
この記事は、インテル® デベロッパー・ゾーンに掲載されている「Optimization Practice of Deep Learning Inference Deployment on Intel® Processors」(https://software.intel.com/en-us/articles/optimization-practice-of-deep-learning-inference-deployment-on-intel-processors) の日本語参考訳です。
この記事の PDF 版はこちらからご利用になれます。
動画共有サイト iQIYI では、人工知能 (AI) テクノロジーの使用拡大により、クラウドでディープラーニング (DL) をサポートするため、計算能力に対する需要が急速に高まっています。ディープラーニング・クラウド・プラットフォーム・チームの目標は、ディープラーニング・アプリケーションのデプロイメントの効率を改善し、クラウド・プラットフォームのランニングコストを軽減し、アルゴリズムとビジネスチームがアプリケーションとサービスを素早く適用できるようにし、AI が真の生産性を実現できるようにすることです。
CPU 上の推論サービスのパフォーマンスを向上し、GPU から CPU へサービスを移行してクラスター内の多数の CPU サーバーを利用することで、チームは CPU ベースのディープラーニング推論サービスを最適化し、計算リソースの節約に成功しました。
ディープラーニング推論サービスと最適化プロセス
ディープラーニング推論サービスの概要
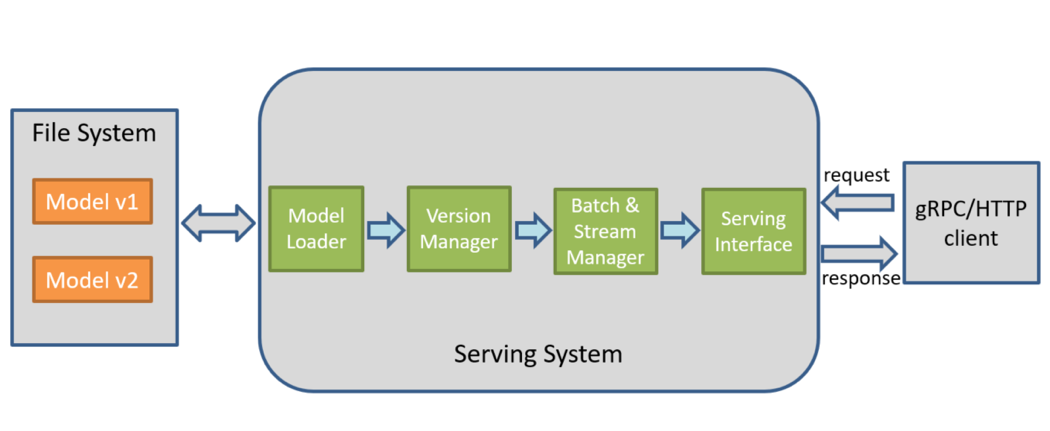
ディープラーニング推論サービスとは、通常、トレーニング済みのディープラーニング・モデルをクラウドにデプロイして、gRPC/HTTP インターフェイス・リクエストを提供することを指します。推論サービスの内部では、図 1 に示すように、モデル・ローディング、モデルバージョン管理、バッチ処理、マルチパスサポート、サービス・インターフェイスのカプセル化などの関数が実装されています。
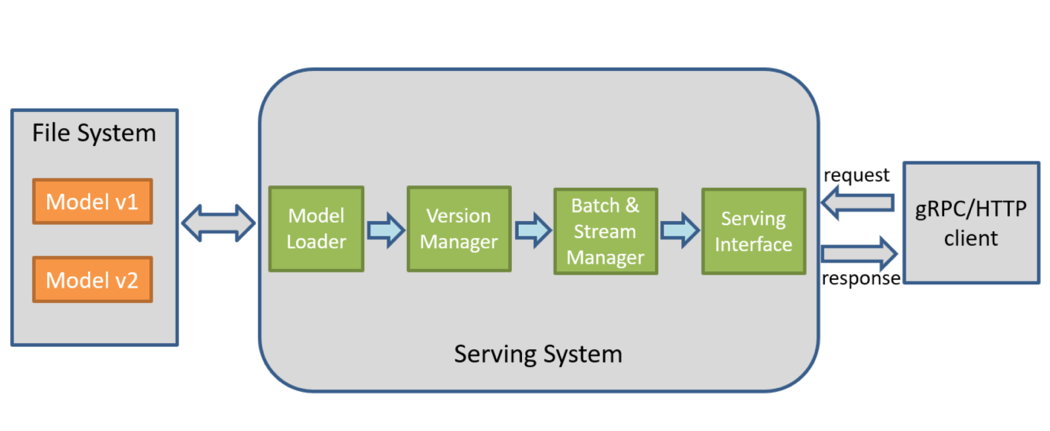
図 1: ディープラーニング推論サービスのワークフロー
業界で一般的に使用さているディープラーニング推論サービスは、TensorFlow* と Amazon* Elastic Inference です。現在、iQIYI のディープラーニング・クラウド・プラットフォーム Jarvis* は、TensorFlow* に基づいた推論サービスの自動デプロイメントを提供しています。サポートされるディープラーニング・フレームワークとツールには、TensorFlow*、Caffe、Caffe2、MXNet*、TensorRT に加えて、OpenVINO™ ツールキットと PyTorch* が含まれます。さらに、ビジネスチームは特定のディープラーニング・サービス・コンテナーをカスタマイズして、Docker* ベースのアプリケーション・エンジンを介してサービスを管理できます。
推論サービス・ワークフローの最適化
図 2 に示すように、サービスの最適化プロセスは、最適化の目標に向かって繰り返し移動するプロセスです。
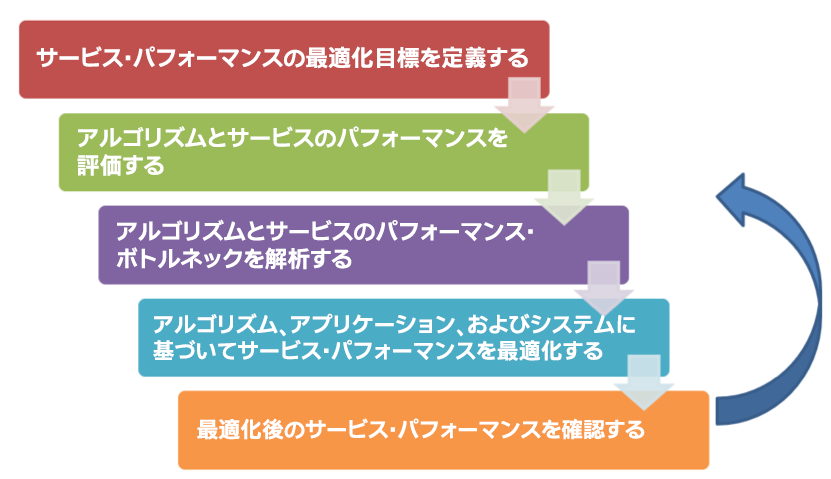
図 2. サービスの最適化プロセス
ディープラーニング推論サービスを最適化するには、サービスの最適化の目標を決定するため、最初にサービスのタイプと主要なパフォーマンス・メトリックを明確にする必要があります。システムリソースの観点から、ディープラーニング・サービスは、計算集約型と I/O 集約型に分類できます。例えば、畳み込みニューラル・ネットワーク (CNN) ベースの画像/ビデオ・アルゴリズムは、多くの場合計算要件が高いため、計算集約型サービスです。ビッグデータに依存する検索と推奨アルゴリズムは、高次元の特徴と膨大な量のデータを扱うため、通常 I/O 集約型サービスに分類されます。サービス品質の観点からは、レイテンシーに敏感なサービスとスループットが大きいサービスに分けることができます。例えば、通常、オンラインサービスのほとんどはレイテンシーに敏感なサービスで、短い応答時間が要求されます。一方、オフラインサービスは、バッチ処理される大きなスループットのサービスです。ディープラーニング・サービスの最適化の目標と手法は、サービスのタイプにより異なります。
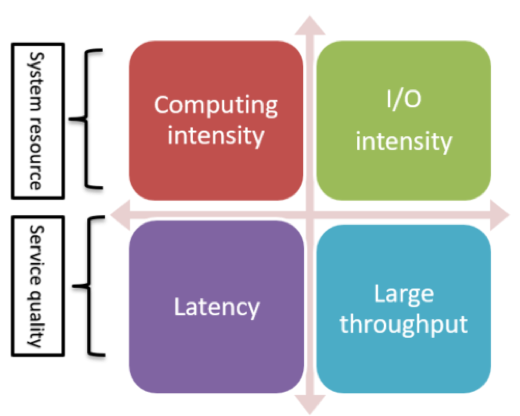
図 3. ディープラーニング推論サービス
ディープラーニング推論サービスのパフォーマンスの評価
ディープラーニング・サービスの主要パフォーマンス・メトリックには、図 4 に示すように、応答レイテンシー、スループット、およびモデル精度が含まれます。レイテンシーとスループットは、推論サービスの 2 つの主要メトリックです。主要メトリックが明確になったら、サービスの規模を解析し、各サービスのパフォーマンス要件を計算できます。
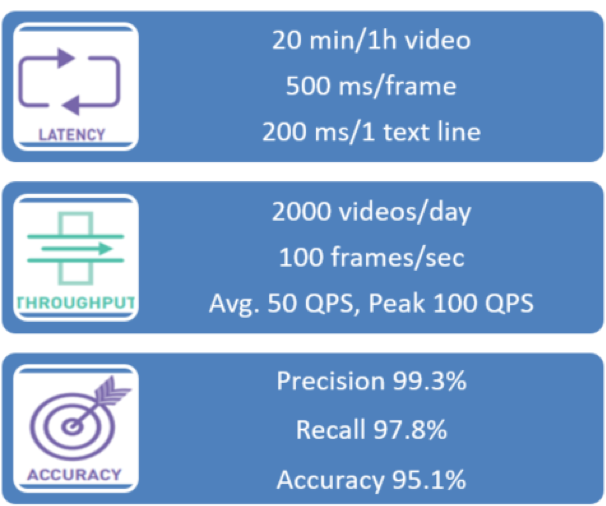
図 4. ディープラーニング推論サービスのパフォーマンス・メトリック
CPU でのディープラーニング推論サービスの最適化
CPU でのディープラーニングの最適化手法
CPU でのディープラーニング推論サービスの最適化手法は、システムレベル、アプリケーション・レベル、アルゴリズム・レベルに分けることができます。以下に示すとおり、各レベルには対応するパフォーマンス解析ツールがあります。
ディープラーニング・サービスの最適化手法とツール
| 最適化手法 | プロファイル・ツール |
|---|---|
| アルゴリズム | |
| ハイパーパラメーターの設定 精度モデルに関するモデル構造の最適化 |
TensorBoard* Visual DL |
| アプリケーション | |
| マルチプロセシング並列処理 非同期処理 | インテル® VTune™ Amplifier dtrace、strace、plockstat、lockstat |
| システム | |
| コンパイラー・オプション ディープ・ニューラル・ ネットワーク向けインテル® MKL (インテル® MKL-DNN) OpenVINO™ ツールキット |
perf、sar、numactl、iostat、vmstat、blktrace インテル® VTune™ Amplifier |
システムレベルの最適化は、ハードウェアとプラットフォームの両方の計算処理を高速化します。これには、SIMD 命令を利用するコンパイラーによる高速化、OMP ベースの数学ライブラリーを利用する並列計算の高速化、およびハードウェア・ベンダーによって提供されるディープラーニング・アクセラレーション SDK が含まれます。
アプリケーション・レベルの最適化は、主に特定のアプリケーションとサービスのパイプラインと並列性を向上します。通常のディープラーニング・サービスには、推論に加えて、データの前処理、後処理、およびネットワーク要求応答が含まれます。優れた並列処理設計は、サーバーのエンドツーエンドのパフォーマンスを効率良く向上します。
アルゴリズム・レベルの最適化は、ディープラーニング・モデル自体に注目して、ハイパーパラメーター設定、ネットワーク構造のクリッピング、および量子化によるモデルのサイズと演算強度の軽減などの手法を利用して、推論プロセスを高速化します。
システムレベルの最適化
CPU でのシステムレベルの最適化には、ディープ・ニューラル・ネットワーク向けインテル® マス・カーネル・ライブラリー (インテル® MKL-DNN) と OpenVINO™ ツールキットを使用します。どちらの手法も SIMD 命令による高速化を含みます。
数学ライブラリーの最適化は、一般的なディープラーニング・フレームワーク (TensorFlow*、Caffe、MXNet、PyTorch* など) を公式にサポートしています。例えば TensorFlow* の場合、インテル® Optimization for TensorFlow* のアップデートをダウンロードするか、以下のパラメーターで GitHub* のソースコードを直接ビルドします。『インテル® Optimization for TensorFlow* インストール・ガイド』 (英語) を参照してください。
以下は Linux* での使用例です。
Anaconda* のプロンプトを開いて、次のコマンドを実行します。
conda install tensorflow
インテル® MKL を使用してソースから Tensorflow* をビルドします。
bazel build --config=mkl -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mavx512f --copt=-mavx512pf --copt=-mavx512cd --copt=-mavx512er //tensorflow/tools/pip_package:build_pip_package
OpenVINO™ ツールキットによる最適化では、最初にネイティブ・ディープラーニング・モデルを変換して中間表現 (IR) を生成し、モデル・ローディングと推論サービスをカプセル化するため推論エンジンを呼び出します。図 5 にプロセスを示します。詳細な使用法はセクション 3 を参照してください。
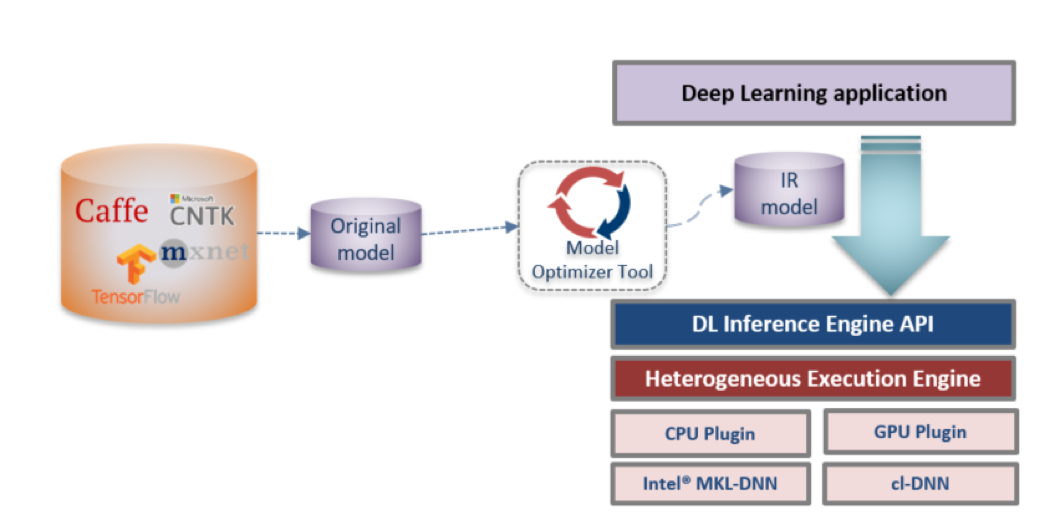
図 5. OpenVINO™ ツールキットによる推論の最適化プロセス
最適化手法の選択
2 つの最適化手法の比較を以下に示します。
インテルにより最適化されたフレームワークと OpenVINO™ ツールキットの比較
| インテル® MKL-DNN 最適化フレームワーク | OpenVINO™ ツールキット |
|---|---|
| 長所 | |
| 使いやすく、モデルを変更する必要がない 数学ライブラリー/OpenMP*/インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) による最適化を含む トレーニングと推論の両方のパフォーマンスを向上 一般的なフレームワークをサポート モデルの量子化と最適化をサポート |
数学ライブラリー/OpenMP*/インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) による最適化を含む 柔軟なモデルの最適化をサポート 複数のプラットフォームの最適化をサポート: インテル® CPU および GPU プロセッサー/インテル® Movidius™ ビジョン・プロセシング・ユニット (VPU)/インテル® FPGA モデルの量子化と最適化をサポート |
| 短所 | |
| 最適化されたパフォーマンスは OpenVINO™ ツールキット API ほど良くない インテル® CPU の最適化のみサポート |
推論の最適化のみサポート モデル・オプティマイザーでモデルを変換する必要がある OpenVINO™ ツールキット API を習得する必要がある |
2 つの最適化手法の特徴を考慮すると、最初にインテル® MKL-DNN ベースの最適化手法を使用してサービスのパフォーマンスをテストするとよいでしょう。この手法でサービス要件を満すことができれば、それを直接デプロイできます。より高いサービス要件が求められる場合は、OpenVINO™ ツールキットによる最適化手法を試します。
システム・パフォーマンスの最適化
次の要因は、上記の 2 つのシステムレベルの最適化手法のパフォーマンスに影響します。
- OpenMP* パラメーターの設定
どちらの推論最適化手法も、OpenMP* による並列計算の高速化を使用しているため、パラメーターの設定はパフォーマンスに大きく影響します。パラメーターの推奨設定は次のとおりです。
- OMP_NUM_THREADS = “コンテナー内の CPU コアの数”
- KMP_BLOCKTIME = 10
- KMP_AFFINITY=粒度 (fine、verbose、compact、1、0 から指定)
- デプロイされている CPU コアの数
バッチサイズは、推論サービスのパフォーマンスに影響します。オンラインサービスは一般に小さなバッチサイズのジョブで、オフラインサービスは多くの場合大きなバッチサイズのジョブです。
- 小さなバッチサイズのジョブ (オンラインサービス) では、CPU コアの数が増えるにつれて、推論スループットが低下します。実際のサービス・デプロイメントで推奨される CPU コアの数は 8 – 16 です。
- バッチサイズが大きい場合 (オフラインサービス)、CPU コアの数が増えるにつれて、推論スループットも直線的に向上します。20 コア以上の CPU を使用することを推奨します。
- CPU の種類
CPU 世代が異なると、CPU がサポートする SIMD 命令セットに応じてパフォーマンス・アクセラレーションが異なる場合があります。例えば、コア数が同じ場合、インテル® Xeon® Gold 6148 プロセッサーの平均推論パフォーマンスは、インテル® Xeon® プロセッサー E5-2650 v4 の約 2 倍です。これは主に、インテル® Xeon® Gold 6148 プロセッサーでは、インテル® アドバンスト・ベクトル・エクステンション 2 (インテル® AVX2) からインテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) に SIMD 命令セットがアップグレードされているためです。
- 入力データ形式
画像ベースのアルゴリズムを入力として使用する、TensorFlow* を除く多くのディープラーニング・フレームワークは、NCHW (バッチ内の画像の数、チャネル、高さ、幅) 形式の入力データを使用することを推奨しています。オリジナルの TensorFlow* フレームワークは、デフォルトで CPU 向けに NHWC(channels_last) 形式をサポートしています。インテル® Optimization for TensorFlow* は 2 つの入力データ形式をサポートします。これらのデータ形式の詳細は、TensorFlow* ガイドの「データ形式」を参照してください。
上記の 2 つの最適化手法を使用する場合、推論プロセスでのメモリーデータの再配置に起因するオーバーヘッドを軽減するため、NCHW 入力形式を推奨します。
- NUMA (Non-Uniform Memory Access) 構成
通常、同じノード上に NUMA を構成すると、異なるノードを使用する場合と比較して、パフォーマンスが 5% – 10% 向上します。
アプリケーションの最適化
アプリケーション・レベルの最適化では、最初にアプリケーションのすべての側面をエンドツーエンドでテストするパフォーマンス解析を実行してパフォーマンスのボトルネックを見つけ、適切な最適化を実装します。パフォーマンスの解析とテストは、タイムスタンプ・ログを追加したり、インテル® VTune™ Amplifier などのタイミング・パフォーマンス解析ツールを使用して行うことができます。最適化手法には、並列処理とパイプライン設計、データのプリフェッチと前処理、I/O アクセラレーション、エンコードやデコードなどのその他の特定のアクセラレーション手法、ライブラリーやハードウェアの使用、フレーム抽出、特徴の埋め込みなどが含まれます。
例えば、ビデオ品質評価サービスでインテル® VTune™ Amplifier を使用してボトルネック解析を行い、マルチスレッド/マルチプロセスの並列処理を利用してサービスを最適化できます。
ビデオ品質評価サービスの基本プロセスを図 6 に示します。アプリケーションは、OpenVINO™ ツールキットに統合されている OpenCV* を介してビデオストリームの読み取り、デコード、フレーム化、および前処理を行います。処理済みのコードストリームは、ディープラーニング・ネットワークに渡され、結果のセットを使用してビデオ品質を評価し、ビデオの種類を決定します。
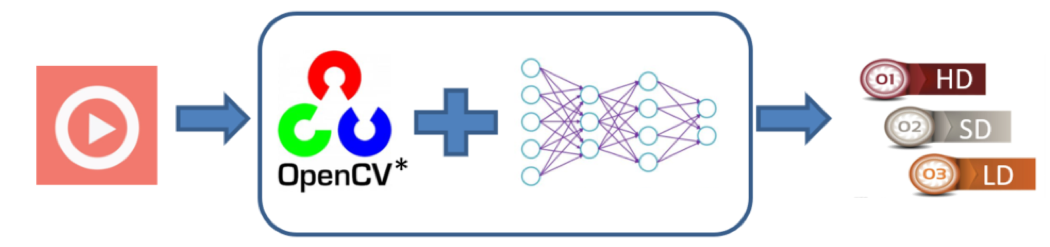
図 6. ビデオ品質評価プロセス
図 7 は、インテル® VTune™ Amplifier によって取得されたオリジナルのアプリケーション・スレッドを示します。以下に示すとおり、OpenCV* の単一のデコードスレッドは常にビジー (茶色) であるのに対し、OpenMP* 推論スレッドは多くの場合待機状態 (赤) です。アプリケーション全体のボトルネックは、OpenCV* のデコードと前処理にあります。
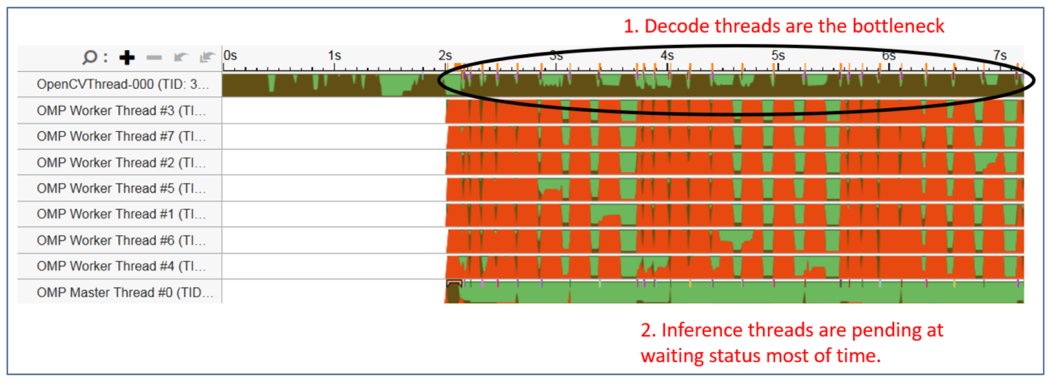
図 7. アプリケーションを最適化する前のスレッドの状態
図 8 は、最適化されたサービススレッドの状態です。ビデオストリームは同時にデコードされ、バッチで前処理されます。その後、処理済みデータは OpenMP* スレッドにバッチ転送され、サービスを最適化します。
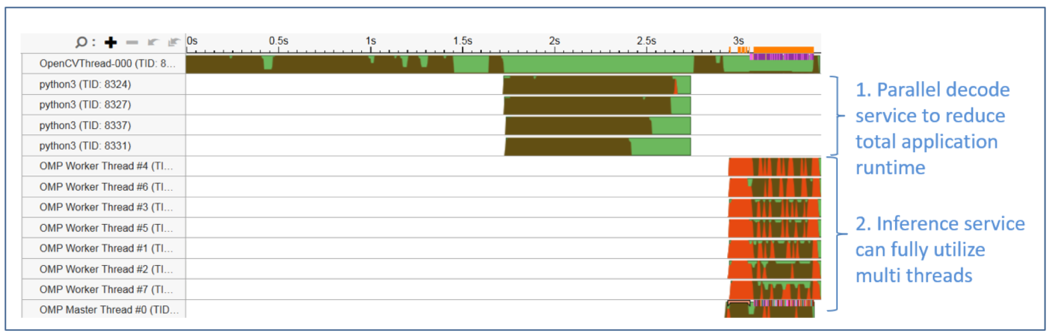
図 8. アプリケーションを最適化 (並列化) した後のスレッドの状態
上記の単純な並列処理による最適化を適用後、720 フレームのビデオストリームは処理時間が 7 秒から 3.5 秒に短縮され、パフォーマンスが 2 倍になりました。パイプライン設計の改善、専用のデコード・ハードウェア・アクセラレーション、およびその他の手法により、サービス全体のパフォーマンスをさらに向上できます。
アルゴリズムの最適化
推論パフォーマンスを向上する一般的なアルゴリズムの最適化手法には、バッチサイズの調整、モデルの調整、モデルの量子化などが含まれます。モデルの調整と量子化には、モデル構造とパラメーターの調整が含まれ、通常、アルゴリズム・エンジニアがモデルの精度要件を確認する必要があります。
推論効率に対するバッチサイズの影響
バッチサイズを選択する際の基本原則は、レイテンシーに敏感なサービスでは小さなバッチサイズを選択し、スループットに敏感なサービスでは大きなバッチサイズを選択することです。
図 9 は、推論サービスのスループットとレイテンシーに対する異なるバッチサイズの影響を示します。テスト結果から、バッチサイズが小さい場合、バッチサイズを適切に (例えば 1 から 2 に) 増やすと、レイテンシーに影響を与えることなく、スループットが向上します。バッチサイズが大きい場合、バッチサイズを増やすと (例えば 8 から 32 に)、スループットは変わらず、サービス・レイテンシーが大幅に低下します。そのため、デプロイされるサービスノードの CPU コアの数とサービスのパフォーマンス要件に応じて、最適なバッチサイズを選択する必要があります。
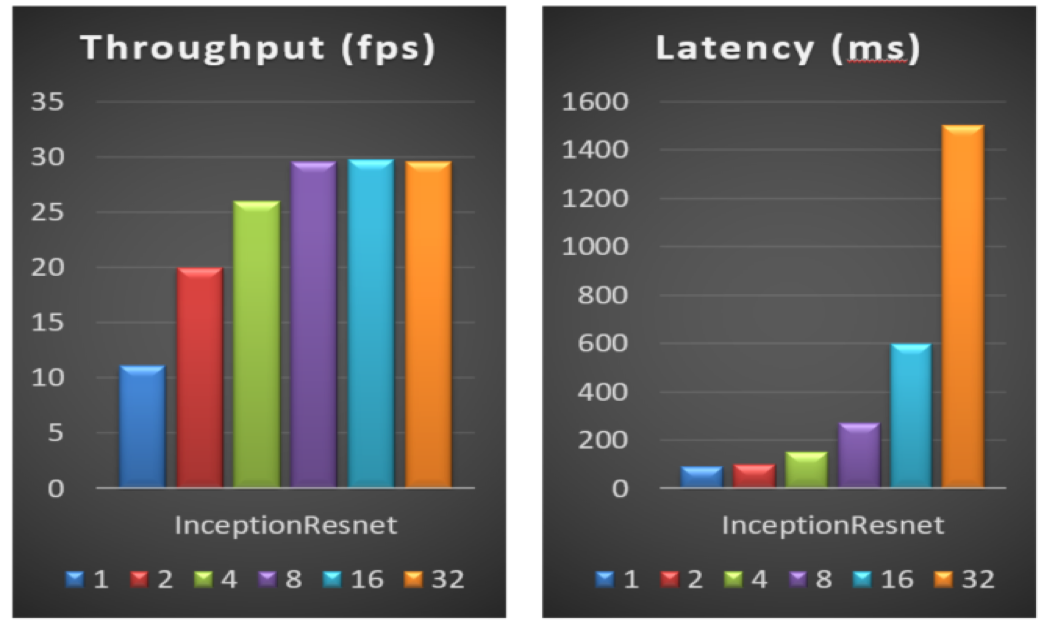
図 9. インテル® Xeon® プロセッサー E5-2650v4 における異なるバッチサイズのパフォーマンス
OpenVINO™ ツールキットによるモデルの推論の高速化
OpenVINO™ ツールキットの概要
OpenVINO™ ツールキットは、CPU、統合 GPU、FPGA、VPU を含むインテル® ハードウェア上のエッジからクラウドに至るプラットフォームにおいて、ディープラーニング・モデルの推論を素早く、効率的に高速化します。このセクションでは、DeepLabV3+ モデルを例に使用して OpenVINO™ ツールキットについて説明します。
以下に示すように、インテル® ディープラーニング・デプロイメント・ツールキット (インテル® DLDT) はモデルの推論に使用され、OpenCV* はビデオと画像処理に使用されます。インテル® メディア SDK は、ビデオ/画像 AI ワークロードのパイプラインで、ビデオ/オーディオコーデックと処理を高速化できます。
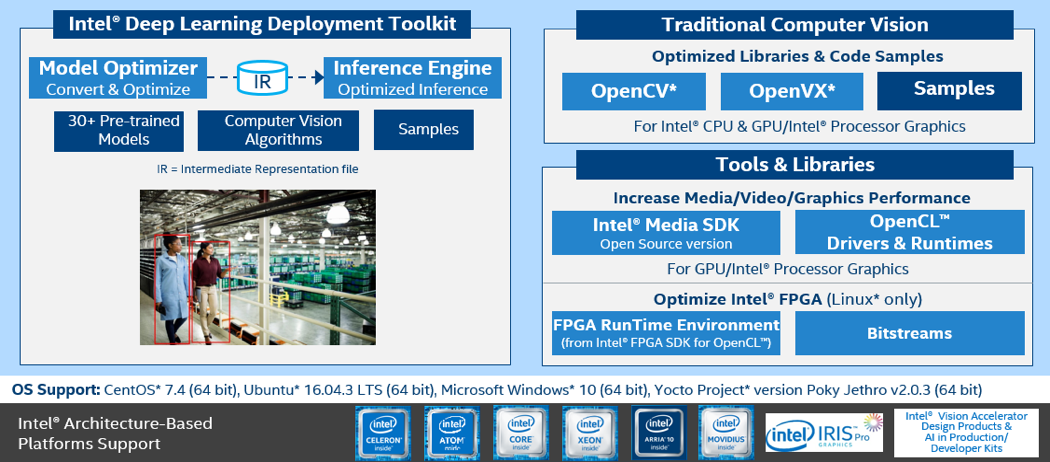
図 10. OpenVINO™ ツールキットの概要
OpenVINO™ ツールキットの使用
モデル・オプティマイザー (MO) の Python* プログラムは、一般的なフレームワークから中間表現 (IR) へのオフラインモデル変換を行うため、コマンドライン・インタープリターで使用されます。
モデル・オプティマイザーで TensorFlow* モデルを変換するコマンド:
モデルファイルの拡張子が標準とは異なる場合、 -framework {tf, caffe, kaldi, onnx, mxnet} オプションを使用して明示的にフレームワークの種類を指定できます。
例えば、次の 2 つのコマンドは等価です。
python3 mo.py --input_model /usr/models/model.pb
python3 mo.py --framework tf --input_model /usr/models/model.pb
生成される IR ファイルは、ランタイムモデル推論のため、推論エンジン (IE) によってロードされます。現在、OpenVINO™ ツールキットは Caffe、TensorFlow*、MXNet、ONNX、および Kaldi をサポートしています。MO の詳細な使用法は、オンライン・ドキュメントとユーザーガイドを参照してください。
C++ または Python* API の IE を使用するプログラムで、クロスプラットフォーム・ランタイム推論を実装および最適化できます。推論エンジンは、CPU、統合 GPU、VPU、FPGA、および低レベルのパフォーマンス・ライブラリーを介したインテル® Gaussian & Neural Accelerator (インテル® GNA) を含むインテル® ハードウェア・ベースの最適化をサポートします。例えば CPU 側では、インテル® DLDT はインテル® MKL-DNN に応答して、推論プロセス中のネットワーク・トポロジーの層の実装にパフォーマンス・ゲインをもたらします。最近、OpenVINO™ はオープンソース化され、ユーザーはカスタム定義クラスを追加したり書き換えてソースコードをリビルドし、カスタマイズされたディープラーニング・デプロイメント・ツールキットを生成できるようになりました。
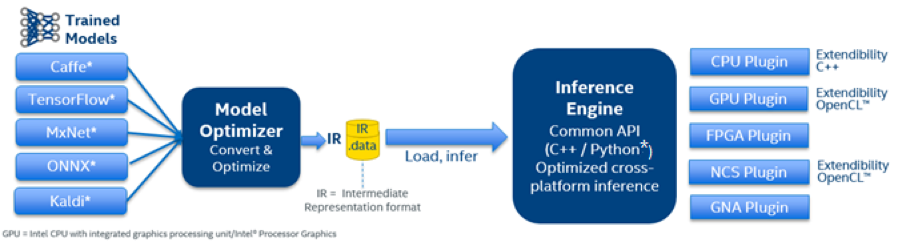
図11. インテル® ディープラーニング・デプロイメント・ツールキットの構造
OpenVINO™ ツールキットは、実際の AI/DL プロジェクト開発要件を満たし、より高いパフォーマンスの最適化を達成できるように、ヘテロジニアス・コンピューティング、非同期推論モード、INT8 モデルの推論、およびスループット・ストリーム・モードも提供します。
OpenVINO™ ツールキットの商用使用例
ディープラーニング・ニューラル・ネットワーク推論は、産業および商用アプリケーションの画像、テキスト、および音声のインテリジェントな認識と検出に広く使用されています。
iQIYI は、ライブコメントの非ブロック化という素晴らしい DL の使用例を示しています。ライブコメントとは、ビデオの上にリアルタイムで表示されるコメントです。スマート・ビデオ・プラットフォームは、ビデオフレーム内のポートレートとオーバーラップするコメントを、ブロックする代わりに背景に残すことができます。

図 12. 非ブロッキング・スマート・ライブ・コメントを効果を示す画像
この機能は、セマンティック画像セグメンテーション・モデルの推論を介して、単一のビデオフレームごとにイメージマットを適用することで実装できます。従来のコンピューター・ビジョン・アルゴリズムと比較して、畳み込みニューラル・ネットワーク推論手法は、さまざまな複雑なテクスチャーやシーン (例えば、前景と背景が類似した色など) において、より正確な結果と容易なデプロイメントを提供します。これは、推論パフォーマンスと精度のバランスを開発者が微調整できる柔軟なソリューションです。
DeepLabV3+ モデル (深い畳み込みネットによるセマンティック画像セグメンテーション)、Atrous 畳み込み、および全結合 CRF を使用して期待する機能を実現できます。Atrous 空間ピラミッドプーリング (ASPP) モジュールと Xception 畳み込み構造を含むエンコーダー-デコーダー構造をサポートする DeepLabV3+ モデルに関する追加情報は、「DeepLab 推論ガイド」 (英語) を参照してください。
OpenVINO™ ツールキットを使用して推論ワークロードを最適化するには、GitHub* ケース・レポジトリー (英語) のスクリプトに従ってください。
モデル・オプティマイザーのモデルカット機能を使用して、モデルの前処理部分をカットします。MobileNetV2 の主なワークロードは推論用に予約されていますが、ほかの操作は TensorFlow* で実装できます。DeepLabV3+ と OpenVINO™ ツールキットを使用するステップは次の通りです。
- モデルの最適化コマンド:
python mo_tf.py --input_model ./model/DeeplabV3plus_mobileNetV2.pb --input 0:MobilenetV2/Conv/Conv2D --output ArgMax --input_shape [1,513,513,3] --output_dir ./model
- サンプル推論エンジンの実行:
Python infer_IE_TF.py -m ./model/DeeplabV3plus_mobileNetV2.xml -I ./test_img/test.jpg -d CPU -l ${INTEL_CVSDK_DIR}/deployment_tools/inference_engine/samples/intel64/Release/lib/libcpu_extension.so
インテル® Xeon® プラットフォームでの iQIYI の取り組みによると、OpenVINO™ ツールキットは、AI ビデオ・プロジェクトに適用されるさまざまな CNN FP32 モデルにおいて大幅なスピードアップをもたらします。
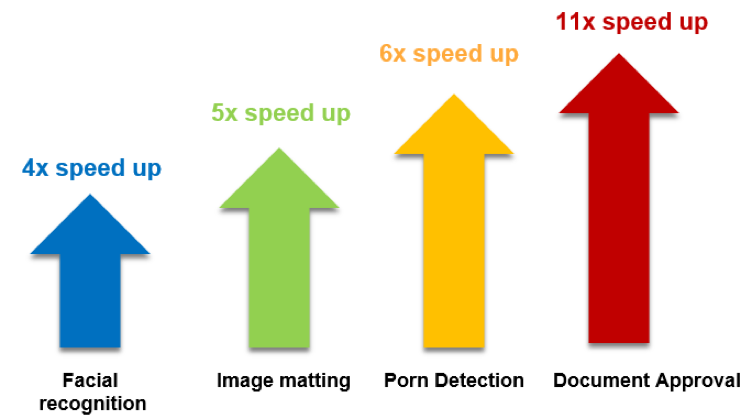
図 13. AI ビデオ・プロジェクトに適用された CNN FP32 モデルのパフォーマンス向上 (パフォーマンス・データの出典: iQIYI)
上の図では、インテル® Xeon® プロセッサー上で OpenVINO™ ツールキットを使用すると、イメージマット用の DeepLabV3 モデルのパフォーマンスは 5 倍向上し、ドキュメント用のテキスト検出モデルのパフォーマンスは 11 倍向上しています。
iQIYI が自社のアプリケーション開発環境で実施したテストによると、インテル® Xeon® プロセッサー上で OpenVINO™ ツールキットを使用することで、異なる FP32 ディープラーニング・ニューラル・ネットワークのパフォーマンスを 4 – 9 倍向上できます。また、インテル® Xeon® Gold 6148 プロセッサーを使用すると、さらに 2 倍のスピードアップを達成できます (パフォーマンス・データの出典: iQIYI)。
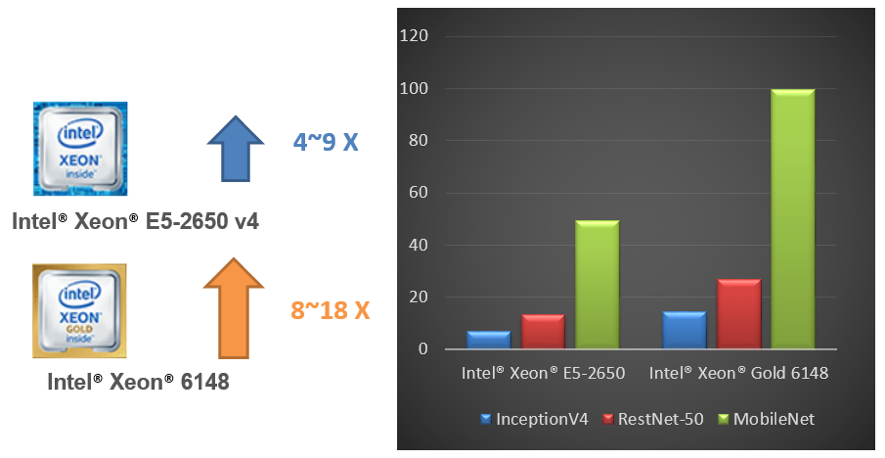
図 14. インテル® Xeon® プロセッサーとインテル® Xeon® Gold プロセッサー上で OpenVINO™ ツールキットを使用した場合のパフォーマンス (パフォーマンス・データの出典: iQIYI)
まとめと今後の展望
ここで紹介したシステムレベルの最適化手法は、iQIYI ディープラーニング・クラウド・プラットフォームの 10 を超えるアプリケーションとアルゴリズムにすでに適用されており、数千のコアにデプロイされています。平均パフォーマンスは、4 – 11 倍向上しています (図 15 を参照)。
ディープラーニング推論サービスを最適化するため、ディープラーニング・クラウド・プラットフォームは、VPU や FPGA などのヘテロジニアス・コンピューティング・リソースを追加して、特定のタスクを高速化することも計画しています。同時に、サービスの柔軟性、スケジュールの最適化、パラメーターの自動選択の観点から、iQIYI はサービスをさらに最適化して、利用可能な計算リソースを最大限に利用し、ディープラーニング推論サービスをより短期間で準備できるようにする予定です。
著者紹介
Lei Zhang
iQIYI のインフラストラクチャーおよびインテリジェント・コンテンツ配信ビジネスグループ (IIG) のシニア・ソフトウェア・エンジニアです。アルゴリズムのトレーニングとデプロイメントを促進するディープラーニング・クラウド・プラットフォームの開発と、ディープラーニング・モデルとアプリケーションのパフォーマンスの最適化に取り組んでいます。Linux* システムとドライバー・ソフトウェア開発において 8 年の経験があります。浙江大学から電気工学の理学修士号を取得しています。
Feng Dong
iQIYI の IIG インテリジェント・プラットフォーム・ディビジョン インテリジェント・アクセラレーション・チームの研究者です。CPU、GPU、および FPGA など、異なるハードウェア・プラットフォーム上で AI モデルと AI サービスの高速化を担当しています。前職は、Lattice Semiconductor (Silicon Image により買収) のシニア・スタッフ・エンジニアでした。主にハードウェア/ソフトウェアの共同設計と最適化に関心を持っています。上海交通大学からコンピューター・システム組織の理学修士号を取得しており、セミコンダクター業界において 10 年以上の経験があります。
Yuping Zhao
インテルのセールス & マーケティング・グループの人工知能 (AI) テクニカル・スペシャリストです。中国におけるインテルのデータセンター AI ソリューションのテクニカルサポートとコンサルティングを担当しています。AI と HPC、特にインテル® アーキテクチャー上でのアプリケーションの最適化の経験が豊富です。インテルに入社する前は、HP と Lenovo でシニア・テクニカル・コンサルタントとして、HPC とクラウドソリューションのテクニカル・コンサルティングを担当していました。北京科技大学からコンピューター・サイエンスの修士号を取得しています。
Fiona Zhao
インテルのアーキテクチャー・グラフィックスおよびソフトウェアのテクニカル・コンサルティング・エンジニアで、OpenVINO™ ツールキットの推論エンジン、インテル® メディア SDK、およびインテル® MKL-DNN を含むインテルの AI およびコンピューター・ビジョン製品のテクニカルサポートを提供しています。プロによるアルゴリズムの最適化、プログラムのチューニング、およびパフォーマンス・アクセラレーション・ソリューションにより、世界中の戦略的顧客とパートナーが、インテル® アーキテクチャーで成功できるように支援しています。以前は、線形代数、画像処理、およびマシンラーニング向け数学ライブラリーに取り組んでいました。サウサンプトン大学からソフトウェア・エンジニアの理学修士号を取得しています。
Ying Hu
インテルのアーキテクチャー・グラフィックスおよびソフトウェアのシニア・テクニカル・コンサルティング・エンジニアで、インテル® ソフトウェア・ツール、インテル® AI フレームワーク、インテル® アーキテクチャー上のハイパフォーマンス・ライブラリーに関する技術的専門知識を提供しています。インテルにおいて 15 年の経験があり、グローバルな開発者、エンタープライズ・ユーザー、エンジニア、および研究者がマシンラーニング、ディープラーニング、HPC などでインテル® MKL、インテル® MKL-DNN、インテル® IPP、インテル® DAAL を含むインテル® ソフトウェアを使用できるように取り組んでいます。パターン認識とインテリジェント・システムの博士号を取得しています。
Jason Wang
インテルのセールス & マーケティング・グループのテクニカル・アカウント・マネージャーです。中国の主要 CSP 顧客向けにインテルの AI/クラウド・ソリューションを普及させる活動に取り組んでいます。信頼できるテクニカル・アドバイザーとして、インテルの製品とソリューションにより顧客のビジネスと技術的な問題を解決する方法を提示しています。前職は Dell の CSP 顧客担当のシニア・ソリューション・アーキテクトで、その前は EMC の主席ソフトウェア・エンジニアでした。西南交通大学からコンピューター・サイエンスの修士号を取得しています。
関連リンク
インテル® MKL-DNN の GitHub* レポジトリー (英語)
インテル® Optimization for TensorFlow* インストール・ガイド (英語)
OpenVINO™ ツールキット (英語)
OpenCV* と DLDT の GitHub* レポジトリー (英語)
OpenVINO™ ツールキットのドキュメント (英語)
インテル® VTune™ Amplifier
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
