 インテル® Parallel Studio XE
インテル® Parallel Studio XE ハイブリッド・クラウド: オンプレミスとクラウドでの HPC パフォーマンスのベスト・プラクティス
このセッションは、Tech.Decoded で公開されている「Hybrid Cloud: Best Practices for HPC Performance On Premise and On Cloud」( の日本語版です。パブリック・...
 インテル® Parallel Studio XE
インテル® Parallel Studio XE  HPC
HPC  インテル® Advisor
インテル® Advisor  インテル® oneTBB
インテル® oneTBB  インテル® Fortran コンパイラー
インテル® Fortran コンパイラー  インテル® oneAPI
インテル® oneAPI  インテル® oneDAL
インテル® oneDAL  インテル® Parallel Studio XE
インテル® Parallel Studio XE  インテル® MPI ライブラリー インテル® IPP インテル® oneMKL インテル® ディストリビューションの Python* HPC
インテル® MPI ライブラリー インテル® IPP インテル® oneMKL インテル® ディストリビューションの Python* HPC 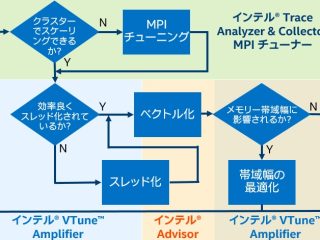 HPC
HPC 