
この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「PMDK Application Overhead」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピは、PMDK ベースのアプリケーションのメモリーアクセスのオーバーヘッドを検出して修正する方法を説明します。
コンテンツ・エキスパート: Kirill Uhanov (英語)
不揮発性メモリー開発キット (PMDK) は、データの一貫性と耐久性を維持するためのトランザクションおよびアトミック操作のサポートを提供します。Linux* と Windows* の両方で利用可能なオープンソースのライブラリーとツールのコレクションです。詳細は、不揮発性メモリー・プログラミングのウェブサイト pmem.io (英語) を参照してください。PMDK は、高水準言語のサポートにより、不揮発性メモリー・プログラミングの採用を容易にします。現在、完全に検証済みの C/C++ サポートを Linux* で利用できます。Windows* では早期アクセスとして利用できます。
インテルの新世代の不揮発性メモリーは、メモリー層とストレージ層に加え、DRAM よりも大容量でストレージよりも高速な第 3 のメモリー層を提供します。アプリケーションは、従来のメモリーと同様に不揮発性メモリー内のデータ構造にアクセスでき、メモリーとストレージ間のデータブロック転送の必要性を排除します。
しかし、PMDK ライブラリーを利用すると、アプリケーションのパフォーマンスに影響することがあります。このレシピでは、インテル® VTune™ Amplifier でそのような問題を検出する方法を説明します。
使用するもの
以下は、パフォーマンス解析シナリオで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: PMDK メモリー・アロケーターを使用して 2 つのベクトルの要素単位の合計を計算するサンプル・アプリケーション
- コンパイラー: GNU* コンパイラー。次のコンパイラー/リンカーオプションを指定します。
gcc -c -o array.o -O2 -g -fopenmp -I <pmdk-install-dir>/src/include -I <pmdk-install-dir>/src/examples array.c
gcc -o arrayBefore array.o -fopenmp -L <pmdk-install-dir>/src/nondebug -lpmemobj -lpmem -pthread
- パフォーマンス解析ツール: インテル® VTune™ Amplifier 2018: メモリーアクセス解析/高度な hotspot 解析
注
- インテル® VTune™ プロファイラー評価版のダウンロードと製品サポートについては、https://www.isus.jp/intel-vtune-amplifier-xe/ を参照してください。
- このクックブックのレシピはすべてスケーラブルであり、インテル® VTune™ Amplifier 2018 以降に適用できます。バージョンにより設定がわずかに異なることがあります。
- ベータ版インテル® oneAPI ベース・ツールキット向けのバージョンから、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。引き続き、インテル® Parallel Studio XE またはインテル® System Studio のコンポーネントとして、あるいはスタンドアロン版のインテル® VTune™ プロファイラーをご利用いただけます。
- オペレーティング・システム: Ubuntu* 16.04 LTS
- CPU: インテル® Core™ i7-6700K プロセッサー @ 4.00GHz
PMDK アプリケーションのメモリーアクセス解析を実行する
このレシピは、不揮発性メモリーを利用するサンプル・アプリケーションから始めます。このアプリケーションは、よく知られている STREAM ベンチマークの Triad カーネルを使用して、DRAM 帯域幅を最大限に利用します。
統計解析向けに大きく測定可能な計算処理にするため、ループでベクトル合計計算を繰り返しています。
#include <ex_common.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/stat.h>
#include <libpmemobj.h>
#include <omp.h>
#define REPEATS 32
POBJ_LAYOUT_BEGIN(array);
POBJ_LAYOUT_TOID(array, int);
POBJ_LAYOUT_END(array);
int
main()
{
size_t size = 82955000;
size_t pool_size = 16200000000;
int i,j;
int multiplier = 3;
PMEMobjpool *pop;
char* path = "test_file1";
if (file_exists(path) != 0)
{
if ((pop = pmemobj_create(path, POBJ_LAYOUT_NAME(array),
pool_size, CREATE_MODE_RW)) == NULL)
{
printf("failed to create pool\n");
return 1;
}
}
else
{
if ((pop = pmemobj_open(path, POBJ_LAYOUT_NAME(array))) == NULL)
{
printf("failed to open pool\n");
return 1;
}
}
TOID(int) a;
TOID(int) b;
TOID(int) c;
POBJ_ALLOC(pop, &a, int, sizeof(int) * size, NULL, NULL);
POBJ_ALLOC(pop, &b, int, sizeof(int) * size, NULL, NULL);
POBJ_ALLOC(pop, &c, int, sizeof(int) * size, NULL, NULL);
for (i = 0; i < size; i++)
{
D_RW(a)[i] = (int)i;
D_RW(b)[i] = (int)i+100;
D_RW(c)[i] = (int)i+3;
}
pmemobj_persist(pop, D_RW(a), size * sizeof(*D_RW(a)));
pmemobj_persist(pop, D_RW(b), size * sizeof(*D_RW(b)));
pmemobj_persist(pop, D_RW(c), size * sizeof(*D_RW(c)));
for (j = 0; j < REPEATS; j++)
{
#pragma omp parallel for
for (i = 0; i < size; i++)
{
D_RW(c)[i] = multiplier * D_RO(a)[i] + D_RO(b)[i];
}
}
POBJ_FREE(&a);
POBJ_FREE(&b);
POBJ_FREE(&c);
pmemobj_close(pop);
return 0;
}
サンプルコード内のパフォーマンスの問題を特定し、メモリーアクセスに費やされた時間を予測するには、インテル® VTune™ Amplifier を起動してメモリーアクセス解析を実行します。
- ツールバーの [New Project (新規プロジェクト)] ボタンをクリックして、新規プロジェクトの名前 (例: arraysum) を指定します。
- [Analysis Target (解析ターゲット)] ウィンドウで、ホストベースの解析として [local host (ローカルホスト)] ターゲット・システム・タイプを選択します。
- [Launch Application (アプリケーションを起動)] ターゲットタイプを選択して、右ペインで解析するアプリケーションを指定します。
- 右の [Choose Analysis (解析の選択)] ボタンをクリックし、[Microarchitecture Analysis (マイクロアーキテクチャー解析)] > [Memory Access (メモリーアクセス)] を選択して、[Start (開始)] をクリックします。
インテル® VTune™ Amplifier は、アプリケーションを起動してデータを収集し、収集したデータをファイナライズして、シンボル情報を解決します。この情報は、ソース解析で必要になります。
PMDK ベースのアプリケーションの hotspot を特定する
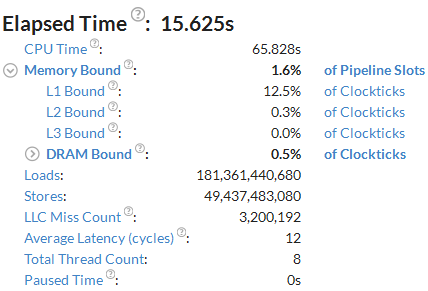
ハードウェア・メトリックごとのアプリケーション・レベルの統計が表示される [Summary (サマリー)] ビューから解析を始めます。通常、基本パフォーマンス・ベースラインはアプリケーションの経過時間です。このサンプルコードでは約 16 秒です。
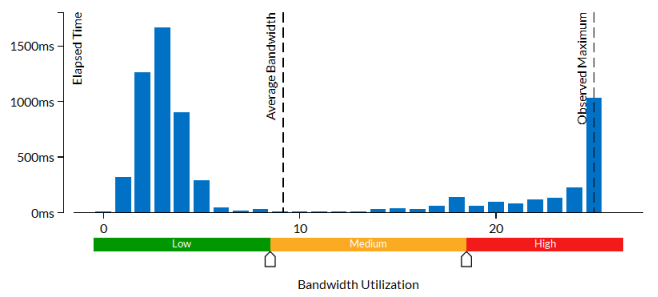
この PMDK コードでは高い DRAM 使用率が予測されましたが、 [Summary (サマリー)] ビューのメトリックはこのサンプル・アプリケーションを DRAM 帯域幅依存として定義していません。
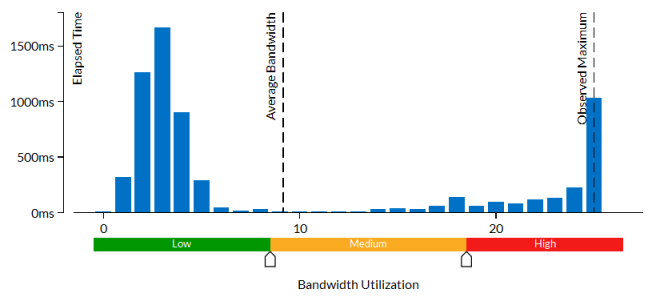
[Bandwidth Utilization Histogram (帯域幅利用率分布図)] もアプリケーションが DRAM 帯域幅を最大限に使用していないことを示しており、[Observed Maximum (観察された最大値)] は予想を大きく下回る約 13GB/秒です。
PMDK によりコードのオーバーヘッドが増えているのは明らかです。詳細を確認するため、[Bottom-up (ボトムアップ)] ビューに切り替えて [Function/Call Stack (関数/コールスタック)] グループレベルを適用します。
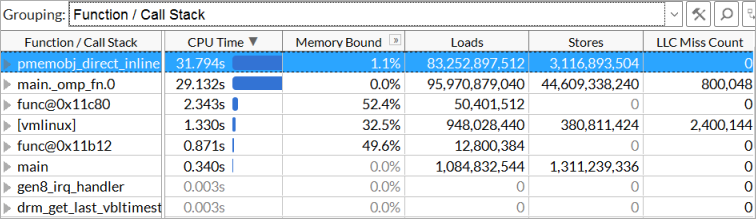
最も大きな hotspot は pmemobj_direct_inline です。この関数は、D_RO マクロと D_RW マクロから呼び出されています。関数をダブルクリックして、<pmdk-install-dir>/src/include/libpmemobj/
types.h にあるソースコードを表示します。
#define DIRECT_RW(o) \
(reinterpret_cast < __typeof__((o)._type) > (pmemobj_direct((o).oid)))
#define DIRECT_RO(o) \
(reinterpret_cast < const __typeof__((o)._type) > \
(pmemobj_direct((o).oid)))
#endif /* (defined(_MSC_VER) || defined(__cplusplus)) */
#define D_RW DIRECT_RW
#define D_RO DIRECT_RO
注
アプリケーション実行中の DRAM 帯域幅の使用状況を視覚化するには、[Platform (プラットフォーム)] ビューを使用します。DRAM 帯域幅は、緑色と青色で表示されます。
冗長な PMDK 関数呼び出しを削除する
各配列のメモリーは 1 つのチャンクとして割り当てられるため、D_RO と D_RW は配列の開始アドレスを取得するため計算前に一度だけ呼び出します。
int* _c = D_RW(c);
const int* _a = D_RO(a);
const int* _b = D_RO(b);
for (j = 0; j < REPEATS; j++)
{
#pragma omp parallel for
for (i = 0; i < size; i++)
{
_c[i] = multiplier * _a[i] + _b[i];
}
}
アプリケーションを再コンパイルしメモリーアクセス解析を再度実行して、この変更がパフォーマンスにどのように影響したか確認します。

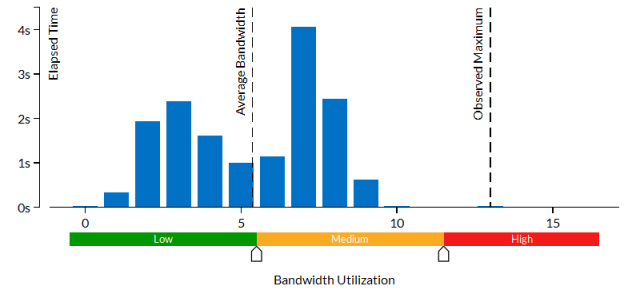
アプリケーションの経過時間が大幅に減ったことが分ります。PMDK オーバーヘッドはパフォーマンスに影響しません。
[Bandwidth Utilization Histogram (帯域幅利用率分布図)] はアプリケーションが DRAM 帯域幅を最大限に使用していないことを示しており、[Observed Maximum (観察された最大値)] は約 25GB/秒です。
注
このレシピの情報は、デベロッパー・フォーラム (英語) を参照してください。
