
この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「False Sharing」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピは、インテル® VTune™ Amplifier の全般解析とメモリーアクセス解析を使用してメモリー依存の linear_regression アプリケーションをプロファイルします。
コンテンツ・エキスパート: Dmitry Ryabtsev (英語)
注
全般解析は、インテル® VTune™ Amplifier 2019 でマイクロアーキテクチャー全般解析に改名されました。
使用するもの
以下は、パフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: linear_regression。linear_regression.tgz サンプルパッケージは、製品の <install-dir>/samples/en/C++ ディレクトリーに含まれています。https://github.com/kozyraki/phoenix/tree/master/sample_apps/linear_regression (英語) からダウンロードすることもできます。
- パフォーマンス解析ツール:
- インテル® VTune™ Amplifier 2018: 全般解析、メモリーアクセス解析
注
- インテル® VTune™ プロファイラー評価版のダウンロードと製品サポートについては、https://www.isus.jp/intel-vtune-amplifier-xe/ を参照してください。
- このクックブックのレシピはすべてスケーラブルであり、インテル® VTune™ Amplifier 2018 以降に適用できます。バージョンにより設定がわずかに異なることがあります。
- ベータ版インテル® oneAPI ベース・ツールキット向けのバージョンから、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。引き続き、インテル® Parallel Studio XE またはインテル® System Studio のコンポーネントとして、あるいはスタンドアロン版のインテル® VTune™ プロファイラーをご利用いただけます。
- インテル® VTune™ Amplifier 2018: 全般解析、メモリーアクセス解析
- オペレーティング・システム: Ubuntu* 16.04 64 ビット
- CPU: インテル® Core™ i7-6700K プロセッサー
全般解析を実行する
サンプル・アプリケーションの潜在的なパフォーマンス・ボトルネックを理解するため、まず、インテル® VTune™ Amplifier の全般解析を実行します。
- ツールバーの [New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: linear_regression) を指定します。
- [Analysis Target (解析ターゲット)] ウィンドウで、ホストベースの解析として [local host (ローカルホスト)] ターゲット・システム・タイプを選択します。
- [Launch Application (アプリケーションを起動)] ターゲットタイプを選択して、右ペインで解析するアプリケーションを指定します。
- 右の [Choose Analysis (解析の選択)] ボタンをクリックし、[Microarchitecture Analysis (マイクロアーキテクチャー解析)] > [General Exploration (全般)] を選択して、[Start (開始)] をクリックします。
インテル® VTune™ Amplifier は、アプリケーションを起動してデータを収集し、収集したデータをファイナライズして、シンボル情報を解決します。この情報は、ソース解析で必要になります。
ボトルネックを特定する
ハードウェア・メトリックごとのアプリケーション・レベルの統計が表示される [Summary (サマリー)] ビューから始めます。
一般に、パフォーマンス解析では、ベースラインを作成して以降の最適化を測定することを推奨します。このケースでは、アプリケーションの [Elapsed Time (経過時間)] をベースラインとして使用します。
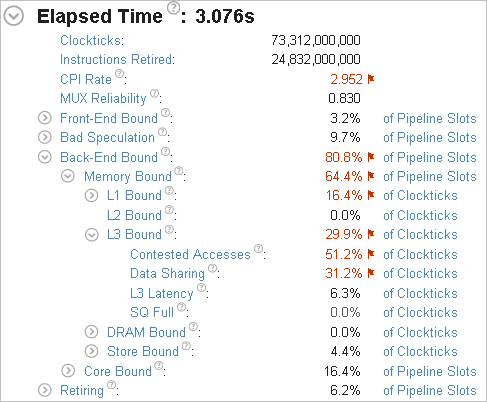
サマリーメトリックから、メモリーアクセスの競合によりアプリケーションのパフォーマンスが制限されていることが分かります。
競合するデータ構造を見つける
[Contested Accesses (アクセス競合)] メトリックの値が高い原因を調べるため、[Analyze dynamic memory objects (動的メモリー・オブジェクトを解析)] オプションを有効にしてメモリーアクセス解析を実行します。この解析は、競合問題の原因になっているデータ構造へのアクセスを見つけるのに役立ちます。
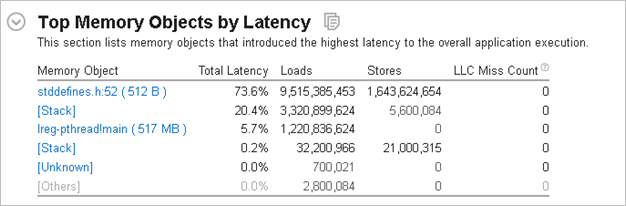
[Summary (サマリー)] ビューから、ファイル stddefines.h の行 52 のメモリー割り当てデータ・オブジェクトでアプリケーション実行のレイテンシーが高くなっていることが分かります。割り当てのサイズは 512 バイトと非常に小さいため、L1 キャッシュに完全に収まるはずです。詳細を確認するため、このオブジェクトをクリックして [Bottom-up (ボトムアップ)] ビューに切り替えます。
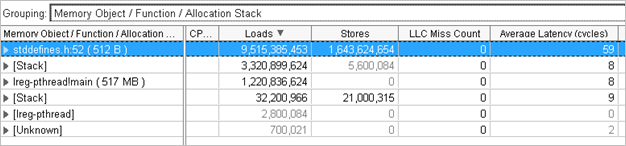
このオブジェクトの平均アクセス・レイテンシーは 59 サイクルと、L1 キャッシュ上にあると予想されるメモリーサイズとしては非常に高い値になっています。これがアクセス競合パフォーマンス問題の原因になっている可能性があります。
グリッドの stddefines.h:52 (512B) メモリー・オブジェクトを展開して割り当てスタックを表示します。割り当てスタックをダブルクリックして [Source (ソース)] ビューを開きます。オブジェクトが割り当てられているコード行がハイライトされます。
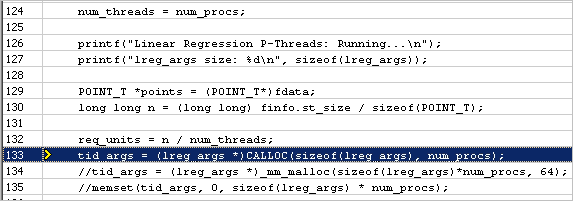
lreg_args の内容を次に示します。
typedef struct
{
pthread_t tid;
POINT_T *points;
int num_elems;
long long SX;
long long SY;
long long SXX;
long long SYY;
long long SXY;
} lreg_args;
次のように、lreg_args 配列にアクセスしているコードをスレッド化します。
// ADD Up RESULTS
for (i = 0; i < args->num_elems; i++)
{
//Compute SX, SY, SYY, SXX, SXY
args->SX += args->points[i].x;
args->SXX += args->points[i].x*args->points[i].x;
args->SY += args->points[i].y;
args->SYY += args->points[i].y*args->points[i].y;
args->SXY += args->points[i].x*args->points[i].y;
}
各スレッドは別々に配列の要素にアクセスしているため、フォルス・シェアリング問題が考えられます。
サンプルの lreg_args 構造のサイズは 64 バイトで、キャッシュラインのサイズと一致しています。しかし、これらの構造の配列を割り当てるときに、この配列が 64 バイトでアライメントされる保証はありません。その結果、配列要素がキャッシュライン境界を超えて、意図しない競合問題 (フォルス・シェアリング) が発生することがあります。
フォルス・シェアリング問題を修正する
このフォルス・シェアリング問題を修正するため、メモリーを 64 バイト・アライメントで割り当てる _mm_malloc 関数に変更します。
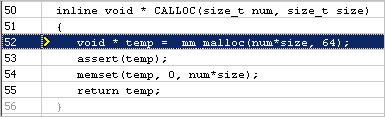
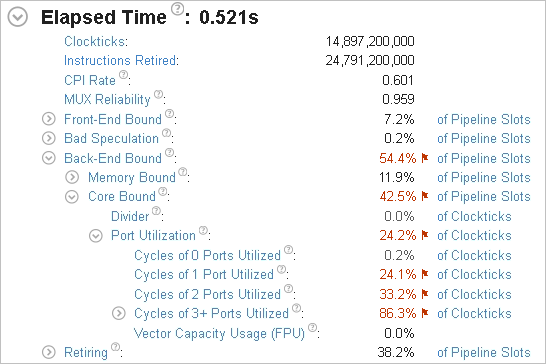
再コンパイルしてインテル® VTune™ プロファイラーのアプリケーション解析を再度実行すると、結果は次のようになりました。
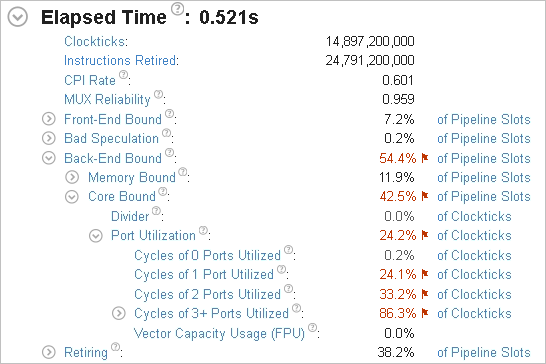
Elapsed Time (経過時間) は 0.5 秒になり、オリジナルの 3 秒からパフォーマンスが大幅に向上しました。メモリー依存のボトルネックが解消し、フォルス・シェアリング問題が修正されました。
注
このレシピの情報は、デベロッパー・フォーラム (英語) を参照してください。
関連情報
- マイクロアーキテクチャー全般解析 (英語)
- メモリーアクセス解析 (英語)
- トップダウン・マイクロアーキテクチャー解析法
