
この記事は、インテル® デベロッパー・ゾーンに掲載されている「What Can We Learn from the Intel SPMD Program Compiler?」(https://software.intel.com/en-us/blogs/2018/12/17/what-can-we-learn-from-the-intel-spmd-program-compiler) の日本語参考訳です。
インテル® SPMD プログラム・コンパイラー (ISPC) GitHub* リポジトリー (英語) に、新しく簡単な SGEMM の用例 (https://github.com/ispc/ispc/tree/master/examples/sgemm) を追加しました。インテル® SPMD プログラム・コンパイラーは、コンパイラーの実行ファイル名 “ispc.exe” から “ISPC” と呼ばれています。この SGEMM の用例は、ISPC で計算を最適化する用例のバリエーションを紹介しています。一般に、単精度汎用行列乗算 (SGEMM) は、多くの開発者に知られるコンパクトで優れた例です。SGEMM の ISPC バージョンは、他のプログラミング言語と SGEMM コードの最適化の手法を比較するのに役立ちます。
プログラミング言語の進化について、どのような教訓を ISPC から学べるでしょうか? ISPC は、CPU、マルチコア SIMD 言語、GPU 計算言語、データ並列 C++ 拡張、および組込みアプリケーションやドメイン固有の計算言語の進化に対する将来の重要な方向性を的確に示します。具体的には、ISPC でスレッドレベルのプログラミングを導入する方法と、SPMD 反復範囲を明確に指定する方法を個別に説明します。
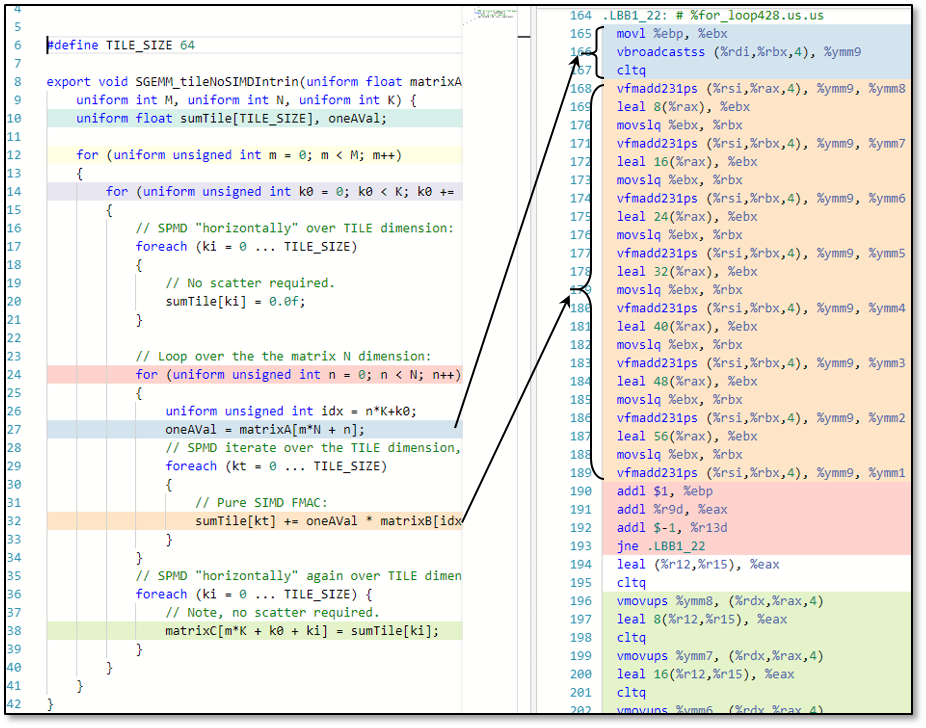
一見すると、ISPC は OpenCL*、DirectX* 計算シェーダー、Vulkan* 計算、Metal 計算などの一般的なベンダーポータブルな GPU 計算言語とよく似た NVIDIA* CUDA* 言語をはじめとするカーネルベースの SPMD (Single Program Multiple Data) プログラミング言語です。これらの言語は、単一命令複数データ (SIMD) または単一命令複数スレッド (SIMT) ベクトル計算アーキテクチャーを対象とする、複数インスタンスのギャング (群) としてコンパイルされたスカラー・コード・カーネルを採用します。このような言語は、効率良く容易にベクトル化可能なアセンブリー・コードを生成できます。そして、カーネル・インスタンス間のデータアクセスが明らかに連続している場合、コストのかかるスカラーロード/ストアや非連続ギャザー/スキャッター操作を行わなくても、ベクトル命令で連続したデータを効率良くロード/ストアできます。これを分かりやすく説明するため、典型的な ISPC カーネルと SGEMM コードの内部ループ向けの x86-64 codegen を含めました。

GPU 計算言語と ISPC 言語は類似したコンパイル概念を持ちます。ISPC と他の言語の重要な違いは、カーネル・インスタンスに対する反復範囲の指定方法です。
OpenCL* でのプログラミング反復を考えてみます。アプリケーション開発者は、ドライバー API を使用してローカルの「ワークグループ」として指定されるサブサイズを集約した階層的な「グローバルワーク」サイズで構成される「N 次元範囲」を指定します。サイズは、1、2、または 3 次元にすることができます。上級開発者向けに、ワークグループをさらに「サブグループ」に細分化する方法が用意されています。DirectX* 計算シェーダーと CUDA* は、同様の抽象化概念を持ちます。
ND-Range は、複数ハードウェア・スレッドと SIMD プログラミングの両方を活用する単一の抽象化によるプログラミングの簡素化を意図しています。カーネル・インスタンスを実行するハードウェア・スレッドのグループには、共有 (ローカル) メモリーリソース、バリア、およびアトミック向けのソフトウェアからハードウェアへのマッピングを定義するワークグループの抽象化があります。サブグループの抽象化は、コンパイラーが一連のカーネル・インスタンスを持つ単一ハードウェア・スレッドをどのように対象とするか開発者に示すため存在します。GPU 計算はしばしば素晴らしいパフォーマンスを発揮するため、明らかにこの計算言語の抽象化は適切であると思われます。
しかし、GPU 計算言語と抽象化には欠点もあります。これらを考えてみます。
- 反復範囲は、計算カーネルとは別にコンパイルおよびプログラミングされる API 呼び出しで指定されます。
- カーネルがインデックス範囲の処理を開始すると、範囲は固定されます。反復範囲を変更するには、さらに API を呼び出して新しいカーネルをディスパッチする必要があります。
- ND Range、ワークグループ、サブグループ (スレッドグループ、ワープ、ウェーブフロントなど) は分かりにくい概念です。
- SGEMM、畳み込みニューラル・ネットワーク、レイトレーシングなどのコードを最適化する開発者は、データの初期化やスレッドごとのリソースを管理するため、直接ハードウェア・スレッドをプログラムしてワークグループ・パラダイムを打開する必要があります。
- アプリケーションが共有ローカルメモリーやバリアを使用しない、またはハイパフォーマンスなキャッシュ階層を持つアーキテクチャーでは、ワークグループの抽象化は不要な複雑さを招きます。
ISPC 言語では、ハードウェア・スレッドへのマッピング方法と反復範囲のプログラミング方法が異なります。ISPC では、ハードウェア・スレッドは直接マッピングされ、反復範囲は foreach() セマンティクスを介してカーネルコードで直接指定されます。これらの一見すると単純な言語設定は、複数の属性を持つスレッド化された SPMD 計算プログラミング・モデルを可能にします。
- foreach() の前または foreach() 構造間のカーネルコードは、ハードウェア・スレッドと予測可能に 1 対 1でマッピングされます。
- ハードウェア・スレッドを直接プログラミングすることで、プログラマーやコンパイラーは、ローカル配列の初期化、データのブロックロード、水平 SIMD 操作を行う組込み関数、またはより綿密なレジスター割り当ての制御を容易に実現できます。
- プログラマーは、foreach() {} ブロックを記述するだけで単一のカーネル内で異なる複数の反復範囲を指定できます。一部のプログラマーは、これをカーネル内で「並列処理の軸を変更する」と呼んでいます。
- foreach() 句内で指定される SPMD 反復は、明確に単一ハードウェアにマッピングされます。
- プログラマーは、単一のカーネル内で foreach() を従来の for() ループの複数の入れ子内に入れ子にできます。すべてが単一のカーネル内で記述されるため、コンパイラーはループ境界にまたがってベクトル化と最適化のコード変換を選択できます。
- 反復範囲が明確であるため、short 定数で定義された SPMD 反復は容易にアンロールできます。
これらは、プログラマーにとってもコンパイラーにとっても好ましいことです。プログラマーは、ワークグループ、スレッドグループ、サブグループの抽象化によって整理された、シンプルで直観的なコードを記述できます。コードのハードウェアへのマッピングは直観的であり、パフォーマンスは透過的です。私たちは、アーキテクチャー間でのパフォーマンスの移植は容易に達成できないと考えていますが、このスタイルのコードのパフォーマンスの移植は期待できる可能性があります。コンパイラーにとって、この言語設計は、ハイパフォーマンス向けのマシンコード生成において SPMD ベクトルブロックを効率良く表現できます。
次のアクションとして強調したいことは、プログラマーと計算言語設計者がこれらの ISPC 言語設計の選択肢を取り入れることです。GPU 計算と CPU SIMD 言語を進化させて、同様のカーネル言語セマンティクスを取り込むことが可能であるかを検討し、ワークグループとサブグループの抽象化の負担からプログラマーを解放する方法を提供します。
ISPC 言語設計には議論に値する多くの魅力的な選択肢があります (uniform/varying 変数指定子、双方向および trivial C/C++ 言語バインド、タスク並列向けの厄介なシンプルタスクとスポーン構文など)。機会がありましたら、今後紹介したいと思います。
参考文献:
- SGEMM サンプル (https://github.com/ispc/ispc/tree/master/examples/sgemm)
- インテル® SPMD プログラム・コンパイラー (英語)
- ISPC について: すべてのリンク (英語)
- ISPC トリックパート 1: アドレス指定… (英語)
- SPIR* から ISPC: GPU 計算を CPU に変換する (英語)
- コンパイラー・エクスプローラー (英語)
- メディア開発パッケージ向けのインテル® C コンパイラー (https://01.org/c-for-media-development-package)
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
