 AI
AI インテル® Xeon® プロセッサー上での SLM の最適化: llama.cpp のパフォーマンス調査
この記事は、インテルのウェブサイトで公開されている「Optimizing SLMs on Intel® Xeon® Processors: A llama.cpp Performance Study」を iSUS で翻訳した日本語参考訳です...
 AI
AI  AI
AI  AI
AI  AI
AI  AI
AI  AI
AI  AI
AI  AI
AI  AI
AI  AI
AI  AI
AI  AI
AI  AI
AI 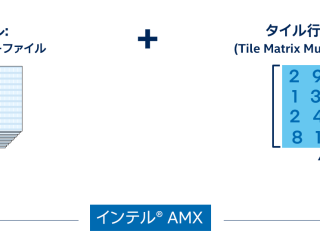 AI
AI 