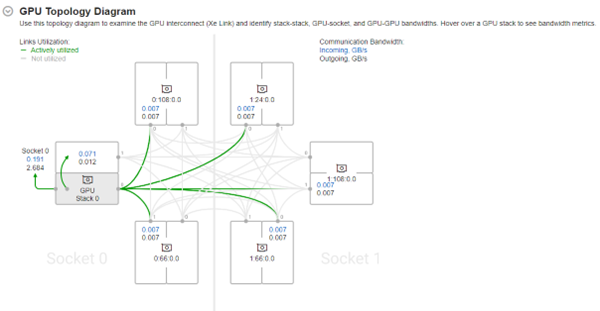
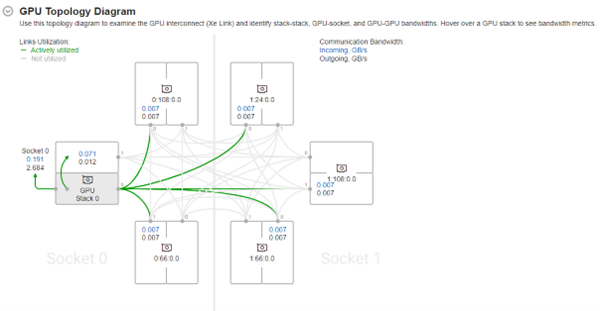
スタック間のトラフィックやスループット、および帯域幅のボトルネックなど、インテル® データセンター GPU マックス・シリーズ上のインテル® Xe リンクで接続されたデバイス間のトラフィックの可視化にもインテル® VTune™ プロファイラーを使用できます。CPU と GPU 間のトラフィックの不均衡を特定するには、GPU トポロジー・ダイアグラムが役立ちます。
以下の解析タイプを使用して Xe リンクのクロスカード相互接続の利点を評価できます。
- GPU オフロード解析 – [Analyze Xe Link usage (Xe リンクの使用を解析)] オプションをオンにする
- GPU 計算/メディア・ホットスポット解析 – [Analyze Xe Link usage (Xe リンクの使用を解析)] オプションをオンにする
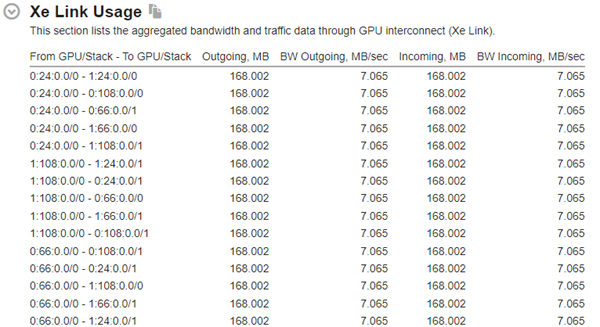
インテル® VTune™ プロファイラーには、Xe リンクのトラフィックと帯域幅の観測機能が含まれており、ワークロードによるカード間のメモリー転送と Xe リンクの利用状況を把握するのに役立ちます。Xe リンクによるカード間の全体的なトラフィックと帯域幅のグリッドは、結果の [Summary (サマリー)] ビューで確認できます。
また、カード間、スタック間、カード-ソケット間の帯域幅は、[Summary (サマリー)] の [GPU Topology Diagram (GPU トポロジー・ダイアグラム)] に表示されます。これは、システムの GPU トポロジーを理解し、ホバーリングで領域を選択して正確なリンク、スタック、またはカードの通信帯域幅を見積もるのに役立ちます。
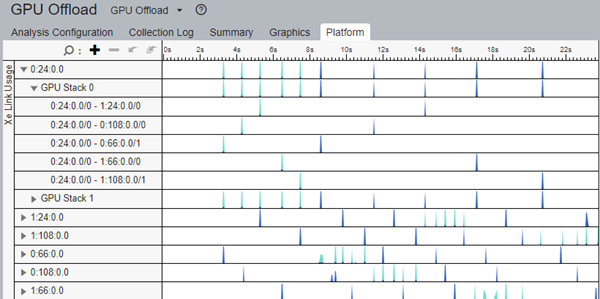
カード間のメモリー転送を更に詳しく解析するには、プラットフォーム・パネルのタイムラインを使用できます。帯域幅のタイムライン表示により、ワークロードのさまざまな段階での Xe リンクの使用量を確認し、最大限に活用し、コードの実行と関連付けることができます。
インテル® VTune™ プロファイラーをダウンロード (英語) して、サンプルコード (英語) をお試しください。
訳者注: iSUS ではインテル® VTune™ プロファイラーの GUI を日本語化する日本語パッケージを提供しています。ご利用のバージョンに合わせて対応する日本語パッケージをこちらから入手してください。また、インテル® VTune™ プロファイラー 2023 対応の日本語ヘルプもこちらでご覧いただけます。
製品および性能に関する情報
1ワークロードとシステム構成については、SuperComputing '22 のパフォーマンス指標サイト (英語) を参照してください。性能は、使用状況、構成、その他の要因によって異なります。構成の詳細を確認してください。絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。
2 性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
