
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Software News Updates」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
2025年
インテル® ソフトウェア開発ツールのバージョン 2025.3 リリース
2025年11月7日 | インテル® ソフトウェア開発ツール | AI フレームワークとツール (英語)
イノベーションとパフォーマンスを強化: AI、HPC、およびゲーム向けインテル® Arc™ B シリーズ・グラフィックス、インテル® Core™ Ultra プロセッサー (シリーズ 3)、およびインテル® Xeon® 6 プロセッサー上でワークロードと開発者の生産性を加速
インテル® ソフトウェア開発ツールのバージョン 2025.3 がリリースされました。最新バージョンは、インテル® Arc™ B シリーズ・グラフィックス (開発コード名 Battlemage)、インテル® Core™ Ultra プロセッサー (シリーズ 3) (開発コード名 Panther Lake)、および最新のインテル® Xeon® 6 プロセッサー (開発コード名 Granite Rapids) を含む最新のハードウェア・プラットフォーム上で、強化されたパフォーマンスと拡張された機能を提供します。高度な SYCL DirectX12 イメージフォーマット相互運用性とインテル® Xe3 GPU のサポートにより、開発者はゲーム、AI、HPC ワークロードにわたって、より高速でスケーラブルなアプリケーションを構築できます。新しいハードウェア最適化には、インテル® oneDNN におけるインテル® AVX 10.2 命令セットとインテル® AMX 命令セットへの早期アクセス、および最新アーキテクチャーでアプリケーション効率を最大限に高める強化された CPU/GPU ハイブリッド・プロセッサー・サポートが含まれます。
詳細情報とダウンロード
インテル® oneAPI ベース・ツールキット
インテル® HPC ツールキット
AI フレームワークとツール (英語)
最新のインテルのハードウェア・プラットフォーム向けにパフォーマンスと生産性を向上
- インテル® oneAPI DPC++/C++ コンパイラー 2025.3 は、リファクタリングされた Unified Runtime L0 v2 アダプターを提供します。このアダプターは、インテル® Arc™ B シリーズ・グラフィックスおよびその他のインテル® Xe2 GPU でデフォルトで有効化されており、計算集約型の グラフィックス、AI、HPC ワークロードをターゲットとする開発者向けに、パフォーマンス向上とデバイス管理の効率化をもたらします。
- インテル® VTune™ プロファイラーでは、パフォーマンス解析がさらに高速になり、より詳細な情報が得られるようになりました。インテル® Arc™ B シリーズ・グラフィックス (開発コード名 Battlemage) とインテル® Core™ Ultra プロセッサー (シリーズ 3) が新たにサポートされ、ファイナライズが最大 2 倍高速化、ITT メタデータの拡充、新しいメモリー帯域幅メトリック、CPU/GPU カーネル関係の可視化 といった機能が追加されました。
- ソフトウェア開発者は、インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) の、インテル® Xe3 GPU のサポート、OpenMP 6.0 準拠、高速なスパースソルバーと LAPACK ソルバーを活用して、HPC、AI、科学計算のワークロードを高速化できるようになりました。
- ディープラーニング開発者は、インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) (英語) の、強化されたハードウェア最適化、新しいレイヤー正規化手法 (RMSNorm) のサポート、インテル® AVX 10.2 命令セットおよびインテル® AMX 命令セットへの早期アクセスにより、インテルの CPU と GPU でより高いパフォーマンスを実現できるようになりました。
- MPI 開発者は、高度な P-core/E-core ピニングにより、ハイブリッド CPU/GPU ワークロードを最適化し、最新のハイブリッド・プロセッサー上でのアプリケーション効率を最大化できるようになりました。
- SHMEM 開発者は、新しい包括的で排他的なスキャン集合を活用できるようになりました。OpenSHMEM 1.6 仕様に 2 つの強力な新しい操作が追加され、並列計算機能が拡張され、CPU/GPU アフィニティーが向上し、スケールアウト・パフォーマンスが向上します。インテル® oneAPI OpenSHMEM ライブラリー (英語) は、予備的にインテル® Arc™ B シリーズ GPU をサポートします。
スピード、スケーラビリティー、将来を見据えた開発向けに最適化
- インテル® oneAPI DPC++/C++ コンパイラーの DirectX12 相互運用性の向上と OpenMP 6.0 機能の強化により、より高速でスケーラブルな C++ および SYCL アプリケーションを構築できます。
- インテル® oneAPI DPC++ ライブラリー (インテル® oneDPL) の拡張範囲アルゴリズムと最適化されたスキャン、検索、セット演算により、並列 C++ ワークロードを高速化します。
- インテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) の高度な数値演算、アフィン変換、インテル® AVX-512 拡張機能により、信号処理と画像処理を高速化します。
- インテル® oneAPI スレッディング・ビルディング・ブロック (インテル® oneTBB) の新しい task_group 依存関係、task_arena 統合の改善、CPU 処理の向上により、並列プログラミングとリソース管理が簡素化されます。
- Fortran 2023 の新機能により、よりクリーンで安全なコード、より優れた並列実行を実現する OpenMP 制御の拡張、クロスプラットフォーム・ビルド向けの高度な MPI-5.0 サポート、そしてインテル® Fortran コンパイラーにおけるネットワーク性能と安定性の向上を実現し、Fortran および HPC 開発を強化します。
- 新しいインテル® MPI ライブラリー 2025.3 は、HPC ワークロードを高速化します。libfabric v2.2.0 の改良点の統合によるネットワーク・パフォーマンスの向上、スレッド分割 (テクニカルプレビュー機能) による並列プログラミングの簡素化、大規模システムの安定性の強化を実現します。
スケーラブルなデータと分散ワークロードの高速化
- 新しいインテル® oneAPI DPC++/C++ コンパイラーを使用することで、Graph USM 割り当てのサポート、カーネルコンパイルの高速化、フリー関数カーネルのファイナライズを含む、コンパイラーの最新の SYCL 言語の改良により、データ並列ワークロードのスケーラビリティーとモジュール性が向上し、ハイパフォーマンスな AI 推論、科学計算、シミュレーション・アプリケーションを構築できます。
- Python 開発者は、インテル® ディストリビューションの Python*の、新しいテンソル・メンバーシップ・テスト、高度な NumPy インデックス、拡張された FFT と線形代数関数、改善された CuPy との互換性、Python 3.13/3.14 のフルサポートにより、科学研究やデータワークフローを高速化できるようになりました。
- インテル® oneAPI コレクティブ・コミュニケーション・ライブラリー (インテル® oneCCL) (英語) を使用することで、通信ライブラリー開発者は、NCCL のような API プレビュー、すべての集合での柔軟なマルチスレッド、ユーザー定義のリダクション操作、大規模メッセージ Allgather 向けに最適化されたスケーラビリティーのメリットを享受できるようになりました。
その他、多数の新機能を利用できます。詳細については、最新のリリースノートを参照してください。
インテル® ソフトウェア開発ツールのバージョン 2025.2 リリース
2025年6月30日 | インテル® ソフトウェア開発ツール | AI フレームワークとツール (英語)
AI、グラフィックス、アクセラレーテッド・コンピューティング向けに最適化されたパフォーマンスと生産性
より高速な AI 推論、リアルタイム・レンダリング、HPC サポート拡張を提供する、インテル® ソフトウェア開発ツールのバージョン 2025.2 がリリースされました。
oneAPI を基盤とするこれらのツールは、最新の P-cores 搭載インテル® Xeon® 6 プロセッサー、インテル® Xeon® 6 SoC、インテル® Core™ Ultra プロセッサーなどのインテル® Xeon® 6 プロセッサー上で、データセンターから PC に至るまで、AI パフォーマンスを最適化します。
Vulkan および DirectX 12 API との SYCL 相互運用性が向上したことで、ゲーム開発者やグラフィックス開発者は、より幅広い画像フォーマットでリアルタイム処理と表示を実現できます。新しい言語サポート機能により、科学研究やデータ集約型アプリケーションの開発が加速されます。
詳細情報とダウンロード: AI フレームワークとツール (英語) | oneAPI の概要
AI パフォーマンスと生産性の向上
- インテル® Core™ Ultra プロセッサー (シリーズ 2) およびインテル® Arc™ GPU 向けのインテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) (英語) と PyTorch 2.7 の最適化 (英語) により、LLM から画像生成まで、AI PC の推論機能を最大化します。
- データセンター AI ワークロードを扱うデータ・サイエンティストや AI 研究者は、P-cores 搭載インテル® Xeon® 6 プロセッサー向けの インテル® oneDNN (英語) 最適化により、複雑なモデルや大規模データセットをより効率的に処理し、AI による洞察を加速し、BERT、Llama、GPT などの一般的な AI 推論ワークフローを強化できます。
- インテル® ディストリビューションの GDB (英語) の強化されたデバッグツールにより、GPU コードのオフロードを必要とする AI ワークロードの開発を効率化します。
- インテル® VTune™ プロファイラーの新しい解析ツール機能により、インテルのクライアント GPU および NPU のパフォーマンスを最適化します。
レンダリングとデータ可視化のためのリアルタイム画像処理
- ゲーム開発者やグラフィックス開発者は、インテル® oneAPI DPC++/C++ コンパイラーの Vulkan および DirectX 12 API との SYCL 相互運用性強化、およびインテル® DPC++ 互換性ツールを使用して CUDA バインドレス・テクスチャーを SYCL に移行することで、より幅広い画像フォーマットでリアルタイム処理と表示を実現できます。
- インテル® ディストリビューションの GDB (英語) の Visual Studio デバッグ効率の向上により、ゲーム開発とリアルタイム・シミュレーションを効率化できます。
- インテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) の改良されたワープ・パースペクティブ関数と最近傍補間により、32 ビット浮動小数点画像の操作とアライメントが高速化され、高精度画像処理アプリの開発が加速します。
幅広い言語サポートとコンパイラー強化によるアクセラレーテッド・コンピューティング
- インテル® oneAPI DPC++/C++ コンパイラーの OpenMP 6.0 新機能により、科学技術計算やデータ集約型アプリケーションにおける GPU オフロードのパフォーマンスと柔軟性が最適化されます。
- インテル® Fortran コンパイラーの Fortran 2023 新機能により、並列コンピューティングと複雑なデータ構造の効率が向上します。
- インテル® DPC++ 互換性ツールにより、一般的な AI およびアクセラレーテッド・コンピューティング・アプリケーションで使用される 350 以上の API が自動移行されるため、CUDA コードを SYCL に簡単に移行できます。
- ハイブリッド HPC アプリケーション開発者とエンドユーザーは、インテル® MPI ライブラリーの MPI 4.1 サポートと新たに拡張されたマルチスレッド機能により、互換性とアプリケーション・パフォーマンスが向上します。
インテル® ソフトウェア開発ツールの最新機能、標準規格への対応、プレビュー、パフォーマンス向上に関する詳細は、以下の記事をご覧ください。
⇒ インテル® oneAPI ツールキット 2025.2 – 並列パフォーマンスを引き出そう
高性能並列処理のスーパーチャージ
インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) は、高速フーリエ変換 (FFT) のクロスアーキテクチャー並列実行を新たなレベルに引き上げ、新しい SYCL DFT API を使用することで、複数の GPU を組み合わせた 2D および 3D 非バッチ FFT 処理を容易に実現します。
OpenMP 6.0 の新しいストライプループ変換構造と、nowait 節のオプションのブール引数により、インテル® コンパイラーで非同期または同期オフロードを条件付きで選択可能になり、オフロード処理を柔軟に制御できるようになりました。
インテル® MPI ライブラリーで以下の機能を利用できるようになりました。
- I_MPI_OFI_PROVIDER リストを設定する新機能により、プロバイダー初期化の制御が強化されました。
- 完全な MPI 4.1 機能に加え、継続的なアップデートにより、将来の安定性、移植性、および MPI 4.1 へのアップデートとの互換性を確保します。
- 新たに拡張されたマルチスレッド機能により、集合操作全体にわたってリソース利用率とパフォーマンスが向上し、デバイス主導型 RMA の相互運用性とパフォーマンスが向上します。
これらすべてにより、CPU のみを使用するラップトップから、HPC および AI 向けのエクサスケール・スーパーコンピューターに至るまで、スケーラブルな並列処理が実現します。
今すぐダウンロード: AI ツールセレクター (英語) | インテル® oneAPI ツールキット
より高速な AI、リアルタイム・グラフィックス、よりスマートな HPC: インテル® ソフトウェア開発ツール 2025.1 リリース!
2025年03月26日 | インテル® ソフトウェア開発ツール | AI フレームワークとツール (英語)

インテルの最新世代の AI ツールとフレームワーク、およびインテル® oneAPI ツールキット 2025.1 がリリースされました。開発者が AI と HPC をより迅速かつ自信を持って作成できるように支援が強化されています。
ソフトウェア・プロジェクト全体でパフォーマンス、生産性、コード品質をターボチャージ
インテル® Xeon® 6 プロセッサー向けの最新の最適化 (英語)、インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) を使用した AI 推論とトレーニングの高速化、インテル® Core™ Ultra プロセッサーでのディープラーニング推論パフォーマンスのプロファイルから、最新の貢献やインテル® プロセッサー上での PyTorch による FlexAttention サポートまで、最新リリースはすべてをカバーしています。
リアルタイム・グラフィックス、ビジュアル AI、レンダリング・パフォーマンスにおいて、Vulkan および Microsoft DirectX 12 との SYCL 相互運用性が強化されました。
サニタイザーと拡張されたコードカバレッジにより、CPU と GPU で実行される計算カーネルのコード品質を保証します。LLVM ベースのコンパイラー・テクノロジーにより、最新の C/C++、Fortran、SYCL、OpenMP をサポートしています。
新しいインテル® SHMEM ライブラリーにより、大規模なデータセット計算向けのマルチノード分散構成で GPU による通信の効率を向上できます。
oneAPI をベースとしたこれらの広範な分野に対応したツール、ライブラリー、および一般的なフレームワークを組み合わせることで、プログラミングとワークロードのニーズを満たすことができます。
詳細情報とダウンロード
AI ソリューション:
AI フレームワークとツール (英語) | AI ツールセレクター (英語)
汎用計算ソリューション:
インテル® oneAPI の概要 | インテル® ソフトウェア開発ツール
データセンターから PC まで AI パフォーマンスを最適化
最新のインテルの CPU および GPU プラットフォームで PyTorch 2.6 (英語) およびその他の主要なディープラーニング・フレームワークを使用して大幅なパフォーマンス向上を実現します。
インテル® Core™ Ultra AI PC およびインテル® Arc™ ディスクリート・グラフィックス上で PyTorch モデルをファイン・チューニング、推論、開発したい開発者や研究者は、Windows、Linux、Windows Subsystem for Linux 2 向けのバイナリーリリースを使用して PyTorch を直接インストールできるようになりました。
- TorchInductor CPP バックエンドを通じて X86 CPU の FlexAttention サポートが追加されました。これにより、CPU のパフォーマンスを最適化する既存の FlexAttention API に基づいて、現在の CPP テンプレートの機能が拡張され、幅広いアテンション・バリアント (LLM 推論に不可欠な PageAttention など) がサポートされます。
- x86 CPU での Float16 サポートは、PyTorch 2.5 でプロトタイプ機能として初めて導入されました。現在、Eager モードと Torch.compile および Inductor モードの両方でさらに改良され、り広く採用されるようにベータ版がリリースされています。
ディープラーニング推論向けのインテル® oneDNN (英語) の最適化により最新のインテル® プロセッサーを活用できます。
インテル® アドバンスト・マトリクス・エクステンション (インテル® AMX) 命令セットを搭載したインテル® Xeon® プロセッサー・アーキテクチャーのパワーを活用し、インテル® oneDNN により強化された行列乗算と畳み込みのパフォーマンスを体験できます。
インテル® Arc™ グラフィックス上の AI アプリケーションのパフォーマンスが向上し、インテル® Core™ Ultra プロセッサー (シリーズ 2) とインテル® Arc™ B シリーズ・ディスクリート・グラフィックスの機能が最大限に活用されます。
暗黙的なカジュアルマスクを使用して、ゲート付き多層パーセプトロン (ゲート付き MLP) と SDPA (Scaled Dot-Product Attention) の速度と効率の両方を向上させ、インテル® oneDNN Graph API を通じて int8 または int4 圧縮キーと値をサポートすることで、AI モデルをさらに最適化します。
インテル® VTune™ プロファイラーを使用して、AI PC のパフォーマンス・ボトルネックを解消し、分散型ディープラーニング・ワークロードを効率化します。
DirectML または WinML API を呼び出す AI ワークロードのパフォーマンス・ボトルネックを特定します。
分散型ディープラーニングと Python ワークロードの解析を改良し、Python 3.12 で最も時間のかかるコード領域とクリティカルなコードパスを特定します。
C++ with SYCL を使用して、ゲーム、グラフィックス、デジタルコンテンツ向けのリアルタイム・ビジュアル AI エクスペリエンスを提供
インテル® oneAPI DPC++/C++ コンパイラーとインテル® DPC++ 互換性ツールは、Vulkan および DirectX12 との SYCL 相互運用性を強化します。
これにより、GPU からイメージ・テクスチャー・マップ・データを直接共有できるようになり、CPU と GPU 間の余分なイメージコピーが排除され、イメージ処理と高度なレンダリング・アプリケーションでシームレスなパフォーマンスが確保され、コンテンツ作成の生産性が向上します。
HPC とアクセラレーテッド・コンピューティングのパフォーマンス、生産性、コード品質を向上
インテル® コンパイラーは、コードの安定性、セキュリティー、生産性を向上します。
インテル® oneAPI DPC++/C++ コンパイラーとインテル® Fortran コンパイラーは、CPU MemorySanitizer のサポートを GPU を含むデバイス側に拡張します。これにより、開発者は CPU とデバイスコードの両方で問題を簡単に検出してトラブルシューティングできるため、より信頼性が高く堅牢なアプリケーションを実現できます。
- インテル® oneAPI DPC++/C++ コンパイラーは、ビルド時間を大幅に短縮するキャッシュ* をサポートしました。以前のコンパイルをキャッシュして再利用することで、反復処理が高速化し、ワークフローが効率化されます。ビルドに時間をかけずに、高品質のコードの作成に集中できます。
- インテル® oneAPI DPC++/C++ コンパイラーのコード・カバレッジ・ツールには、C/C++、SYCL、OpenMP を使用するアプリケーション向けの GPU サポートと拡張 CPU カバレッジが追加されました。
- インテル® Fortran コンパイラーは、スレッド間で作業を効率的に分散する WORKDISTRIBUTE 構造と、ループネスト内のループを並べ替える INTERCHANGE 構造を導入することで、OpenMP 6.0 標準のサポートを拡張し、並列パフォーマンスとコード最適化を向上させます。
Fortran 23 のサポートがさらに強化され、標準準拠によってコードの柔軟性が向上し、SYSTEM_CLOCK 組込み関数の整数引数の種類の一貫性が確保され、PUBLIC NAMELIST グループに PRIVATE 変数を含めることができるようになりました。
MPI と新しいインテル® SHMEM ライブラリー (英語) により GPU 開始通信の効率が向上します。
ポイントツーポイントのリモート・メモリー・アクセス (RMA) と OpenSHMEM 1.6 ストライド RMA 操作、アトミックメモリー操作 (AMO)、シグナリング、メモリー順序付け、チーム、コレクティブ、同期などの OpenSHMEM 1.5 準拠機能を使用して、マルチノード・アクセラレーター・デバイスとホストをターゲットにできます。
対称ヒープ API を使用したインテル® SHMEM SYCL キュー順序付け RMA、SYCL ホスト USM アクセスにより、分散マルチノード SYCL デバイスアクセスを簡素化します。
インテル® MPI ライブラリーは、新しい MPI 標準に先駆けて、サポートされている GPU でデバイス開始 MPI-RMA 機能もサポートしました。
AI フレームワークとツール (英語) | インテル® ソフトウェア開発ツール
2024年
AI ツールと最適化フレームワークの最新バージョン 2025.0 リリース
2024年12月19日 | AI フレームワークとツール (英語)
生成 AI の生産性、アクセラレーション、スケーリングを次のレベルへ
インテルは、生成 AI の量子化と推論にフォーカスして AI の効率とスケーリングを推進する、AI ツールと最適化フレームワークのバージョン 2025.0 をリリースしました。PyTorch および TensorFlow エコシステムへの多くの貢献を含むオープン・スタンダードのサポート、最新の P-cores 搭載インテル® Xeon® 6 プロセッサー、インテル® Arc™ B シリーズ・グラフィックス、インテルの GPU と内蔵アクセラレーター向けの最適化が追加されています。
詳細とダウンロード (英語)
オープンソースの AI フレームワークとディープラーニング・モデルを採用したインテルの最新世代の AI ツールにより、開発者は既存のコードベースを、下位互換性を失うことなく最新のインテルのテクノロジーをサポートするように容易に拡張できます。
oneAPI を利用した豊富なライブラリーとユーティリティーのセットは、高性能な AI ワークロードを迅速に作成または移行する、信頼性が高く、柔軟性があり、拡張可能で、高度に最適化された基盤を形成します。
オープン AI フレームワークを採用
- インテル® Xeon® 6 プロセッサー、インテル® Core™ Ultra プロセッサー、インテル® データセンター GPU マックス・シリーズ、およびクライアント GPU のネイティブサポートを含むインテルの PyTorch 最適化 (英語) は、PyTorch 2.5 にアップストリームされています。現世代のプロセッサー向けに最適化され、パフォーマンス向上のため (英語) インテル® oneAPI DPC++/C++ コンパイラーで TorchInductors をコンパイルする機能を備えた PyTorch 2.5 と torch.compile サポートによる PyTorch 推論の最新の CPU パフォーマンス (英語) を利用できます。PyTorch 向けインテル® エクステンションには、大規模言語モデル (LLM) を最適化するカスタマイズされたカーネルサポートが追加され、DeepSpeed 向けインテル® エクステンション (英語) が統合されました。
- インテルの TensorFlow 最適化 (英語) は、インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) (英語) を使用して公式の TensorFlow 機能を拡張し、パフォーマンスとスケーラビリティーを向上します。最新のインテルの CPU および GPU 上で TensorFlow ワークロードのパフォーマンスを最適化して、効率良く実行できます。
- JAX Python ライブラリー (英語) が AI ツールに統合され、自動微分による効率的で柔軟な数値計算が可能になりました。これにより、JAX の高性能なジャストインタイム・コンパイルを活用し、マシンラーニング、科学計算、最適化タスク向けの機能が強化されます。PJRT (英語) プラグインメカニズムをベースにインテルにより最適化された PyPI パッケージである OpenXLA (英語) 向けインテル® エクステンションを使用して、インテル® データセンター GPU 上で JAX (英語) モデルをシームレスに実行します。
モデルサイズとパフォーマンスの最適化
- インテル® ニューラル・コンプレッサー (英語) は、モデルを最適化してモデルサイズを小さくし、CPU と GPU 上でディープラーニング (DL) の推論を高速化します。
- 新機能には、LLM の重みのみの量子化を行う Transformer ライクな量子化 API があり、インテルのハードウェアで量子化と推論のワンストップ・エクスペリエンスを提供します。また、AutoRound アルゴリズムを使用した LLaVA、Phi-3-vision、Qwen-VL などのビジュアル言語モデル (VLM) の INT4 量子化もあります。
- インテル® ニューラル・コンプレッサーのその他の改善点には、Transformer ライクな API での PyTorch 推論用の AWQ 形式 INT4 モデルの読み込みと変換のサポート、INT4 モデルの AutoRound 形式のエクスポートの有効化、PyTorch 2 エクスポート (PT2E) のチャネルごとの INT8 トレーニング後量子化のサポートなどがあります。
生成 AI 開発者の生産性を高める
- AI ツールコンテナ (英語) は、サポートする主要 Python フレームワークやライブラリーに基づいて再定義されました。これにより、コンテナサイズが縮小され、使い方が簡素化され、開発者にとってもユーザーにとっても、より合理的で効率的な環境が保証されます。
- インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) (英語) は、サーバー、デスクトップ、モバイルにまたがる最新のインテル® プラットフォーム向けに最適化され、大規模言語モデル (LLM) や SPDA (Scaled Dot-Product Attention) サブグラフのパフォーマンスが大幅に向上するなど、効率とパフォーマンスを最大化します。
- インテル® oneAPI データ分析ライブラリー (インテル® oneDAL) は、ランダムフォレスト (RF) アルゴリズムの説明可能性に必要なバイナリー分類モデルの SHAP (SHapley Additive exPlanations) 値の計算を可能にします。
- インテル® oneAPI コレクティブ・コミュニケーション・ライブラリー (インテル® oneCCL) (英語) は、ワークロードのスケーリングとパフォーマンスをさらに向上します。AllGather、AllReduce、Reduce-Scatter などの主要な集合操作の重要な機能強化が追加されています。インテル® oneCCL の Key-Value ストアの強化により、ランク間の通信が改善され、ワークロードをさらに多数のノードに拡張できるようになりました。
- scikit-learn 向けインテル® エクステンション (英語) は、共分散および統計アルゴリズムの新しいインターフェイスを追加し、LogisticRegression アルゴリズムのスパースデータをサポートします。
AI フレームワークとツール (英語)
AI ツールセレクター (英語)
oneAPI 誕生から 5 周年を記念するインテル® ソフトウェア開発ツールのバージョン 2025.0 がリリース
2024年11月17日 | インテル® ソフトウェア開発ツール
インテルは、oneAPI プログラミング・モデルの誕生から 5 周年を記念して、パフォーマンスの最適化とオープン・スタンダードのカバレッジが拡張された、マルチアーキテクチャー、ハードウェアに依存しないソフトウェア開発とデプロイ、エッジからクラウドまでの最新のイノベーションをサポートする、oneAPI を利用した開発者ツールの最新バージョン 2025.0 をリリースしました。
3 つの特長
- インテル® プラットフォームでさらなるパフォーマンスを引き出す – インテル® oneDNN (英語)、インテルにより最適化された AI フレームワーク、インテル® AMX1 を搭載したインテル® Xeon® 6 プロセッサー (P-cores) で最大 3 倍の生成 AI パフォーマンスを実現します。MRDIMM2 とインテル® oneMKL により HPCG パフォーマンスを最大 2.5 倍向上します。インテル® Core™ Ultra プロセッサー (シリーズ 2) の性能を最大限に発揮するように最適化されたツールにを利用して、PC 上で LLM 開発を含む ハイパフォーマンス AI を開発できます。インテル® クリプトグラフィー・プリミティブ・ライブラリー (英語) によりセキュリティーと暗号化を向上できます。
- 業界標準ツールへのアクセスの拡大 – CPU および GPU での PyTorch* 2.5 のネイティブサポートなど、業界をリードする AI フレームワークと、多くのインテルの最適化を含むパフォーマンス・ライブラリーを使用して、既存の開発ワークフローを活用できます。インテルの AI ツール (英語) を使用すると、CPU、GPU、AI アクセラレーター上で Llama* 3.2、Qwen2、Phi-3 などの最新の LLM から最適なパフォーマンスを引き出すことができます。また、ツールキット・セレクター (英語) を使用してフルキットまたは適切なサイズのサブバンドルをインストールすることで、ソフトウェアのセットアップを効率化できます。
- ハードウェアの選択肢が拡大 – 一般的な AI、HPC、レンダリング・アプリケーションで使用される 100 以上の API を自動移行するインテル® DPC++ 互換性ツールにより、CUDA* から SYCL* への迅速な移行など、マルチベンダー、マルチアーキテクチャーのサポートが強化されています。インテル® ディストリビューションの Python* により、CPU および GPU でドロップインの、ネイティブに近い数値計算パフォーマンスを実現できます。インテル® oneDPL によりアルゴリズムの GPU カーネルを 4 倍高速化できます。Triton、JAX、OpenXLA などのクロスハードウェア AI アクセラレーション・ライブラリーにより、将来のシステムの柔軟性を獲得し、ロックインを防止します。
新機能
以下は、コンポーネント・レベルの詳細です。
コンパイラー
- インテル oneAPI DPC++/C++ コンパイラーは、インテル® Xeon® 6 プロセッサーおよびインテル® Core™ Ultra プロセッサー向けにカスタマイズされた最適化が追加され、新しい SYCL* バインドレス・テクスチャー・サポートによりインテル® GPU の動的実行と柔軟なプログラミングを可能にし、デバイスコードの問題を検出してトラブルシューティングする新しい LLVM サニタイザーで開発を効率化し、 OpenMP* 標準 5.x および 6.0 への準拠を拡張し、OpenMP* オフロードの詳細を含むよりユーザーフレンドリーな最適化レポートが追加されています。
- インテル® Fortran コンパイラーは、クリーンな出力のための AT 編集記述子、OpenMP* 6.0 の新しい IF 節による条件付き TEAMS 構造の実行、およびアプリケーションの標準への準拠を正確に制御する Co-Array の配列と「standard-semantics」オプションのサポートなど、Fortran 2023 標準機能を含むいくつかの機能強化が追加されています。『Fortran デベロッパー・ガイドおよびリファレンス』のサンプルコードが更新され、Fortran 2018 および 2023 の Fortran 言語機能のサポートが追加されています。
パフォーマンス・ライブラリー
- インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL)は、P-cores 搭載インテル® Xeon® 6 プロセッサーをターゲットとする開発者向けに、BLAS、LAPACK、FFT などの複数のドメインにわたるパフォーマンス最適化が導入されています。また、インテル® データセンター GPU マックス・シリーズで単精度 3D 実数インプレース FFT を使用した HPC ワークロードの実行が大幅に改善され、SYCL* デバイス API を使用した RNG の新しい分布モデルとデータ型が利用できるようになりました。
- インテル® oneAPI データ・アナリティクス・ライブラリー (インテル® oneDAL) は、説明可能性ランダム フォレスト (RF) アルゴリズムに必要なバイナリー分類モデルの SHAP (SHapley Additive exPlanations) 値を計算できるようになりました。
- インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) (英語) は、サーバー、デスクトップ、モバイルにわたる最新のインテル® プラットフォーム向けの最適化により、効率とパフォーマンスを最大化します。これには、大規模言語モデル (LLM) とスケーリングされたドット積アテンション・サブグラフの大幅な高速化が含まれます。
- インテル® oneAPI スレッディング・ビルディング・ブロック (インテル® oneTBB) は、task_group、flow_graph、parallel_for_each のスケーラビリティーを向上させ、マルチスレッド・アプリケーションの実行速度を向上させます。また、インテル® oneTBB のフローグラフを使用して共有グラフの重複メッセージを処理し、結果を迅速に取得できるようにする新しい try_put_and_wait 実験的 API が導入されました。
- インテル® oneAPI コレクティブ・コミュニケーション・ライブラリー (インテル® oneCCL) (英語) は、ワークロードをさらに多数のノードにスケールアップできるようするキー値格納の強化と、Allgather、Allreduce、Reduce-scatter などの主要な集合操作のパフォーマンス向上により、ワークロードのパフォーマンスとスケーラビリティーを向上させます。
- インテル® MPI ライブラリーは、分割通信、改善されたエラー処理、Fortran 2008 サポートを含む完全な MPI 4.0 実装を提供します。P-core ピニングによりインテル® Xeon® 6 プロセッサーと MPI_Allreduce の最適化によりインテル® GPU の両方でスケールアウト/スケールアップのパフォーマンスが向上します。
- インテル® oneAPI DPC++ ライブラリー (インテル® oneDPL) (英語) は、reduce、scan、その他の多くの関数を含むアルゴリズムで GPU カーネルを最大 4 倍3 高速化します。20 以上の新しい C++20 標準の範囲とビューを使用した範囲ベースのアルゴリズムにより、マルチアーキテクチャー・デバイスで高度に並列化されたコード実行を高速化します。
- インテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) は、最先端のハードウェア強制セキュリティー対策である CET 対応の保護 (Control-flow Enforcement Technology) により、ソフトウェアを攻撃や悪用リスクから保護します。
- インテル® クリプトグラフィー・プリミティブ・ライブラリー (英語) (旧称インテル® IPP クリプトグラフィー) は、開発者がインテル® Xeon® 6 プロセッサー上にディスパッチできるようにし、マルチバッファー機能で RSA 暗号化 (2K、3K、4K) を高速化し、強化された SM3 アルゴリズムでハッシュ化します。
アナライザーとデバッガ―
- インテル® DPC++ 互換性ツールは、一般的な AI、HPC、レンダリング・アプリケーションで使用されるより多くの API を自動移行することで、CUDA* コードと CMake ビルドスクリプトを SYCL* に移行する際の時間と労力を軽減します。移行したコードは、SYCLcompat で簡単に理解でき、CodePin を使用して簡単にデバッグでき、NVIDIA* GPU で実行できます。
- インテル® VTune™ プロファイラーは、P-cores 搭載インテル® Xeon® 6 プロセッサーとインテル® Core™ Ultra プロセッサー (シリーズ 2) をサポートしました。また、Python* 3.11 のプロファイル・サポートが追加され、Python* のプロファイルを関心領域に集中させ、インテル® ITT API (英語) を使用したパフォーマンス・データ収集の制御により、生産性を向上させます。
- インテル® Advisor は、開発者が最新のインテルのプラットフォームでボトルネックを特定し、コードを最適化し、最高のパフォーマンスを実現できるようにします。柔軟なカーネルマッチングと XCG アプリの統合により、適応性の高いカーネル・マッチング・メカニズムが導入されており、特定の最適化目標に関連するコード領域を特定して分析することが可能です。
- インテル® ディストリビューションの GDB* (英語) は、最新の状態を維持し、効果的なアプリケーションのデバッグをサポートする最新の機能拡張に合わせて、GDB 15 をベースとするように変更されました。また、Windows* でインテル® Core™ Ultra プロセッサー (シリーズ 2) をサポートしました。デバッガー・パフォーマンスの向上とユーザー・インターフェイスの改良により、コマンドラインと Microsoft* Visual Studio* および Visual Studio* Code 使用時の両方で開発者のエクスペリエンスを向上します。
AI および ML ツール、フレームワーク、および高速化された Python*
- インテル® ディストリビューションの Python* は、CPU と GPU でドロップインの、ネイティブに近い数値計算パフォーマンスを実現します。Python 向けデータ・パラレル・エクステンション (dpnp) とデータ・パラレル・コントロール (dpctl) は、互換性を拡張し、ランタイムに NumPy* 2.0 をサポートして、オフロードされた操作の非同期実行を提供します。
- インテルの AI ツール (英語) の最新リリースでは、Llama* 3.2、Qwen2、Phi-3 ファミリーを含む生成 AI 基礎モデルの現在および将来のリリースが、インテルの CPU、GPU、AI アクセラレーターで最適に動作するようにします。
- Triton (英語) (ニューラル・ネットワーク向けのオープンソースの GPU プログラミング) がインテル® データセンター GPU マックス・シリーズとインテル® Core™ Ultra プロセッサー (シリーズ 2) 向けに完全に最適化され、ストック PyTorch* のアップストリームで利用できるようになりました。開発者はインテルの GPU でピーク・パフォーマンスとカーネル効率を実現できます。
- PyTorch* 2.5 のネイティブサポート (英語) は、インテルのデータセンター GPU、インテル® Core™ Ultra プロセッサー、インテルのクライアント GPU で利用できます。インテル® Arc™ グラフィックスとインテル® Iris® Xe グラフィックス GPU のサポートにより、Windows* で PyTorch* を使用した開発が可能です。
- LF AI & Data Foundation のオープン・プラットフォーム・プロジェクトである OPEA (英語) を採用することにより、エンタープライズ生成 AI の導入を簡素化し、強化された、信頼できるソリューションの運用までの時間を短縮します。現在リリース 1.0 の OPEA は、AMD、BONC、ByteDance、MongoDB、Rivos などの最新のパートナーを含む 40 社を超えるパートナーとともに躍進を遂げています。
- PJRT (英語) プラグイン・メカニズム・ベースのインテルにより最適化された PyPI パッケージである OpenXLA* (英語) 向けインテル® エクステンションにより、インテル® データセンター GPU マックス・シリーズとインテル® データセンター GPU フレックス・シリーズで JAX (英語) モデルをシームレスに実行します。
脚注
1 intel.com/processorclaims の [9A2] を参照: インテル® Xeon® 6 プロセッサー。結果は異なることがあります。
2 intel.com/processorclaims の [9H10] を参照: インテル® Xeon® 6 プロセッサー。結果は異なることがあります。
3 インテル® oneDPL 製品ページ (英語) を参照。
oneAPI 誕生から 5 年
2024年11月17日 | oneAPI とは? (英語)、インテル® oneAPI デベロッパー・ページ (英語)
アクセラレーター・アーキテクチャー向けのオープンで標準ベースのマルチアーキテクチャー・プログラミング・イニシアチブの誕生から 5 周年

Supercomputing 2019 で発表された oneAPI イニシアチブは、グローバルな開発者エコシステムのヘテロジニアス・プログラミングへの取り組み方に恒久的な変化をもたらしただけでなく、あらゆるベンダー・アーキテクチャー上で実行可能な高性能ソフトウェアを構築、最適化、デプロイする基盤となっています。
多数の貢献者、430 万以上のインストール、680 万人の開発者がインテルのソフトウェアと AI ツール (最新バージョン 2025.0 の詳細はこちら) を介して oneAPI を使用しており、oneAPI は間違いなく主要なプログラミング標準の 1 つです。Unified Acceleration (UXL) Foundation の使命は、ハイパフォーマンスのクロスプラットフォーム・アプリケーションの開発を簡素化するオープンスタンダードのアクセラレーター・プログラミング・モデルを提供することです。これは、oneAPI を主要コンポーネントとして、イノベーションを推進するための重要な一歩です。
これらすべてをわずか 5 年で実現しました。次の 5 年間で何が起こるか想像してみてください。
oneAPI をまだ試していない場合は、概要を確認し、最新バージョン 2025.0 のツールをダウンロードしてお試しください。
oneAPI 5 周年を祝う – エコシステムの利用者の声
oneAPI 5 周年は、異なるハードウェア上でアプリケーションの実行を可能にするエコシステムの技術的な深さと、HPC、AI、API 標準、ポータブルなアプリケーションを中心としたコミュニティー形成の成功の両方を認識する良い機会です。
oneAPIは、アーキテクチャーを超えたシームレスな開発を可能にすることで、ヘテロジニアス・コンピューティングへのアプローチ方法に革命をもたらしました。そのオープンで統一されたプログラミング・モデルは、AI から HPC までの分野におけるイノベーションを加速し、研究者と開発者の新たな可能性を解き放ちました。oneAPI 5 周年おめでとうございます。
インテルの oneAPI ソフトウェア・スタックへのコミットメントは、開発者重視のオープン・スタンダードへのコミットメントの証です。oneAPI は 5 周年を迎え、CPU と GPU 向けに OpenMP* と SYCL* の包括的で高性能な実装を提供し、インテル® プロセッサーを最大限に活用するライブラリーとツールのエコシステムによって強化されています。
oneAPI が 5 周年を迎えたことをお祝いいたします。ExaHyPE において、oneAPI は双曲方程式系の数値計算カーネルの実装に大きく貢献し、SYCL* がこれらのバリエーションを探索する理想的な抽象化と不可知論を提供することで、性能に大きな違いをもたらしました。この多用途性により、私たちのチームは、インテルのエンジニアとともに、カーネルの 3 つの異なる設計パラダイムを発表することができました。
oneAPI、5 周年おめでとうございます! 私たちは、2019年のプライベート・ベータ・プログラム以来のパートナーです。現在、材料科学のシミュレーションやバイオインフォマティクスのデータ・アナリティクス向けの電力効率の高いソリューションを、さまざまなアクセラレーターを使って模索しています。そのためには、oneAPI のコンポーネント、さまざまな GPU や FPGA 用のバックエンドを備えたコンパイラー、oneMKL、インテル® VTune™ プロファイラーやインテル® Advisor などのパフォーマンス・ツールが不可欠です。
GROMACS は、性能と移植性に優れたバックエンドとして SYCL* を早くから採用し、マルチベンダーの GPU 上で実行するために活用してきました。長年にわたり、SYCL* 標準の大幅な改善とそのコミュニティーの成長を見てきました。これは、イノベーションとコラボレーションを推進するため、計算研究におけるオープン・スタンダードの重要性を強調しています。ソフトウェア・パフォーマンスの向上とプログラマーの生産性向上を可能にする、SYCL* の継続的な開発に期待しています。
私たちは、インテル® oneAPIベースツールキットを使用して、超音波診断ソリューションで広く使用されている、重い処理を必要とするコードを SYCL* に移行することに成功しました。これは、ヘテロジニアス・コンピューティングのための、単一でオープンな標準ベースのプログラミング・モデルへの大きな前進です。移行されたコードは、異なる GPU プラットフォーム上で効率良く実行され、競争力のある性能を達成しています。
インテル® oneAPIベースツールキットを使用して、GE HealthCare の CT ポートフォリオの多くで利用可能な、独自のディープラーニング画像再構成アルゴリズムである TrueFidelity DL を実装することに成功しました。オープンソースの SYCL* コンパイラーは、複数の NVIDIA* GPU デバイスでほぼ同等の AI/DL 推論パフォーマンスを提供します。GE Healthcare の OpenCL* ソフトウェアの経験に基づくと、コードの移植性は、ソフトウェア開発への投資を保護し、異なるプラットフォームやベンダー間でソフトウェアを再利用するために極めて重要です。
関連情報:
- AI & マシンラーニング・エコシステム開発者リソース (英語)
- HPC エコシステム開発者リソース (英語)
インテル® Tiber™ AI クラウドでオブジェクト・ストレージの一般提供を開始
2024年10月17日 | インテル® Tiber™ AI クラウド
インテルは、インテル® Tiber™ AI クラウドで新しいオブジェクト・ストレージ・サービスの提供開始を発表しました。このサービスは、最新のデータおよび AI ワークロードの厳しい要件を満たす、スケーラブルで耐久性があり、コスト効率に優れたデータストレージを提供します。
このサービスは、S3 API (AWS* の Simple Storage Service) と互換性のある強力なオープンソース MinIO プラットフォーム上に構築されており、既存のアプリケーションやツールとの統合が容易です。
詳細 (英語)
次のような利点があります。
- 拡張性と柔軟性 – ギガバイトでもペタバイトでも、膨大なデータストレージのニーズに対応できるため、ビジネスに合わせてストレージ・インフラストラクチャーを拡張できます。
- パフォーマンス – 高速データアクセスと取得に最適化されているため、AI/ML ワークロードを含め、データに常にアクセスでき、迅速に処理できます。
- コスト効率の良いストレージ – あらゆる規模の企業が、多額の費用をかけずに膨大な量のデータを保存できます。
- 堅牢なセキュリティー – 保存時と転送時の暗号化と、堅牢なアクセス制御が含まれています。
- 統合が容易 – バックアップとリカバリー、データアーカイブ、データレイクの使用など、既存のワークフローやアプリケーションとシームレスに統合できるように構築されています。
- 強化されたデータ管理 – バージョン管理、ライフサイクル・ポリシー、メタデータ管理などの機能を使用して、データを効率良く管理できます。
Inflection AI がインテル® Tiber™ AI クラウド上のインテル® Gaudi® 3 AI プロセッサーで動作するエンタープライズ AI を発表
2024年10月7日 | Inflection AI とインテルの協業 (英語)、インテル® Tiber™ AI クラウド
新たな協業により、企業に大きな成果をもたらす AI 搭載のターンキー・プラットフォームを提供
Inflection AI とインテルは、大企業向けに AI の導入と効果を加速させる協業を発表しました。業界初のエンタープライズ・グレードの AI プラットフォームである Inflection 3.0 は、インテル® Tiber™ AI クラウド上のインテル® Gaudi® 3 AI アクセラレーターで動作し、複雑で大規模な導入に必要な制御、カスタマイズ、拡張性を備えた、共感的で会話的な、従業員に優しい AI 機能を提供します。
「Inflection AI とインテルは協力して、エンタープライズのお客様に AI に対する究極の制御を提供します。Inflection AI をインテル® Tiber™ AI クラウドとインテル® Gaudi® 3 AI アクセラレーターと統合することで、ソフトウェア、価格、性能、スケーラビリティーのオープンなエコシステムを提供します。これにより、企業における AI 導入の重要な障壁を解消し、お客様が必要とする安全で、目的に特化した、従業員固有の、企業文化に応じた AI ツールを実現します。」
これが重要な理由
AI プラットフォームの構築は複雑であり、広範なインフラストラクチャーに加えて、モデルの開発、トレーニング、ファインチューニング、さらには多数のエンジニア、データ・サイエンティスト、アプリケーション開発者を必要とします。
Inflection 3.0 は、企業データ、ポリシー、文化に基づいてトレーニングされた仮想 AI により従業員を強化する完全な AI プラットフォームを、企業のお客様に提供します。インテル® Tiber™ AI クラウド上のインテル® Gaudi® 3 AI アクセラレーターで動作し、優れたパフォーマンス、堅牢なソフトウェア、効率性を提供することで、業界をリードするパフォーマンス、スピード、スケーラビリティーを費用対効果の高い方法で実現し、大きな成果をもたらします。
![]()
インテルが次世代の AI ソリューションを実現するインテル® Xeon® 6 プロセッサーとインテル® Gaudi® 3 AI アクセラレーターを発表
2024年9月24日 | インテル® Xeon® 6 プロセッサー (P-core採用)、インテル® Gaudi® 3 AI アクセラレーター
インテルは本日、Performance-cores (P-cores) を搭載したインテル® Xeon® 6 プロセッサーとインテル® Gaudi® 3 AI アクセラレーターを発表しました。これらの製品により、最適な電力効率 (パフォーマンス/ワット) とより低い総保有コスト (TCO) を特徴とする、強力な AI システムの提供を実現します。
インテルの AI に特化したデータセンター向け製品ポートフォリオに次の 2 つの新製品が加わりました。
 インテル® Xeon® 6 プロセッサー (P-core採用): 計算負荷の高いワークロードを効率良く処理するように設計されたインテル® Xeon® 6 プロセッサーは、前世代製品と比較して 2 倍のパフォーマンスを実現します1。コア数の増加、メモリー帯域幅の倍増、すべてのコアに組み込まれた AI アクセラレーション機能を提供します。
インテル® Xeon® 6 プロセッサー (P-core採用): 計算負荷の高いワークロードを効率良く処理するように設計されたインテル® Xeon® 6 プロセッサーは、前世代製品と比較して 2 倍のパフォーマンスを実現します1。コア数の増加、メモリー帯域幅の倍増、すべてのコアに組み込まれた AI アクセラレーション機能を提供します。 インテル® Gaudi® 3 AI アクセラレーター: 大規模生成 AI 向けに最適化されており、64 個の Tensor プロセッサー・コア (TPC) と 8 個の行列乗算エンジン (MME) を実装し、ディープ・ニューラル・ネットワーク (DNN) の計算処理を加速します。トレーニングと推論用に 128GB の HBM2e メモリーを備え、スケーラブルなネットワーク処理を可能にする 24 ポートの 200Gb イーサネットを搭載しており、Llama 2 70B 推論で NVIDIA* H100 と比較して最大 20% 高いスループットと、2 倍の価格性能比を実現します2。
インテル® Gaudi® 3 AI アクセラレーター: 大規模生成 AI 向けに最適化されており、64 個の Tensor プロセッサー・コア (TPC) と 8 個の行列乗算エンジン (MME) を実装し、ディープ・ニューラル・ネットワーク (DNN) の計算処理を加速します。トレーニングと推論用に 128GB の HBM2e メモリーを備え、スケーラブルなネットワーク処理を可能にする 24 ポートの 200Gb イーサネットを搭載しており、Llama 2 70B 推論で NVIDIA* H100 と比較して最大 20% 高いスループットと、2 倍の価格性能比を実現します2。
1 intel.com/processorclaims (英語) のインテル® Xeon® 6 プロセッサーを参照してください。結果はシステム構成によって異なります。
2 intel.com/processorclaims (英語) のインテル® Gaudi® 3 AI アクセラレーターを参照してください。結果はシステム構成によって異なります。
Seekr がインテル® Tiber™ デベロッパー・クラウド上のセルフサービス AI エンタープライズ・プラットフォームを発表
2024年9月4日 | SeekrFlow (英語)、インテル® Tiber™ デベロッパー・クラウド
インテル® Tiber™ デベロッパー・クラウド上で動作する Seekr で、優れたコスト・パフォーマンスの信頼できる AI を導入
![]() Seekr は本日、インテル® Tiber™ デベロッパー・クラウド上の高性能でコスト効率の高いインテル® Gaudi® AI アクセラレーター上で動作する、エンタープライズ対応プラットフォームの SeekrFlow を発表しました。
Seekr は本日、インテル® Tiber™ デベロッパー・クラウド上の高性能でコスト効率の高いインテル® Gaudi® AI アクセラレーター上で動作する、エンタープライズ対応プラットフォームの SeekrFlow を発表しました。
SeekrFlow は、信頼できるエンタープライズ AI アプリケーションのトレーニング、検証、デプロイ、スケーリングを行う完全なエンドツーエンド・プラットフォームであり、AI 導入のコストと複雑さ、そしてハルシネーションを軽減します。
詳細 (英語)
これが重要な理由
一言で言えば、顧客の利点です。
インテルのクラウドを使用して大規模な AI の開発とデプロイを行うと同時に、SeekrFlow のパワーを活用して信頼できる AI を実行し、これらすべてを 1 カ所で行うことで、顧客は優れたコスト・パフォーマンス、インテルの CPU、GPU、AI アクセラレーターへのアクセス、オープン AI ソフトウェア・スタックによる柔軟性が得られます。
次世代のインテル® Core™ Ultra プロセッサー搭載の AI PC で AI を高速化
2024年9月3日 | AI 開発のジャンプスタート (英語)、AI PC 向け開発 (英語)
![]() 本日、インテルは次世代のインテル® Core™ Ultra プロセッサー (開発コード名 Lunar Lake) を発表し、最新の AI PC における効率、コンピューティング、AI パフォーマンスの飛躍的進歩を明らかにしました。
本日、インテルは次世代のインテル® Core™ Ultra プロセッサー (開発コード名 Lunar Lake) を発表し、最新の AI PC における効率、コンピューティング、AI パフォーマンスの飛躍的進歩を明らかにしました。
ISV、開発者、AI エンジニア、データ・サイエンティストは、クライアント・プラットフォームの AI 性能を業務に活用できます。AI PC は、モデル、アプリケーション、ソリューションの開発と最適化に最適です。
- オープンソースの基礎モデル、PyTorch* や TensorFlow* などの最適化されたフレームワーク、インテル® OpenVINO™ ツールキットを使用して、AI のトレーニングと推論を簡素化および高速化します。
- インテル® ソフトウェア開発ツールを活用して、インテル® AVX-512 やインテル® AI ブーストなどの AI PC の最先端機能を活用し、パフォーマンスと開発の生産性を向上させます。
- oneAPI (英語) ヘテロジニアス・プログラミングを使用して既存の CPU/GPU コードを移植し、最大 40% の消費電力を削減しながら高速に実行できるように最適化します。
2024年末までに、統合ソフトウェア開発キット (SDK) を備えたインテル® Core™ Ultra プロセッサー・ベースのプラットフォームもインテル® Tiber™ デベロッパー・クラウドで利用できるようになる予定です。
詳細 (英語)
あらゆるところに AI: インテル® ソフトウェア開発ツール & AI ツール 2024.2 リリース
2024年8月9日 | インテル® ソフトウェア開発ツール、インテル® Tiber™ デベロッパー・クラウド
高性能で量産可能な AI への高速パス
インテルの oneAPI および oneAPI を採用した AI ツールの最新リリースは、ソリューションまでの時間を短縮し、ハードウェアの選択肢を増やし、安定性を向上することで、開発者が高性能な AI (および HPC) アプリケーションをより簡単に提供できるようにチューニングされています。実稼働用のクラウド環境での AI の構築とデプロイについては、インテル® Tiber™ デベロッパー・クラウドの新しいハードウェアとサービスをご確認ください。
3 つの特長
- より高速で応答性の高い AI – oneDNN (英語)、インテルにより最適化された AI フレームワーク、インテル® AMX1 を搭載した、今後発売されるインテル® Xeon® 6 プロセッサー (P-cores) で最大 2 倍の生成 AI パフォーマンスを実現し、アナリティクスやメディアなどのワークロードでは (インテル® Xeon® 6 プロセッサーの E-cores を使用して) 最大 1.6 倍のパフォーマンスを実現します2。将来に対応した比類のない AI 計算能力を備えた今後発売されるクライアント・プロセッサー (開発コード名 Lunar Lake) と、前世代の 3.5 倍の AI スループット (英語) を含む3、AI PC 上で LLM 推論スループットとスケーラビリティーを向上します。ツールは、Llama* 3.1 や Phi-3 などの 500 以上のモデル (英語) をサポートしています。インテル® Tiber™ デベロッパー・クラウドにより、コスト効率に優れたマネージド・インフラストラクチャー上に実稼働用 AI をデプロイして拡張できます。
- 選択肢と制御の拡大 – 業界標準の AI フレームワークに継続的に最適化をアップストリームすることで、インテルのすべての CPU と GPU で AI および HPC ワークロードのパフォーマンスを最大化します。ユビキタス・ハードウェアへのデプロイを容易にするため、最小限のコーディングでインテル® GPU 上で PyTorch* 2.4 (英語) を実行およびデプロイできます。oneMKL、oneTBB、oneDPL の最適化とインテル® oneAPI DPC++/C++ コンパイラーの強化された SYCL* Graph 機能により、アプリケーションの効率と制御が向上します。このリリースでは、AI、テクニカル、エンタープライズ、グラフィックスの計算ワークロードを高速化するため、インテル® Xeon® 6 プロセッサー (E-cores と今後の P-cores) および今後発売されるプロセッサー (開発コード名 Lunar Lake) の幅広いツールがサポートされています。
- 簡素化されたコード最適化 – インテル® VTune™ プロファイラーのプラットフォームを考慮した最適化、幅広いフレームワーク、新しいハードウェア (開発コード名 Grand Ridge) プロセッサーにより、AI トレーニングと推論のパフォーマンスが向上します。インテル® DPC++ 互換性ツールを使用して 100 以上の CUDA* API を自動的に移行し、CodePin インストルメンテーションにより CUDA* から SYCL へのコード移行における不整合を正確に特定することで、CUDA* コードから SYCL* へ容易に移行できます。
新機能
以下は、コンポーネント・レベルの詳細です。基本ツールは、インテル® oneAPI ベース・ツールキットとインテル® HPC ツールキットにバンドルされています。AI ツールについては、セレクターツール (英語) で必要なものだけを入手できます。
コンパイラー
- インテル® oneAPI DPC++/C++ コンパイラーは、SYCL* Graph 機能を強化し、一時停止/再開をサポートして、より優れた制御とパフォーマンス・チューニングを実現します。デフォルトのコンテキストが有効な Windows* で SYCL* パフォーマンスを向上します。また、カーネル・コンパイラーの最新リリースで SPIR-V* と OpenCL* クエリーをサポートして、計算カーネルの柔軟性と最適化を強化します。
- インテル® Fortran コンパイラーは、整数オーバーフロー制御オプション (-fstrict-overflow、Qstrict-overflow[-]、および -fnostrict-overflow) を追加して、正しく機能することを確実にします。最新の OpenMP* 標準 5.x および 6.0 への準拠を拡張し、スレッド使用量の制御とループの最適化を強化します。また、メモリー管理、パフォーマンス、効率性を向上する OpenMP* ランタイム・ライブラリー拡張も追加しています。
ライブラリー
- インテル® ディストリビューションの Python* では、生産性向上のため、Data Parallel Control Library にソートおよび合計関数が追加されました。パフォーマンス向上のため、NumPy* 向け Data Parallel Extension に新たな累積関数と改良された線形代数関数が提供されています。
- インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) (英語) は、インテルの AI が強化されたクライアント・プロセッサーおよびサーバー・プラットフォームでパフォーマンスを向上するプロダクション品質の最適化を提供し、matmul での int8 および int4 重み展開のサポートにより AI ワークロードの効率を高め、LLM を高速化してより迅速に洞察と結果をもたらします。
- インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) は、インテル® データセンター GPU マックス・シリーズ上で 実数および複素数の 2D FFT と 3D FFT のパフォーマンスを強化します。
- インテル® oneAPI データ・アナリティクス・ライブラリー (インテル® oneDAL) は、DPC++ スパース gemm プリミティブ、DPC++ スパース gemy プリミティブ、スパース logloss 関数プリミティブをサポートし、アルゴリズム全体でスパース関数を拡張しています。
- インテル® oneAPI DPC++ ライブラリー (インテル® oneDPL) (英語) は、開発者がマルチアーキテクチャー・デバイス向けの並列プログラムを記述できるようにし、インテルおよび他のベンダーの GPU で既存のアルゴリズムを改善する、新しい C++ 標準テンプレート・ライブラリーの inclusive_scan アルゴリズム拡張を追加しています。
- インテル® oneAPI コレクティブ・コミュニケーション・ライブラリー (インテル® oneCCL) (英語) は、メモリーや I/O などのシステムリソースの使用率を向上する複数の機能拡張を導入し、さらに優れたパフォーマンスを実現します。
- インテル® oneAPI スレッディング・ビルディング・ブロック (インテル® oneTBB) は、スレッドとマルチスレッドの同期を最適化し、第 5 世代インテル® Xeon® プロセッサーでの起動レイテンシーを短縮し、Apple* Mac* を含む ARM* CPU で OpenVINO™ ツールキットのパフォーマンスを最大 4 倍に高速化します。
- インテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) は、zlip 1.3.1 の最適化パッチを追加して、データ圧縮タスクの圧縮率とスループットを向上し、インテル® GPU 上でインテル® AVX-512 VNNI を使用して一部の色変換関数の高速画像処理を実現します。
- インテル® IPP Cryptography (英語) は、NIST FIPS 140-3 準拠を含む政府機関と民間セクター全体のセキュリティーを拡張し、単一バッファー実装向けに最適化された LMS ポスト量子暗号アルゴリズムでデータ保護を強化します。また、簡素化された新しいコードサンプルを使用してインテル® Xeon® プロセッサーとインテル® Core™ Ultra プロセッサーの AES-GCM パフォーマンスを最適化し、Linux* での Clang 16.0 コンパイラー・サポートにより開発を効率化します。
- インテル® MPI ライブラリーは、開発者が特定のスレッドを個々の NIC に固定できるようにすることで、複数のネットワーク・インターフェイス・カードを搭載したマシンでアプリケーション・パフォーマンスを向上します。また、第 5 世代インテル® Xeon® プロセッサー向けに、GPU 対応ブロードキャスト、RMA ピアツーピア・デバイス間通信、ノード内スレッド分割、Infiniband* チューニングの最適化を追加しています。
AI および ML ツールとフレームワーク
- PyTorch* 2.4 では、インテル® データセンター GPU マックス・シリーズの初期サポート (英語) が提供され、インテル® GPU と SYCL* ソフトウェア・スタックが公式の PyTorch* スタックに追加され、AI ワークロードのさらなる高速化に役立ちます。
- PyTorch* 向けインテル® エクステンション (英語) は、Eager モードで FP16 最適化を使用して、Bert_Large、Stable Diffusion の CPU パフォーマンスのチューニングを改善します。一般的な LLM モデル (英語) は、重みのみの量子化 (Weight-Only Auantization、WOQ) (英語) を使用してインテル® GPU 向けに最適化されており、精度を低下させることなくメモリーアクセスを減らし、パフォーマンスを向上します。
- インテル® ニューラル・プロセッサー (英語) は、15 以上の一般的な LLM 量子化レシピ (英語) で SmoothQuant および WOQ アルゴリズムを使用して、INT8 および INT4 LLM モデルのパフォーマンスを向上します。WOQ のインプレース・モードを利用して、量子化プロセスの実行時にメモリー・フットプリントを削減します。LLM 推論用の低ビット量子化法である AutoRound を使用してモデルの精度を向上させ、より少ない手順で丸め値と重みの最小/最大値を微調整します。PyTorch* LLM 用の新しい Wanda および DSNOT プルーニング・アルゴリズムは、AI 推論中のパフォーマンスを向上するのに役立ち、SNIP アルゴリズムは、マルチカードまたはマルチノード (CPU) でのモデルのスケーリングを可能にします。
解析、デバッグ、コード移行ツール
- インテル® VTune™ プロファイラーは、最適ではないインテル® oneCCL 通信に関する詳細なデータを提供し、.NET8 をサポートし、今後発売されるプロセッサー (開発コード名 Grand Ridge) をサポートします。テクニカルプレビュー機能により、開発者はソフトウェア・パフォーマンス解析における潜在的なボトルネックを高レベルで把握してから、トップダウンのマイクロアーキテクチャー・メトリックを調査してより深い分析を行うことができます。
- インテル® DPC++ 互換性ツールは、オプションで有効になる SYCL* イメージ API 拡張への移行により、マルチベンダー GPU 上のビジュアル AI アプリケーションと画像処理アプリケーションを高速化します。カーネル実行ログを自動的に比較し、移行された SYCL* コードの違いを報告します。よく使用される 126 個の CUDA* API は自動的に移行できます。
- インテル® ディストリビューションの GDB* (英語) は、Windows* マシンでインテル® Core™ Ultra プロセッサーをサポートし、変数を監視および解析して VS Code でより迅速かつ効率的にアプリケーションの安定性を強化する Land Variable Watch Window を追加します。また、インテル® Control-flow Enforcement Technology (CET) を拡張してアプリケーションのセキュリティーを強化します。
ブログ (英語) と各ツールのリリースノート (英語) では、開発者の視点から新機能についてさらに詳しく説明しています。
インテル® Tiber™ デベロッパー・クラウドでの大規模な AI ソリューションのビルドとデプロイ
人気の高い基本モデルと最適化されたツールおよびフレームワークを含む、oneAPI をベースに構築されたオープン・ソフトウェア・スタックを使用して、最新のインテル® アーキテクチャーで AI モデル、アプリケーション、および実稼働用ワークロードを開発およびデプロイできます。
新しいハードウェアとサービスにアクセス可能
- インテル® データセンター GPU マックス・シリーズ搭載の仮想マシン
- インテル® Gaudi® 2 AI アクセラレーターと生成 AI Jupyter* Notebook
- インテル® Kubernetes Service と K8s API によるコンテナーのデプロイメント
- 出荷前のインテル® Xeon® 6 プロセッサーを搭載したプレビュー環境
インテル® Gaudi® 2 AI アクセラレーターが AI コンピュートと生成 AI の低コストな代替手段を実現
2024年6月12日 | インテル® Gaudi® 2 AI アクセラレーター、インテル® Tiber™ デベロッパー・クラウド
 本日、MLCommons は、業界の AI パフォーマンス・ベンチマークである「MLPerf Training v4.0」の結果を発表しました。インテルの結果は、インテル® Gaudi® 2 AI アクセラレーターが企業や顧客に提供する選択肢を示しています。
本日、MLCommons は、業界の AI パフォーマンス・ベンチマークである「MLPerf Training v4.0」の結果を発表しました。インテルの結果は、インテル® Gaudi® 2 AI アクセラレーターが企業や顧客に提供する選択肢を示しています。
インテルは、インテル® Tiber™ デベロッパー・クラウドでトレーニングした大規模なインテル® Gaudi® 2 システム (1,024 基のインテル® Gaudi® 2 AI アクセラレーター) の結果を提出し、AI アクセラレーターのパフォーマンスとスケーラビリティー (70B-175B パラメーターの LLM を容易にトレーニング可能)、および MLPerf の GPT-3 175B1 パラメーター・ベンチマーク・モデルを効率的にトレーニングできるインテル® Tiber™ デベロッパー・クラウドの能力を実証しました。
結果
MLPerf ベンチマークの結果から、インテル® Gaudi® 2 AI アクセラレーターは、引き続き AI コンピューティングにおける NVIDIA* H100 の唯一の代替品であることが分かります。1,024 基のインテル® Gaudi® 2 AI アクセラレーターを搭載した AI システムを使ってインテル® Tiber™ デベロッパー・クラウドでトレーニングした GPT-3 の TTT (time-to-train、トレーニング時間) は 66.9 分であり、これはインテル® Tiber™ デベロッパー・クラウド環境内の超大規模 LLM におけるインテル® Gaudi® 2 AI アクセラレーターの強力なスケーリング性能を証明しています1。
ベンチマーク・スイートには、LoRA (Low-Rank Adaptation、大規模言語および拡散モデルのファイン・チューニング手法) を使用して Llama 2 70B パラメーター・モデルをファイン・チューニングする新しい測定も含まれていました。インテルの提出物は、8 個のインテル® Gaudi® 2 AI アクセラレーターで 78.1 分の TTT を達成しました。
詳細 (英語)
インテル® Gaudi® AI アクセラレーターがもたらす AI 価値
高いコストによって、多くの企業が AI 市場から撤退しています。インテル® Gaudi® AI アクセラレーターはそれを変えようとしています。COMPUTEX でインテルが発表した、システム・プロバイダー向けに提供されるユニバーサル・ベースボード (UBB) と 8 基のインテル® Gaudi® 2 AI アクセラレーターを含む標準的な AI キットの価格は $65,000 で、同等の競合プラットフォームと比べてコストが 3 分の 1 になると推定されます。また、8 基のインテル® Gaudi® 3 AI アクセラレーターと UBB を含むキットの価格は $125,000 で、同等の競合プラットフォームと比べてコストが 3 分の 2 になると推定されます2。
インテル® Tiber™ デベロッパー・クラウドの価値
インテルのクラウドは、AI モデル、アプリケーション、ソリューションを開発およびデプロイするための、ユニークで管理されたコスト効率の高いプラットフォームを企業顧客に提供します。インテル® Tiber™ デベロッパー・クラウドでは、インテルのアクセラレーター、CPU、GPU、オープン AI ソフトウェア・スタック、その他のサービスに簡単にアクセスできます。詳細はこちら。
関連情報
1 MLPerf の GPT-3 測定は、MLCommons ベンチマークを共同で考案した参加企業によって決定された、モデル全体の 1% の典型的なスライスで実施されています。
2 カードやシステムの価格ガイダンスはモデリングのみを目的としています。最終的な価格については、各 OEM メーカーにご相談ください。結果は数量とリードタイムによって異なる場合があります。
ワークロードと構成については、MLCommons.org を参照してください。結果は異なることがあります。
インテル® Core™ Ultra プロセッサー上で実行が最適化された AI モデルが 500 を超える
2024年5月1日 | インテル® Core™ Ultra プロセッサー・ファミリー
インテルが PC 業界で最も堅牢な AI PC ツールチェーンを構築
 インテルは本日、市場で入手可能な業界最高峰の AI PC プロセッサーである新しいインテル® Core™ Ultra プロセッサー上で実行が最適化された、事前学習済み AI モデルの数が 500 を超えたことを発表しました。
インテルは本日、市場で入手可能な業界最高峰の AI PC プロセッサーである新しいインテル® Core™ Ultra プロセッサー上で実行が最適化された、事前学習済み AI モデルの数が 500 を超えたことを発表しました。
大規模言語、拡散、超解像、物体検出、画像分類とセグメンテーション、コンピューター・ビジョンなど、20 以上のローカル AI 推論カテゴリーにおよぶ、Phi-2、Mistral、Llama、BERT、Whisper、Stable Diffusion 1.5 などのモデルが含まれます。
これは、AI PC の変革を促進しサポートするインテルの取り組みにとって画期的な瞬間です。インテル® Core™ Ultra プロセッサーは、急成長している AI PC プロセッサーで、新しい AI エクスペリエンス、没入型グラフィックス、最適なバッテリー寿命が特徴です。また、他のプロセッサー・ベンダーよりも多くの AI モデル、フレームワーク、ランタイムに対応した、AI PC 開発用の最も堅牢なプラットフォームです。
500 のモデルはすべて、CPU、GPU、NPU にデプロイできます。これらのモデルは、OpenVINO™ Model Zoo、Hugging Face*、ONNX* Model Zoo、PyTorch* など、業界で人気のあるソースで利用可能です。
詳細 (英語)
関連情報
インテルのテクノロジーにより最適化された Canonical Ubuntu* 24.04 LTS リリース
2024年4月25日 | Ubuntu* 24.04 LTS (英語)、インテル® QAT、インテル® TDX (英語)
![]() 本日、Canonical は Ubuntu* 24.04 LTS (開発コード名 Noble Numbat) のリリースを発表しました。この 10 回目の長期サポートリリースでは、CPU 上のワークロードを高速化するインテル® クイックアシスト・テクノロジー (インテル® QAT) 統合や、プライベート・データセンターにおけるコンフィデンシャル・コンピューティングを強化するインテル® Trust Domain Extensions (インテル® TDX) のサポートなど、パフォーマンス・エンジニアリングとコンフィデンシャル・コンピューティングの進歩が融合されています。
本日、Canonical は Ubuntu* 24.04 LTS (開発コード名 Noble Numbat) のリリースを発表しました。この 10 回目の長期サポートリリースでは、CPU 上のワークロードを高速化するインテル® クイックアシスト・テクノロジー (インテル® QAT) 統合や、プライベート・データセンターにおけるコンフィデンシャル・コンピューティングを強化するインテル® Trust Domain Extensions (インテル® TDX) のサポートなど、パフォーマンス・エンジニアリングとコンフィデンシャル・コンピューティングの進歩が融合されています。
Ubuntu* は、インテルの最先端機能を利用するのに最適です。Canonical とインテルは、プラットフォーム全体で大規模なパフォーマンスとセキュリティーを実現するという理念を共有しています。
インテル コーポレーション システム・ソフトウェア・エンジニアリング VP 兼 GM Mark Skarpness
主な機能
- パフォーマンス・エンジニアリング・ツール – システムコール・パフォーマンスが向上した最新の Linux* 6.8 カーネル、ppc64el でのネストされた KVM サポート、カーネルタスクのスケジューリング遅延を軽減する機能、およびより完全な CPU とオフ CPU をプロファイルするため、すべての 64 ビット・アーキテクチャーでデフォルトでオンになるフレーム・ポインターを含みます。
- インテル® QAT 統合 – 第 4 世代および新しいインテル® Xeon® スケーラブル・プロセッサーでの暗号化と圧縮の高速化、CPU 利用率の軽減、ネットワークとストレージ・アプリケーションのパフォーマンス向上を実現します。
- インテル® TDX サポート – アプリケーション層に変更を加えることなく、ホスト側とゲスト側の両方で拡張機能をシームレスにサポートし、既存のワークロードのコンフィデンシャル・コンピューティング環境への移植と移行を大幅に簡素化します。
- 開発者の生産性の向上 – Python* 3.12、Ruby 3.2、PHP 8.3、Go* 1.22 が含まれており、.NET、Java*、Rust* の開発者エクスペリエンスに重点が置かれています。
詳細 (英語)
Ubuntu* 24.04 LTS のダウンロード (英語)
ブログ記事「Noble Numbat Deep Dive」 (英語)
Canonical について
Ubuntu* の発行元である Canonical (英語) は、オープンソースのセキュリティー、サポート、サービスを提供しています。そのポートフォリオは、最小のデバイスから最大のクラウドまで、カーネルからコンテナまで、データベースから AI まで、重要なシステムをカバーしています。
Seekr がインテル® Tiber™ デベロッパー・クラウドで大幅なコスト削減と AI ビジネスの成長を実現
2024年4月10日 | インテル® Tiber™ デベロッパー・クラウド
コンテンツの評価と生成向けの低コストで信頼できる AI
![]() Fast Company によって 2024年の最も革新的な企業の 1 つに選ばれた Seekr (英語) は、インテル® Tiber™ デベロッパー・クラウド1 を利用して、インテル® Gaudi® 2 AI アクセラレーターを含む最新のインテルのハードウェアとソフトウェアで構成される、費用対効果に優れたクラスター上で高度な LLM を構築、トレーニング、デプロイしています。AI を高速化するインテルとの戦略的協業により、Seekr は増え続ける計算能力への需要に対応しつつ、クラウドコストを削減し、ワークロードのパフォーマンス向上を達成しています。
Fast Company によって 2024年の最も革新的な企業の 1 つに選ばれた Seekr (英語) は、インテル® Tiber™ デベロッパー・クラウド1 を利用して、インテル® Gaudi® 2 AI アクセラレーターを含む最新のインテルのハードウェアとソフトウェアで構成される、費用対効果に優れたクラスター上で高度な LLM を構築、トレーニング、デプロイしています。AI を高速化するインテルとの戦略的協業により、Seekr は増え続ける計算能力への需要に対応しつつ、クラウドコストを削減し、ワークロードのパフォーマンス向上を達成しています。
ソリューションの概要
Seekr の人気製品である Flow と Align は、顧客が AI を活用してコンテンツと広告戦略を展開および最適化し、スケーラブルで構成可能なワークフローを使用して LLM パイプライン全体をトレーニング、構築、管理するのに役立ちます。
これには膨大な計算能力が必要であり、これまでは多額のインフラストラクチャー投資とクラウドコストを要していました。
運用ワークロードをオンプレミスからインテル® Tiber™ デベロッパー・クラウドに移行することで、Seekr は、数千枚のインテル® Gaudi® 2 カードを含むインテルのハードウェアおよびソフトウェア・テクノロジーの能力と容量を利用して、従来よりも低コストで、非常に高いパフォーマンスの LLM を構築できるようになりました。
詳細 (英語) →
ケーススタディー (ベンチマークを含む)
Seekr について
Seekr は、ブランドの信頼に対する顧客のニーズを解決しながら、インターネットをより安全で価値のあるものにすることを目標に、大規模な信頼性の高いコンテンツを識別、採点、生成する大規模言語モデル (LLM) を構築しています。同社の顧客には、Moderna、SimpliSafe、Babbel、Constant Contact、Indeed が含まれます。
1 旧「インテル® デベロッパー・クラウド」は、エンタープライズ・ビジネス・ソリューションのインテル® Tiber™ ポートフォリオの一部になりました。
Intel Vision 2024 でオープンかつセキュアなエンタープライズ AI への全面的な取り組みを発表
2024年04月9日
Intel Vision 2024 (英語) において、インテル コーポレーション CEO の Pat Gelsinger は、AI 全体にわたる新しい戦略、次世代の製品とポートフォリオ、顧客、コラボレーションを紹介しました。
最初に紹介されたインテル® Tiber™ は、AI、クラウド、エッジ、信頼性とセキュリティーにわたるエンタープライズ向けソフトウェアとサービスの展開を合理化する補完的なビジネス・ソリューションと、エンタープライズ向け生成 AI にさらなるパフォーマンス、オープン性、選択肢をもたらすインテル® Gaudi® 3 アクセラレーターで構成されるポートフォリオです。
20 社を超える顧客企業が、インテル® アーキテクチャー上で動作する主要な AI ソリューションを展示し、LLM/LVM プラットフォーム・プロバイダーである Landing.ai、Roboflow、および Seekr が、インテル® Tiber™ デベロッパー・クラウド上でインテル® Gaudi® 2 アクセラレーターを使用して、運用レベルのソリューションを開発、チューニング、デプロイするデモを実施しました。
またインテルは、Google Cloud、Thales、Cohesity とのコラボレーションにより、インテルのコンフィデンシャル・コンピューティング機能を各社のクラウド・インスタンスに実装する計画を発表しました。これには、インテル® トラスト・ドメイン・エクステンションズ (インテル® TDX)、インテル® ソフトウェア・ガード・エクステンションズ (インテル® SGX)、インテル® Tiber™ Trust Services1 認証サービスが含まれます。
さらに、エンタープライズ AI 向けオープン・プラットフォームの開発、E-core および P-core 搭載のインテル® Xeon® 6 プロセッサーとクライアント、エッジ、コネクティビティー向けのシリコンを含むインテルの AI ロードマップとオープン・エコシステム・アプローチの拡大についても発表がありました。
あらゆる企業が急速に AI 対応の組織へと移行しています。インテル® Gaudi® アクセラレーター、インテル® Xeon® プロセッサー、インテル® Core™ Ultra プロセッサー、イーサネット対応ネットワーク、オープン・ソフトウェアなど、柔軟なソリューションを結集したインテルのオープンでスケーラブルなシステムは、現在および将来にわたって企業の AI ニーズに応え、企業全体に AI を浸透させています。
主な内容
![]() ビジネス向けソリューションを提供するインテル® Tiber™ ポートフォリオは、AI を含め企業環境へのソフトウェアやサービスの導入を効率化し、顧客企業と開発者がセキュリティー、コンプライアンス、パフォーマンスのいずれも妥協することなく、ニーズに合ったソリューションを見つけ、イノベーションを加速し、価値を最大限に引き出すことを容易にします。完全な展開は 2024年の第 3 四半期に予定されています。インテル® Tiber™ については、こちらを参照してください。
ビジネス向けソリューションを提供するインテル® Tiber™ ポートフォリオは、AI を含め企業環境へのソフトウェアやサービスの導入を効率化し、顧客企業と開発者がセキュリティー、コンプライアンス、パフォーマンスのいずれも妥協することなく、ニーズに合ったソリューションを見つけ、イノベーションを加速し、価値を最大限に引き出すことを容易にします。完全な展開は 2024年の第 3 四半期に予定されています。インテル® Tiber™ については、こちらを参照してください。
インテル® Gaudi® 3 AI アクセラレーターは、インテル® Gaudi® 2 AI アクセラレーターと比較して、計算能力が 4 倍、メモリー帯域幅が 1.5 倍増加しており、LLaMa 7B および 70B、Falcon 180B の LLM 推論で平均 50%、電力効率で 60% NVIDIA* H100 を上回るパフォーマンスを発揮すると予測されています。インテル® Tiber™ デベロッパー・クラウドを含め、2024年の第 2 四半期に利用可能になる予定です。
インテル® Tiber™ デベロッパー・クラウドの最新リリースには、インテル® Gaudi® 2 アクセラレーターとインテル® データセンター GPU マックス・シリーズの大規模クラスターをホストする BMaaS (Bare Metal as a Service) オプション、インテル® Gaudi® 2 アクセラレーター上で動作する VM、ファイルストレージを含む StaaS (Storage as a Service)、クラウドネイティブな AI ワークロード向けのインテル® Kubernetes Service など計算能力を高める新しいハードウェアとサービスが含まれています。
Seekr がインテル® Tiber™ デベロッパー・クラウドを利用して、大規模なコンテンツの生成と評価向けの信頼できる LLM をデプロイした事例をご覧ください。
コンフィデンシャル・コンピューティングにおける Thales と Cohesity とのコラボレーションは、信頼性とセキュリティーを向上し、企業顧客のリスクを軽減します。
- 世界有数のテクノロジーおよびセキュリティー・プロバイダーの Thales (英語) は、エンドツーエンドのデータ保護を提供する Google Cloud Platform* 上の独自の CipherTrust データ・セキュリティー・プラットフォームと、コンフィデンシャル・コンピューティングとクラウドに依存しない信頼性認証を提供するインテル® Tiber™ Trust Services で構成されるデータ・セキュリティー・ソリューションを発表しました。これにより、企業は保存中、転送中、使用中のデータを保護する追加の制御が可能になります。
- AI を活用したデータ・セキュリティーと管理のリーダーである Cohesity は、Cohesity Data Cloud にコンフィデンシャル・コンピューティング機能を追加したことを発表しました。このソリューションは、インテル® SGX およびインテル® Tiber™ Trust Services と連携し、使用中のデータを暗号化する FortKnox サイバー保管庫サービスを活用することで、メインメモリーで処理中のデータに悪意のある企業がアクセスするリスクを低減します。これは、金融サービス、ヘルスケア、政府機関など規制のある産業にとって非常に重要です。
関連情報
- インテルのエンタープライズ・ソフトウェア・ソリューション
- インテル® Tiber™ デベロッパー・クラウド
- インテル® Confidential Computing Solutions (英語)
- インテル® トラスト・ドメイン・エクステンションズ (インテル® TDX)
- インテル® ソフトウェア・ガード・エクステンションズ (インテル® SGX)
1 旧インテル® Trust Authority
インテル® ソフトウェア開発ツールのバージョン 2024.1 リリース
2024年03月28日 | インテル® ソフトウェア開発ツール
世界初の SYCL* 2020 準拠ツールチェーンで、自信を持ってコードを高速化
インテル® ソフトウェア開発ツール 2024.1 がリリースされました。アクセラレーテッド・コンピューティングにとって重要なマイルストーンとして、インテル® oneAPI DPC++/C++ コンパイラーが SYCL* 2020 仕様 (英語) を完全に採用した最初のコンパイラー (英語) となりました。
なぜこれが重要なのか?
SYCL* 2020 準拠のコンパイラーがあることで、開発者はコードが移植可能で、現在および将来のさまざまなアーキテクチャーとハードウェア・ターゲット (GPU を含む) にわたって確実にパフォーマンスを発揮することを確信できます。
「SYCL* 2020 は、生産性の高いヘテロジニアス・コンピューティングを可能にし、今日のソフトウェアとハードウェアの複雑な現実に対応するハイパフォーマンスな並列ソフトウェアを作成するために必要な制御を提供します。SYCL* 2020 Khronos Adopter となったことで、オープン・スタンダードのサポートに対するインテルの取り組みが改めて示されました。」
主な利点
自信を持ってコードを作成し、高速にビルド – SYCL* 2020 に完全準拠したインテル® oneAPI DPC++/C++ コンパイラーを利用して、最新の C++ コードのパフォーマンスと生産性を高めるため並列処理を最適化します。AI、HPC、分散コンピューティングにわたる新しいマルチアーキテクチャー機能を探索します。また、拡張されたウェブベースのセレクター (英語) のオプションセットを使用して、関連する AI ツールに素早く簡単にアクセスできます。
AI ワークロードの高速化と計算コストの軽減 – インテルの新しい CPU および GPU でパフォーマンスを向上します。これには、第 5 世代インテル® Xeon® スケーラブル・プロセッサー上で oneDNN を使用した最大 14 倍のパフォーマンス向上1、PyTorch* や TensorFlow*2 などの一般的なディープラーニング・フレームワークとライブラリーの 10 倍から 100 倍の高速化、XGBoost、LightGBM、および CatBoost にわたるより高速な勾配ブースティング推論が含まれます。scikit-learn* 向けインテル® エクステンションのアルゴリズム拡張機能を使用して、コストを削減して並列計算を実行します。
イノベーションの促進とデプロイの拡大 – インテル® oneAPI DPC++/C++ コンパイラーで複数の SYCL* バックエンドで利用できるようになった、SYCL* Graph を使用した効率良いコードオフロードにより、一度のチューニングで汎用的にデプロイできます。インテル® DPC++ 互換性ツールでは、より多くの CUDA* API を CUDA* から SYCL* へ簡単に移行できるようになりました。さらに、CodePin 技術プレビュー (SYCLomatic の新機能) で時間の節約を調査し、テストベクトルを自動キャプチャーし、移行後すぐに検証を開始できます。Codeplay は、NVIDIA* GPU と AMD* GPU 用の oneAPI プラグインに新しいサポートと機能を追加しています。
要点
以下は、コンポーネント・レベルの詳細です。
コンパイラー
インテル® oneAPI DPC++/C++ コンパイラーは、SYCL* 2020 準拠の最初のコンパイラーであり、開発者は SYCL* コードが移植可能であり、現在および将来のさまざまな GPU 上で確実に動作することを確信できます。強化された SYCL* Graph により、マルチスレッド処理やスレッドセーフ関数をアプリケーションとシームレスに統合できるようになり、複数の SYCL* バックエンドで利用できるようになったため、一度のチューニングでどこでもデプロイすることが可能です。OpenMP* 5.0、5.1、5.2、TR12 言語標準への準拠が拡張され、パフォーマンスが向上しました。
インテル® Fortran コンパイラーは、C コードと Fortran コード間の互換性と相互運用性の向上、三角関数の計算の簡素化、事前定義されたデータ型など、Fortran 2023 言語機能をさらに追加して、コードの移植性を向上させ、一貫した動作を保証します。OpenMP* オフロード・プログラミングの生産性が向上し、コンパイラーの安定性も向上しています。
パフォーマンス・ライブラリー
インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) は、インテル® GPU とホスト CPU 間のデータ転送を軽減する新しい最適化と機能を導入し、CNR を介してインテル® GPU 上で BLAS レベル 3 演算の結果を実行間で再現できるようにします。また、CUDA* と同等の機能を追加することで、CUDA* から SYCL* への移行を合理化します。
インテル® oneAPI データ・アナリティクス・ライブラリー (インテル® oneDAL) は、精度を犠牲にすることなく、XGBoost、LightGBM、および CatBoost にわたる勾配ブースティング推論の高速化を可能にします。観測値のクラスタリングに使用される特徴のサブセットを自動的に識別するスパース K 平均のサポートにより、クラスタリングを改善します。
インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) (英語) は、LLM パフォーマンスを向上する GPT-Q のサポート、プリミティブと Graph API の fp8 データ型、レイヤーの正規化用の fp16 および bf16 のスケール引数とシフト引数、固定環境の実行間で結果がビット単位で同一であることを保証するオプトイン決定論的モードが追加されています。
インテル® oneAPI DPC++ ライブラリー (インテル® oneDPL) (英語) は、インテル® GPU 上でアプリのパフォーマンスを向上させる特殊なソート・アルゴリズムと、ステンシル計算のニーズに対応するマスク入力を備えた transform_if バリアントが追加され、AI と科学計算を高速化するため、ヒストグラム・アルゴリズムを使用して C++ STL 形式のプログラミングを拡張しています。
インテル® oneAPI コレクティブ・コミュニケーション・ライブラリー (oneCCL) (英語) は、すべての主要な通信パターンを最適化し、メモリー効率の良い方法でメッセージの受け渡しを高速化し、推論パフォーマンスを向上します。
インテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) は、大規模なデータ集約型アプリケーションにおいて高速なデータ転送とストレージ要件の軽減を実現するため、XMSS ポスト量子ハッシュベースの暗号化アルゴリズム (技術プレビュー)、FIPS 140-3 準拠、更新された LZ4 可逆データ圧縮アルゴリズムなど、量子コンピューティング、サイバーセキュリティー、およびデータ圧縮の機能とサポートを拡張しています。
インテル® MPI ライブラリーは、リモートメモリーへ効率良くアクセスする GPU RMA や、MPI 4.0 の Persistent Collectives や Large Counts サポートなど、アプリケーションのパフォーマンスとプログラミングの生産性を向上する新機能が追加されています。
AI および ML ツールとフレームワーク
インテル® ディストリビューションの Python* は、データ並列制御 (dpctl) ライブラリーの Python* 配列 API 標準への完全準拠や NVIDIA* デバイスのサポートなど、より将来性の高いコードを開発する機能を拡張してます。NumPy* 用データ並列拡張機能では、線形代数、データ操作、統計、データ型が強化され、キーワード引数のサポートが拡張されています。Numba* 用データ並列拡張機能では、カーネルの起動時間が改善されています。
scikit-learn* 向けインテル® エクステンション (英語) は、増分共分散を使用して変更されたデータセット部分のみで計算を行い、SPMD インターフェイスを使用して並列 GPU 計算を実行することで、GPU の計算コストを軽減します。
Modin 向けインテル® ディストリビューション (英語) は、データ資産の脆弱性を事前に特定して修復する堅牢なセキュリティー・ソリューションや、非同期実行を最適化するパフォーマンスの修正など、セキュリティーとパフォーマンスを大幅に強化します (注: 2024.2 リリースでは、開発者はアップストリーム・チャネルを通じて Modin にアクセスできます)。
アナライザーとデバッガ―
インテル® VTune™ プロファイラーは、SYCL* アプリケーションのパフォーマンス低下を招くホストと GPU 間の暗黙の USM データ移動を特定し、理解するのに役立つ機能が拡張されています。また、.NET 8、Ubuntu* 23.10、および FreeBSD* 14.0 がサポートされました。
インテル® ディストリビューションの GDB (英語) は、最新のアプリケーション・デバッグ機能に対応するため、GDB 14 ベースに変わりました。メモリーアクセスの問題をリアルタイムでモニターし、トラブルシューティングできます。GPU アクセラレーション・アプリケーションのより包括的なデバッグと最適化のため、大規模汎用レジスターファイル用のデバッグモードがサポートされました。
レンダリングとレイトレーシング
インテル® Embree は、クロスアーキテクチャー・コードの移行をスムーズにするため、SYCL* プラットフォームとドライバーのエラーレポートを強化しています。安定性、セキュリティー、パフォーマンス機能が向上しています。
インテル® オープン・イメージ・デノイズは、x86 および ARM 製 CPU (Windows*、Linux*、macOS* での ARM サポートを含む)、および インテル、NVIDIA、AMD、Apple 製の GPU など、すべてのプラットフォームでマルチベンダーのノイズ除去を完全にサポートします。
関連情報
- インテル® コンパイラーが初めて SYCL* 2020 準拠を達成 (英語)
- 2024.1 リリースに関する開発者の見解 (英語)
- Codeplay の oneAPI プラグインをダウンロード: NVIDIA* GPU 用 (英語) | AMD* GPU 用 (英語)
脚注
パフォーマンス指標: 第 5 世代インテル® Xeon® スケーラブル・プロセッサー (英語)
2 「ソフトウェア AI アクセラレーターで最大 100 倍のパフォーマンス向上を実現」
インテル® Gaudi®2 アクセラレーターとインテル® Xeon® プロセッサーは生成 AI に高度な推論パフォーマンスを提供
2024年3月27日 | インテル® デベロッパー・クラウド、MLCommons (英語)
インテル® Gaudi®2 アクセラレーターと第 5 世代インテル® Xeon® プロセッサーの最新の MLPerf* の結果は、インテルが生成 AI のパフォーマンスの水準を高めていることを示しています。
本日 MLCommons は、インテル® Gaudi®2 アクセラレーターとインテル® AMX をサポートする第 5 世代インテル® Xeon® スケーラブル・プロセッサーを含む、業界標準の推論ベンチマーク MLPerf* v4.0 の結果を発表しました。
インテル® Gaudi®2 アクセラレーターは、大規模言語モデル (LLM) およびマルチモーダル・モデルにおいて、NVIDIA* H100 に代わる唯一のベンチマーク対象製品として、総所有コストを評価する際に重要となる説得力のある価格/性能を提供します。CPU では、インテルは MLPerf の結果を提出した唯一のサーバー CPU ベンダーです (そして、インテル® Xeon® プロセッサーは多くのアクセラレーターのホスト CPU です)。
詳細と結果は、こちら (英語) を参照してください。
インテル® デベロッパー・クラウドで評価
インテル® デベロッパー・クラウドでは、小規模および大規模なトレーニング (LLM または生成 AI) や推論用のプロダクション・ワークロードの大規模な実行、AI コンピューティング・リソースの管理など、第 5 世代インテル® Xeon® プロセッサーおよびインテル® Gaudi®2 アクセラレーターを評価できます。こちらからサブスクリプション・オプションを確認し、アカウントにも申し込むことができます。
インテルが常時稼働の CPU パフォーマンス解析を自動化する Continuous Profiler ソリューションをオープンソース化
2024年3月11日 | インテル® Granulate™ Cloud Optimization Software (英語)
継続的かつ自律的な方法で実行時の効率を把握して、コードの最適化を簡素化
本日、インテルは、オープンソースの Continuous Profiler 最適化エージェントを公開しました。これは、イノベーションを促進し、開発者の生産性を向上する同社のオープン・エコシステム・アプローチの新たな一例です。
名前が示すように、Continuous Profiler は CPU 使用率を永続的に監視して、開発者、パフォーマンス・エンジニア、DevOps に、アプリケーションとワークロードのランタイムの非効率性を特定する常時稼働の自律的な方法を提供します。
仕組み
複数のサンプリング・プロファイラーを 1 つのフレームグラフに統合して、CPU が何に時間を費やしているか、特にコード内で高いレイテンシーやエラーが発生している場所を統一的に視覚化します。
使用すべき理由
Continuous Profiler は、チームがパフォーマンス・エラーを見つけて修正し、スムーズにデプロイできるよう支援する多数の独自機能を備えており、インテル® Granulate™ の継続的最適化サービスと互換性があり、数分でクラスター全体にデプロイでき、コードを変更することなくさまざまなプログラミング言語をサポートしています。
さらに、SOC2 認定 (英語) を受けており、インテルの高いセキュリティー基準に準拠しているため、導入における信頼性と信頼性が保証されます。Continuous Profiler は、Snap Inc. (Snapchat と Bitmoji)、ironSource (アプリ・ビジネス・プラットフォーム)、ShareChat (ソーシャル・ネットワーク・プラットフォーム) で採用されています。
プレスリリース (英語)
関連情報
- GitHub* から Continuous Profiler を入手 (英語)
- インテル® Granulate™ 継続的プロファイル (http://granulate.io/continuous-profiling/)
- インテル® Granulate™ のデモを申し込む (http://granulate.io/request-a-demo/)
インテル® ソフトウェア開発ツール @KubeCon Europe 2024
2024年2月29日 | インテル® ソフトウェア開発ツール @ KubeCon Europe 2024 (英語)
![]() インテルのエンタープライズ・ソフトウェア・ポートフォリオはエンタープライズ・アプリケーションで k8s スケーラビリティーを実現
インテルのエンタープライズ・ソフトウェア・ポートフォリオはエンタープライズ・アプリケーションで k8s スケーラビリティーを実現
KubeCon Europe 2024 (3月19日~22日) では、インテルのエンタープライズ・ソフトウェア・エキスパートから、デプロイメントの合理化と拡張、Kubernetes コストの削減、エンドツーエンドのデータ・セキュリティーを実現する方法を聞くことができます。
さらに、「Above the Clouds with American Airlines」 (英語) セッションに参加することで、世界トップクラスの航空会社がインテル® Granulate™ ソフトウェアを使用して、同社の最大のクラウドベースのワークロードで 23%のコスト削減を達成した方法を学ぶことができます。
インテルの K8s 向けエンタープライズ・ソフトウェアを採用する理由
インテルのエンタープライズ・ソフトウェア・ポートフォリオは、クラウドネイティブなアプリケーションとソリューションを効率良く大規模に高速化し、AI への道を素早く切り開くことを目的として構築されています。つまり、運用レベルの Kubernetes ワークロードを、管理しやすく、セキュアで、効率良くスケーリングする方法で実行できます。
次のようなメリットが得られます。
- 最適化されたパフォーマンスとコスト削減
- 合理化されたワークフローによる優れたモデル
- セキュアでコンプライアンスに準拠したコンフィデンシャル・コンピューティング
インテルのエンタープライズ・ソフトウェア・ソリューションの詳細は、ブース #J17 でご確認ください。
KubeCon EU 2024 でインテルについて知ろう (英語) →
関連情報
- イベントの詳細と登録 (英語)
- イベントのスケジュール (英語)
Prediction Guard はインテル® デベロッパー・クラウドにより LLM の信頼性とセキュリティーを顧客に提供
2024年2月22日 | インテル® デベロッパー・クラウド
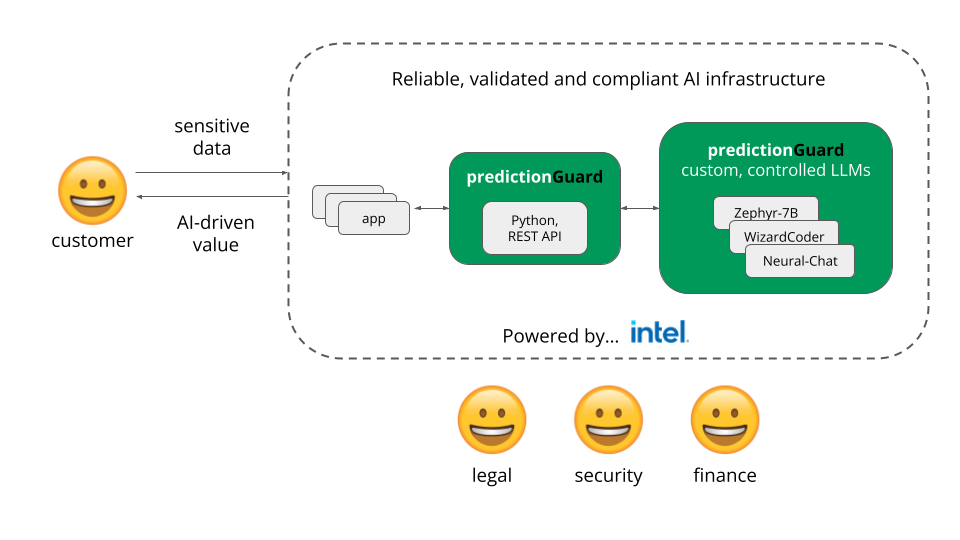 AI スタートアップの Prediction Guard (英語) は、インテル® デベロッパー・クラウドのセキュアでプライベートな環境で LLM API をホスティングしており、インテルの回復機能を備えたコンピューティング・リソースを活用して、顧客の生成 AI アプリケーション向けにクラウド運用で最高のパフォーマンスと一貫性を提供しています。
AI スタートアップの Prediction Guard (英語) は、インテル® デベロッパー・クラウドのセキュアでプライベートな環境で LLM API をホスティングしており、インテルの回復機能を備えたコンピューティング・リソースを活用して、顧客の生成 AI アプリケーション向けにクラウド運用で最高のパフォーマンスと一貫性を提供しています。
同社の AI プラットフォームは、幻覚、有害な出力、プロンプトの注入などのセキュリティーと信頼性の問題を軽減しながら、企業が大規模な言語モデルの可能性を最大限に活用できるようにします。
インテル® デベロッパー・クラウドに移行することで、Prediction Guard は顧客に信頼性の高いコンピューティング能力と、最新の AI ハードウェア・アクセラレーション、ライブラリー、およびフレームワークを提供しています。同社は現在、インテル® Gaudi®2 AI アクセラレーター、インテルと Hugging Face が協力して提供している Optimum Habana ライブラリー、PyTorch* 向けインテル® エクステンション、および Transformer を利用しています。
「一部のモデルでは、インテル® Gaudi®2 への移行により、スループットを 2 倍向上する一方でコスト削減を実現しました。」
Prediction Guard
創設者
Daniel Whitenack 氏
関連情報
Prediction Guard は、初期段階の AI やマシンラーニングなどのスタートアップ企業によるイノベーションとスケールアップを支援する、インテル® Liftoff 無料プログラムに参加しています。
新しい調査で 2024年のクラウド最適化の現状が明らかに
2024年2月20日 | インテル® Granulate™ ソフトウェア (英語)
インテル® Granulate™ クラウド最適化チームが実施し、新たに発表されたグローバル調査では、さまざまな業界にわたる 413 組織の DevOps、データ・エンジニアリング、IT リーダーのクラウド・コンピューティングにおける主要な傾向と戦略が評価されました。
調査結果から、大多数の組織 (66% 以上) にとって優先事項の 1 位と 2 位は、クラウドのコスト削減とアプリケーション・パフォーマンスの向上であることが明らかになりましたが、54% にはクラウドベースのワークロード最適化を専門とするチームがありません。
レポートでは、次のような傾向についても詳しく説明しています。
- クラウド最適化の優先順位と目標
- 現在の最適化の取り組みの評価
- 最もコストが高く、最適化が困難なクラウドベースのワークロード
- 技術スタックで使用される最適化ツール
- 2024年に向けたイノベーション
レポートをダウンロードする: http://granulate.io/lp/state-of-cloud-optimization-2024/
アメリカン航空がインテル® Granulate™ によりクラウド・ワークロードのコストを 23% 削減
2024年1月29日 | インテル® Granulate™ Cloud Optimization Software (英語)
アメリカン航空 (AA) はインテル® Granulate™ を利用して、Databricks データレイクに保存されている最も困難なワークロードを最適化し、維持することが難しいデータ管理価格の課題を軽減しました。
コード変更や開発作業を必要とせずに自律的かつ継続的な最適化を実現するインテル® Granulate™ ソリューションを導入することで、AA のエンジニアリング・チームは最適なペースと規模でデータを処理および分析し、ジョブクラスター実行にかかるリソースの 37% 削減と、すべてのクラスターコストの 23% 削減を実現しました。
ケース・スタディーを読む: http://granulate.io/blog/american-airlines-journey-contain-data-lakes-costs/
Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。
インテル® SHMEM がオープンソースをリリース
2024年1月10日 | インテル® SHMEM (英語) [GitHub]
インテル® SHMEM オープンソース・ライブラリーの最初のバージョン 1.0.0 は、OpenSHMEM (英語) プログラミング・モデルを拡張し、SYCL* クロスプラットフォーム C++ プログラミング環境を使用してインテル® データセンター GPU をサポートします。
OpenSHMEM (SHared MEMory) は、分散メモリーシステムの SPMD (Single Program Multiple Data) プログラミングを可能にする並列プログラミング・ライブラリー・インターフェイス標準です。これにより、ユーザーはスーパーコンピューターやクラスター・コンピューター間でプログラムの多数のコピーを実行する単一のプログラムを作成できます。
インテル® SHMEM は、アプリケーションが SYCL* で実装されたデバイスカーネルで OpenSHMEM 通信 API を使用できるようにする C++ ライブラリーです。PGAS (Partitioned Global Address Space) プログラミング・モデルを実装しており、現在の OpenSHMEM 標準のホスト起動型操作のサブセットと、GPU カーネルから直接呼び出せる新しいデバイス起動型操作が含まれています。
主な機能
- インテル® データセンター GPU マックス・シリーズのサポート
- OpenSHMEM 1.5 準拠のポイントツーポイント RMA、アトミックメモリー、シグナリング、メモリー順序付け、および同期操作に対するデバイスおよびホスト API のサポート
- OpenSHMEM 集合操作におけるデバイスおよびホスト API のサポート
- リモート・メモリー・アクセス、シグナリング、集合、メモリー順序付け、および同期操作の SYCL* ワークグループおよびサブグループ・レベルの拡張機能に対するデバイス API サポート
- OpenSHMEM 仕様の C11 汎用選択ルーチンを置き換える C++ テンプレート関数ルーチンのサポート
- 高性能ネットワーク・サービスに適した Libfabric プロバイダーと Sandia OpenSHMEM で構成された場合の GPU RDMA サポート
- SHMEM Symmetric Heap にデバイスメモリーまたは USM を選択可能
詳細 (英語)
(インテルの 3 人のシニア・ソフトウェア・エンジニアによるブログ)
関連情報
- 完全なインテル® SHMEM 仕様 (英語)
- OpenSHMEM 標準 (英語) [PDF]
2023年
Codeplay の oneAPI for NVIDIA* GPU プラグインのアップデート
2023年12月23日
oneAPI と AI ツールで構成されるインテル® ソフトウェア開発ツールの最新バージョン 2024.0.1 には、Codeplay の oneAPI for NVIDIA* GPU プラグインへの注目すべき追加と改善が含まれています。
主な機能:
- バインドレス・イメージ – 現在の SYCL* 2020 のイメージ API を大幅に見直した SYCL* 拡張です。
- ユーザーは、メモリーとイメージをより柔軟に管理できます。
- ミップマップなどのさまざまなイメージタイプのハードウェア・サンプリングとフェッチ機能、およびサブ領域コピーなどのイメージをコピーする新しい方法を利用できます。
- Vulkan* などの外部グラフィックス API との相互運用性機能と、Blender と統合するための画像操作の柔軟性を提供します。
- SYCL* サポート
- 不均一グループ – 開発者は、ワークグループまたはサブグループ内の作業項目の一部のサブセット全体で同期操作を実行できます。
- ピアツーピア・アクセス – マルチ GPU システムでは、これにより、デバイス間のメモリー・アクセス・レイテンシーが短縮されたり、帯域幅が向上する可能性があります。
- SYCL-Graph の実験版 – 開発者が GPU に送信する操作を事前に定義できるため、パフォーマンスが向上し、時間を節約できます。
さらに、AMD プラグインは引き続きベータ版が提供されており、2024年に製品版がリリースされる予定です。
プラグインを入手
- oneAPI for NVIDIA* GPU (英語)
- oneAPI for AMD* GPU (英語)
- オープンソース・レポジトリー
http://github.com/intel/llvm/tree/sycl/sycl/plugins/unified_runtime/ur/adapters
関連情報
インテルの最新の AI アクセラレーション CPU + 2024.0 ソフトウェア開発ツール = 大規模なイノベーション
2023年12月14日 | AI Everywhere 基調講演、インテル® ソフトウェア開発ツール 2024.0
データセンター、クラウド、エッジにわたる AI ワークロードのパワーアップと最適化
本日、インテルの最新の AI アクセラレーション・プラットフォーム、第 5 世代インテル® Xeon® スケーラブル・プロセッサー (開発コード名 Emerald Rapids) とインテル® Core™ Ultra プロセッサー (開発コード名 Meteor Lake) が正式に発表されました。今朝、ニューヨークの Nasdaq で開催された「AI Everywhere」イベントで、インテル CEOのパット・ゲルシンガー (Pat Gelsinger) が発表したこれらのシステムは、開発者やデータ・サイエンティストに大規模な AI イノベーションを加速するための柔軟性と選択肢を提供します。
また、新たにリリースされたインテル® ソフトウェア開発ツール 2024.0 は、これらのプラットフォームをターゲットとするアプリケーションやソリューションをサポートする準備が整っています。
以下はその一部です。
第 5 世代インテル® Xeon® スケーラブル・プロセッサーに対応
第 5 世代インテル® Xeon® スケーラブル・プロセッサーは、第 4 世代インテル® Xeon® プラットフォームの進化版であり、AI、データベース、ネットワーク、HPC において、ワットあたりの優れた性能に加え、卓越したパフォーマンスと TCO を実現します。
インテルの 2024.0 リリースは、oneAPI により最適化されたツール、ライブラリー、AI フレームワークを提供し、開発者は第 4 世代および第 5 世代インテル® Xeon® スケーラブル・プロセッサー、およびインテル® Xeon® CPU マックス・シリーズの高度な機能を活用することで、アプリケーション・パフォーマンスを最大限に引き出すことができます。
- インテル® アドバンスト・マトリクス・エクステンション (インテル® AMX) 内蔵 AI アクセラレーター
- インテル® クイックアシスト・テクノロジー (インテル® QAT) 搭載ワークロード・アクセレーター
- 高帯域幅、低レイテンシーのデータ移動を実現するインテル® データ・ストリーミング・アクセラレーター (インテル® DSA)
- インテル® In-Memory Analytics Accelerator (インテル® IAA) による非常に高いスループットの圧縮/展開とプリミティブ分析機能
第 4 世代および第 5 世代インテル® Xeon® スケーラブル・プロセッサーと
インテル® マックス・シリーズ製品ファミリー向けソフトウェア・ツール (英語)
インテル® Core™ Ultra プロセッサーに対応
CPU、GPU、NPU (ニューラル・プロセシング・ユニット) を搭載したこのプラットフォームは、新しい Intel 4 プロセス上に構築されており、電力効率とパフォーマンスの最適なバランス、没入型体験、ゲーム、コンテンツ制作、生産性向けの専用 AI アクセラレーションを提供します。
インテルの 2024.0 リリースは、ISV、開発者、プロのコンテンツ制作者が、次のような新しいプラットフォームの最先端の機能を利用して、ゲーム、コンテンツ制作、AI、メディア・アプリケーションを最適化するのに役立ちます。
- インテル® AVX-512
- インテル® AI ブーストおよび推論アクセラレーション
- AV1 エンコード/デコード
- レイトレース・ハードウェア・アクセラレーション
インテル® Core™ Ultra プロセッサー向けソフトウェア・ツール (英語)
関連情報
- 基調講演のビデオ
- プレスリリース
- 新しいクイック・スタート・ガイド: PyTorch* と TensorFlow* の最適化、および OpenVINO™ ツールキットを使用したインテル® AMX による AI アクセラレーション (英語)

インテル® ソフトウェア開発ツールのバージョン 2024 リリース
2023年11月20日 | インテル® ソフトウェア開発ツール
AI および HPC 向けのマルチアーキテクチャーのパフォーマンス、移植性、生産性を拡大
インテル® ソフトウェア開発ツールの最新バージョン 2024 がリリースされ、拡張されたマルチアーキテクチャー機能により、開発者はインテルの CPU、GPU、AI アクセラレーターで AI、HPC、レンダリングのワークロードを高速化および最適化できるようになりました。Powered by oneAPI (現在は Unified Acceleration Foundation が推進) のツールは、オープンスタンダードに基づき、C++、OpenMP*、SYCL*、Fortran、MPI、および Python* を幅広くカバーしています。
5 つの主なメリット
(ほかのメリットについては、こちらのページ (英語) またはブログ記事 (英語) を参照してください。)
- 将来に対応したプログラミング – Python*、Modin、XGBoost、レンダリングのサポートを含む最新のインテル® GPU でのパフォーマンスの高速化、今後登場する第 5 世代インテル® Xeon® スケーラブル CPU とインテル® Core™ Ultra CPU のサポート、複数のツールで広範な標準に対応したことによる AI と HPC 機能の拡張。
- AI アクセラレーション – インテルにより最適化された PyTorch* および TensorFlow* フレームワークによるネイティブサポートと、Python* のデータ並列拡張機能の改善により、インテルの CPU および GPU で AI およびマシンラーニングを高速化。
- ベクトル演算の最適化 – oneMKL は、x86 CPU およびインテルの GPU 上の HPC シミュレーション、統計サンプリング、その他の分野向けに、ターゲットデバイスで RNG オフロードを統合し、インテルの GPU 上で FP16 データ型をサポート。
- 拡張された CUDA* から SYCL* への移行 – インテル® DPC++ 互換性ツール (オープンソースの SYCLomatic ベース) に CUDA* ライブラリー API と、AI、ディープラーニング、暗号化、科学シミュレーション、画像処理などの分野の 20 の一般的なアプリケーションを追加。
- 高度なプレビュー機能 – GPU オフロードを容易にする C++ Parallel STL、計算ノードのリソース使用量を最適化する動的デバイス選択、GPU オフロードのオーバーヘッドを軽減する SYCL* グラフ、インテル® oneTBB と OpenMP* 間のスレッド・オーバーサブスクリプションを防ぐスレッド・コンポーザビリティーを含む。
インテルの CPU と GPU + oneAPI の可能性
- ATLAS Experiment (https://atlas.cern/Discover/Detector/Software-Computing/Intel-Case-Study) は、インテルと NVIDIA* GPU 上での SYCL* と CUDA* コードのベンチマークを含む、インテル® ソフトウェア開発ツールにより最適化されたヘテロジニアス粒子再構成をインテル® GPU 上で実装することで、パフォーマンス向上を達成しました。
- oneAPI の STAC-A2 ベンチマーク実装 (英語) がインテル® GPU と NVIDIA* GPU の比較で記録を更新しました。
- VMware とインテルが共同で検証した AI スタック (英語) により、どこでもプライベート AI を利用して、モデルの開発と展開を行うことができます。
インテルの oneAPI ソフトウェア・ツールとライブラリーが HPCwire Reader's Choice Award を受賞
2023年11月13日
 |
素晴らしいニュースです! 2023 年の HPCwire Readers' and Editors' Choice Awards が発表され、インテルの oneAPI ソフトウェア開発ツールとライブラリーが、Best HPC Programming Tool or Technology (英語) を受賞しました。開発者と HPC エキスパートが新たなレベルの HPC と AI イノベーションを推進する中、彼らの投票によるこの栄誉は、オープンで標準ベースのマルチアーキテクチャー・プログラミングの重要性を証明するものです。oneAPI は、2020年以降、毎年 Editors' Choice Awards または Readers' Choice Awards を受賞しています。このような高い評価をいただいたことに感謝します。 |
インテル® デベロッパー・クラウドで AI ワークロードを高速化およびスケーリング
2023年9月20日 | インテル® デベロッパー・クラウド (英語)
開発者に最新のインテルの CPU、GPU、AI アクセラレーターへのアクセスを提供
Intel® Innovation 2023 で発表されたインテル® デベロッパー・クラウドが一般公開されました。このプラットフォームは、開発者、データ・サイエンティスト、研究者、組織に対して、最新の、場合によってはプレリリースのインテルのハードウェアとソフトウェア・サービスおよびツールに直接アクセスできる開発環境を提供します。これらはすべて、最新の技術機能に対応した製品とソリューションを開発、テスト、最適化し、迅速に市場に投入するのに役立ちます。
無償版と有償サブスクリプションが用意されています。
ハードウェアとソフトウェアの現在のラインナップは以下のとおりです。
- ハードウェア
- 第 4 世代インテル® Xeon® スケーラブル・プロセッサー (シングルノード、マルチアーキテクチャー・プラットフォーム、クラスター)
- インテル® Xeon® CPU マックス・シリーズ (高帯域幅メモリーのワークロード向け)
- インテル® データセンター GPU マックス・シリーズ (最も厳しい計算要件のワークロード向け)
- Habana® Gaudi®2 AI アクセラレーター (ディープラーニング・タスク向け)
- ソフトウェアとサービス
- 小規模および大規模の AI トレーニング、モデル最適化、および推論ワークロード (Meta AI Llama 2、Databricks Dolly など)
- 小規模から大規模の VM、フルシステム、クラスターを活用
- ソフトウェア・ツール (インテル® oneAPI ベース・ツールキット、インテル® oneAPI HPC ツールキット、インテル® oneAPI レンダリング・ツールキットなど)、インテル® Quantum SDK、AI ツールと最適化されたフレームワーク (インテル® OpenVINO™ ツールキット、インテルにより最適化された TensorFlow* および PyTorch*、インテル® ニューラル・コンプレッサー、インテル® ディストリビューションの Python* など) へのアクセス
今後さらに追加予定
今すぐ申し込む (英語)
Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。
Intel® Innovation 2023 の概要
2023年9月20日 | Intel® Innovation (英語)
2 日間にわたるインテルの開発者イベントには 2,000 人近くの参加者が集まり、ハードウェア、ソフトウェア、サービス、先進テクノロジーにわたる AI の最新のブレークスルーに注目した豊富なセッション (インテル コーポレーション CEO の Pat Gelsinger をはじめインテルのリーダーや業界の著名人による基調講演、ハンズオンラボ、技術的洞察パネル、トレーニングなど) が実施されました。
多くの発表がありました。そのうち 6 つを以下に示します。
「Siliconomy (シリコノミー)」。Pat Gelsinger は冒頭でこの言葉を紹介し、「AI は世代交代の象徴であり、世界経済が成長する新たな時代の到来を告げるものです。そして、すべての人々のよりよい未来にとって、コンピューティングを一層、なくてはならないものにします。」と述べました。
Pat Gelsinger による Siliconomy 論説 (英語) [PDF]インテル® デベロッパー・クラウドの一般提供。開発者は、インテルの最新のハードウェアとソフトウェアへのアクセスを提供するこの開発環境 (無償版と有償版があります) を活用して、AI や HPC 向けのアプリケーションとワークロードの開発、テスト、最適化、デプロイを行うことができます。第 4 世代インテル® Xeon® スケーラブル・プロセッサー、インテル® Xeon® プロセッサー・マックス・シリーズ、インテル® データセンター GPU マックス・シリーズ、Habana® Gaudi®2 AI アクセラレーター、インテル® oneAPI ツール、インテルにより最適化された AI ツールとフレームワーク、SaaS (Hugging Face BLOOM、Meta AI Llama 2、Databricks Dolly など) を含む、幅広いハードウェアとソフトウェア・ツールおよびサービスを利用できます。
インテル® デベロッパー・クラウドの詳細 (英語)インテルが Unified Acceleration (UXL) Foundation に加盟しました。oneAPI オープン・プログラミング・モデルの進化版として、Linux Foundation は、クロスプラットフォーム・アプリケーションの開発を簡素化するオープン・スタンダードなアクセラレーター・プログラミング・モデルに関する業界横断的な協力体制を確立するため、UXL Foundation を設立しました。
インテル コーポレーションのデベロッパー・ソフトウェア・エンジニアリング・マネージャーである Sanjiv Shah のブログ (英語) と Codeplay のエコシステム担当副社長である Rod Burns のブログ (http://codeplay.com/portal/news/2023/09/19/announcing-the-unified-acceleration-uxl-foundation) を読むIntel® Certified Developer – MLOps プロフェッショナル。MLOps のエキスパートが指導するこの新しい認定プログラムでは、自己学習モジュール、ハンズオンラボ、実習を使用して、コンピューティングを意識した AI ソリューション設計により AI パイプライン全体のパフォーマンスを最大化する方法を学ぶことができます。
プログラムの詳細 (英語)Intel® Trust Authority。この信頼とセキュリティー・サービスのスイートは、複数のクラウド、エッジ、オンプレミス環境などのプラットフォーム上でアプリケーションとデータが保護されていることを保証します。
Intel® Trust Authority の詳細 (英語)新しいエンタープライズ・ソフトウェアとサービスのポートフォリオ。シリコンベースのセキュリティーが組み込まれたスケーラブルで持続可能な技術スタックを提供することで、企業の最大の課題を解決するように設計されています。
セキュリティーを簡素化する製品 (英語) [Intel® Trust Authority]、投資対効果を高めるエンタープライズ AI を実現する製品 (英語) [インテル® デベロッパー・クラウド + Cnvrg.io]、およびリアルタイムの自律的ワークロード最適化によりアプリケーション・パフォーマンスを向上する製品 (英語) [Intel® Granulate] を含みます。

関連情報:
Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。
Unified Acceleration Foundation によりオープンな高速計算とクロスプラットフォーム・パフォーマンスを推進
2023年9月19日 | Unified Acceleration Foundation (英語)
本日、Linux Foundation は、ハイパフォーマンスのクロスプラットフォーム・アプリケーションの開発を簡素化する、オープンスタンダードのアクセラレーター・プログラミング・モデルの提供に取り組む業界横断的なグループである Unified Acceleration (UXL) Foundation の設立を発表しました。
oneAPI イニシアチブの進化である UXL Foundation は、イノベーションを推進し、業界全体で oneAPI 仕様を実装する次の重要なステップを示します。Arm、富士通、Google Cloud、Imagination Technologies、インテル、Qualcomm Technologies, Inc.、Samsung などの業界をリードする組織およびパートナーが、オープンソースのコラボレーションと、クロスアーキテクチャーの統一プログラミング・モデルの開発を促進するために結集しました。
「Unified Acceleration Foundation は、コラボレーションの力とオープンソース・アプローチを体現しています。主要なテクノロジー企業が団結し、クロスプラットフォーム開発のエコシステムを促進することで、データ中心のソリューションのパフォーマンスと生産性における新たな可能性を解き放ちます。」
関連情報
- 私たちの子供が大学を卒業します! (英語) – インテル コーポレーション ソフトウェア開発製品事業本部長 Sanjiv Shah
- Unified Acceleration (UXL) Foundation の発表 (英語) – Codeplay Software エコシステム担当副社長 Rod Burns
生産性を高めるプリセットの AI ツールバンドル
2023年8月21日 | ベータ版 AI ツールセレクター (英語)
新しい柔軟な AI ツール・インストール・サービスで必要なツールを選択
ディープラーニング・フレームワーク、ツール、ライブラリーの合理化されたパッケージ・インストールを支援する、インテルのベータ版 AI ツールセレクターが公開されました。データ・アナリティクス、古典的なマシンラーニング、ディープラーニング、推論最適化などの用途に合わせて、個別に、またはプリセットのバンドルをインストールできます。
以下のツールに対応しています。
- ディープラーニング・フレームワーク
- TensorFlow* 向けインテル® エクステンション
- PyTorch* 向けインテル® エクステンション
- ツールとライブラリー
- XGBoost 向けインテル® オプティマイゼーション
- scikit-learn* 向けインテル® オプティマイゼーション
- Modin 向けインテル® ディストリビューション
- インテル® ニューラル・コンプレッサー
- SDK とコマンドライン・インターフェイス (CLI):
- cnvrg Python* SDK V2
上記はすべて conda、pip、または Docker* パッケージ・マネージャーから入手できます。
あらゆる場所で AI を進化させる: インテルが PyTorch Foundation に加盟
2023年8月10日 | インテルの PyTorch* 最適化 (英語)
インテルは、PyTorch* の開発と民主化を加速させるため、PyTorch Foundation の Premier メンバーとなり、運営委員会の一員となりました。
PyTorch Foundation のウェブサイトでは、当財団について次のように記載されています。
「PyTorch Foundation は、ディープラーニング・コミュニティーがオープンソースの PyTorch* フレームワークとエコシステムに関して協力する中立的な拠点です。PyTorch* を使ったオープンソースでベンダーニュートラルなプロジェクトのエコシステムを育成し維持することで、AI とディープラーニング・ツールの採用を促進することを使命としています。」
これはインテルの目指すところと一致しています。インテルは 2018年から、ユビキタス・ハードウェアとオープン・ソフトウェアを通じて AI へのアクセスを民主化するというビジョンの下、PyTorch* フレームワークに貢献しています。一例として、最新のインテルによる PyTorch* の最適化と機能は、stock PyTorch* にアップストリームされる前に、PyTorch* 向けインテル® エクステンションで定期的にリリースされています。これにより、データ・サイエンティストやソフトウェア・エンジニアはアップストリーム前の拡張機能を利用して競争力を高め、最新のハードウェア・テクノロジーを活用した AI アプリケーションを開発することが可能です。
詳細 (英語)
PyTorch* 向けインテル® エクステンションのダウンロード (英語)
インテル/Accenture の AI リファレンス・キットで実証されたパフォーマンスの向上
2023年7月24日 | AI リファレンス・キット (英語)
AI 開発を簡素化する事前設定済みキット
以前にも取り上げた AI リファレンス・キットは、コンシューマー製品、エネルギー/公共事業、金融サービス、ヘルスケア/ライフサイエンス、製造、小売、電気通信分野の AI ワークロード向けの無料のドロップイン・ソリューションであり、全部で 34 種類あります。
AI リファレンス・キットに含まれるコードと機能を利用することで、複数の業界が目に見えるメリットを実感しています。
以下はその一例です。
- エンタープライズ向け会話型 AI チャットボットとの対話をセットアップする AI リファレンス・キットを使用することで、oneAPI の最適化によりバッチモードの推論が最大 45% 高速になりました。
https://github.com/oneapi-src/customer-chatbot - ライフサイエンス向けの視覚的品質管理検査を自動化する AI リファレンス・キットを使用することで、oneAPI の最適化により視覚的欠陥検出のトレーニングが最大 20% 高速化され、推論が 55% 高速化されました。
https://github.com/oneapi-src/visual-quality-inspection
公共設備の健全性を予測し、より高いサービスの信頼性を提供するため、予測精度を最大 25% 向上できる AI リファレンス・キットもあります。詳細 → (英語)
記事全文を見る → (英語)
AI リファレンス・キットの詳細 → (英語)
AI リファレンス・キットをダウンロード → (英語)
インテル® oneAPI ツール 2023.2 リリース
2023年7月20日 | インテル® oneAPI ツール
オープンなマルチアーキテクチャー・コンピューティング向けのソフトウェア開発ツールをさらに拡張 & 強化
インテル® oneAPI ツール 2023.2 は、マルチアーキテクチャー・ソフトウェア開発の自由度を Python* にもたらし、CUDA* からオープンな SYCL* への移行を簡素化し、最新の GPU および CPU ハードウェアでパフォーマンスを向上します。
詳細 (英語)
バージョン 2023.2 の主な機能
マルチアーキテクチャー対応のインテル® oneAPI にまだアップデートしていない場合、またはまだ試していない場合、本リリースでアップデートする 5 つのメリットがあります。
- CUDA* から優れたパフォーマンスの SYCL* への移行を簡素化 – AI、ディープラーニング、暗号化、科学シミュレーション、画像処理などの一般的なアプリケーションで、CUDA* から SYCL* へ容易に移行できます。新しいリリースでは、追加の CUDA* API、CUDA* の最新バージョン、FP64 がサポートされ、移行範囲が広がりました。
- より高速で高精度な AI 推論 – 推論時の NaN (Not a Number) 値のサポートにより、前処理が効率化され、不完全なデータでトレーニングしたモデルの予測精度が向上します。
- GPU での AI ベースの画像補正の高速化 – インテル® オープン・イメージ・デノイズ・レイトレーシング・ライブラリーは、インテルや他のベンダーの GPU をサポートし、高速で忠実度の高い AI ベースの画像補正を実現するハードウェアの選択肢を提供します。
- AI および HPC 向けの Python* の高速化 – このリリースでは、ベータ版の Data Parallel Extensions for Python* が導入され、NumPy* および cuPy* 関数で Python* の数値計算機能が GPU に拡張されています。
- 効率良い並列コードを記述するための合理化 – インテル® Fortran コンパイラーが DO CONCURRENT リダクションをサポートしました。この強力な機能は、コンパイラーがループを並列に実行できるようにし、コードのパフォーマンスを大幅に向上させるとともに、効率良く正しい並列コードの記述を容易にします。
各ツールの主な機能
コンパイラーと SYCL* サポート
- インテル® oneAPI DPC++/C++ コンパイラーは、即時コマンドリスト機能をデフォルトとして設定します。これは、インテル® データセンター GPU マックス・シリーズへの計算のオフロードを検討している開発者に役立ちます。
- インテル® oneAPI DPC++ ライブラリー (インテル® oneDPL) (英語) は、インテル® GPU で実行する C++ STD ライブラリーのソートおよびスキャン・アルゴリズムのパフォーマンスを向上します。これにより、C++ アプリケーションで一般的に使用されるアルゴリズムが高速化されます。
- インテル® DPC++ 互換性ツール (インテル® DPCT) (英語) は、オープンソースの SYCLomatic プロジェクトをベースとしており、CUDA* 12.1 とさらに多くの関数呼び出しをサポートし、AI、暗号化、科学シミュレーション、画像処理など多数のドメインで CUDA* から SYCL* への移行を合理化し、移行したコードに FP64 認識を追加して、FP64 ハードウェアのサポートの有無にかかわらず、インテル® GPU 間での移植性を確保します。
- インテル® Fortran コンパイラーは、リダクション・コードのパフォーマンスを大幅に向上し、効率良い並列コードの作成を容易にする DO CONCURRENT リダクションをサポートしました。
AI フレームワークとライブラリー
- インテル® ディストリビューションの Python* は、CPU プログラミング・モデルを GPU に拡張し、NumPy* と CuPy* で CPU と GPU を利用してパフォーマンスを向上するベータ版 Parallel Extensions for Python を導入しました。
- インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) (英語) は、AI ワークロードのトレーニングと推論の高速化、より簡単なデバッグと診断、グラフ・ニューラル・ネットワーク (GNN) 処理のサポート、および第 4 世代インテル® Xeon® スケーラブル プロセッサーやインテルおよびその他のベンダーの GPU など、多数のプロセッサーでのパフォーマンスの向上をもたらします。
- インテル® oneAPI データ・アナリティクス・ライブラリー (インテル® oneDAL) の Model Builder 機能は、推論中に NaN サポートの欠損値を追加し、前処理を合理化し、不完全なデータでトレーニングされたモデルの予測精度を高めます。
パフォーマンス・ライブラリー
- インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) は、インテル® データセンター GPU マックス・シリーズおよびフレックス・シリーズのプロセッサーでカーネルの起動時間を大幅に短縮し、GPU 用の LINPACK ベンチマークを導入しました。
- インテル® MPI ライブラリーは、第 4 世代インテル® Xeon® スケーラブル・プロセッサーおよびインテル® Xeon® CPU マックス・シリーズのメッセージ パッシング パフォーマンスを向上し、インテル® GPU に重要な最適化をもたらします。
- インテル® oneAPI スレッディング・ビルディング・ブロック (インテル® oneTBB) のアルゴリズムとフロー・グラフ・ノードは、新しいタイプのユーザー呼び出し可能オブジェクトへの対応により、より強力で柔軟なプログラミング環境を実現します。
- インテル® インテグレーテッド・パフォーマンス・プリミティブ Cryptography (インテル® IPP Cryptography) (英語) のマルチバッファー・ライブラリーは、SM4 アルゴリズムの XTS モードをサポートしました。これにより、ストレージデバイスなどのセクターに保管されたデータを効率良くセキュアに暗号化する方法が開発者に提供されます。
解析とデバッグ
- インテル® VTune™ プロファイラーは、GPU オフロードのタスクと実行に関する情報を提供し、インテル® GPU 上の BLAS レベル 3 ルーチンのアプリケーション・プロファイルを改善し、プラットフォーム図でインテル® データセンター GPU マックス・シリーズのデバイスを識別します。
- インテル® ディストリビューションの GDB (英語) は、最新の状態を維持し、効果的なアプリケーションのデバッグと共有ローカルメモリー (SLM) のデバッグをサポートする最新の機能拡張に合わせて、GDB 13 をベースとするように変更されました。
詳細
- インテル® oneAPI およびインテル® AI ツール
- SYCL* 初心者向け SYCL* 入門
- oneAPI トレーニング・ポータル – ラーニングパス、ツール、オンデマンド・トレーニングなど、情報を共有して紹介する機会を利用して、好みの方法で学習できます。
法務上の注意書き
Codeplay はインテルの子会社です。
性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。結果は異なることがあります。
性能の測定結果はシステム構成の日付時点のテストに基づいています。また、現在公開中のすべてのセキュリティー・アップデートが適用されているとは限りません。
絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。実際の費用と結果は異なる場合があります。
インテルのテクノロジーを使用するには、対応したハードウェア、ソフトウェア、またはサービスの有効化が必要となる場合があります。
インテルは、サードパーティーのデータについて管理や監査を行っていません。ほかの情報も参考にして、正確かどうかを評価してください。
Blender* 3.6 LTS が インテル® GPU 上でインテル® Embree によるハードウェア・アクセラレーションのレイトレーシングを搭載
2023年6月29日 | インテル® Embree (英語)、Blender* 3.6 LTS (https://www.blender.org/download/releases/3-6/)
数々の賞を受賞したインテル® Embree が Blender* 3.6 LTS リリースに含まれました。インテルの高性能レイトレーシング・ライブラリーの追加により、コンテンツ制作者はインテル® Arc™ GPU、インテル® データセンター GPU フレックス・シリーズおよびマックス・シリーズ上で Cycles のハードウェア・アクセラレーションによるレンダリングを利用できるようになり、忠実度を損なうことなくレンダリング時間を大幅に短縮できます。
3.6 LTS には、インテル® オープン・イメージ・デノイズによる AI ベースのノイズ除去も含まれています。両ツールは、高性能で忠実度の高いビジュアル体験を作成するオープンソース・レンダリングおよびレイトレーシング・ライブラリーのセットである、インテル® oneAPI レンダリング・ツールキット (Render Kit) の一部です。
- ブログ (ベンチマークを含む)
http://game.intel.com/story/intel-arc-graphics-intel-embree-and-blender/ - デモ動画 [6:20] (英語)
- Blender 3.6 LTS のダウンロード (英語)
- Render Kit のダウンロード (英語)
UKAEA がインテルのハードウェアと oneAPI ソフトウェア・ツールを使用して核融合発電を実現
2023年6月29日 | インテル® oneAPI ツール
英国原子力公社 (UK Atomic Energy Authority、略称 UKAEA) と Cambridge Open Zettascale Lab は、インテル® ハードウェア、インテル® oneAPI ツール、および分散型非同期オブジェクト・ストレージ (DAOS) を使用して、英国における世界初の核融合発電所の設計、認証、建設、規制に必要な次世代エンジニアリング・ツールとプロセスを開発しています。これは、2040年代初頭までに商用核融合発電へのロードマップを加速するという英国の目標に沿ったものです。
UKAEA のチームは、スーパーコンピューティングと AI を使って核融合発電所を仮想的に設計しました。今後、チームは第 4 世代インテル® Xeon® プロセッサーや複数のベンダーの GPU、FPGA など、さまざまなアーキテクチャー上で多くの HPC ワークロードを実行する予定です。
これが重要な理由
複数のハードウェアに対して一度にプログラミングできることが重要です。oneAPI のオープンで標準ベースのマルチアーキテクチャ・プログラミングを使用することで、UKAEA チームはコードの移植性の課題を克服し、ベンダーに縛られないパフォーマンスと開発生産性を実現できます。
詳細
関連情報
新しい oneAPI Construction Kit オープンソース・プロジェクト
2023年6月5日
Codeplay はオープンで標準ベースの SYCL* プログラミングを新しいハードウェア、カスタム・ハードウェア、および専門ハードウェアに提供
Codeplay は、oneAPI エコシステムの最新の拡張として、SYCL* コードを HPC や AI 向けのカスタム・アーキテクチャー上で実行できるようにするオープンソース・プロジェクトを発表しました。
oneAPI Construction Kit には、RISC-V* ベクトル・プロセッサー向けのリファレンス実装が含まれていますが、さまざまなプロセッサーに適応させることができ、サポートされている豊富な SYCL* ライブラリーを簡単に利用できます。
カスタム・アーキテクチャーのユーザーにとっては、新しいカスタム言語を習得する必要がなく、SYCL* を使用して複数のアーキテクチャーで動作する単一のコードベースで、ハイパフォーマンスなアプリケーションを効率良く記述できるというメリットがあります。これは、移行作業やアーキテクチャーごとに異なるのコードベースの保守作業を軽減し、技術革新のための時間を増やすことを意味します。
oneAPI Construction Kit に含まれるもの
- 特殊な AI アクセラレーターなど、新しく革新的なハードウェアに oneAPI のサポートを提供するフレームワーク
- x86、ARM、および RISC-V* ターゲットのサポート
- ドキュメント
- リファレンス設計
- チュートリアル
- モジュラー・ソフトウェア・コンポーネント
関連情報と入手方法
- developer.codeplay.com (英語) から無料で入手可能
- デモ動画 [2:32] (英語)
- Codeplay 主席ソフトウェア・エンジニア Colin Davidson によるブログ
- ドキュメント (英語) を入手
インテルが oneAPI を利用して AI により高速化した HPC パフォーマンスを実現
2023年5月22日 | インテル® oneAPI ツール
ISC'23 のまとめ: 最も広範でオープンな HPC + AI ポートフォリオが、サイエンス向けのパフォーマンスと生成 AI を強化
International Super Computing (英語) 2023 のインテルによる基調講演では、CPU、GPU、AI アクセラレーター、oneAPI ソフトウェアの幅広い製品ポートフォリオに基づいて、マルチアーキテクチャー・プログラミングを容易にしてオープンなエコシステムを実現し、多様な HPC および AI ワークロードのパフォーマンスを高めるインテルの取り組みが強調されました。
以下は、基調講演の要点です。
ハードウェア:
- 独立系ソフトウェア・ベンダーである Ansys は、インテル® データセンター GPU マックス・シリーズが、AI により高速化された HPC アプリケーションにおいて、NVIDIA* H100 を 50% 上回るパフォーマンスを発揮し、さらに多様なワークロードにおいて H100 と比較して平均 30% のパフォーマンス向上が見られることを示しました。**
- Habana* Gaudi* 2 ディープラーニング・アクセラレーターは、DL トレーニングおよび推論において、NVIDIA* A100 よりも最大 2 倍高速な AI パフォーマンスを実現します。**
- インテル® Xeon® CPU (マックス・シリーズおよび第 4 世代を含む) は、帯域幅が制限された問題において、それぞれ AMD* Genoa よりも 65% の高速化を実現し、AMD* Milan よりも平均で 50% の高速化を実現します。**
ソフトウェア:
- 全世界の開発者の約 90% が、インテルが開発または最適化したソフトウェアの恩恵を受けているか、使用しています。
- oneAPI は、複数のハードウェア・プロバイダーの多様な CPU、GPU、FPGA、AI シリコン上で実証されており、シングルベンダーのアクセラレーション・プログラミング・モデルの課題に対処しています。
- 最新の oneAPI ツールの新機能 (OpenMP* GPU オフロード、OpenMP* と Fortran サポートの拡張、TensorFlow* と PyTorch* フレームワーク、AI ツールの最適化など) は、インテルの最先端の HPC および AI 向け CPU と GPU の能力を解き放ちます。
- ハードウェア・アクセラレーションによるリアルタイムのレイトレースされたサイエンティフィック・ビジュアライゼーションがインテル® GPUで利用可能になり、AI ベースのノイズ除去が数ミリ秒で完了するようになりました。
oneAPI SYCL* 標準実装は、NVIDIA* のネイティブシステム言語のパフォーマンスを上回ることが示されています。例えば、インテル® Xeon® データセンター GPU マックス・シリーズで実行された DPEcho SYCL* コードは、NVIDIA* H100 で実行された同じ CUDA* コードよりも 48% 高速でした。
インテルは、顧客やエンドユーザーが画期的な発見を迅速にできるよう支援する製品で、HPC および AI コミュニティーに貢献します。インテル® Xeon® CPU マックス・シリーズ、インテル® Xeon® データセンター GPU マックス・シリーズ、第 4 世代インテル® Xeon® スケーラブル・プロセッサー、Gaudi* 2 に及ぶ当社の製品ポートフォリオは、さまざまなワークロードで競合製品を凌駕し、優れた電力効率と総所有コスト、AI の大衆化、そして選択肢、オープン性、柔軟性を提供しています。
インテル コーポレーション
スーパーコンピュート・グループ VP 兼 GM
Jeff McVeigh
記事を読む (英語)
** 詳細は、プレスリリース、法務上の注意書き、システム構成を参照してください (英語)
インテル® データセンター GPU フレックス・シリーズがオープン・ソフトウェア・スタックで拡張
2023年5月18日 | インテル® データセンター GPU フレックス・シリーズ向けソフトウェア (英語)
新しいソフトウェア・アップデートにより、クラウドゲーミング、AI 推論、メディア・アクセラレーション、デジタルコンテンツ作成のワークロードを最適化
データセンターおよびインテリジェント・ビジュアル・クラウド向けの柔軟な汎用 GPU として導入されたインテル® データセンター GPU フレックス・シリーズ (英語) が、クラウドゲーミング、AI 推論、メディア・アクセラレーション、デジタルコンテンツ作成などのワークロードを最適化する新しい製品レベルのソフトウェアで拡張されました。この GPU プラットフォームは、oneAPI (英語) により、オープンなフル・ソフトウェア・スタック、ライセンス料不要、CPU と GPU 向け統一プログラミング・モデルで、パフォーマンスと生産性を実現します。
新しいソフトウェア機能の概要
- Windows* クラウドゲーミング: 新しいリファレンス・スタックにより、GPU のパワーをリモートゲームに活用できます。
- AI 推論: スマートシティー、図書館のインデックス作成とコンプライアンス、AI によるビデオ強化、インテリジェント交通管理、スマートビルと工場、小売業に使用されるアプリケーションでディープラーニングと視覚推論を強化します。
- デジタルコンテンツ作成: 専用ハードウェア・アクセラレーションを活用したリアルタイム・レンダリングを実現し、AI ベースのノイズ除去を数ミリ秒で完了します。
- 自律走行: Unreal Engine* 4 を活用して、AD システムのトレーニングや検証を進めることができます。
オープン・ソフトウェア・スタックの構成要素、利用可能なツール、構成済みコンテナを使用した開始方法を学ぶことができます。
詳細 (英語)
新機能と問題の修正を含むインテル® AI アナリティクス・ツールキット 2023.1.1 リリース
2023年5月3日 | インテル® AI アナリティクス・ツールキット (英語)
AI キットの最新リリースは、AI 開発者、データ・サイエンティスト、研究者が、インテル®アーキテクチャー上でエンドツーエンドのデータサイエンスおよびアナリティクス・パイプラインを加速させることを引き続き支援します。
今すぐ入手 (英語)
概要
- インテル® ニューラル・コンプレッサー (英語) は、自動および複数ノードのチューニング戦略と大規模言語モデル (LLM) メモリーを最適化します。
- Modin 向けインテル® ディストリビューション (英語) では、分散型数値計算の基本的なサポートを提供する新しい実験的な NumPy* API を導入しています。
- インテル® アーキテクチャー向け Model Zoo (英語) は、インテル® データセンター GPU マックス・シリーズをサポートし、データセット・ダウンローダーとデータコネクターのサポートを拡張しました。
- TensorFlow* 向けインテル® エクステンション (英語) が TensorFlow* 2.12 をサポートし、Ubuntu* 22.04 と Red Hat* Enterprise Linux* 8.6 をサポート・プラットフォームに追加しました。
- PyTorch* 向けインテル® エクステンションがインテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) 3.1 に対応し、PyTorch* 1.13 のオペレーターカバレッジが改善されました。
詳細は、AI キットのリリースノート (英語) を参照してください。
関連情報
- すぐに使える AI とアナリティクスのサンプルコード (英語)
- AI 開発プロジェクトを飛躍させるための必須ツール (英語)
- インテル® ニューラル・コンプレッサーのチューニング戦略 (https://github.com/intel/neural-compressor/tree/master/docs/source/tuning_strategies.md) (英語) [GitHub*]
- 10 分で Modin を始めるクイックスタート・ガイド (英語)
すぐに使える CPU、GPU、FPGA のサンプルコード
2023年4月20日 | oneAPI と AI のサンプルコード (英語)
インテルが新たに開設した Code Samples ポータルでは、マルチアーキテクチャー・アプリケーションの開発、オフロード、最適化に使用できる、オープンソースの高品質ですぐに使えるコードのコレクションに直接アクセスできます。
各サンプルは、ハイパフォーマンス・コンピューティング、コードとパフォーマンスの最適化、AI とマシンラーニング、科学的または一般的なグラフィックス・レンダリングなど、あらゆるレベルの開発者が並列プログラミング手法をヘテロジニアス・コンピューティングに適応させるための概念と技術を理解できるように、目的に沿って構築されています。
開発者の経験レベルに関係なく、役立つ説明とコメント付きのコードを含むさまざまなサンプルを GitHub* リポジトリーで見つけることができます。
Code Samples ページ (英語) をブックマークに追加してお役立てください。
詳細 (英語)
VMWare とインテルの協業により、インテル® GPU で AV1 エンコード/デコードによるビデオおよびグラフィックスの高速化を実現
2023年4月11日 | インテル® Arc™ グラフィックス、インテル® データセンター GPU フレックス・シリーズ
 圧縮効率とパフォーマンスがさらに向上した次世代のマルチメディア・コーデック
圧縮効率とパフォーマンスがさらに向上した次世代のマルチメディア・コーデック
最新バージョンの VMware Horizon* は、インテル® GPU をサポートし、インテル® oneAPI ビデオ・プロセシング・ライブラリー (インテル® oneVPL) によりメディアを高速化します。インテル® GPU のサポートにより、VMware ユーザーは、単一の GPU ベンダーに縛られることなく、展開するハードウェア・システムの選択肢、柔軟性、およびコストオプションが広がります。インテル® GPU を搭載したシステムで VMware Horizon* を実行する場合、ライセンスサーバーの設定、ライセンス費用、継続的なサポート費用は不要です。
デスクトップおよびサーバー向けのこの VMware Horizon* リリースでは、インテル® Arc™ グラフィックスとインテル® データセンター GPU フレックス・シリーズの両方で、インテル® oneVPL によって最適化された AV1 エンコーディングを利用しています。このソリューションは、サポートされているインテル® Xe アーキテクチャー・ベースおよび最新のインテル® GPU (統合およびディスクリート) で高速ハードウェア・エンコーディングを実現します。GPU 搭載の仮想マシン (VM) により、ユーザーはパフォーマンスの向上、レイテンシーの低減、より安定した FPS、CPU 使用率の低下など、より優れたメディア体験が得られます。
 詳細: http://blogs.vmware.com/euc/2023/04/boost-video-and-graphics-delivery-in-horizon-with-vmware-blast-and-av1-enabled-on-intel-gpus.html
詳細: http://blogs.vmware.com/euc/2023/04/boost-video-and-graphics-delivery-in-horizon-with-vmware-blast-and-av1-enabled-on-intel-gpus.html
@VMWare-@Intel の協業により、インテル® oneVPL を利用して、#インテル® GPU で #AV1 エンコード/デコードのサポートを強化し、ビデオおよびグラフィックスを高速化。詳細: http://bit.ly/3KzlS1B (英語) #Intelsoftware @vmwarehorizon #horizon
インテル® oneAPI 2023.1 リリース
2023年4月4日 | インテル® oneAPI およびインテル® AI ツール (英語)
新しいパフォーマンスとコード移行機能
今回リリースされたインテル® oneAPI 2023.1 は、高帯域幅メモリリー解析、フォトリアリスティックなレイトレーシングとパスガイド、CUDA* から SYCL* へのコード移行サポートの拡張により、最新のインテル® アーキテクチャーの機能を強化します。さらに、マルチアーキテクチャーの SYCL* コードを簡単に記述できる、Codeplay の oneAPI for NVIDIA* GPU (英語) と oneAPI for AMD* GPU (英語) プラグインの最新アップデートも引き続きサポートしています (無料でダウンロードできるこれらのプラグインは、品質の向上、Joint_matrix 拡張と CUDA* 11.8/testing 12 のサポート、AMD* での gfx1032 の有効化を実現し、AMD* プラグインのバックエンドは、ROCm* 5.x ドライバーで動作するようになりました)。
詳細 (英語)
2023.1 の新機能:
コンパイラーと SYCL* サポート
- インテル® oneAPI DPC++/C++ コンパイラーは、BF16 のフルサポート、自動 CPU ディスパッチ、SYCL* カーネル・プロパティーにより AI を高速化し、SYCL* 2020 と OpenMP* 5.0 および 5.1 機能の追加により生産性を改善し、CPU と GPU のパフォーマンスを向上します
- インテル® oneAPI DPC++ ライブラリー (インテル® oneDPL) (英語) は、ソート、スキャン、レデュース・アルゴリズムのパフォーマンスを向上します。
- インテル® DPC++ 互換性ツール (英語) (オープンソースの SYCLomatic プロジェクト・ベース) は、CUDA* ヘッダーの最新リリースをサポートすることで CUDA* から SYCL* へのコード移行を容易にし、より同等の SYCL* 言語と、ランタイム、数学、ニューラル・ネットワーク・ドメインなどの oneAPI ライブラリーのマッピング関数を追加しています。
パフォーマンス・ライブラリー
- インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) は、新しい実数 FFT に加え、1D および 2D の最適化、乱数ジェネレーター、スパース BLAS および LAPACK の逆最適化により、データセンター GPU のパフォーマンスを向上します。
- インテル® MPI ライブラリーは、E-core および P-core を搭載した CPU で GPU バッファーとデフォルトのプロセスピニングを使用して、集合操作のパフォーマンスを向上します。
- インテル® oneAPI スレッディング・ビルディング・ブロック (インテル® oneTBB) は、Linux* でスレッド作成アルゴリズムの堅牢性を向上し、macOS* で Thread Sanitizer を完全にサポートし、フルハイブリッドのインテル® CPU をサポートします。
- インテル® oneAPI データ・アナリティクス・ライブラリー (インテル® oneDAL) は、サイズが 30% 縮小されました。
- インテル® oneAPI コレクティブ・コミュニケーション・ライブラリー (インテル® oneCCL) (英語) は、Alltoall と Allgather の Scaleup アルゴリズムのスケーリング効率を改善し、デバイス (GPU) バッファーのスケールアウト・アルゴリズムの集合選択が追加されています。
- インテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) は、CCM/GCM モードで暗号化のサポートを拡張しています。CCM/GCM モードは、スカラー実装と比較してパフォーマンスが優れている Crypto Multi-Buffer を有効にし、鍵交換プロトコルと暗号化/復号化 API で非対称暗号化アルゴリズム SM2 をサポートします。
解析とデバッグ
- インテル® VTune™ プロファイラー は、インテル® データセンター GPU マックス・シリーズの CPU/GPU の不均衡、スタック間のトラフィック、スループットと帯域幅のボトルネックなど、インテル® Xe リンクのカード間のトラフィックの問題を表示します。
- インテル® ディストリビューションの GDB (英語) は、Windows* 上でインテル® Arc™ GPU のデバッグをサポートし、Linux* 上でインテル® ディスクリート GPU のデバッグ・パフォーマンスを向上します。
レンダリングとビジュアル・コンピューティング
- インテル® オープン・パス・ガイディング・ライブラリー (インテル® オープン PGL) (英語) は、Blender と Chaos V-Ray に統合され、レンダリング向けに最先端のパスガイド・メソッドを提供します。
- インテル® Embree (英語) は、インテル® Arc™ GPU とインテル® データセンター GPU フレックス・シリーズをサポートし、第 4 世代インテル® Xeon® プロセッサー上で Phoronix ベンチマーク (英語) のパフォーマンスを向上します
- インテル® OSPRay Studio (https://www.ospray.org/ospray_studio/) は、オープン Tiny EXR、Tiny DNG (.tiff ファイル)、および Open Image IO の機能を追加します。
oneAPI ツールはエコシステムのイノベーションを推進
oneAPI ツールの採用により、新しいアクセラレーターでのマルチアーキテクチャー・プログラミングが増加しており、エコシステムは、オープンで標準ベースの統一されたプログラミング・モデルを使用した、ユニークなソリューションを急速に開拓しています。以下に最新の例を示します。
- クロスプラットフォーム: パデュー大学 (英語) は、米国で AI と HPC の教育を推進するため、oneAPI 研究拠点を開設しました。
- クラウド: テネシー大学 (英語) は、学生にクラウドベースの Rendering as a Service (RaaS) 学習環境を提供する oneAPI 研究拠点を開設しました。
- AI: Hugging Face は第 4 世代インテル® Xeon® プロセッサー上で PyTorch* Transformers を高速化し (パート 1 (英語) とパート 2 (英語) を参照)、HippoScreen は AI パフォーマンスを 2.4 倍向上 (英語) して効率を高め、ディープラーニング・モデルを構築しました。
- グラフィックスとレイトレーシング: 何千人ものアーティスト、コンテンツ・クリエイター、3D エキスパートが、Blender、Chaos V-Ray、DreamWorks のオープンソース MoonRay (英語) などの一般的なレンダラーに統合されたインテルのレンダリング・ライブラリーを介して、高度なレイトレーシング、ノイズ除去、およびパスガイド機能を簡単に利用できます。
関連情報
- インテル® oneAPI およびインテル® AI ツール (英語)
- SYCL* に関する情報 (英語)
- oneAPI トレーニング・ポータル (英語) – 学習パス、ツール、オンデマンド・トレーニング、作品の共有と紹介など、思い通りの方法で学習できます。
法務上の注意書き
Codeplay はインテルの子会社です。
性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。結果は異なることがあります。
性能の測定結果はシステム構成の日付時点のテストに基づいています。また、現在公開中のすべてのセキュリティー・アップデートが適用されているとは限りません。
絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。実際の費用と結果は異なる場合があります。
インテルのテクノロジーを使用するには、対応したハードウェア、ソフトウェア、またはサービスの有効化が必要となる場合があります。
インテルは、サードパーティーのデータについて管理や監査を行っていません。ほかの情報も参考にして、正確かどうかを評価してください。
パデュー大学、米国における AI & HPC 教育を推進する oneAPI 研究拠点を開設
2023年3月27日 | oneAPI (英語)、インテル® oneAPI ツールキット
ECE カリキュラムに oneAPI マルチアーキテクチャー・プログラミングの概念を組み込む
パデュー大学は、West Lafayette キャンパスに oneAPI 研究拠点を開設し、電気・コンピューター工学部 (ECE) (英語) のカリキュラムで oneAPI を教えることにより、学生の AI や HPC 研究プロジェクトを次のレベルに引き上げます。
教材や認定インストラクター・コースなど、インテルのキュレーション・コンテンツを使用し、学生はインテル® デベロッパー・クラウド (英語) を通じてインテルの最新のハードウェアとソフトウェアにアクセスできます。
「世界を変える研究、プログラム、多様性の文化など、米国で最も革新的な大学の 1 つであるパデューの実績は、oneAPI 拠点に合致するものです。学生が最新の AI ソフトウェアとハードウェアを利用できるようにすることで、次世代の開発者、科学者、エンジニアによる、世界を変えるイノベーションの実現につながるでしょう。私たちは、パデュー大学が高速コンピューティングにおいて大きな飛躍を遂げるのを支援できることを嬉しく思います。
– インテル コーポレーション
デベロッパー・リレーション部門ディレクター
Scott Apeland
詳細 (英語)
|
@LifeAtPurdue パデュー大学は、oneAPI の概念と #インテルのハードウェアとソフトウェアを使って、学生の #AI と #HPC の研究プロジェクトを次のレベルに引き上げるため、#oneAPI 研究拠点を開設します。 詳細: http://bit.ly/3JQTfML (英語) |
最後の 6 つの AI リファレンス・キットをリリース
2023年3月24日 | AI リファレンス・キット (英語)
AI ソリューションを効率化する計 34 種類のキット
データ・サイエンティストや開発者が、より簡単かつ迅速に、インテル® ハードウェア上で最大のパフォーマンスを発揮する革新的なビジネス・ソリューションを開発・展開できるよう、最後の 6 つの AI リファレンス・キットを提供開始しました。
- Visual Process Discovery (視覚処理検出) (英語):
ユーザーが操作したウェブサイトのスクリーンショット (ボタン、リンク、テキスト、画像、見出し、フィールド、ラベル、iframe など) からリアルタイムで UI 要素を検出します。 - Text Data Generation (テキストデータ生成) (英語):
大規模言語モデル (LLM) を用いて、提供されたソース・データセットなどの合成テキストを生成します。 - Image Data Generation (画像データ生成) (英語):
GAN (敵対的生成ネットワーク) を用いて合成画像を生成します。 - Voice Data Generation (音声データ生成) (英語):
VOCODER モデルを用いた転移学習により、入力テキストデータを翻訳して音声を生成します。 - AI Data Protection (AI データ保護) (英語):
データマスキング、データ非識別化、匿名化など、設計・開発段階における PII (個人を特定できる情報) の課題を最小化します。 - Engineering Design Optimization (工学設計の最適化) (英語):
製造エンジニアが製造コストを削減し、製品開発プロセスを短縮しつつ、現実的な設計を行えるように支援します。
AI リファレンス・キットの詳細 (英語)
DreamWorks Animation のオープンソース MoonRay ソフトウェアをインテル® Embree で最適化
2023年3月15日 | インテル® oneAPI レンダリング・ツールキット
オープン・レンダリングのイノベーションを推進
DreamWorks Animation の制作用レンダラーがオープンソースとなり、インテル® oneAPI レンダリング・ツールキットに含まれるハイパフォーマンス・レイトレーシング・ライブラリーのインテル® Embree (英語) によって、フォトリアリスティック・レイトレーシングが高速化されました。
社内のモンテカルロ・レイトレーサーであった MoonRay を、Dreamworks のチームはベータテスターと協力して、社内のパイプライン環境でなくてもビルドして実行できるように、機能拡張を含むコードベースを適合化しました。
「DreamWorks との協力により、このリリースで MoonRay ユーザーは、オープンでハイパフォーマンスなレンダリング・エコシステムのビルディング・ブロックとして、インテル® テクノロジー、インテル® Embree、インテル® oneAPI ツールを利用できます。」
インテル コーポレーション
グラフィックス・リサーチ担当副社長
Anton Kaplanyan
詳細 (英語)
インテル® Embree サンプルコード [GitHub*] (英語)
最新のインテルの GPU と CPU をサポートするインテル® AI アナリティクス・ツールキット 2023.1 リリース
2023年2月10日 | インテル® AI アナリティクス・ツールキット (AI キット) (英語)、 AI リファレンス・キット (英語)
oneAPI によりマルチアーキテクチャー・パフォーマンスを最大化
インテルは、最新の GPU (インテル® データセンター GPU マックス・シリーズおよびインテル® データセンター GPU フレックス・シリーズ) と CPU (第 4 世代インテル® Xeon® スケーラブル・プロセッサーおよびインテル® Xeon® プロセッサー・マックス・シリーズ) の能力を最大限に引き出すように最適化されたツールを含む、AI キットの最新バージョンをリリースしました。
最新のツールキットを使用することで、開発者やデータ・サイエンティストは、特に新しいハードウェア上で、AI ワークロードのエンドツーエンドのトレーニングと推論をより効果的かつ効率的に加速できます。
インテル® AI アナリティクス・ツールキット 2023.1 をダウンロードする
新しいソフトウェア機能とハードウェア・サポート
以下は新機能の一部です。詳細は、リリースノート (英語) を参照してください。
インテル® ニューラル・コンプレッサー (英語)
- 量子化と蒸留により推論とパフォーマンスが改善された DL モデルを構築できます。TensorFlow* 向けインテル® エクステンション 1.1.0、PyTorch* 向けインテル® エクステンション 1.13.0、PyTorch* 1.13、TensorFlow* 2.10 をサポートしています。
- チューニング戦略の調整、スパース性 (ブロックワイズ) を強化するトレーニング、および Neural Coder との統合を可能にします。
インテル® oneDNN (英語)
- インテル® Xeon® プロセッサーでは、高度な機能 (インテル® AMX、インテル® AVX-512、VNNI、bfloat16 など) を有効にして、優れた DL パフォーマンスを提供します。
- データセンター向け GPU では、インテル® XMX で同様の機能を提供します。
インテル® アーキテクチャー向け Model Zoo (英語) [GitHub*]
- 新しい精度 (PyTorch* BERT Large の FF32 と FP16 + インテル® ニューラル・コンプレッサーの INT8 量子化モデル) は、TensorFlow* 画像認識トポロジー (ResNet50、ResNet101、MobileNetv1、Inception v3) をサポートします。
- PyTorch* 向けインテル® オプティマイゼーションと TensorFlow* 向けインテル® エクステンションでインテル® データセンター GPU フレックス・シリーズをサポートします。
TensorFlow* 向けインテル® エクステンション (英語) [GitHub*]
- インテル® データセンター GPU をサポートします。新しいインテル® データセンター GPU マックス・シリーズでの分散トレーニングをサポートする Horovod* 向けインテル® オプティマイゼーション 0.4 を含みます。
- TensorFlow* 2.11 および 2.10 と連携して動作します。
PyTorch* 向けインテル® オプティマイゼーション (英語)
- Windows* ネイティブサポートによる使いやすさ/統合性、インテル® oneDNN 量子化バックエンドによる BF16 と INT8 演算子の最適化により、トレーニングと推論を向上します。
- PyTorch* 向けインテル® エクステンションと併用することで、インテルの新しい CPU と GPUのパフォーマンスを向上できます。
- インテル® oneDNN と TensorFlow* や PyTorch* を含む最適化されたディープラーニング・フレームワークは、データセンター GPU 上でインテル® Xe マトリクス・エクステンション (インテル® XMX) を有効にし、幅広い市場セグメントで競争力のある優れたパフォーマンスを実現します。
- GPU をネイティブにサポートする、TensorFlow* 向けインテル® エクステンションと PyTorch* 向けインテル® エクステンションにより、さらにパフォーマンスを向上できます。
関連情報
- エンタープライズ全体で AI ソリューションを構築、展開、スケーリング (英語)
- インテルの AI とマシンラーニング・ツール (英語)
- 新しい GPU (英語) と CPU (英語) 向けのワークロード・タイプ、インテル® oneAPI ツール、関連リソース
- AI アナリティクスのサンプルコード (英語) [GitHub*]
- PyTorch* 向けインテル® エクステンション (英語) [GitHub*]
- TensorFlow* 向けインテル® エクステンション (英語) [GitHub*]
6 種類の AI リファレンス・キットを新たにリリース
2023年2月10日 | AI リファレンス・キット (英語)
新しい 6 種類の AI リファレンス・キットは、さまざまな業界とアーキテクチャーで AI アクセラレーションを支援
2022年の秋以降、インテルは Accenture と協力して、エネルギー/公益事業、金融サービス、ヘルスサイエンス/ライフサイエンス、小売、半導体、通信など、さまざまな業界向けに AI リファレンス・キットをリリースしています。
今回、新たに 6 つが加わり、その数は約 30 種類になりました。いずれも oneAPI を採用しており、増え続ける AI ワークロードに自由に適用できます。
AI リファレンス・キットの詳細 (英語) とダウンロード (英語)
概要
以下は、インテル® ハードウェア上で AI パフォーマンスを最大限に引き出すように最適化されたフレームワークとインテル® oneAPI のライブラリー、ツール、その他のコンポーネントを含む、AI リファレンス・キットの概要です。
- 交通監視カメラの物体検出 (英語): 交通監視カメラの画像をリアルタイムで分析し、自動車事故のリスクを予測するコンピューター・ビジョン・モデルの開発を支援します。
- 計算流体力学 (英語): 流体プロファイルを計算する方程式を数値的に解くディープラーニング・モデルの開発を支援します。
- AI 構造化データ生成 (英語): 数値、カテゴリー、時系列などの構造化データを合成的に生成するモデルの開発を支援します。
- 構造物被害評価 (英語): 自然災害による被害の深刻度を評価する、衛星画像を用いたコンピューター・ビジョン・モデルの開発を支援します。
- 垂直検索エンジン (英語): 自然言語処理 (NLP) による文書の意味的検索モデルの開発を支援します。
- データ・ストリーミング異常検出 (英語): 機器の状態を監視するセンサーデータの異常を検出するディープラーニング・モデルの開発を支援します。
関連情報
- プレスリリース: インテル、オープンソースの AI リファレンス・キットを発表
- ブログ記事: インテル、オープンソースの AI リファレンス・キットを発表 (英語)
インテルから最新の CPU と GPU がリリースされました!
2023年1月10日 | インテル® oneAPI およびインテル® AI ツール (英語)

本日、インテルは、同社にとって史上最も重要な製品発表の 1 つである、待望の CPU および GPU アーキテクチャーを発表しました。
- 第 4 世代インテル® Xeon® スケーラブル・プロセッサー (開発コード名 Sapphire Rapids)
- インテル® Xeon® CPU マックス・シリーズ (開発コード名 Sapphire Rapids HBM)
- インテル® データセンター GPU マックス・シリーズ (開発コード名 Ponte Vecchio)
これらの機能豊富な製品ファミリーは、oneAPI オープン・ソフトウェア・エコシステムと統合するスケーラブルでバランスのとれた CPU および GPU アーキテクチャーをもたらし、データセンターのパフォーマンス、効率、セキュリティー、そして AI、クラウド、ネットワーク、エクサスケール向けの新しい機能の飛躍的向上を実現します。
単一のコードベースをさらに多くのアーキテクチャにスケーリング
バージョン 2023 のインテル® oneAPI およびインテル® AI ツール (英語) と組み合わせることで、開発者は、新しいハードウェアの高度な機能と内蔵のアクセラレーション機能を完全に活用する、シングルソースでポータブルなコードを作成できます。
- 第 4 世代インテル® Xeon® スケーラブル・プロセッサーとインテル® Xeon® CPU マックス・シリーズは、インテル® アドバンスト・マトリクス・エクステンション (インテル® MMX)、インテル® クイックアシスト・テクノロジー、インテル® データ・ストリーミング・アクセラレーター、インテル® In-Memory Analytics Accelerator を含む命令セットや内蔵アクセラレーターなど、電力とパフォーマンスを効率良く管理するさまざまな機能を提供します。1
- oneDNN、oneDAL、oneCCL などの oneAPI パフォーマンス・ライブラリーを使用して、int8 および bfloat16 データ型のインテル® AMX サポートを有効にします。
- oneAPI を利用してインテル® AMX を活用するように最適化されている、TensorFlow* および PyTorch* AI フレームワークのトレーニングと推論を大幅に向上します。
- インテル® oneAPI ベース・ツールキットおよびインテル® oneAPI HPC ツールキットを使用して、ベクトル化、マルチスレッド、マルチノード並列化、メモリー最適化により、高速でスケーラビリティーに優れた HPC アプリケーションを実現します。
- インテル® oneAPI レンダリング・ツールキットを使用して、最大規模のデータセットでもシステムメモリー空間をすべて活用できる、科学研究、宇宙論、映画などに高忠実度のアプリケーションを提供します。
- 新しい CPU 向けのワークロード・タイプ、oneAPI ツール、関連リソースを見る (英語) >
- インテル® データセンター GPU マックス・シリーズは、物理学、金融、サービス、ライフサイエンスなど、AI や HPC 分野で使用されるデータを多用するコンピューティング・モデルにおいて、画期的なパフォーマンスを発揮するように設計されています。このインテルで最も高性能かつ高密度のディスクリート GPU は、1,000 億個以上のトランジスターと最大 128 個の Xe コアを備えています。
- インテル® Xe マトリクス・エクステンション(インテル® XMX)、ベクトルエンジン、インテル® Xe リンク、データ型の柔軟性など、ハードウェアの革新的な機能を有効にし、oneAPI と AI ツールを使用して最大のパフォーマンスを引き出します。
- コード移行ツールを使用して CUDA* コードを SYCL* に簡単に移行して、新しい GPU や他のベンダーのアーキテクチャーを含む複数のアーキテクチャーに容易に移植できます。
- 新しい GPU 向けのワークロード・タイプ、oneAPI ツール、関連リソースを見る (英語) >
「第 4 世代インテル® Xeon® スケーラブル・プロセッサー、インテル® Xeon® CPU マックス・シリーズ、およびインテル® データセンター GPU マックス・シリーズのリリースは、インテルの再生を促進し、データセンター分野を牽引するための道を再確認し、新しい分野でフットプリントを拡大するために極めて重要です。」
インテル コーポレーション データセンター & AI グループ 執行副社長兼 GM Sandra Rivera
詳細
- インテル® ニュースルームの記事
- 新しいインテル® oneAPI 2023 の各種ツールは、今後発売されるインテル製ハードウェアの価値を最大化 (英語)
- oneAPI の計算ワークロード別に、CPU、GPU、FPGA のメリットを比較する
- [プログラミング・ガイド] インテル® C++ コンパイラー・クラシックからインテル® oneAPI DPC++/C++ コンパイラーへの移行
- [オンデマンド・ウェビナー] インテルの LLVM* ベースのコンパイラーを使用して CPU および GPU でアプリケーションをチューニング (英語)
1インテル® Xeon® CPU マックス・シリーズは、64 ギガバイトの高帯域幅メモリー (HBM2e) を搭載しており、HPC や AI ワークロードのデータ・スループットを大幅に向上します。
2022年
インテル® oneAPI ツールキット 2023 がインテル® デベロッパー・クラウドで利用可能に
2022年12月16日 | インテル® oneAPI ツールキット、インテル® デベロッパー・クラウド (英語)、oneAPI イニシアチブ (英語)
マルチアーキテクチャーに最適化された標準ベースのサポートを提供
インテル® oneAPI ツールキット 2023 の提供が開始され、インテル® デベロッパー・クラウドで利用できるようになりました。
このリリースも、開発者にさまざまなアーキテクチャーで優れたパフォーマンスと生産性を引き続き提供します。また、インテルの最新の CPU/GPU アーキテクチャーと高度な機能に、最適化されたサポートを提供します。
- 第 4 世代インテル® Xeon® スケーラブル・プロセッサーおよびインテル® Xeon® プロセッサー・マックス・シリーズ (開発コード名 Sapphire Rapids)。インテル® アドバンスト・マトリクス・エクステンション (インテル® AMX)、インテル® クイックアシスト・テクノロジー (インテル® QAT)、インテル® AVX-512、bfloat16、その他の機能を搭載。
- インテル® データセンター GPU フレックス・シリーズ (ハードウェア AV1 エンコーダー内蔵) およびインテル® データセンター GPU マックス・シリーズ (開発コード名 Ponte Vecchio)。柔軟なデータ型とインテル® Xe リンク、インテル® Xe マトリクス・エクステンション (インテル® XMX)、ベクトルエンジン、その他の機能を搭載。
- 既存のインテル® CPU、GPU、FPGA。

ハイライト: インテル® oneAPI 2023 の新機能
コンパイラーと SYCL* サポート
- インテル® oneAPI DPC++/C++ コンパイラー CPU と GPU オフロードのパフォーマンスを向上、コードの移植性と生産性を高めるため SYCL* 言語サポートを拡大
- インテル® oneAPI DPC++ ライブラリー (インテル® oneDPL) (英語) は、追加のヒープ・アルゴリズムとソート・アルゴリズムを使用して、SYCL* カーネルにおける C++ 標準ライブラリーのサポートを拡張し、スレッドレベルの並列処理に OpenMP* を使用できるようにします。
- インテル® DPC++ 互換性ツール (英語) オープンソースの SYCLomatic プロジェクトをベースにしており、ランタイム、ドライバー、cuBLAS、cuDNN を含む、CUDA* ライブラリー API の移行を向上
- インテル® Fortran コンパイラーは、Fortran 2018 までのすべての Fortran 言語標準に対応します。Co-Array が実装され、MPI や OpenMP* などの外部 API が不要になり、OpenMP* 5.0 および 5.1 のオフロード機能が拡張され、DO CONCURRENT GPU オフロードが追加され、ソースレベルのデバッグでの最適化が向上します。
パフォーマンス・ライブラリー
- インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) は、BLAS および FFT のライブラリー関数 API の互換性が向上しました。インテル® データセンター GPU マックス・シリーズ (開発コード名 Ponte Vecchio) では、インテル® XMX を活用して、TF32、FP16、BF16、INT8 データ型の行列乗算計算が最適化されます。
- インテル® oneAPI スレッディング・ビルディング・ブロック (インテル® oneTBB) は、parallel_sort の最新の C++ 標準のサポートと使用法を改善、同時に複数の task_arena を呼び出したときの競合を減らすように同期メカニズムを改善、Microsoft* Visual Studio* 2022 および Windows Server* 2022 をサポート
- インテル® oneAPI ビデオ・プロセシング・ライブラリー (インテル® oneVPL) は、インテル® データセンター GPU フレックス・シリーズのハードウェア AV1 コーデックとインテル® Arc™ グラフィックスをサポート、OS のサポートが拡張され新たに RHEL9、CentOS* Stream 9、SLES15Sp4、Rocky 9 Linux* をサポート、sample_multi_transcode の並列エンコーディング機能を追加
解析とデバッグ
- インテル® VTune™ プロファイラーは、アプリケーション・パフォーマンス・スナップショット機能により、MPI のインバランス問題を特定できます。
- インテル® Advisor は、メモリー、キャッシュ、計算のボトルネックを特定して優先度を設定し、原因を理解できるインテル® データセンター GPU マックス・シリーズの自動ルーフライン解析を追加、CPU から GPU へのオフロードのデータ転送再利用コストを最適化する実用的な推奨事項を提供
AI とアナリティクス
- インテル® AI アナリティクス・ツールキット (英語) は、分散トレーニングを除き、Windows* で Linux* と完全に同等でネイティブに実行できるようになりました (GPU のサポートは 2023年第 1 四半期を予定)。
- インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (英語) は、インテル® AMX、インテル® AVX-512、VNNI、bfloat16 を含む、第 4 世代インテル® Xeon® スケーラブル・プロセッサーの高度な機能を有効にすることにより、さらに優れたディープラーニングのパフォーマンスを提供します。
- Modin 向けインテル® ディストリビューション (英語) は、バックエンドで新しいヘテロジニアス・データ・カーネル (HDK) ソリューションと統合して、負荷の低い計算リソースから負荷の高いまたは分散計算リソースまで AI ソリューションを拡張
レンダリングとビジュアル・コンピューティング
- インテル® oneAPI レンダリング・ツールキットには、CPU で高速な SIMD パフォーマンスを実現するインテル® インプリシット SPMD プログラム・コンパイラー・ランタイム・ライブラリーが含まれています。
- インテル® オープン・ボリューム・カーネル・ライブラリー (英語) は、VDB ボリュームのメモリーレイアウト効率が向上し、インテル® AVX-512 の 8-wide の CPU デバイスモードが追加されました。
- インテル® OSPRay (英語) およびインテル® OSPRay Studio (英語) には、メッシュ・ジオメトリー、プリミティブ、オブジェクトのマルチセグメント・デフォメーション・モーション・ブラー機能、メッシュおよびサブディビジョン・ジオメトリーの face-varying 属性、フォトメトリック・ライト・タイプなどの新しいライト機能、AI トレーニング向けのセグメンテーション画像を作成するインスタンス ID バッファーなどが追加されました。
関連情報
- ベンチマーク (英語) >
- 詳細 (英語) >
- インテル® デベロッパー・クラウド・アカウントの作成 (英語) >
- oneAPI ワークロードでの CPU、GPU、FPGA の利点の比較 (英語) >
- SYCL* に関する情報 (英語) >
- oneAPI トレーニング・ポータル (英語) – 学習パス、ツール、オンデマンド・トレーニング、作品の共有と紹介など、思い通りの方法で学習できます。
Codeplay が NVIDIA* GPU および AMD* GPU 向け oneAPI プラグインを発表
2022年12月16日 | Codeplay Software (英語)
![]() マルチアーキテクチャー、マルチベンダー・プログラミングが容易に
マルチアーキテクチャー、マルチベンダー・プログラミングが容易に
本日、Codeplay Software1 は、コンパイラー・プラグインにより NVIDIA* GPU および AMD* GPU 向けの oneAPI サポートを拡大し、開発者がより幅広いプラットフォームとアーキテクチャーをターゲットとできるようにすることを発表しました。
詳細:
- これらのプラグインは、インテル® oneAPI DPC++/C++ コンパイラー 20232 および多くの一般的なライブラリーとシームレスに動作します。
- oneAPI NVIDIA* GPU プラグイン向けに、Codeplay は補完的なエンタープライズ対応の優先サポートを提供しており、開発者は Codeplay のエンジニアなどから直接、迅速な対応を受けることができます。
- Codeplay はさらに、インテル® oneAPI DPC++/C++ コンパイラーで使用できる oneAPI AMD* GPU プラグインのベータ版リリースを提供しています。
詳細 (英語) >
NVIDIA* GPU プラグインをダウンロードする (英語) >
AMD* GPU プラグインをダウンロードする (英語) >
Codeplay の関連情報:
- インテルとともにオープン・スタンダードを拡大 (英語)
- oneAPI でオープン・スタンダードのヘテロジニアス・ソフトウェア・プラットフォームを構築 (英語)
- SYCL* トレーニング・プログラム (英語)
- oneAPI ソリューションと貢献 (英語)
1Codeplay はインテルの子会社です。
2NVIDIA および AMD 向けの oneAPI プラグインは、インテル® oneAPI ベース・ツールキットのコンポーネントであるインテル® oneAPI DPC++/C++ コンパイラー 2023.0 以降のバージョンで使用できます。
oneAPI 仕様 1.2 リリースと oneAPI 運営委員会の新メンバー
2022年11月14日 | oneAPIイニシアチブ (英語)
oneAPI 仕様 1.2 (英語) は、新しい oneDNN グラフ API (英語) を含む oneDNN 仕様の最新のメジャー リリースが含まれており、広範囲のディープ・ニューラル・ネットワーク (DNN) 計算グラフ機能によりパフォーマンスを向上します。
次のような追加機能が含まれます。
- DPC++ (oneAPI のオープンソース SYCL* 実装) の更新と拡張
- oneMKL の機能強化、BLAS ライブラリーに新ルーチンを追加
- oneVPL にカメラの RAW データなどを処理する新しい API を追加
- Level Zero にファブリック・トポロジー検出 API と画像コピーの sRGB サポートを追加
oneAPI コミュニティー・フォーラムの拡大
Codeplay Software 社のエコシステム担当副社長である Rod Burns が率いるこのフォーラムに、以下の新メンバーが運営委員として加わりました。
- アルゴンヌ国立研究所パフォーマンス・エンジニアリング・チーム・リーダー Kevin Harms 氏 (コンピューター・サイエンス修士号取得)
- Google シニア・ソフトウェア・エンジニア Penporn Koanantakool 氏 (コンピューター・サイエンス博士号取得)
- インテル コーポレーション シニア・プリンシパル・エンジニア Robert Cohn (コンピューター・サイエンス博士号取得)
インテル @ Supercomputing 2022 – HPC と AI 向けのオープンな高速コンピューティング
2022年11月9日 | インテル® oneAPI および AI・ツールキット (英語)、oneAPI イニシアチブ (英語)
本日、インテル コーポレーションのスーパーコンピューティング・グループ担当 VP & GM である Jeff McVeigh によって、多くの開発者にとって素晴らしいニュースが発表されました。ここでは、そのハイライトを紹介します。
oneAPI および AI ツール 2023 のリリース
12月に提供されるインテルの oneAPI および AI 2023 ツールは、第 4 世代インテル® Xeon® スケーラブル・プロセッサー、インテル® Xeon® CPU マックス・シリーズ (開発コード名 Sapphire Rapids HBM)、インテル® データセンター GPU マックス・シリーズ (開発コード名 Ponte Vecchio) などの強力な新しいアーキテクチャーを最適にサポートします。
これらの標準ベースのツールは、開発者がマルチアーキテクチャーのパフォーマンスと生産性を実現できるよう、引き続き支援します。HPC および AI の新機能は以下のとおりです。
- HPC と汎用コンピューティング – 一部のツールで OpenMP* 5.1 をサポートし、インテル® oneAPI DPC++/C++ コンパイラーでは SYCL* 言語サポートを強化し、インテル® Fortran コンパイラーではインテルの CPU および GPU で F2003、F2008、F2018 標準を完全に実装しました。
- AI – TensorFlow* および PyTorch* の最適化により、現在および将来のインテルの CPU および GPU でパフォーマンスが向上します。インテル® Neural Compressor の量子化および蒸留機能の拡張により、AI 推論を高速化します。これらの機能は、oneAPI のインテル® AI アナリティクス・ツールキットにバンドルされています。
- コードの移植性 – 強化された CUDA* から SYCL* へのコード移行機能により、マルチアーキテクチャー・システム向けのシングルソース・コードの作成が簡素化されます。
10月28日に開催されたIntel® Innovation (英語) では、その他の拡張機能のプレビューも紹介されました。
7 つの新しい AI リファレンス・キットをリリース
業界主導の AI 向けソリューションを加速するため、インテルは主要なビジネス課題に対応する 7 つの新しい AI リファレンス・キットをリリースしました。これらのキットは、oneAPI を搭載し、インテル®ハードウェア上で AI パフォーマンスを最大化するため、最適化されたフレームワークと oneAPI ライブラリー、ツール、その他のコンポーネントを含んでいます。新しいキットは以下の分野をターゲットとしています。
- ヘルスサイエンスとライフサイエンス – 音声認識 AI
- 小売 – 顧客セグメンテーションによる体験のパーソナライズ、購入予測の自動化、需要予測、注文から配送までの予測
- 金融サービス – ローン不履行リスク予測
- さまざまな業界に共通 – ネットワーク侵入検知
すでにある 9 つのキットにこれらのキットが追加されたことで、合計 16 種類 のキットを利用できるようになりました。インテル (英語) または GitHub* (英語) から今すぐ入手できます。
地震研究に注目した新しい oneAPI 研究拠点
カリフォルニア大学サンディエゴ校のサンディエゴ・スーパーコンピューター・センターと南カリフォルニア地震センターが新たに oneAPI 研究拠点 (英語) に加わりました。これらの研究拠点では、リアルな 3D モデルを用いて断層破壊と地震動のダイナミクスを数値的にシミュレートするという課題に取り組んでいます。oneAPI を使用してオープンソースのシミュレーション・コードである Anelastic Wave Propagation – Olsen, Day, Cui (AWP-ODC) ソフトウェア (英語) を最適化し、高度な HPC システム向けに移植性とパフォーマンスに優れたマルチアーキテクチャー・コードを作成します。
Anelastic Wave Propagation コードは、SCEC コミュニティー、米国科学財団コンソーシアム、科学者や研究者によって、実際の地震災害シミュレーションや研究領域で幅広く使用されています。標準的な「順」解析 (地震現象の記録である 3 成分波形の計算) から、複数ソースの「逆」解析 (対象地点の地震ハザード推定値の計算) まで、さまざまな計算を可能にします。この計算結果は、意思決定者が建築基準を改善し、地震災害に対する地域社会の耐性を高めることによって地震リスクを低減するのに役立つ地盤変動予測を可能にします。
この oneAPI 研究拠点は、世界中にある 28 の研究拠点とともに、研究、コードの最適化および実装、トレーニング・プログラムを通じて oneAPI を加速するため活動していきます。
インテル® oneAPI 2022.3 リリース
2022年10月10日 | インテル® oneAPI および AI・ツールキット (英語)、oneAPI イニシアチブ (英語)
![]() オープンなマルチアーキテクチャーの世界を実現
オープンなマルチアーキテクチャーの世界を実現
インテル® oneAPI ツールキット (英語) とスタンドアロン・ツールの最新のアップデートがリリースされました。パッケージをダウンロードすることも、インテル® DevCloud for oneAPI (英語) で利用することもできます。今回のリリースには 30 以上のツールが含まれており、それぞれがデータセントリックなワークロード向けにパフォーマンスの向上と機能の拡張をもたらすように最適化されています。
インテル® oneAPI ツールキットは、クロスアーキテクチャーでヘテロジニアスなコンピューティングを最適化および高速化することを目的に構築されており、開発者にパフォーマンスや機能を犠牲にすることなく、オープンな選択肢を提供します。
SYCL*、C++、C、Python*、Fortran、MPI、OpenMP* などの業界標準を実装するコンパイラー、言語、ライブラリー、解析およびデバッグツールに加えて、最適化された AI フレームワークと Python* ライブラリーを提供します。
2022.3 の新機能:
コンパイラー
- インテル® oneAPI DPC++/C++ コンパイラー (英語) では、GPU や FPGA などのさまざまなハードウェア・アクセラレーターでプログラミングの生産性を向上させる SYCL 2020 機能が追加され、OpenMP 5.x への準拠が強化されました。
- インテル® Fortran コンパイラー (英語) では、Fortran 2008 および 2018 の Co-Array、DLLImport/DLLExport、DO CONCURRENT オフロードのサポート、-int および追加の -check コンパイラー・オプションが追加されました。
CUDA* から SYCL* への移行
- インテル® DPC++ 互換性ツール (英語) では、CUDA* 11.7 ヘッダーファイルと CUDA* ランタイムおよびドライバー API (cuDNN、NCCL、Thrust、cuBLAS および cuFFT) がサポートされ、より完全な CUDA* から SYCL* へのコードの移行をサポートします。
- SYCLomatic Project (英語) は、オープンソース版の互換性ツールを提供することで、インテルによるオープン・コンピューティングのサポートを拡大し、コミュニティーによる SYCL* 標準の採用を促進します。
パフォーマンス・ライブラリー
- インテル® oneAPI マス・カーネル・ライブラリー (英語) では、BLAS GPU デバイスタイミングがサポートされ、例外の検出と回復をより迅速かつ容易に行えるようにしました。また、OpenMP* クラスターオフロード機能の拡張により、LAPACK で OpenMP* 5.1 仕様がサポートされ、移植性と互換性が向上しました。
- インテル® oneAPI DPC++ ライブラリー (英語) では、SYCL* カーネルの C++ 標準ライブラリーのサポートが拡張され、9 つのヒープおよびソート・アルゴリズムが追加され、一般的な関数のコーディングが簡素化されました。
- インテル® oneAPI ビデオ・プロセシング・ライブラリー (英語) は、エンコードされた内容に関する広範なデータを提供する機能を備えており、品質向上とアルゴリズム革新の機会を提供します。
解析およびデバッグツール
- インテル® VTune™ プロファイラー (英語)、インテル® Advisor, (英語)、インテル® Inspector (英語) では、機能やセキュリティー・アップデートなどを含む、サードパーティー・コンポーネントの最新バージョンが含まれました。
- インテル® ディストリビューションの GDB (英語) では、GPU 側のデバッグをシームレスに行うため、使いやすさと安定性が向上しました。
- インテル® Cluster Checker (英語) では、要求の厳しい分散型 HPC 環境向けの IBM Spectrum LSF* ワークロード管理プラットフォームがサポートされました。
AI とアナリティクス
- PyTorch* 向けインテル® エクステンション (英語) が 1.12.100 にアップデートされ、INT8 の自動量子化機能が追加され、幅広いワークロードでパフォーマンスが向上するように操作とグラフの機能が強化されました。
- TensorFlow* 向けインテル® オプティマイゼーション (英語) が TensorFlow* 2.9.1 にアップデートされ、bfloat16 モデルのパフォーマンスが向上し、Linux* ベースの開発コード名 Cascade Lake 以降の CPU でインテル® oneDNN の最適化を有効にするコンパイラー要件が削除されました。
- インテル® Neural Compressor (英語) では、生産性を向上するバイナリーサイズの軽量化、新しい量子化精度機能、実験的な自動コーディングのサポートに加えて、TensorFlow* 量子化 API のサポート、ITEX の QDQ 量子化、混合精度の強化、DyNAS、ブロック単位の構造スパース性のトレーニング、op タイプ単位のチューニング戦略などが追加されています。
レンダリングとレイトレーシング
- インテル® オープン・ボリューム・カーネル・ライブラリー (英語) では、パフォーマンスとメモリー効率が向上し、VDB ボリューム (一時定数ボリュームのパックド/連続データレイアウト) とインテル® AVX-512 の 8-wide の CPU デバイスモードがサポートされました。
- インテル® OSPRay (英語) では、フレームバッファーのチャネルとしてプリミティブ、オブジェクト、インスタンス ID バッファーがサポートされ、メッシュおよびサブディビジョンのジオメトリーで face-varying 属性がサポートされました。
- インテル® Embree (英語) では、インテル® oneAPI DPC++/C++ コンパイラーがサポートされました。
oneAPI トレーニング・ポータル (英語) – 学習パス、ツール、オンデマンド・トレーニング、作品の共有と紹介など、思い通りの方法で学習できます。
oneAPI イニシアチブがオープン・アクセラレーテッド・コンピューティングのコミュニティー・フォーラムに拡大
2022年9月28日 | oneAPI イニシアチブと仕様 (英語)
 oneAPI は、開発者、ソフトウェア・ベンダー、国立研究所、研究者、シリコンベンダーの進化するニーズに対応するため、コミュニティー・フォーラムに移行しています。
oneAPI は、開発者、ソフトウェア・ベンダー、国立研究所、研究者、シリコンベンダーの進化するニーズに対応するため、コミュニティー・フォーラムに移行しています。
これは、複数のアーキテクチャーやベンダーにまたがる oneAPI (英語) の採用や実装で得られた進歩を将来に活かすためです。
オープンスタンダードを推進し、SYCL* 開発と oneAPI 実装でクロスプラットフォームの経験がある Codeplay が、oneAPI 開発者コミュニティーの成長と調整を目的としたフォーラムの設立を主導します。
メリット
フォーラムは、コミュニティーの参加を促し、oneAPI の継続的な進化を導いて、より多くのクロスアーキテクチャー、マルチベンダーの実装、および迅速な採用を可能にするでしょう。
Codeplay は、コミュニティーと協力して、次の四半期に移行の詳細を提供する予定です。
詳細
- oneAPI コミュニティーに参加し、コラボレーションに参加する (英語)
- 詳しくは、ブログを参照してください。
oneAPI がコミュニティー・フォーラムに拡大 (インテル コーポレーション バイスプレジデント Sanjiv Shah のブログ)
http://simplecore.intel.com/oneapi-io/blog/oneapi-expands-to-a-community-forum-for-open-accelerated-computing
オープン・スタンダード、オープンソースのヘテロジニアス・ソフトウェア・プラットフォームの構築 (Codeplay Software バイスプレジデント Rod Burns のブログ) (英語)
インテル® oneAPI 2023 のプレビュー
2022年9月28日 | インテル® oneAPI ツールキット
![]() 12月にリリース予定の新機能について
12月にリリース予定の新機能について
冬が近づいています。インテル® oneAPI ツール (ツールキットおよびスタンドアロン・ツール) が進化し、CPU、GPU、FPGA など、複数のアーキテクチャーで動作するアプリケーションやソリューションを開発者が継続的に提供できるように、改良と最適化が施されたバージョンが間もなくリリースされる予定です。
バージョン 2023 では、標準ベースの開発製品が強化され、以下のような最新および将来のアーキテクチャー (単独または組み合わせ) 向けに最適化されています。
- 第 4 世代インテル® Xeon® スケーラブル・プロセッサー
- インテル® Data Center GPU (開発コード名 Ponte Vecchio)
- インテル® Data Center GPU フレックス・シリーズ
- インテル® Arc™ グラフィックス
- インテル® Agilex™ FPGA
主な機能:
- HPC と一般的な計算処理 – CUDA* から SYCL* へのコード移行機能の強化により、マルチアーキテクチャー・システム向けのハイパフォーマンスなシングル・ソースコードを容易に作成できます。インテル® oneAPI DPC++/C++ コンパイラーでは SYCL* 言語サポートが強化され、インテル® Fortran コンパイラーではインテルの CPU および GPU で F2003、F2008、F2018 標準が完全に実装されました。
- 人工知能 (AI) – TensorFlow* と PyTorch* は、第 4 世代インテル® Xeon® スケーラブル・プロセッサーと開発コード Ponte Vecchio 向けに最適化されています。インテル® Neural Compressor の量子化および蒸留機能の拡張により、より高速な AI 推論を実現します。これらの機能は、oneAPI のインテル® AI アナリティクス・ツールキットにバンドルされています。
これらのツールは、12月にリリースされる予定です。
6 つの新しい oneAPI 研究拠点
2022年9月28日 | 研究拠点 (英語)
新たに 6 つの oneAPI 研究拠点が oneAPI コミュニティーに加わりました。これらの研究拠点は、主要なソフトウェア・コードの最適化、新しい実装の作成、戦略的アプリケーションの oneAPI への移行、oneAPI の採用を促進し拡大するための新しいカリキュラムの開発と幅広い共有によって、マルチアーキテクチャー・システム上での oneAPI 開発を促進します。
新しい 6 つの oneAPI 研究拠点:
- 英国科学技術振興機構は、SYCL* 標準と oneAPI を使用したマルチアーキテクチャー・システムにおけるエクサスケール・ソフトウェア開発を加速します。特に、MUI (Multiscale Universal Interface) と呼ばれる C++ カップリング・ライブラリーと Xcompact3d と呼ばれる高忠実度の数値流体力学コードの、2 つの有名オープンソース HPC ソフトウェア・コードの最適化に取り組んでいます。この 2 つのコードは、英国の ExCALIBUR エクサスケール・プログラムに不可欠なもので、将来のエクサスケール・コンピューティングの開発にも採用されており、1 秒間に 1 兆回以上の計算を処理できる高速な計算プラットフォームを提供します。
- 北京大学ソフトウェア・マイクロエレクトロニクス学部 (http://ss.pku.edu.cn/en/?view=featured) は、中国の大学で oneAPI の採用を促進し拡大するため、新しい現地語カリキュラムの開発、授業、幅広い共有を含む oneAPI プログラミングの教育および実用化に取り組んでいます。
- テクニオン・イスラエル工科大学 (https://www.technion.ac.il/en/home-2/) は、oneAPI とインテル® Developer Cloud (英語) を使用して、CPU、GPU、その他のアクセラレーター上での現代科学計算の研究を促進しています。oneAPI と OpenMP* を使用した上級コースは、他の大学にも拡大される予定です。また、学部のプロジェクトでは、oneAPI を利用してオープンソースの HPC および AI アプリケーションを OpenMP*/SYCL* に移行し、パフォーマンスの最適化に取り組む予定です。
詳細: http://www.technion.ac.il/en/2022/09/intel-oneapi-center-of-excellence-at-the-technion/ - カリフォルニア大学サンディエゴ校 (英語) は、同校のスーパーコンピューター・センターにおいて、oneAPI (英語) を利用して、CPU とアクセラレーターを使って Amber で高性能分子動力学シミュレーションを行う予定です。
- ユタ大学は、ローレンス・リバモア国立研究所と共同で、エクサスケール・コンピューティングを推進するため、複数のアーキテクチャー上で oneAPI を使用して ZFP圧縮ソフトウェア (英語) を高速化し、可搬性と移植性に優れた、ハイパフォーマンスなデータ圧縮技術の開発に取り組んでいます。
- ベルリン・コンラート=ツーゼ情報技術センター (ZIB) は、oneAPI を使用して、GPU と FPGA に可搬性の高い実装を提供することで、電力効率の良い HPC コンピューティングを実現しています。
現在までに、28 の oneAPI 研究拠点が、世界中で oneAPI のオープンで高速な計算の採用を推進しています。
詳細: oneAPI 研究拠点 (英語)
新たに 3 つの AI リファレンス・キットをリリース
2022年9月28日 | AI リファレンス・キット (英語)
重要なビジネス課題を解決
7月にリリースされた AI SW リファレンス・キット (Accenture との共同開発) をベースにした、oneAPI の 3 つの新しい AI アプリケーション・リファレンス・キット (英語) がリリースされました。ヘルスケア向けのこれらのキットは、臨床医の疾病予測、医療画像診断、文書自動化を支援します。インテル (英語) または GitHub* (英語) からダウンロードできます。
今後も、2023年まで継続的に新しい AI リファレンス・キットがリリースされる予定です。
Red Hat との共同ソリューションで AI を加速、新たなデータサイエンス開発者向けプログラムを開始
2022年9月28日
12月にリリース予定の新機能について
![]() インテルと Red Hat は、インテルの AI ハードウェアおよびソフトウェア・ポートフォリオと、データ・サイエンティストと開発者が協力してインテリジェントなアプリケーションを作成、テスト、構築できる AI プラットフォーム「Red Hat OpenShift Data Science (RHODS)」を組み合わせた新しい共同ソリューションを発表しました。
インテルと Red Hat は、インテルの AI ハードウェアおよびソフトウェア・ポートフォリオと、データ・サイエンティストと開発者が協力してインテリジェントなアプリケーションを作成、テスト、構築できる AI プラットフォーム「Red Hat OpenShift Data Science (RHODS)」を組み合わせた新しい共同ソリューションを発表しました。
このソリューションにより、開発者は oneAPI のインテル® AI アナリティクス・ツールキット (英語) と OpenVINO™ ツール (英語) を使用してモデルのトレーニングおよびデプロイを行うことができます。
Red Hat は、Habana* Gaudi* トレーニング・アクセラレーターを同社のサービスで利用できるようにし、コスト効率に優れた、ハイパフォーマンスなディープラーニング・モデルのトレーニングおよびデプロイを実現する取り組みも行っています。さらに、インテルと Red Hat の共同 AI 開発者プログラム (英語) により、開発者は RHODS サンドボックスとインテル® Developer Cloud (英語) の両方から直接 AI ソフトウェアを学習、テスト、デプロイできるようになります。
詳細: インテルと Red Hat の開発者向けリソース (英語) | インテル® AI アナリティクス・ツールキットで OpenShift Data Science を高速化 (英語)
期間限定: 新しいインテルのテクノロジーへのベータアクセスを受付開始
2022年9月27日 | インテル® Developer Cloud (英語)
![]() 拡張されたインテル® Developer Cloud では、新しいテクノロジーがクリックひとつで利用できます。
拡張されたインテル® Developer Cloud では、新しいテクノロジーがクリックひとつで利用できます。
Intel® Innovation (英語) の基調講演でインテル コーポレーションの CEO である Pat Gelsinger が述べたように、新しく拡張されたインテル® Developer Cloud への期間限定のベータトライアルが開始されました
アクセスが許可されると、インテルの強化されたクラウドベースのサービス・プラットフォームで、リリースの数カ月から 1年前にインテルのテクノロジーにアクセスし、テストし、評価できます。
ベータトライアルには、以下のような最新のインテルの計算プラットフォームとアクセラレーター・プラットフォームが含まれます。
- 第 4 世代インテル® Xeon® スケーラブル・プロセッサー (開発コード名 Sapphire Rapids)
- 高帯域幅メモリー (HBM) 搭載第 4 世代インテル® Xeon® プロセッサー
- インテル® Data Center GPU (開発コード名 Ponte Vecchio)
- インテル® Data Center GPU フレックス・シリーズ
- Habana* Gaudi*2 ディープラーニング・アクセラレーター
ベータトライアルには、登録と事前審査が必要です。
詳細: cloud.intel.com (英語)
インテルが TensorFlow* の公式ビルド・コラボレーターに
2022年9月21日 | pip での TensorFlow* のインストール
 インテルは、Google と正式に提携し、TensorFlow* 2.10 から TensorFlow* Windows* Native CPU ビルドの開発およびリリースを担当することになりました。この Google との密接な協力関係は、Windows* プラットフォームで TensorFlow* 開発者に最適な体験を提供するというインテルのコミットメントを示しています。
インテルは、Google と正式に提携し、TensorFlow* 2.10 から TensorFlow* Windows* Native CPU ビルドの開発およびリリースを担当することになりました。この Google との密接な協力関係は、Windows* プラットフォームで TensorFlow* 開発者に最適な体験を提供するというインテルのコミットメントを示しています。
Tencent が oneAPI ツールにより最大 85% のパフォーマンス向上を達成
2022年9月12日 | インテル® oneAPI DPC++/C++ コンパイラー、Intel® VTune™ プロファイラー
MySQL を最適化した Tencent の結果は、インテル® oneAPI DPC++/C++ コンパイラーなどの最新の [インテル® oneAPI] 開発ツールとインテル® VTune™ プロファイラーによる最新の最適化手法の両方の重要性を実証しています。パフォーマンスの大幅な向上により、ビジネス・クリティカルなアプリケーションでは、結果を得るまでの時間の短縮、あるいはより多くの結果を得ることが可能です。
Tencentは、データベース・ホスティング・サービスである TencentDB for MySQL (英語) のパフォーマンスを大幅に向上させました。オープンソースのリレーショナル・データベース管理システム MySQL をベースに、インテル® Xeon® プロセッサーで構築し、高度なインテル® oneAPI DPC++/C++ コンパイラーとインテル® VTune™ プロファイラー (インテル® oneAPI ベース・ツールキットに含まれる) を使用することでパフォーマンスの向上を実現しました。
これが重要な理由
分散データストレージは、インターネット、金融、電子商取引などの業界やユースケースにおいて重要な役割を果たします。TencentDB for MySQL のようなソリューションは、開発者に分散データストレージのサービスを提供し、クラウドでリレーショナル・データベースを簡単にセットアップ、運用、拡張できるようにサポートします。
レンダリングから HPC まで、インテル® oneAPI ツールがオープンソース・ソリューションを最適化
2022年9月8日 | インテル® oneAPI ベース・ツールキット、インテル® oneAPI HPC ツールキット、インテル® oneAPI レンダリング・ツールキット
2 つの人気があるパワフルなアプリケーション、Blender 3.3 と Radioss (オープンソース版 OpenRadioss を利用可能) が、非常に異なる (そして非常に重要な) oneAPI ツールと機能によって最適化されました。
Blender Cycles がインテル® ディスクリート GPU を完全にサポート
Blender 3.3 (英語) から、Cycles レンダリング・エンジンに、インテル® Arc™ A シリーズ・ディスクリート・グラフィックスとインテル® Data Center GPU フレックス・シリーズをサポートするレンダリング・デバイス API として oneAPI が含まれました。この新しいサポートは、マルチベンダーの CPU と GPU コード開発を提供する、オープンで標準ベースの言語である The Khronos Group の SYCL* を実装しています。これは、Blender のクリエイターとユーザーを、特定の独自アーキテクチャーとプログラミングから解放することを目的とした、進化的な開発アプローチの第一歩となります。
Cycles は Blender のレイトレーシング・レンダラーで、複雑なパストレーシング・シーン、ジオメトリー・ノート、間接照明、最終フレーム用の高密度ジオメトリーを備えています。長年にわたり、インテルは、開発コンサルティング、高度なレイトレーシング機能の統合、トレーニングなど、Blender に貢献してきました。アカデミー賞を受賞した (英語) 3D レイトレーシング・カーネル・ライブラリーであるインテル® Embree は、数年前に Blender に統合され、高忠実度のフォトリアリズムを実現し、多くの映画やプロジェクトをサポートしています。2019年にはインテル® Open Image Denoise が追加され、アーティストやスタジオがより短時間で最終フレームの画質を実現できるようになりました。
Altair が OpenRadioss を発表
「Altair が OpenRadioss をオープンソース・コミュニティーに提供したことで、衝突シミュレーションなどの構造解析における重要な問題の解決を目指す開発者が、オープンソース開発のメリットを享受できるようになりました。オープンソース開発に対するインテルのコミットメントは、ハイパフォーマンス・ハードウェアの価値を生産的に最大化するのに役立つ、オープンソースの oneAPI コンパイラー、ライブラリー、開発ツールを用いた Altair との協業にも反映されています。」
Altair は、複雑な設計の耐衝撃性、安全性、および製造可能性を高める最先端の解析ソリューション Radioss (英語) を、OpenRadioss としてオープンソース化しました。Altair のエンジニアは、インテル® oneAPI ベース & HPC ツールキットに含まれる複数のツールを使用して、ソフトウェアの最適化を行いました。
インテリジェント・ビジュアル・クラウド向けの新しいインテル® Data Center GPU フレックス・シリーズがオープン・ソフトウェア・スタックを採用
2022年8月24日 | インテル® oneVPL (英語) | インテル® VTune™ プロファイラー
本日発表されたインテル® Data Center GPU フレックス・シリーズは、汎用性の高いシームレスなハードウェアとオープンなソフトウェア・ソリューション・スタックを備え、インテリジェントなビジュアル・クラウド・ワークロードに必要な柔軟性とパフォーマンスを提供します。
主な機能:
- 競合ソリューションの半分の消費電力で、5 倍のメディア・トランスコード・スループットと 2 倍のデコード・スループットを実現1
- 帯域幅を 30% 以上向上し、総所有コスト (TCO) を大幅に軽減
- 一般的なメディアツール、API、フレームワーク、および最新のコーデックを幅広くサポート
インテル® フレックス・シリーズ GPU は、メディア配信、クラウドゲーミング、AI、メタバースなど、幅広いワークロードに柔軟に対応し、パフォーマンスや品質を損なうことなく、TCO を軽減/最適化するように設計されています。この GPU は、ユーザーをサイロ化された独自環境の制約から解放し、データセンターが個別の専用ソリューションを使用する必要性を低減します。

開発者は、オープンソースのコンポーネントとツールを組み合わせた包括的なソフトウェア・スタックを利用して、ビジュアル・クラウド・ワークロード向けのインテル® フレックス・シリーズ GPU の機能を効果的に実現できます。インテル® oneAPI ツールは、インテル® oneVPL (英語)、インテル® VTune™ プロファイラーなど、高速化されたアプリケーションとサービスを提供する開発者向けのツールです。
簡単にダウンロードできるソフトウェア・パッケージの詳細については、近日公開予定です。
詳細: インテル ニュースルーム | インテル® フレックス・シリーズ GPU
インテルのハードウェアと高度なレイトレーシングにより 3D アーティストの映像に生命を吹き込む
2022年8月16日 | インテル® Open VKL (英語)、インテル® oneAPI レンダリング・ツールキット
インテル® Advanced Ray Tracing とインテル® Core™ モバイル・プロセッサー HX シリーズは、プロフェッショナルなワークフローと素晴らしいコンテンツ制作のためのハイパフォーマンスを提供します。
インテルは最近、RenderMan* 向けのインテル® Open VKL プラグイン (英語) をリリースしました。このプラグインは、VFX およびアニメーション向けの世界で最も汎用性の高いレンダラーである Pixar Animation の RenderMan* と連携し、インテル® オープン・ボリューム・カーネル・ライブラリーを利用して、最終フレームのボリューム・レンダリングのパフォーマンスを大幅に向上させることが可能です。
Renderman*、インテル® Open VKL、第 12 世代インテル® Core™ HX プロセッサーの強力な組み合わせにより、Fabio Sciedlarczyk (http://fabio_scied.artstation.com/) などのアーティストは、火、水、空気、雲、煙など、計算量の多いボリュメトリック・コンテンツをより迅速にレンダリングできるようになり、視覚的に魅力的なストーリーの制作により多くの時間を割くことが可能になりました。このビデオでは、Sciedlarczyk 氏がこれらのツールを使って、素晴らしいフォトリアリスティックなビジュアルを構築し、パフォーマンスを犠牲にすることなく、モバイル・ワークステーションでコンパイル時間を劇的に短縮しながら、外出先でもそれらを作成する様子をご覧いただけます。
「最近では、利用可能なツールを使用することで、コンピューター・グラフィックスがほとんど制約のないメディアになりつつあります。」そしてインテルは、可能性の限界を押し広げ続けているのです。
このオープンソース・プラグインは、GitHub* (英語) で無料公開されており、ソフトウェア・エコシステム全体でコンテンツ・クリエイターや開発者によるイノベーションと幅広い採用を促進するという、インテルのオープン・ソフトウェア戦略に沿ったものとなっています。インテル® Open VKLは、インテル® oneAPI レンダリングツール・キットに含まれます。
関連情報
- インテル® Advanced Ray Tracing による驚異的な Hi-Fi グラフィックスの展開 (英語)
- 世界最高のモバイル・ワークステーション・プラットフォーム、第 12 世代インテル® Core™ HX プロセッサー発売 [プレスリリース] (英語)
- 技術トーク: 第 12 世代インテル® Core™ HX モバイル・プロセッサー [動画 – 13:46] (英語)
インテルと Aible が AI を実現するため提携
2022年8月9日 | Aible (英語)、インテル® AI アナリティクス・ツールキット (英語)
インテル® Xeon® スケーラブル・プロセッサーは、ソフトウェアの最適化とともに、30 日以内にビジネス成果を実現します。
インテルは、クラウドベースの AI/ML プラットフォーム・ソリューション・プロバイダーである Aible との協業により、データセンター・ベースの AI アプリケーションおよびイニシアチブを、複雑性を増すことなく、より迅速に、より優れた TCO で提供できます。
AI を加速するインテル® Xeon® スケーラブル・プロセッサーと AI に最適化されたツール (インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) + インテル® AI アナリティクス・ツールキットのほかのツール) と組み合わせることで、Aible のテクノロジーは、ほかのサーバー指向ソリューションよりも速くマシンラーニング・モジュールをトレーニングするサーバーレス・ファーストアプローチを提供できます。
詳細とベンチマーク (英語) >
ケーススタディー (英語) >
インテル® Advanced Ray Tracing による驚異的な Hi-Fi グラフィックスの展開
2022年8月8日 | [NEW!] インテル® Arc™ Pro A シリーズ・グラフィックス、インテル® Open VKL プラグインplugin for RenderMan* (英語)、インテル® Open Path Guiding Library (英語)、SIGGRAPH 2022 (英語)
新たに発表されたインテル ® Arc™ Pro GPU、インテル® Open VKL Plugin for Renderman*、およびインテル® Open Path Guiding Library
 |
SIGGRAPH 2022 に合わせて、インテルは高忠実度グラフィックスを高速化する新しい GPU ハードウェアおよびソフトウェア・テクノロジーを発表しました。これらのイノベーションは、コンシューマー向けからハイエンドノート PC、ワークステーション、データセンター/レンダーファーム、クラウド、そして世界最大のスーパーコンピューターまで、パフォーマンスをスケーリングするオープンなエンドツーエンドのプラットフォーム規模のソリューションを提供するというインテルのミッションの次のステップを示しています。 |
概要
プロフェッショナル向けのインテル® Arc™ Pro A シリーズ GPU は、内蔵のレイトレーシング・ハードウェア、業界初の AV1 ハードウェア・エンコーディング・アクセラレーション、およびマシンラーニング機能を搭載しています。
詳細 (英語) >
新しいインテル® Advanced Ray Tracing テクノロジーは、洗練されたレイトレーシング、ビジュアル・コンピューティング、高忠実度、ビジュアライゼーションを可能にします。
- インテル® Open VKL plugin for Renderman* (英語) は、最終フレームのボリューム・レンダリングを大幅に改善します。
- インテル® Open Path Guiding Library (英語) は、最先端のパスガイド手法をレンダラーに簡単に統合できる業界初のオープンソース・ライブラリーです。
標準ベースのソリューションにおけるグローバルリーダーとの異業種コラボレーションにより、グラフィックス・イノベーションを継続的に進めています。
- DreamWorks Animation は、MCRT レンダラー「MoonRay*」をオープンソース・ソフトウェアとして今年後半にリリースする計画を発表しました。このレンダラーの写実的なレイトレーシングは、インテル® oneAPI レンダリング・ツールキット (レンダリング・キット) の 2 つのオープンソース・ツールによってサポートされています。インテル® Embree レイトレーシング・カーネル・ライブラリーは高度なレンダリング機能を、インテル® Implicit SPMD Program Compiler (インテル® ISPC) はベクトル命令の並列化を提供します。
- Blender* 3.3 (英語) のベータ版が公開され、oneAPI プログラミングにより、インテル® Arc™ GPU および今後発売予定のインテル® データセンター GPU において、Linux* および Windows* で 1 つのコードベースをサポートすることが可能になりました。
- インテルは、Unity* アセット・パブリッシャーである Procedural Worlds 社と共同で、インテル® Game Dev AI Toolkit with Gaia ML (for Unity*) (英語) を開発しました。これにより、開発者はマシンラーニング機能をゲーム体験に導入できます。
- Foundry の Modo* 16.0 (英語) リリースは、次期インテル® Arc™ GPUのリアルタイム・ビューポートに新たなサポートを追加します。
SIGGRAPH 2022 に参加される皆さん
インテルのブース (#427) (英語) では、発表されたばかりのインテル® Arc™ Pro グラフィックス上で動作する Topaz や SketchUp、インテルの GPU と CPU 上で Render Kit によって最適化された SideFX、Blender、RenderMan など、革新的な使用方法を紹介するデモをご覧いただけます。
関連情報
- Intel Newsroom (英語)
- インテル® Advanced Ray Tracing による驚異的な Hi-Fi グラフィックスの展開 (英語)
- オープン・パスガイド・レンダリングが容易に (英語)
インテルが開発を簡素化するオープンソースの AI リファレンス・キットをリリース
2022年7月12日 | インテル® AI 開発ツール (英語)
インテルは、オンプレミス、クラウド、エッジ環境において AI をより利用しやすくするため特別に設計された、オープンソースの AI リファレンス・キットを新たにリリースしました。
インテル® Vision (英語) で発表されたこれらのキットには、AI モデルコード、トレーニング・データ、エンドツーエンドのマシンラーニング・パイプライン命令、ライブラリー、クロスアーキテクチャー・パフォーマンス向けのインテル® oneAPI コンポーネントが含まれています。
現時点では、以下のキットを利用できます。
- Utility Asset Health (英語) – ユーティリティーがより高いサービス信頼性を提供できるようにトレーニングされた予測分析モデルです。
- Visual Quality Control (英語) – 製薬などのライフサイエンス分野の VQ 管理検査を自動化し、錠剤の品質向上と運用コスト低減に貢献します。
- Customer Chatbot for the Enterprise (英語) – Airline Travel Information Systems データセットからの 4,000 以上の発話を使用してトレーニングされ、94% の予測精度を提供する会話型 AI チャットボット・モデルです。
- Intelligent Document Indexing (英語) – 高速なルーティングと手作業によるコスト削減により、数百万件のドキュメントの処理と分類を自動化します。
イノベーションはオープンで大衆化された環境で成長し、インテルの AI ツールとフレームワークの最適化は、オープンで標準ベースの統一された oneAPI プログラミング・モデルの基盤の上に構築されています。Project Apollo リファレンス・キットは、インテルのエンドツーエンドの AI ソフトウェア・ポートフォリオのコンポーネントで構築されており、何百万人もの開発者やデータ・サイエンティストが、アプリケーションに AI を迅速かつ容易に導入したり、既存の AI/ML 実装を強化できるようにします。これにより、さまざまなユースケースや産業にわたる幅広いインテリジェント・ソリューションの実現が可能になります。
インテル コーポレーション
バイスプレジデント兼 AI アナリティクス事業本部長
Wei Li 氏
無料のソフトウェアをダウンロードする (英語)
インテルと Google Cloud* が HPC ワークロード向けのすぐに使える最適化ソリューションを提供
2022年7月6日 | インテル® oneAPI ベース・ツールキット、インテル® oneAPI HPC ツールキット
インテルと Google は協力して、Google Cloud* 上でハイパフォーマンス・コンピューティングを推進する Cloud HPC Toolkit (英語) をリリースしました。この新しいリソースは、インテル® MPI ライブラリーとインテル® oneAPI マス・カーネル・ライブラリーを含むインテル® oneAPI ベース & HPC ツールキットの各種ツールへのアクセスを提供し、インテル® Select ソリューション for シミュレーション & モデリングによりパフォーマンスを最適化します。これらの新しいツールは、コンパイル時間と結果の速度を向上させ、SYCL* でマルチベンダーのアクセラレーションを提供します。
これが重要な理由
新しいツールキットは、不慣れな開発コンセプトやツールを理解し、克服するための課題を取り除くことで、堅牢でハイパフォーマンスなクラウド・コンピューティングを容易に導入できるようにします (これらの課題は、要求の厳しいワークロードの展開に時間がかかったり、ソフトウェアの非互換性を生じさせたり、パフォーマンスを低下させることがあります)。
「Cloud HPC Toolkit とインテル® Select ソリューション for シミュレーション & モデリングを使用することで、厳密なテストを経て実際のパフォーマンスに最適化されたハードウェア・ソフトウェア構成を自動的にスピンアップできるため、当て推量を排除できる利点があります。」
関連情報
- インテル® MPI ライブラリー
- インテル® oneAPI マス・カーネル・ライブラリー
- Google Cloud* ブログ (英語)
- ビデオ: インテル® oneAPI ツールキットを使用した Google Cloud* 上でのワークロードの高速化 (英語)
インテル® VTune™ プロファイラー 2022.3 リリース
2022年6月7日 | インテル® VTune™ プロファイラー
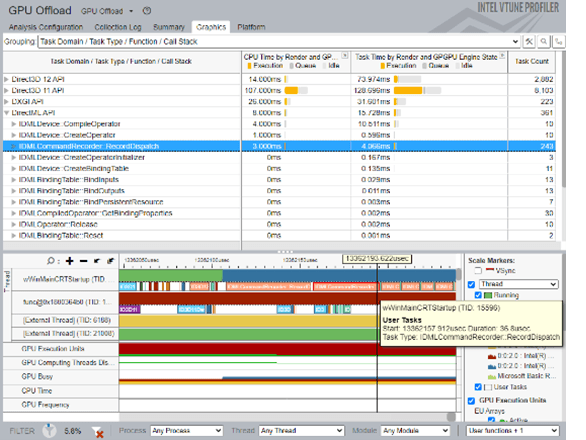 CPU、GPU、FPGA システムのパフォーマンス・ボトルネックを素早く発見して最適化できます。
CPU、GPU、FPGA システムのパフォーマンス・ボトルネックを素早く発見して最適化できます。
新機能
- ホスト側の非効率的な API 呼び出しとその原因を特定する DirectML API をサポートしました。
- CPU 側のスタックを分析して、OpenCL* API の USM 拡張を使用する GPU 計算タスクのメモリー転送関連のボトルネックを特定できます。
詳細については、software.intel.com/vtune (英語) を参照してください。
インテルが Codeplay Software を買収
2022年6月1日 | oneAPI 仕様 (英語)

インテルは、クロスアーキテクチャーでオープンな標準ベースの開発者向けテクノロジーのグローバルリーダーである Codeplay Software の買収に合意し、oneAPI エコシステムのサポートをさらに推進しています。
Codeplay は、oneAPI で採用された Khronos Group のオープンスタンダードなプログラミング・モデルである SYCL* に関する専門知識とリーダーシップ、および SYCL* や OpenCL* などのオープンエコシステムの活動から、RISC-V*、自動車のソフトウェア安全、医療画像に至る、幅広い業界への大きな貢献で世界的に認められている企業です。
Codeplay は、oneAPI を大衆に届けるという使命を担い、多様なハードウェア・プラットフォームをサポートする製品をグローバルに幅広く提供しています。
Codeplay は、インテルの強みを生かし、オープンスタンダードとその上に構築されたオープンソースのエコシステムに基づき、SYCL* ソリューションをクロスアーキテクチャーおよびマルチベンダーの製品に展開できるでしょう。
ISC 2022 においてインテルは持続可能でオープンな HPC-AI に注力
2022年5月31日 | Intel @ ISC 2022 (英語)
![]() International SuperComputing 2022 において、インテル コーポレーションのスーパーコンピューティング・グループの VP である Jeff McVeigh は、より持続可能でオープンな HPC-AI 向けのイノベーションを加速するインテルの HPC リーダーシップ技術を、次のように紹介しました。
International SuperComputing 2022 において、インテル コーポレーションのスーパーコンピューティング・グループの VP である Jeff McVeigh は、より持続可能でオープンな HPC-AI 向けのイノベーションを加速するインテルの HPC リーダーシップ技術を、次のように紹介しました。
- インテル® ソフトウェアと oneAPI は、ソフトウェア・スタック全体をカバーしており、開発者がコード・リファクタリングの負担なしに、最新のシリコン・イノベーションを活用してスケーラブルでハイパフォーマンスな効率良いコードを作成できるように支援する、ツール、プラットフォーム、ソフトウェア IP を提供します。
- 新たに 2 つのインテル® oneAPI 研究拠点がエコシステムに加わり、oneAPI の能力と採用を拡大するため世界中で活動している大学や研究所は合計 22 となりました。
新しいインテル® oneAPI 研究拠点の紹介
- ブリストル大学では、oneAPI とクロスプラットフォーム・プログラミング向けの Khronos Group の SYCL* 抽象化レイヤーを使用して、エクサスケールのパフォーマンス移植性を達成するベスト・プラクティスを開発しています。目標は、科学計算コードが大規模なヘテロジニアス・スーパーコンピューティング・システムでハイパフォーマンスを達成できるようにすることです。
- Centre for Development of Advanced Computing (CDAC) (英語) は、インドの HPC および AI コミュニティーに oneAPI トレーニングを提供する、熟練インストラクターの基盤を構築しています。CDAC は、そのインフラを通じて国内でトレーニングを幅広く展開し、トップレベルの大学で oneAPI を教える予定です。
関連情報
ハイデルベルク大学が oneMKL オープンソース・インターフェイスでヘテロジニアス・コンピューティングを推進
2022年5月25日 | インテル® oneMKL、oneAPI 仕様 (英語)
ハイデルベルク大学 (英語) は最近、インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) インターフェイスで乱数生成と BLAS に対する ROCm サポートを実現しました。これは、oneMKL インターフェイス・プロジェクトに対するコミュニティーによる新しい重要な貢献です。このプロジェクトは、CPU およびコンピュート・アクセラレーター・アーキテクチャーに焦点を当てた数学アルゴリズム向けに、SYCL* ベースの API を提供する oneAPI 業界イニシアティブの一部です。
rocRAND と rocBLAS のサポートをプロジェクトに追加するこの取り組みにより、hipSYCL コンパイラーを使用して乱数生成と線形代数計算が可能になり、hipSYCL で記述されたクロスプラットフォーム・アプリケーションでネイティブに近いパフォーマンスを達成できるようになりました。また、oneMKL オープンソース・インターフェイスは、DPC++ 以外のほかの SYCL* 実装をアップストリーム・サポートする最初の oneAPI コンポーネントとなります。
関連情報
- ハイデルベルク大学の oneAPI 仕様の hipSYCL の取り組みに関するブログ (英語)
- ハイデルベルク大学の oneAPI プロジェクトにおけるエンジニアリング・ビジョン (英語)
- oneAPI CoE エコシステムの主要な貢献者 (英語)
- oneAPI イニシアチブの詳細: oneapi.io (英語)
- oneMKL オープンソース・インターフェース (英語)
TensorFlow* 2 で oneDNN の AI 最適化のチューニングがデフォルトで有効に
2022年5月25日 | インテル® oneDNN (英語)
最新リリースの TensorFlow* 2.9 (英語) では、Google* が x86 パッケージのデフォルトのバックエンド CPU 最適化として、インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) を有効にしたことで、パフォーマンスが向上しています。これは、すべての Linux* x86 パッケージと、第 2 世代インテル® Xeon® スケーラブル・プロセッサー以降の CPU でサポートされるインテル® AVX512_VNNI、インテル® AVX512_BF16、インテル® AMX ベクトルおよび行列拡張などのニューラル・ネットワーク向けのハードウェア機能を搭載した CPU に対して適用されます。
これらの最適化により、畳み込み、行列乗算、バッチ正規化などの主要な計算負荷の高い演算が高速化され、oneDNN を使用しないバージョンと比較して、パフォーマンスが最大 3 倍 (英語) 向上します。
これが重要な理由
今日、マシンラーニングやディープラーニングでは GPU などの AI アクセラレーターが重視されていますが、AI ワークフローのすべての段階において、CPU は依然として重要な役割を果たしており、ほとんどのパーソナルデバイス、ワークステーション、データセンターで利用されています。このデフォルトの最適化により、すでに TensorFlow* を使用している何百万人もの開発者が、生産性の向上、トレーニング時間の短縮、計算の効率的な利用を達成できるようになります。
パフォーマンスの向上は、自然言語処理、画像および物体認識、自律走行車、不正検知、医療診断および治療など、さまざまなアプリケーションに恩恵をもたらします。
ソフトウェアを入手
- インテル® oneDNN は スタンドアロン (英語) またはインテル® oneAPI ベース・ツールキット (英語) の一部として利用できます。
- TensorFlow* 向けインテル® オプティマイゼーションスタンドアロン (英語) またはインテル® oneAPI AI アナリティクス・ツールキット (英語) の一部として利用できます。
関連情報
インテルがヘテロジニアス・コードの開発を支援する SYCLomatic 移行ツールをオープンソース化
2022年5月15日 | DPC++/SYCL* (英語)
 インテルは最近、SYCLomatic (英語) と呼ばれるプロジェクトを通じて、コードを SYCL* に移行するオープンソースのツールをリリースしました。このツールは、開発者がより簡単に CUDA* コードを SYCL* および C++ に移行し、ヘテロジニアス・アーキテクチャー向けのクロスアーキテクチャー・プログラミングを加速することを支援します。このオープンソース・プロジェクトは、SYCL* 標準の採用を推進するコミュニティーの協力を可能にし、開発者を単一ベンダーの独占的エコシステムから解放する重要なステップとなります。
インテルは最近、SYCLomatic (英語) と呼ばれるプロジェクトを通じて、コードを SYCL* に移行するオープンソースのツールをリリースしました。このツールは、開発者がより簡単に CUDA* コードを SYCL* および C++ に移行し、ヘテロジニアス・アーキテクチャー向けのクロスアーキテクチャー・プログラミングを加速することを支援します。このオープンソース・プロジェクトは、SYCL* 標準の採用を推進するコミュニティーの協力を可能にし、開発者を単一ベンダーの独占的エコシステムから解放する重要なステップとなります。
SYCLomatic ツールの仕組み
SYCLomatic は、CUDA* コードから SYCL* への移行を支援し、通常、CUDA* コードの 90~95% を自動的に SYCL* コードに移行します。このプロセスを完了するため、開発者は残りのコードを手動で完成させ、その後、希望するパフォーマンスのレベルまでカスタム・チューニングします。
インテル® oneAPI のエバンジェリストである James Reinders は次のように述べています。
「SYCL* を使用して C++ に移行することで、ISO C++ との整合性が強化され、マルチベンダーのサポートによりベンダーロックインを解消し、マルチアーキテクチャーのサポートにより新しいハードウェア・イノベーションのパワーを最大限に活用する柔軟性が得られます。SYCLomatic は、作業の多くを自動化する貴重なツールであり、開発者は移行よりもカスタム・チューニングに集中することができます。」
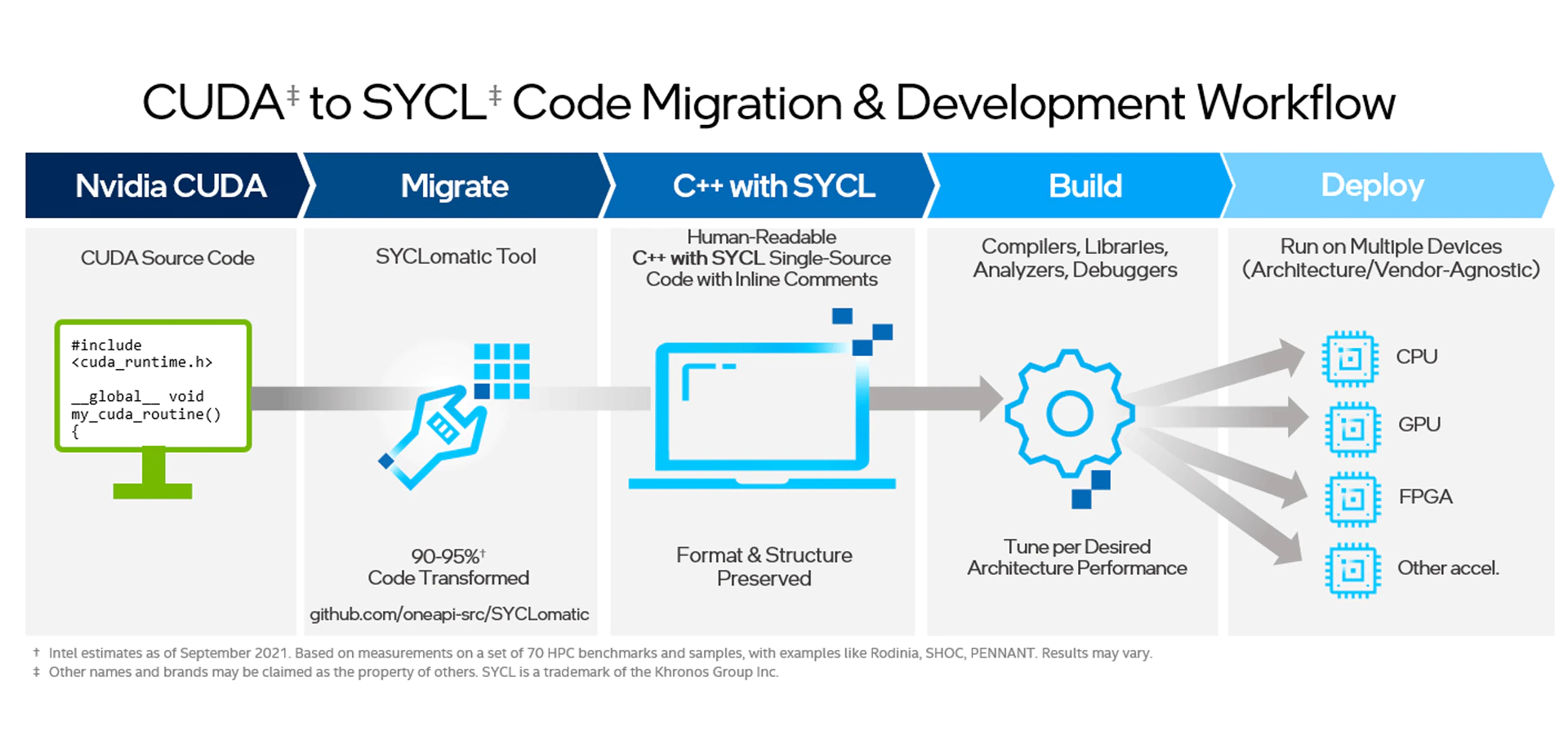
SYCLomatic は GitHub プロジェクトです。ツールの進化のため、このツールを使用し、フィードバックや貢献にご協力ください。
インテル® oneAPI ツールキット 2022.2 リリース
2022年5月18日 | インテル® oneAPI、インテル® oneAPI ツールキット
最新のインテル® oneAPI ツールがリリースされました。パッケージはダウンロードすることも、インテル® DevCloud (英語) で利用することもできます。今回のリリースにはすべてのツールキット (30 以上の個別のツール) のアップデートが含まれており、それぞれがデータセントリックなワークロード向けにパフォーマンスの向上と機能の拡張をもたらすように最適化されています。
2022.2 の新機能:
メディア、ゲーム、AI ワークロード向けのインテル® Arc™ ディスクリート・グラフィックス
- クロスアーキテクチャーのインテル® oneAPI ソフトウェア・ツールを使用して、テクノロジー、プラットフォーム、ソフトウェア、および CPU と組み合わせた GPU での AI アクセラレーション処理で没入型のエンドユーザー体験を実現します。
- インテル® oneAPI ビデオ・プロセッシング・ライブラリー (インテル® oneVPL) (英語) により、業界初のハードウェア・アクセラレーションによる AV1 コーデックで、ビデオ・ソフトウェアによるエンコードと比較して最大 50 倍のパフォーマンス向上を実現します。[ベンチマークの詳細は図のフッターを参照]
- oneAPI を採用したインテル® ディストリビューションの OpenVINO™ ツールキット、インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) (英語)、およびパフォーマンス・チューニングに役立つインテル® VTune™ プロファイラー
コンパイラー
- インテル® oneAPI DPC++/C++ コンパイラーは、GPU や FPGA などのさまざまなハードウェア・アクセラレーターをプログラミングする開発者の生産性を高める SYCL* 2020 機能を追加し、OpenMP* 5.1 への対応を強化し、計算オフロードにおける OpenMP* リダクションのパフォーマンスを向上します。
- インテル® Fortran コンパイラーは、最新の LLVM テクノロジーをベースに、パラメーター化された派生型、F2018 の IEEE 比較操作、VAX 構造体のサポートを追加し、スカラー用の宣言マッパーのサポートにより OpenMP* 5.0 のサポートを拡大しています。
ハイパフォーマンス・ライブラリー
- インテル® oneMKL は、BLAS ドメインに MKL_VERBOSE GPU サポートと転置ドメインに CPU サポートを追加し、デバッグ時の視認性が向上しています。
- インテル® oneCCL (英語) は、インテル® インストルメンテーションおよびトレーシング・テクノロジー (インテル® ITT) のプロファイルをサポートし、インテル® VTune™ プロファイラーなどのツールで新たな情報が得られます。
- インテル® oneTBB は、parallel_sort について最新の C++ 標準のサポートと使用を改善し、task_area 拡張、collaborative_all_once、アダプティブ・ミューテックス、concurrent_hash_map のヘテロジニアス・オーバーロード、および task_scheduler_handle に対する完全に動作する機能が追加されました。
- インテル® oneVPL は、複数のハードウェア・アダプターと拡張開発環境をサポートし、さらに CPU 実装での MPEG2 デコードにより、専用ハードウェアを持たないシステムでコーデックのカバレッジを向上します。
- インテル® MPI ライブラリーは、GPU ピンニングにより、アプリケーション・レベルで優れたリソース計画と制御を可能にし、マルチレールのサポートによりアプリケーションのノード間通信帯域幅を向上します。
解析ツール
- インテル® Advisor は、CPU から GPU へのオフロードのデータ転送再利用コストの最適化、GPU ルーフライン・カーネルとオフロードのモデル化の詳細、GPU ルーフライン・パースペクティブでのオフロード領域のソースコードの確認 (パフォーマンス・メトリックを含む) など、ユーザー向けの推奨と共有が追加されました。
- インテル® VTune™ プロファイラーは、最新世代のサーバー・プラットフォームのインテル® VT-d に関連するパフォーマンスの非効率性を特定できるようになり、インテル® Arc™ GPU をサポートし、さらに Docker* コンテナとしても提供されています。
AI ワークロードの高速化
- TensorFlow* 向けインテル® エクステンション (英語) は、モデル読み込みの高速化、要素単位の Eigen 演算の効率化、matmul biasadd-g などの融合サポートを追加しています。
- scikit-learn* 向けインテル® エクステンション (英語) およびインテル® ディストリビューションの Modin* (英語) は、新機能、アルゴリズム、パフォーマンス向上 (kNN のミンコフスキー距離とちぇびシェフ距離、t-SNE アルゴリズムの高速化など) により、機能性と生産性を向上しています。
- インテル® Neural Compressor (英語) の量子化と精度制御による AI デプロイメントの高速化により、サポートされるディープラーニング・フレームワーク全体で低精度の推論を大いに活用できます。
- Model Zoo for Intel® Architecture (英語) で新しい PyTorch* モデルの推論とトレーニングのワークロードをサポートし、Python* 3.9、TensorFlow* v2.8.0、PyTorch* v1.10.0、IPEX v1.10.0 にサポートを拡大しています。
レンダリングとレイトレーシングによるサイエンティフィック・ビジュアライゼーション
- インテル® オープン・ボリューム・カーネル・ライブラリー (英語) は、IndexToObject アフィン変換と Structured Volumes の定数セルデータをサポートしました。
- インテル® OSPRay (英語) および Intel® OSPRay Studio (英語) は、メッシュ・ジオメトリーの Multi-segment Deformation Motion Blur をサポートし、新しいライト機能と最適化機能を提供します。
- Intel® Implicit SPMD Program Compiler Run Time (ISPCRT) (英語) ライブラリーがパッケージに追加されました。
FPGA
- インテル® oneAPI ベース・ツールキット用インテル FPGA アドオンは、メモリーやパイプの読み取りと書き込みの間の正確な/最小/最大レイテンシーをユーザーが指定できるようにし、DSP と ALM または ALM のみで定数を含む算術浮動小数点演算の実装を可能にします。

GROMACS と oneAPI がオープンソースの創薬を支援
2022年5月5日 | oneAPI 仕様 (英語)、インテル® oneAPI ツール

SYCL*、oneAPI、マルチアーキテクチャー・ツールで高速化された GROMACS は、インテル® Xe アーキテクチャー・ベースの GPU で強力なパフォーマンスを発揮
最近リリースされた GROMACS 2022 (英語) では、インテル® Xe アーキテクチャー・ベースの現在および将来の GPU を含む、マルチベンダー・アーキテクチャーに拡張されました。
ストックホルム大学およびスウェーデン王立工科大学の Erik Lindahl 氏が率いるチームは、NVIDIA* ハードウェアでのみ動作する GROMACS の CUDA* コードを、インテル® DPC++ 互換性ツールを使用して SYCL* に移行しました。通常、このツールはコードの 90%~95%を自動で移行します1,2、その結果、単一の移植性に優れたクロスアーキテクチャー対応のコードベースにより、開発を大幅に合理化し、マルチアーキテクチャー環境での展開に柔軟に対応できるようになりました。
ソフトウェアの高速計算は、インテル® oneAPI の DPC++/C++ コンパイラー、ライブラリー、HPC 解析ツール、クラスターツールなどのクロスアーキテクチャー・ツールを使用することで実現されました。
GROMACS 2022 は SYCL* と oneAPI をフルサポートしており、新しいクラスのハードウェア上で動作するように拡張されています。すでに、現行のインテル® Xe アーキテクチャー・ベースの GPU と、インテル® DevCloud を使用して次期インテル® Xe アーキテクチャー・ベースの GPU 開発プラットフォーム (開発コード名 Ponte Vecchio) 上で、本番シミュレーションを実行しています。現段階では優れたパフォーマンス結果を達成し、インテルのハードウェアとソフトウェアの連携によるパワーを証明しています。全体として、これらの最適化はハードウェアの多様性に対応し、ハイエンドのパフォーマンスを提供し、競争とイノベーションを促進することで、科学をより速く、より低コストで実現します。
GROMACS について
GROMACS は、タンパク質、脂質、核酸のシミュレーションを行う分子動力学パッケージです。乳がん、COVID-19、2 型糖尿病といった疾患に対する重要な医薬品の特定や、国際的な分散コンピューティング・イニシアチブ Folding@home (英語) に貢献しています。
1GROMACS の NVIDIA* CUDA* コードを、oneAPI の SYCL* 実装であるデータ並列 C++ (DPC++) に移行し、新たにクロスアーキテクチャーに対応したコードを作成しました。
2出典: 2021年9月現在のインテルによる推定。Rodinia、SHOC、PENNANT など、70 種類の HPC ベンチマークとサンプルの測定結果に基づいています。結果は異なることがあります。
![]()
クロスアーキテクチャーの開発ツールにより、新しい GPU を搭載したシステムで驚異的なエンドユーザー体験を実現
2022年3月31日 | インテル® ソフトウェア・ツール、インテル® グラフィカル・パフォーマンス・アナライザー (英語)、インテル® oneAPI ビデオ・プロセシング・ライブラリー

コンテンツ制作者やゲーム開発者は、インテル® Arc™ GPU (開発コード名 Alchemist) を搭載した新しいインテル® Evo™ プラットフォーム (英語) により、テクノロジー、ソフトウェア、AI アクセラレーション処理などのイノベーションを活用して、没入型のエンドユーザー体験を創出できます。
インテル®ソフトウェア・ツールは、開発者がインテル® Arc™ GPU の能力を解放し、インテル® CPUと組み合わせて最大のビジュアル・パフォーマンスを発揮できるようにアプリケーションを最適化する大きな役割を担っています。
インテル®ソフトウェア・ツールは、次のような利点をもたらします。
- グラフィックスのボトルネックの解析と最適化。インテル® グラフィックス・パフォーマンス・アナライザー (英語) を使用して、グラフィックスおよびゲーム・アプリケーションをプロファイルし、レイトレーシング、システムレベルのプロファイル、XeSS 機能 (英語) によりプロファイル能力を向上できます。複数の API (DX、Vulkan*、OpenGL*、OpenCL* など) をサポートし、ストリームとトレースのキャプチャー、シェーダーの最適化、最もコストのかかるイベントの特定が可能です。
ダウンロードはこちら (英語) - 計算負荷の高いタスクを高速化。CPU と GPU コードで最も時間のかかる部分を特定します。インテル® VTune™ プロファイラーを使用して、スレッドの挙動を視覚化し、並行処理の問題を迅速に発見して修正します。
ダウンロードはこちら (英語) - メディア処理とクラウドゲームストリーミングを高速化。インテル® oneAPI ビデオ・プロセシング・ライブラリー (インテル® oneVPL) は、ハードウェア AV1 エンコードとデコードのサポート、および Hyper Encode API による インテル® ディープ・リンク・テクノロジーの利用を可能にし、プラットフォームの複数のインテル® アクセラレーターを活用したシングルストリームのトランス・コーディングを最大 1.4x 倍スピードアップ1 します。すでに HandBrake と DaVinci Resolve* を使用しているコンテンツ制作者向けに、インテル® oneVPLは最新バージョンに統合されます。
ダウンロードはこちら (英語) - AI とマシンラーニングを統合。ゲーム開発者向けのインテル® AI Game Dev Toolkit (英語) は、没入感のある世界の創造から、リアルタイムのゲーム・オブジェクト・スタイル転送の可視化まで、AI を活用したさまざまな機能を提供します。
ダウンロードはこちら (英語)
1. HandBrake の内部リリースを使用したビデオエンコードの FPS は、インテル® Xe グラフィックスとインテル® Arc™ グラフィックスを組み合わせほうが、インテル® Arc™ グラフィックスのみの場合よりも最大で 40% 向上。製品化前のインテル® GPU 開発コード名 Alchemist で HandBrake を実行。2021年10月現在。
Soda がさまざまなアーキテクチャーで scikit-learn* のパフォーマンスをサポートするインテル® oneAPI 研究拠点を発表
2022年3月31日| インテル® Extension for scikit-learn* (英語)
フランスのデジタル科学技術のための国立研究機関である Inria (National Institute for Research in Digital Science and Technology) (英語) の ソーシャルデータ研究チーム (Soda) (英語) は、最も広く使用されているマシンラーニング・ライブラリーの 1 つである scikit-learn* のハードウェア最適化パフォーマンス・ブースターの開発に注力するため、インテル® oneAPI 研究拠点 (CoE) を開設することを発表しました。
この scikit-learn* 拡張は、oneAPI の numba_dppy や DPC++ コンポーネントを使用して、より効率的なマシンラーニングを実現します。この実装は、scikit-learn* のコア開発者、インテルのエンジニア、および関心のあるコミュニティー・メンバーによって保守される、独立して管理されるプロジェクトにパッケージ化されます。
「ヘテロジニアス・コンピューティングは必然です。ホストが CPU や GPU などの異なるプロセッサーやアクセラレーターに計算タスクをスケジューリングすることで発生します。このパートナーシップにより、scikit-learn* はマルチアーキテクチャー・システムにおいて、より高いパフォーマンスとエネルギー効率を実現することができます。」
VS Marketplace でインテル® コンパイラーを提供開始
2022年3月10日 | インテル® oneAPI DPC++/C++ コンパイラー (英語)
マルチ並列処理をサポートするコンパイラーのダウンロード方法が増えました。LLVM ベースの Windows* 向け DPC++/C++/C コンパイラーが Visual Studio* Marketplace からダウンロードできるようになりました。
主な機能
- 高速でマルチコア対応のベクトル化されたクラスターベースのアプリケーションの生産的な開発をサポートする拡張を含む
- 最新の C/C++ 言語と OpenMP* 標準をサポート
- 複数の並列モデルとインテル® oneTBB、インテル® oneMKL、インテル® oneVPL、およびインテル® IPP を含むハイパフォーマンス・ライブラリーをサポート
- C++、Visual Basic*、C# など、言語が混在するアプリケーションをビルド可能
詳細と無料のダウンロード (英語)
インテルがソフトウェアによる成長機会に投資
2022年2月22日 | インテル® oneAPI ツール

インテルの 2022年投資家会議では、データセンター、AI、その他のセグメントのワークロードを高速化する次世代のインテル® Xeon® およびクライアント向け CPU、Ponte Vecchio✝/Arctic Sound-M✝ GPU などの製品の最新情報と、これらを実現するためのソフトウェアが発表されました。
役員によるセッション (英語) では、インテルのソフトウェア・ファースト戦略に言及しました。
- インテル コーポレーションのシニア・バイスプレジデント兼 CTO 兼ソフトウェア & アドバンスト・テクノロジー・グループ本部長である Greg Lavender は、oneAPI (英語) とインテル® oneAPI ツールキットによるオープンで標準ベースのクロスアーキテクチャー・プログラミングが、高度なアーキテクチャーにおいて、いかにパフォーマンスと開発生産性を実現するかについて、論説 (英語) とプレゼンテーション (英語) で説明しました。
- インテル コーポレーションのシニア・バイスプレジデント兼アクセラレーテッド・コンピューティング・システム & グラフィックス・グループ本部長である Raja Koduri は、インテルのメディアおよび HPC-AI スーパーコンピューティング戦略を支えるハードウェアとソフトウェアの強化について紹介しました。以下に概要を示します。
- インテル® Xeon® プロセッサーと、インテル® oneAPI ビデオ・プロセシング・ライブラリー (インテル® oneVPL) (英語)、インテル® oneAPI AI アナリティクス・ツールキット (英語)、インテル® ディストリビューションの OpenVINO™ ツールキットなどのオープンなエコシステムにより、高密度、リアルタイムのブロードキャスト、プレミアムコンテンツを実現し、インターネット・トラフィックの 80% が動画であるグローバルな需要に応えます1。
- 今後発売予定の Artic Sound-M✝ GPU は、デスクトップおよびクラウドゲーミングの品質、レイテンシー、密度の要件に対応した最先端のトランスコード・パフォーマンスと、AI アナリティクス・エンジンを備えたシームレスなメディア・スーパーコンピューターを実現します。Artic Sound-M✝ GPU は、ストリーミング、ゲーム、アナリティクス向けの業界唯一のオープンソース・メディア・ソリューション・スタックであり、同じ品質で 30% 以上の帯域幅の改善を実現する AV1 エンコードを搭載した業界初の GPU です2。
- 何十億行ものコードが、スーパーコンピューターの 85% に搭載されているインテル® Xeon® プロセッサー向けに最適化されています3。インテル® Xeon® CPU (Sapphire Rapids✝) + Ponte Vecchio✝ GPU は強力でシームレスなエコシステムの基盤となり、oneAPI は開発者が単一のコードベースで多種多様な CPU やアクセラレーターを利用できるようにします。
関連情報
- インテルのテクノロジー・ロードマップとマイルストーン (英語)
- インテルのソフトウェアの優位性を解読 (英語)
- インテルのソフトウェア: セキュリティーを考慮したオープンな設計 (英語)
- Raja Koduri の高速コンピューティングとグラフィックスについてのプレゼンテーション (英語)
- oneAPI (英語) | インテル® oneAPI ツールキット
1出展: Cisco Global 2021 Forecast Highlights
2出展: Mhojhos Research
3過去 10 年間の TOP500 リストに基づく
✝ 開発コード名
ダルムシュタット工科大学がインテル® oneAPI 研究拠点を開設
2022年2月14日 | インテル® oneAPI ツール
![]() ダルムシュタット工科大学の組込みシステム・アプリケーション・グループは、oneAPI (英語) のオープンなクロスアーキテクチャー・プログラミングにより、医学および薬学研究で使用されるデータ並列計算とシミュレーション・ソフトウェアを高速化することを目的として、インテル® oneAPI 研究拠点 (CoE) を開設することを発表しました。
ダルムシュタット工科大学の組込みシステム・アプリケーション・グループは、oneAPI (英語) のオープンなクロスアーキテクチャー・プログラミングにより、医学および薬学研究で使用されるデータ並列計算とシミュレーション・ソフトウェアを高速化することを目的として、インテル® oneAPI 研究拠点 (CoE) を開設することを発表しました。
インテルと共同で、Autodock アプリケーション (英語) の高速化されたバージョンを移行して、複数のハードウェア・アーキテクチャー向けに効率良く最適化およびチューニングできる単一のコードベースを作成する予定です。
さらに、ダルムシュタット工科大学では、CPU、GPU、FPGA で並列実行することで創薬シミュレーションをスピードアップするため、Autodock-GPU (英語) の次世代並列実装に取り組んでいます。
インテル コーポレーションのバイスプレジデント兼ソフトウェア製品 & エコシステム事業本部長の Joe Curley は次のように述べています。
「新しい oneAPI 研究拠点は、マルチアーキテクチャーの SYCL* 言語と oneAPI にとって素晴らしい前進と言えるでしょう。ダルムシュタット工科大学のチームとのコラボレーションにより、医学および薬学の研究者が AutoDOCK-GPU を任意のハードウェア上で生産的に使用するための道が開かれました。」
詳細:
https://www.tu-darmstadt.de/universitaet/aktuelles_meldungen/einzelansicht_350976.en.jsp (英語)
https://www.tu-darmstadt.de/universitaet/aktuelles_meldungen/einzelansicht_350976.de.jsp (ドイツ語)
2021年
インテル® oneAPI ツールキット 2022.1 リリース
2021年12月23日 | インテル® oneAPI ツール (英語)
ハードウェアの選択肢を増やし、プロプライエタリーの壁を越えて、コードの最高パフォーマンスを解放

インテル® oneAPI ツールキット 2022.1 リリースでは、ハイパフォーマンスなクロスアーキテクチャーのアプリケーションとソリューションを実現する新機能、性能、改善点 (2021.1年12月の 2021 リリースから 900 以上) を提供しています。
主な変更点:
クロスアーキテクチャー・プログラミング
- インテル® oneAPI DPC++/C++ コンパイラー (英語) は、C++/SYCL*/Fortran を実装する初の LLVM ベースのコンパイラーで、CPU と GPU 向けのプログラミングの生産性を向上させます。
- データ並列 Python* により、CPU と GPU で計算を高速化します。
- インテル® DPC++ 互換性ツール (英語) は、CUDA* コードの 90%-95% を SYCL*/DPC++ へ自動的に移行します。1
高度な開発生産性
- インテル® VTune™ プロファイラー (英語) のフレームグラフにより、パフォーマンス・ホットスポットを可視化する機能が向上しました。
- インテル® Advisor (英語) のアクセラレーター・パフォーマンスのモデル化により、コードを変更する前に GPU へオフロードする利点を予測できます。
- コーン・テレメトリー、補助特徴ノイズ除去、FP16 サポートを含むインテル® oneAPI レンダリング・ツールキット (英語) の新機能は、より堅牢な形状を提供し、レンダリング時間を短縮します。今後リリースされるインテル® Xe GPU のサポートに加えて、リアルタイムのノイズ除去により、最終フレームのプロダクション品質のレンダリングをさらに向上します。
- 拡張された開発環境のサポートには、Microsoft* VS Code とのより緊密な統合、VS 2022 サポート、および Windows* 上での Linux* 開発用の WSL2 が含まれます。
AI トレーニングと推論パフォーマンスの最適化
- インテル® Optimization for Tensorflow* (英語) は、第 3 世代インテル® Xeon® スケーラブル・プロセッサー上で純正バージョンと比較して 10 倍のスピードアップを実現します。2
- 新しいインテル® Extension for scikit-learn* (英語) は、インテル® CPU 上でマシンラーニング・アルゴリズムを 100 倍以上高速化します。3
- 複数のディープラーニング・フレームワークにおいて、トレーニング後の最適化手法により推論パフォーマンスを高速化するインテル® Neural Compressor (英語) が追加されました。
ハードウェア・サポート
- すべてのツールキットは、インテル® AVX-VNNI 対応の第 12 世代インテル® Core™ プロセッサー (開発コード名 Alder Lake)、インテル® AMX 対応の第 4 世代インテル® Xeon® スケーラブル・プロセッサー (開発コード名 Sapphire Rapids)、およびこの語リリースされる Xe クライアントやデータセンター GPU を含む最新のハードウェアの高度な機能を利用するように最適化されています。
oneAPI を利用することで、ハードウェアの価値を最大限に引き出し、ハイパフォーマンスなクロスアーキテクチャー・コードを自信を持って開発し、アプリケーションの将来性を確保できます。
ブログを読む (英語)
プレスリリース (英語)
ツールキットを見る (英語)
インテルのレイトレーシング・ライブラリーをベースに構築された「Curved Ray Traversal」
2021年11月22日 | インテル® oneAPI レンダリング・ツールキット (英語)、インテル® Advanced Ray Tracing (英語)
システムを保護、強化、および実現する技術のリーダーである SURVICE Engineering Company (英語) は、インテル® Embree のレイトレーシング・カーネル・ライブラリーとインテル® OSPRay のレイトレーシング API (いずれもインテル® oneAPI レンダリング・ツールキットに含まれる) をベースにした新しい研究開発プロジェクト「Curved Ray Traversal (CRT)」を発表しました。
注目すべき理由
CRTは、実験フローの 3 次元構造を取得、処理、可視化するシステムである PowerFlow3D (英語) の中核を成しています。SURVICE 社は現在、インテルの先進的なレイトレーシング技術と oneAPI (英語) のクロスアーキテクチャー・プログラミングを利用して CRT の実装と最適化を行い、インテルの CPUと将来の Xe アーキテクチャーの GPU をサポートし、PowerFlow3D ベースのソリューションを前進させるべく取り組んでいます。
この共同研究は、ビジュアライゼーションと科学計算の両方において、ハイパフォーマンスなレイトレーシングを使用して革新的なアプリケーションを探求する SURVICE 社とインテルの取り組みを継続するものです。現在、次のようなレイトレーシングを中心とした取り組みが行われています。
- 電波伝搬のインタラクティブなシミュレーションと可視化
- 工業用画像処理および非接触計測における逆問題
- 国防総省向けに開発されている SURVICE 社の Tactical Resupply Vehicle をはじめとする、ドローン・プラットフォームの自律航行を可能にするディープ・ニューラル・ネットワークのトレーニング用合成データの生成
専門家の声
「今回の研究では、最新のプラットフォーム・ハードウェアとインテルが提供するオープンソースの oneAPI レイトレーシング・ソフトウェアを活用し、並列化とコード最適化の最先端の技術を駆使して、複数のアプリケーションに飛躍的な機能を提供しています。」
「インテルは、HPC ハードウェアとレイトレーシング・ソフトウェアの業界リーダーとして、オープンスタンダードとオープンソース・ソフトウェアを通じて業界の発展に努めています。SURVICE 社と協力することで、PowerFlow3D のようなドメイン固有の計算アプリケーション向けのレイトレース・ハードウェア・アクセラレーションなど、新しい画期的なユースケースを可能にしています。」
SuperComputing 2021: HPC を高速化する oneAPI
2021年11月15日 | インテル® oneAPI ツールキット (英語)
SC21 (英語) でインテル コーポレーション データセンター XPU 製品 & ソリューション担当副社長 Jeff McVeigh が発表した通り、バージョン 2021 から 900 を超える新機能が追加されたインテル® oneAPI ツールキット 2022.1 (英語) が 12月初旬にリリースされます。
以下は、新機能の一例です。
- 統一された C++/SYCL*/Fortran コンパイラーとデータ並列 Python* による、CPU と GPU 向けの新しいクロスアーキテクチャー開発機能。
- アクセラレーターをモデル化したり、パフォーマンス・ホットスポットを視覚化する高度な解析機能。
また、HPC と AI 分野で oneAPI エコシステムの拡大を加速させる 2 つの oneAPI 研究拠点 (CoE) の追加を発表しました。これらの研究拠点は、戦略的なコードの移行、ハードウェア・サポートの追加、新しい技術やサービス、開発者向けトレーニングを提供します。
- オールド・ドミニオン大学 (英語) は、NASA の支援を受けて、非構造格子 CFD カーネルを最適化し、インテルの CPU や Xe アーキテクチャーの GPU 上での効率的な実装を開発し、複雑な空力問題の解決を支援します。
- 中国科学院計算技術研究所は、oneAPI のハードウェア・サポートを追加のアーキテクチャーに拡大する予定です。
関連情報
Jeff McVeigh の講演動画: スーパーコンピューティングがより身近に (英語)
インテル® oneAPI 研究拠点ファクトシート (英語)
インテルの HPC & AI パビリオン (https://hpcevents.intel.com/)
Intel® Academic Program for oneAPI (英語)
Khronos がスケーラブルな 3D データ・ビジュアライゼーション向けの ANARI* 1.0 Provisional API をリリース
2021年11月2日 | インテル® OSPRay (英語)、Khronos Group
本日、Khronos Group は、スケーラブルな 3D データ・ビジュアライゼーション向けの暫定的なオープン・スタンダード API である ANARI* 1.0 (Analytic Rendering Interface: アナリティクス・レンダリング・インターフェイス) をリリースしました。ANARI* は、レンダリング処理の詳細を指定するのではなく、シーンの記述を構築して画像を生成することができるため、ビジュアライゼーション・アプリケーションの開発を容易にし、最先端のレイトレーシングを含む多様なレンダリング・エンジンを提供するクロスベンダーの移植性を実現します。
Khronos は、ANARI 仕様 (英語) に加えて、サンプル実装、初心者向けアプリケーション、開発ツール、適合性テストをオープンソースで公開しており、2022年の仕様確定に向けて、コミュニティーからのフィードバックを受け付けています。
ANARI の初期実装は、インテルによるインテル® OSPRay (英語) へのアクセスを含め、現在開発中です。
インテルは、インテル® oneAPI レンダリング・ツールキットに含まれるインテル® OSPRay をベースにしたオープンソース実装で ANARI* API をサポートし、サイエンティフィック・ビジュアライゼーション、高忠実度レンダリング、MPI スケーラビリティーを向上させる専門知識と技術を ANARI* ユーザーに提供しています。
インテル コーポレーション
シニア主席エンジニア兼アドバンスド・レンダリング & ビジュアライゼーション・アーキテクチャー・シニア・ディレクター
Jim Jeffers
詳細は、こちら (英語) を参照してください。
統合されたインテル® デベロッパー・ゾーン、インテル® oneAPI 2022、および新しい研究拠点
2021年10月27日 | インテル® デベロッパー・ゾーン (英語)、インテル® oneAPI、インテル® oneAPI ツール (英語)

インテルは、開発者と業界関係者向けのテクニカル・カンファレンスである Intel InnovatiON (英語) において、統合されたインテル® デベロッパー・ゾーン、インテル® oneAPI 2022 ツール、およびインテル® oneAPI 研究拠点を発表しました。これらは、オープンなアプローチ、選択肢、信頼性を基本とする、インテルの開発者重視のソフトウェア・ファースト戦略の一環です。
統合された開発者体験
統合されたインテル® デベロッパー・ゾーンは、AI、クラウド、5G/エッジ、クライアント、ゲームなどの技術リソース、サンプルコード、リファレンス・デザイン、ツールなどへのアクセスを合理化し、簡素化します。また、ソフトウェアに関するトピックとテクノロジー (英語) の統合開発者カタログ、開発ツール (英語)、インテル® アーキテクチャー (CPU、GPU、FPGA、VPU など) 上でインテル® oneAPI ツールを使用してコードを開発およびテストする改善されたインテル® デベロッパー・クラウド (英語) にアアクスすることもできます。ブックマーク (英語) して活用してください。
インテル® oneAPI 2022 ツールのリリース
2021年内に、多数の新機能を提供するインテル® oneAPI 2022.1 ツールキットのリリースが予定されています (バージョン 2021 がリリースされた 2020年12月以降、累計で 900 以上の新機能が追加されています)。
2022.1 リリースの注目機能:
- 初の C++/SYCL*/Fortran コンパイラーとデータ並列 Python* により、CPU および GPU 向けの新しいクロスアーキテクチャー開発機能を追加。
- インテル® Advisor のアクセラレーター・パフォーマンスのモデル化を拡張。
- インテル® VTune™ プロファイラーにパフォーマンスのホットスポットを視覚化するフレームグラフを搭載。
- Microsoft* Visual Studio* との連携強化と Microsoft* WSL 2 (Windows* Subsystem for Linux*) のサポートによる生産性の向上。
ツールキットを見る (英語)

新しいインテル® oneAPI 開発拠点
インテルは、HPC、AI、ビジュアライゼーションに特化した 11 の新しいインテル® oneAPI 開発拠点 (CoE) を通じて、研究、技術、教育への投資を行っています。これらの研究拠点は、戦略的なコードの移行、ハードウェア・サポートの追加、新しい技術やサービス、カリキュラムを提供し、oneAPI エコシステムの導入を促進します。
以下の研究所および大学で構成されています。
- HPC – オークリッジ国立研究所とダラム大学
- HPC& ビジュアライゼーション – テネシー大学ノックスビル校
- AI – カリフォルニア大学バークレー校
- ビジュアライゼーション – カレル大学、ノーザンイリノイ大学、カリフォルニア大学デービス校、シュトゥットガルト大学、ユタ大学/Scientific Computing and Imaging (SCI)、ケンブリッジ大学/Stephen Hawking Centre for Theoretical Cosmology、テキサス大学オースティン校/Texas Advanced Computing Center (TACC)
詳細: インテル® oneAPI 研究拠点ファクトシート (英語) | Intel® Academic Program for oneAPI (英語)
Arnold 7.0 がインテル® Open Image Denoise を搭載
2021年10月19日 | インテル® Open Image Denoise (英語)、インテル® oneAPI レンダリング・ツールキット
Autodesk の Arnold 7.0 には、視覚的なノイズを選択的に除去するマシンラーニング・アルゴリズムにより画像品質を向上させる高度なノイズ除去機能である、インテル® Open Image Denoise が搭載されています。この統合により、開発者は忠実度を高め、効率良くレンダリングできます。
インテル® Open Image Denoise は、インテル® oneAPI レンダリング・ツールキットに含まれています。
インテル® oneAPI レンダリング・ツールキットをダウンロードする (英語)
ビデオを見る (英語) [1:56]
インテル® Open Image Denoise のコミュニティー & メーリングリスト (英語) にぜひご登録ください。
インテル® oneAPI ツールキット 2021.4 リリース
2021年10月1日 | インテル® oneAPI、インテル® oneAPI ツールキット (英語)
インテル® oneAPI ツールキット (英語) とスタンドアロン・ツールの最新のアップデートがリリースされました。パッケージをダウンロードすることも、インテル® DevCloud (英語) で利用することもできます。今回のリリースには 30 以上のツールが含まれており、それぞれがデータセントリックなワークロード向けにパフォーマンスの向上と機能の拡張をもたらすように最適化されています。
インテル® oneAPI ツールキットは、クロスアーキテクチャーおよびヘテロジニアス・コンピューティングの実現、最適化、および高速化を目的としています。C++、SYCL*、Fortran、MPI、OpenMP*、Python*などの業界標準を実装するコンパイラー、言語、ライブラリー、解析およびデバッグツール、最適化されたフレームワークを提供します。
2021.4 の新機能:
コンパイラー
- インテル® oneAPI DPC++/C++ コンパイラー (英語) とインテル® oneAPI DPC++ ライブラリー (英語) に、GPU や FPGA を含むさまざまなハードウェア・アクセラレーターでプログラミングの生産性を向上させる SYCL* 2020 機能が追加されました。
- ベータ版インテル® Fortran コンパイラー (英語) では、より多くの Fortran 2008 標準機能がサポートされ、アプリケーションをアクセラレーターにオフロードするため OpenMP* 5.0 および 5.1 への対応が強化されました。
- インテル® C++ コンパイラー・クラシック (英語) では、C/C++アプリケーションのマルチプラットフォーム、共有メモリー、マルチプロセシング・プログラミングを向上させる OpenMP* 5.0 & 5.1 機能が追加されました。
解析ツール
- インテル® VTune™ プロファイラーのホットスポット解析では、フレームグラフを使用して、ホットなコードパスと各関数およびその呼び出し先でかかった時間を視覚化できるようになりました。
- インテル® Advisor では、既存の GPU コードを将来の GPU に移行した場合のパフォーマンス・ゲインを予測する、GPU 間のモデル化機能が追加されました。また、GPU ルーフライン機能では、ユーザーコードの解析で GPU を最大限に活用するための実用的な提案が得られるようになりました。
- インテル® Inspector では、C++ スタックフレームの表示が改善され、libc と OpenCL* ライブラリーのレポートの精度が向上しています。
AI とアナリティクス
- インテル® AI アナリティクス・ツールキット (英語) にスパース機能とプルーニング機能が追加され、自然言語アルゴリズムのパフォーマンスをチューニングできるようになりました。
- Python* ベースの scikit-learn* アルゴリズムを GPUに簡単にオフロードして、ハードウェアの最先端の機能を利用できるようになりました。
ハイパフォーマンス・コンピューティング
- インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) (英語) では、乱数ジェネレーター (RNG) の多項分布、ポアソン V 分布、超幾何分布、負の 2 項分布、2 項分布において、DPC++ と OpenMP* オフロード API による GPU サポートが追加されました。
- インテル® MPI ライブラリーでは、Mellanox ConnectX*-6 のハイダイナミック・レンジ (HDR) に対応した OFI/psm3 のパフォーマンスが向上しました。
レンダリングとレイトレーシング
- インテル® オープン・ボリューム・カーネル・ライブラリー (英語) が ARM* CPU でのネイティブな使用に対応しました。また、インターバルとヒット・イテレーター・コンテキスト、任意のボリューム属性の反復処理、設定可能な背景値、3 次フィルタリングなどが追加されています。
- インテル® OSPRay (英語) では、トランスフォーム・モーション・ブラーがサポートされ、Studio Scene Graph での Python* バインディング、トランスフォームとカメラ・モーション・ブラー効果を制御するパラメーター、UDIM テクスチャー・ワークフローのサポートなど、いくつかの新機能が追加されています。
FPGA
- oneAPI ベース・ツールキット用インテル® FPGA アドオン (英語) に FPGA シミュレーション・フローのサポートが追加され、oneAPI デザインを業界標準の RTL シミュレーターで実行できるようになりました。
詳細は、ブログ (英語) を参照してください。
インテルがデータセンター、HPC-AI、クライアント・コンピューティング向けにアーキテクチャーを強化
2021年8月19日 | インテル® oneAPI レンダリング・ツールキット、インテル® oneAPI AI アナリティクス・ツールキット (英語)
 2021年の Intel Architecture Day において、インテル コーポレーションのアーキテクチャー、グラフィックス & ソフトウェア・グループのチーフ・アーキテクト兼シニア・バイスプレジデントである Raja Koduri は次世代のインテル® アーキテクチャー (CPU、GPU、IPU) を発表 (英語) し、次のように述べました。
2021年の Intel Architecture Day において、インテル コーポレーションのアーキテクチャー、グラフィックス & ソフトウェア・グループのチーフ・アーキテクト兼シニア・バイスプレジデントである Raja Koduri は次世代のインテル® アーキテクチャー (CPU、GPU、IPU) を発表 (英語) し、次のように述べました。
「本日インテルは、インテル®アーキテクチャーにおける一世代で最大の変革を発表しました。」
これらの新しいアーキテクチャーは、今後発売されるハイパフォーマンス製品に搭載され、計算能力とパフォーマンスへの要求の高まりに応える次時代のインテルのイノベーションの基盤となります。
高度な機能を実現するインテル® oneAPI ツールキット
インテル® oneAPI ツールで最適化された、Xe/GPU 開発プラットフォーム上で動作する以下の 2 つのデモをご覧ください。
インテル® oneAPI レンダリング・ツールキットのデモ (英語) [07:05] – CPU と Xe アーキテクチャーのレイトレーシング高速化 GPU 上でクロスアーキテクチャーで動作する、本ツールキットの 2 つのライブラリー (インテル® Embree とインテル® Open Image Denois) のプリプロダクション実装を使用したエンドツーエンドの映画品質クリエーターのワークフローを紹介します。
- 市販の SideFx Houdini アプリケーションで Pixar のオープンソース USD API からインテル® Embree とインテル® Open Image Denoise API を呼び出す CPU ベースのクリエイターのワークフロー
- Xe GPU を利用してリアルタイムの美しいレンダリングを実現する、CPU 上でのインテル® Embree とインテル® Open Image Denoise API 呼び出し
- インテルの歴史にインスピレーションを得た架空の「4004 Moore Lane」でのパストレース・シーンのリアルタイム・ウォークスルー
- CPU のみの場合よりも何倍も高速にレンダリングする、1,350 フレームで構成される 45 秒の映画の 4K 映画品質の最終版
インテル® oneAPI AI アナリティクス・ツールキットのデモ (英語) [1:27] – 開発コード名 Ponte Vecchio 上でインテル® oneAPI AI アナリティクス・ツールキットを使用して ResNet50 ベンチマークを実行します。開発コード名 Ponte Vecchio と Sapphire Rapids 上での ResNet50 の推論およびトレーニング・スループットの初期結果は、すでに新たなパフォーマンス・レベルに達しており、インテルが AI および HPC 分野においてこれまでのパフォーマンスを上回るという目標の実現に向けて順調に進んでいることを示しています。
世界は、人々の生活を豊かにするため、最も困難な計算問題を解決することをアーキテクト、エンジニア、開発者に期待しています。インテルはこれらの要求に応えるため、ハードウェアおよびソフトウェア戦略とその実行を急ピッチで進めています。
関連情報
 インテル® Arc™ – ハイパフォーマンスなディスクリート・グラフィックスの新ブランド
インテル® Arc™ – ハイパフォーマンスなディスクリート・グラフィックスの新ブランド
2021年8月16日 | インテル® oneAPI レンダリング・ツールキット、インテル® グラフィックス・パフォーマンス・アナライザー (英語)
インテルは、待望の新しいコンシューマー向けハイパフォーマンス・グラフィックス製品のブランドであるインテル® Arc™ を発表しました。
インテル® Arc™ ブランドは、ハードウェア、ソフトウェア、サーバーを網羅し、複数のハードウェア世代にまたがるものとなります。第 1 世代のインテル® Arc™ 製品は Xe HPG マイクロアーキテクチャー (開発コード名 Alchemist) をベースとしており、ハードウェアベースのレイトレーシングと AI によるスーパーサンプリング機能を備え、DirectX* 12 Ultimate をフルサポートします。
関連情報
- 記事を読む (英語)
- 動画を見る [4:06] (英語)
- インテル® Arc™ 製品ページ (英語)
業界の声…
「インテルは、パワフルでありながらアクセス可能なソフトウェア・ツールに支えられた幅広いハードウェアの選択肢を提供することで、この業界を牽引するゲーマーをサポートしたいと考えています。」 – CG Magazine (https://www.cgmagonline.com/2021/08/16/intel-arc-high-end-graphics-2022/)
「これは、グラフィックス市場の巨人 NVIDIA と AMD に対抗するためのインテルのもう 1 つの戦略です。」 – Geeknetic (スペイン語)
「ついに、青い巨人 (インテル) のファンはインテル® Core™ プロセッサーとインテル® Arc™ グラフィックスの両方を搭載したマシンを構築できるようになりました。」 – Thanh Nien, https://thanhnien.vn/game/cong-nghe/cuoc-chien-vga-se-hap-dan-hon-khi-intel-arc-tham-chien-dau-nam-2022-158372g.html (ベトナム語)
Intel、次期 CPU「Alder Lake」に搭載される新コアの詳細を発表
NVIDIA A100 の倍以上の性能となる Intel のモンスター GPU「Ponte Vecchio」。FP32 で 45TFLOPS を実現
Intel 次期 CPU「Alder Lake」は Windows 11 に最適化されたスレッド割り当て機能を搭載
Intel、ゲーマー向け次世代 GPU「Arc」をチラ見せ。ハイエンドまで対応可能な伸縮アーキテクチャ
Intel、次世代 DC 向けプロセッサ「Sapphire Rapids」の概要を発表 4 タイルを 1 パッケージに実装、DL 演算向け新命令 AMX に対応
レイトレーシングの今後: オープンでヘテロジニアスな高忠実度を重視したアプローチによるビジュアライゼーション
インテルは、Adobe、Autodesk、Blender、Chapeau Studios、Dassault Systèmes、Foundry などの業界リーダーとともに、8月9日~ 13日に開催されたバーチャル SIGGRAPH において、プロジェクション・マッピング、3D モデリングとアニメーション、リアルタイム・グラフィックス、ワークフローの効率化、メモリー・ソリューション、映画制作など、クールなレンダリング機能に焦点を当てた 10 のテクニカルセッションを実施しました (セッションのビデオと PDF はこちら (英語) を参照)。インテル コーポレーションのインテル・アドバンスト・レンダリング & ビジュアライゼーション・アーキテクチャー担当シニア主席エンジニア兼シニア・ディレクターの Jim Jeffers による基調講演 (英語) では、インテルの包括的なエンドツーエンドのプラットフォームにより、最も複雑なワークロードに取り組み、最高の忠実度を実現する方法を紹介しています。このプラットフォームは、強力なインテル® プロセッサー、インテル® Optane™ パーシステント・メモリー、ネットワーク、そしてインテル® oneAPI レンダリング・ツールキットを利用したオープンでヘテロジニアスな開発による高度なレイトレーシングで構成されています。特別基調講演のビデオでは、Autodesk のシニア・ソフトウェア開発マネージャーである Frederic Servant 氏が、インテル® Open Image Denoise (インテル® oneAPI レンダリング・ツールキットの一部) を Arnold レンダラーに統合することで、ノイズ除去のスピードと品質の向上に加えて、ディープラーニングを高速化する方法を紹介しています (ビデオ [2:50] (英語))。Linux Foundation のデジタルメディア & ゲーム担当 GM である Royal O’Brien 氏によるビデオでは、新しいオープンソース・プロジェクトである Open 3D Engine (O3DE) による、業界全体に利益をもたらすコラボレーションとイノベーションの可能性を説明します (ビデオ [3:30] (英語))。O3DE もインテル® oneAPI レンダリング・ツールキットのコンポーネントを使用しています。
今後の展望として Jeffers は、レイトレーシングの持続可能な開発には、新しい革新的なアーキテクチャーが利用可能になったときに選択肢を提供し、プロプライエタリーなプログラミングのウォールドガーデンがもたらす課題を克服するため、オープンで柔軟性があり、生産性の高いヘテロジニアスなアプローチが必要であると述べています。また、データセットやモデルのサイズ、複雑さが増しているため、「グラウンド・トゥルース」に近いフォトリアリスティックなビジュアライゼーションを実現するには、高い忠実度が重要な差別化要因となります。この点を説明するため、Jeffers はブログ (英語) で、インテル® Open Image Denoise と NVIDIA OptiX* を使用して一般に公開されているモデルの忠実度を比較しています。コンテンツ制作者、開発者、研究者の皆さん、oneAPI とインテルのテクノロジーを活用することで、仕事をより鮮やかに、生産的にできることをぜひ確認してください。
インテル® oneAPI ツールキット 2021.3 リリース
2021年7月2日 | インテル® oneAPI、インテル® oneAPI ツール、インテル® DevCloud (英語)
AI、HPC、メディア、レイトレーシングなどを含むデータセントリックなワークロードに対してパフォーマンスの向上と機能の拡張を提供する、インテル® oneAPI ツールキットの最新のアップデートがリリースされました。パッケージをダウンロードすることも、インテル® DevCloud で利用することもできます。
インテル® oneAPI ツールキットは、業界標準の C++、SYCL*、Fortran、MPI、OpenMP*、Python* などを実装し、インテル® AVX-512、インテル® VNNI/インテル® DL ブースト、暗号化命令などの独自の CPU 機能と GPU や FPGA を利用して、複雑なデータ駆動型アプリケーションを強化する、コンパイラー、ライブラリー、解析ツール、最適化されたフレームワークを提供します。
2021.3 の新機能:
- 第 3 世代インテル® Xeon® スケーラブル・プロセッサー (開発コード名:Ice Lake Server) 上でのパフォーマンスが向上しました (コンパイラー、ライブラリー、フレームワークの最適化を含む) (注: インテル® DevCloud for oneAPI で第 3 世代インテル® Xeon® スケーラブル・プロセッサーを利用できるようになりました)。
- 間もなくリリースされるインテル® oneAPI AI アナリティクス・ツールキットのアップデートにインテル® Extension for Scikit-learn* が追加されます。これにより、シングルノードおよびマルチノードのインテルの CPU および GPU 上で、マシンラーニング・アルゴリズムをワンラインの動的パッチで高速化して、100 倍以上のパフォーマンス向上を実現できます。
- ディープラーニングの推論ワークロードにおいて、明示的な入出力設定なしにグラフの最適化が改善され、洗練された自動混合精度 API により Int8 のサポートが向上しました。これは、インテル® oneAPI AI アナリティクス・ツールキットのアップデートに含まれます。
- インテル® DPC++ 互換性ツールで CUDA* 11.2 および 11.3 のヘッダーフィールドがサポートされ、CUDA* ドライバーおよびメモリーフェンス API の移行範囲が改善され、移行時間が最大 50% 削減されました。
- インテル® VTune™ プロファイラーで CPU と GPU 間のデータ転送解析が改善され、GPU オフロードスキーマの解析が向上しました。この機能は、達成可能なピーク GPU 占有率を制限する原因を自動的に検出することで、最もホットな計算カーネルのパフォーマンスを向上させます。
- インテル® Advisor の GPU ルーフライン解析が改善されました。これにより、メモリー・サブシステムのボトルネックを解消するためメモリー依存コードを調査したり、異なるワークロードのパフォーマンス特性を比較するため各カーネルのインスタンスの詳細を得られます。
- インテル® oneAPI レンダリング・ツールキットのボリューム・レイトレーシング・ライブラリーに、構造化 FP16、VDB FP16、VDB モーションブラー、VDB キュービック・フィルタリングの新しいサポートや、同じシーンで複数のボリュームを処理する機能が追加されました。
- インテル® コンパイラーと一部のライブラリー (インテル® oneMKL、インテル® oneDAL、インテル® oneDNN、インテル® oneVPL、インテル® IPP、インテル® MPI ライブラリー) は、HPC 向けパッケージ・マネージャーである Spack から入手可能です。
- より広範なユースケースで、新しい C API、プレビュー C++ および Python* API、インテル® oneVPL サンプルによるパフォーマンス上の利点が得られるようになりました。
- ベータ版インテル® Fortran コンパイラーで、GPU への計算オフロードを含む OpenMP* 5.1 のサブセットと Fortran 2008 標準がサポートされました。
- 新しい Yocto Project* レイヤーの meta-intel-oneapi により、DPC++ ランタイム、データコレクター、ライブラリーなどを Yocto Project* の Linux* カーネルに簡単に統合できるようになりました。
- すべてのツールにおいて、このほかにも新機能が追加され、パフォーマンス、安定性、セキュリティーが改善されています。
アップデートの詳細 (英語)
米国政府が AMD GPU ベースのエクサスケール・スーパーコンピューターをサポートするため oneAPI DPC++ コンパイラーに資金提供
2021年6月17日 | インテル® oneAPI DPC++ コンパイラー (英語)、インテル® oneAPI ツール
アルゴンヌ国立研究所 (英語) はオークリッジ国立研究所 (英語) と共同で、AMD GPU ベースの高性能計算スーパーコンピューター「Frontier」をサポートするため、SYCL* オープン・スタンダード・ソフトウェアの実装である oneAPI DPC++ コンパイラーの実装契約を Codeplay (英語) に授与しました。
Codeplay 社は、多様なハードウェア・アーキテクチャー用のコンパイラーやツールを開発している英国のソフトウェア企業で、SYCL* コンパイラーの主要な実装者でもあります。Frontier が SYCL* オープン・スタンダードに対応することで、米国エネルギー省の国立研究所のヘテロジニアス計算環境向けに科学アプリケーションを開発するための共通のプログラミング・モデルを実現します。
詳細 (英語)
 インテル® oneAPI ツールをサポートする Lenovo LiCO をリリース
インテル® oneAPI ツールをサポートする Lenovo LiCO をリリース
2021年6月11日 | インテル® oneAPI ツール (英語)、インテル® MPI ライブラリー (英語)
ヘテロジニアス・コンピューティングのための oneAPI へのコミットメントとして、Lenovo は LiCO の最新リリースに、インテル・プロセッサー向けに最適化された 3 つのインテル® oneAPI ベースのテンプレート (インテル® MPI ライブラリー、インテル® MPITune、インテルの OpenMP) を追加しました。
LiCO とは?
LiCo は Lenovo Intelligent Computing Orchestration の略で、AI モデルの開発とトレーニングのクラスター・コンピューティング・リソースの使用を簡素化するソフトウェア・ソリューションです。統一されたプラットフォームにより、基盤となる計算リソースとのやり取りが簡素化され、AI に使用する際の労力や複雑さを軽減しつつ、ポピュラーなオープンソースのクラスターツールを活用できます。
詳細 (英語)
 Appsbroker がインテルと Google Cloud を利用して STAC-A2 ベンチマークで HPC 速度に関する 2 つの世界記録を更新
Appsbroker がインテルと Google Cloud を利用して STAC-A2 ベンチマークで HPC 速度に関する 2 つの世界記録を更新
2021年6月7日| インテル® oneAPI ベース・ツールキット (英語)、インテル® oneMKL (英語)、第 2 世代インテル® Xeon® スケーラブル・プロセッサー
Google Premier Provider である Appsbroker (https://www.appsbroker.com/) が、第 2 世代インテル® Xeon® スケーラブル・プロセッサー・ベースの Google Cloud Platform (GCP) インスタンスのクラスターとインテル® oneAPI ツールによる最適化を組み合わせたテスト用ソリューションを提供しました。STAC-A2 ベンチマークがパブリッククラウドでテストされたのは今回が初めてで、その結果は記録的なものでした。
「STAC-A2 の C++ コードは、インテル® oneAPI ベース・ツールキットとインテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) を使用して、インテル・アーキテクチャー向けに開発および最適化されました。このハイパフォーマンスなコードは OnPrem で動作し、Appsbroker は GCP にシームレスに移行しました」
インテル コーポレーション
ファイナンシャル・サービス担当 GM
Mike Blalock
記事を読む
https://blog.appsbroker.com/articles/how-we-built-our-record-breaking-stac-a2-compute-cluster-on-google-cloud-using-intel-cpus)
STAC レポートを見る (英語)
SberCloud が 4 つのインテル® oneAPI ツールキットで AI 向け開発プラットフォームを拡張
2021年5月21日 | SberCloud、インテル® oneAPI ツールキット (英語)、oneAPI 仕様 (英語)
SmartDev (https://smartdev21.ru/) において、Sber 社は AI サービスのフルサイクルの開発と実装を行うクラウド・プラットフォーム「SberCloud ML Space」の機能拡張を発表しました。マシンラーニング・モデルを作成、トレーニング、展開するツールやリソースを提供し、データソースへの迅速な接続から SberCloud (https://www.sberbank.com/eco/sbercloud) へのモデルの自動展開までを行います。
ML Space は、AI アクセラレーションを内蔵したインテル® Xeon® スケーラブル・プロセッサーを使用して、分散学習を組織的に行うためのクラウドサービスです。そのアーキテクチャーは、SberCloud のスーパーコンピューター「Christofari」をベースにしています。Christofari は、ロシア最大のスーパーコンピューターであり、oneAPI プログラミング・モデルを採用して、ベンチマークでは 6.7 ペタフロップスのパフォーマンスを実現しています。
XPU 時代、特に AI 開発をサポートするため、ML Space は 4 つのインテル® oneAPI ツールキット (ベース・ツールキット、HPC ツールキット、AI アナリティクス・ツールキット、OpenVINO™ ツールキット) を追加します。
詳細 (英語)
PING 社がインテル® Xeon® プロセッサーとインテル® oneAPI ツールを使用してゴルフ用品のイノベーションを推進
2021年5月19日 | インテル® Xeon® スケーラブル・プロセッサー、インテル® oneMKL (英語)、インテル® MPI ライブラリー
世界的に有名なゴルフ用品メーカーである PING 社が、ハイパフォーマンス・コンピューティング (HPC) を採用した設計戦略により、製品ラインのイノベーションを促進するため、インテル、Altair、Dell Technologies と提携しました。この提携により、PING 社は、設計サイクルの時間短縮、製品性能のばらつきの低減、市場投入までの時間を遅らせることなく品質の向上を実現して、シミュレーション速度を 4.5 倍向上しました。
PING 社がインテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) とインテル® MPI ライブラリーを活用して、インテル® Xeon® スケーラブル・プロセッサー上のアプリケーションの効率と品質を向上させた成功事例 (英語) をご覧ください。
また、PING 社とインテルが HPC と AI を連携させて完璧なゴルフクラブを見つけた様子を紹介したビデオ [2:43] (英語) もご覧ください。
oneAPI 1.1 暫定仕様を公開
2021年5月13日 | oneAPI 業界仕様 (英語)
インテル コーポレーションのデベロッパー・ソフトウェア担当バイスプレジデント兼ゼネラル・マネージャーの Sanjiv Shah が oneAPI 1.1 暫定仕様リビジョン 1 (英語) の公開を発表しました。
AI、レンダリング、メディアでの新たなユースケースを可能にする、以下のような新機能が追加されています。
- 高度なレイトレーシング。ソフトウェア開発者は、複数のベンダーのシステムやアクセラレーターを使用して、高忠実度のレイトレース計算を行うことができます。
- oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (oneDNN)。ディープラーニングの計算グラフをコンパイルして実行するグラフ API が oneDNN に追加されました。
- oneAPI ビデオ・プロセシング・ライブラリー (oneVPL)。利用可能なメディア・コンポーネント間でワークロードを効率良く分割するハイパーエンコード・モードが oneVPL に追加されました。
- 言語の進化。最新の SYCL* 仕様に含まれる新機能の大部分は、データ並列 C++ (DPC++) 言語の拡張機能が占めています。
アップデートの詳細 (英語)
インテル® oneAPI ツールキット 2021.2 リリース
2021年4月2日 | インテル® oneAPI、インテル® oneAPI ツールキット (英語)
2020年末に製品版がリリースされたインテル® oneAPI ツールキットの Update 1 がリリースされました。計算、AI、メディア、レイトレーシング、HPC などに、さらなるパフォーマンスと新しい機能を提供します。インテル® oneAPI ツールキットは、現在入手可能な oneAPI イニシアチブ準拠のツール (コンパイラー、ライブラリー、最適化フレームワーク、アナライザー、デバッガ) の中で、最も完全で多様なセットです。
主な新機能:
AI および HPC
- AI 向けには、XGBoost と scikit-learn のパフォーマンスが大幅に強化され、さらに Tensorflow* とPyTorch* 向けのインテルの最適化もアップグレードされています。
- インテル® MPI ライブラリーのコンテナーサポートが拡張され、Mellanox* OFED サポートが更新されました。
- インテル® Advisor のオフロードのモデル化と GPU ルーフライン機能のソースビュー解析が拡張されました。
- インテル® VTune™ プロファイラーにプラットフォーム・ダイアグラムが追加されました。入力および出力解析の新しい開始点として使用して、システム・トポロジーや、PCIe* デバイス、インテル® ウルトラ・パス・インターコネクト (インテル® UPI)、メモリーを含むハードウェア・リソースの高レベルの利用率メトリックを提供します。
メディア、レイトレーシング、レンダリング
- VDB マルチアトリビュート・ボリューム・サポート、高速な構造および VDB ボリュームサンプル、構造、VDB、非構造ボリュームの高速インターバル・イテレーション。
- 拡張されたノイズ除去ライブラリーで指向性ライトマップと Apple Silicon がサポートされました。
- ライブラリー GUI では、Lights エディターの改善によりシーンのライティングが容易になり、gITF ローダーがトライアングル・メッシュ、ライト、マテリアル、テクスチャーのアニメーションとスキニングに対応し、シーンファイルのロードとセーブが向上しています。
- 高速なトランスコードやストリーミングなどのメディアサポート。
hipSYCL が SYCL* 2020 & oneAPI DPC++ 機能をサポート
2021年2月23日 | DPC++ (英語)、インテル® oneAPI
oneAPI 研究拠点のハイデルベルク大学 (英語) が hipSYCL 0.9.0 に関するブログ記事を投稿しました。hipSYCL 0.9.0 では、SYCL* 2020 仕様の次の機能がサポートされます。
- 統合共有メモリー
- 並列リダクション
- サブグループ
- ワークグループおよびサブグループ・プリミティブ
- その他
これらの機能は、より細かなハードウェア制御、より柔軟な使用パターン、そしてプログラマーにとっては冗長性の軽減をもたらします。これにより、開発者は DPC++ で SYCL* 2020 の機能を使用してコードを記述できるだけでなく、例えば AMD の GPU をターゲットにする必要がある場合、hipSYCL にシームレスに移行できます。詳細は、こちら (英語) を参照してください。
oneAPI 仕様で提案されている高度なレイトレーシング API
2021年2月17日 | oneAPI 仕様 (英語)
「oneAPI 仕様への追加が検討されている現在公開中の一連の高度なレイトレーシング API について、皆様のご意見をお寄せください。」
インテル コーポレーション
シニア主席エンジニア兼インテル・アドバンスト・レンダリング & ビジュアライゼーション・アーキテクチャー シニア・ディレクター
Jim Jeffers
Jim の最新のブログ (https://www.linkedin.com/pulse/advanced-ray-tracing-apis-proposed-oneapi-jim-jeffers/) では、レイトレーシング計算の分野でロバストで効率的な開発を促進するため、開発者がフィードバックを送ることができるこの機会について詳しく述べています。oneAPI 仕様にレイトレーシング機能を追加することで、業界全体のソフトウェア開発者が、複数のベンダーのシステムやアクセラレーターにまたがる高忠実度のレイトレーシング計算を「一度記述する」だけで済むようになります。
開発者の皆さんからのフィードバックとコラボレーションを GitHub* リポジトリー (英語) までお寄せください。
Demetics がインテル® oneAPI 製品を使用して AI アルゴリズムを保護
2021年2月15日| インテル® oneMKL (英語)、インテル® SGX
Demetics Medical Technology Co. Ltd. は、インテル® ソフトウェア・ガード・エクステンション (インテル® SGX) とインテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) (英語) を使用して、エッジの医療用人工知能 (AI) アルゴリズムと医療機器の知的財産 (IP) を保護しています。中国における AI ベースの超音波検査のパイオニアである Demetics 社は、独自に開発したディープラーニング・フレームワーク「DE-Light」の採用を加速させ、オープンソース・フレームワークでの甲状腺結節の検出精度を 30~40% 向上させ、優れた性能を実現しました。1
記事を読む (https://newsroom.intel.com/news/demetics-protects-ai-based-medical-innovation-intel-sgx/)
インテル® oneMKL を含むインテル® oneAPI ベース・ツールキット (英語) のダウンロード
1 テスト結果は Demetics 社による社内評価を引用したものです。詳細は、Demetics 社までお問い合わせください。
SYCL* 2020 最終仕様書で oneAPI データ並列 C++ 機能を採用
2021年2月9日 | oneAPI 仕様 (英語)、SYCL* 仕様 (英語)、DPC++ (英語)
高度な相互運用性規格を作成する、業界をリードする企業によるオープン・コンソーシアムである The Khronos Group (英語) は、シングルソースの C++ 並列プログラミングのオープン標準である SYCL* 2020 最終仕様書 (英語) の公開を発表しました。SYCL* 2020 は、長年の仕様開発を包含する重要なマイルストーンであり、SYCL* 1.2.1 の機能をベースに構築され、プログラマビリティーの向上、コードサイズの縮小、およびパフォーマンスの向上を実現しています。SYCL* 2020 は C++17 をベースにしており、標準 C++ アプリケーションの高速化を容易にし、ISO C++ ロードマップとの緊密な連携を可能にします。SYCL* 2020 最終仕様書 (英語) には、oneAPI データ並列 C++ (DPC++) 機能が追加されています。
2019年の発表以来、DPC++ は大幅に進歩し、oneAPI 開発拠点からクロスアーキテクチャーとクロスベンダーのサポートを得て、現在は業界標準へ機能をアップストリームしています。オープンなコミュニティー・ベースの DPC++ の開発において、インテルは SYCL* のプログラミング抽象化の改善に大きく貢献をしています。新しい機能は、CPU、GPU、FPGA、AI などの広範な XPU アーキテクチャーでの HPC、マシンラーニング、組込みコンピューティング、および計算集約型アプリケーションのヘテロジニアス並列プログラミングを加速します。
記事を読む: https://newsroom.intel.com/articles/oneapi-dpc-features-2020-final-spec/
Khronos のプレスリリースを読む (英語)
インテル® Embree がアカデミー賞を受賞
2021年2月2日 | インテル® oneAPI レンダリング・ツールキット (英語)、インテル® Embree レイトレーシング・ライブラリー (英語)
 映画芸術科学アカデミー (AMPAS) は、インテル® Embree レイトレーシング・ライブラリー (インテル® oneAPI レンダリング・ツールキット (英語) のコンポーネント) に科学技術賞 (英語) を授与しました。毎年アカデミー賞を主催している映画芸術科学アカデミー (AMPAS) は、インテル® Embree の業界をリードするジオメトリー・レンダリングのレイトレーシングを、映画製作プロセスにおける革新的な貢献として表彰しました†。
映画芸術科学アカデミー (AMPAS) は、インテル® Embree レイトレーシング・ライブラリー (インテル® oneAPI レンダリング・ツールキット (英語) のコンポーネント) に科学技術賞 (英語) を授与しました。毎年アカデミー賞を主催している映画芸術科学アカデミー (AMPAS) は、インテル® Embree の業界をリードするジオメトリー・レンダリングのレイトレーシングを、映画製作プロセスにおける革新的な貢献として表彰しました†。
詳細は https://newsroom.intel.com/news/intel-embree-wins-academy-scientific-technical-award をご覧ください。インテル® Embree はインテル® oneAPI レンダリング・ツールキット (英語) の一部として無料でダウンロードできます。
インテル® Embree が採用されている映画の例:
- ヒックとドラゴン 聖地への冒険
- レゴバットマン ザ・ムービー
- ネクスト ロボ
- ペット 2
- アベンジャーズ/インフィニティ・ウォー
- グリンチ
- ほか多数
†受賞者: Sven Woop、Carsten Benthin、Attila Afra、Manfred Ernst、Ingo Wald、およびインテル コーポレーション アドバンスト・レンダリング & ビジュアライゼーション シニア・ディレクター Jim Jeffers。
2020年
インテルが XPU ソフトウェア開発向けインテル® oneAPI ツールキットをリリース
2020年12月8日 | インテル® oneAPI ツールキット (英語)、インテル® デベロッパー・クラウド (英語)
 「インテル® ソフトウェア開発ツールが CPU から GPU や FPGA に拡張されたことは、XPU への道のりにとって重要なマイルストーンと言えます。oneAPI 業界イニシアチブは、独自のプログラミング・モデルに代わる、オープンな統一されたクロスアーキテクチャー・プログラミングをエコシステムにもたらします。インテル® oneAPI ツールキットとインテル® DevCloud は、分散型インテリジェンス時代への進歩を加速させるために必要なツールを提供します。」
「インテル® ソフトウェア開発ツールが CPU から GPU や FPGA に拡張されたことは、XPU への道のりにとって重要なマイルストーンと言えます。oneAPI 業界イニシアチブは、独自のプログラミング・モデルに代わる、オープンな統一されたクロスアーキテクチャー・プログラミングをエコシステムにもたらします。インテル® oneAPI ツールキットとインテル® DevCloud は、分散型インテリジェンス時代への進歩を加速させるために必要なツールを提供します。」
インテル コーポレーション
アーキテクチャー、グラフィックス & ソフトウェア・グループ
チーフ・アーキテクト兼シニア・バイスプレジデント
Raja Koduri
インテルは、インテルの CPU、GPU、FPGA でハイパフォーマンスなアプリケーション開発を簡素化するインテル® oneAPI ツールキット 2021.1 (英語) をリリースしました。開発ツールにおけるインテルの長年の実績と豊富な経験を標準化されたオープンなクロスアーキテクチャー・プログラミング・モデルと組み合わせることで、開発者が経済的および技術的な負担を伴う独自のプログラミング・モデルに縛られることなく、特定のワークロードに最適なハードウェアを自由に選択できるようにします。インテル® oneAPI ベース・ツールキットには、コンパイラー、パフォーマンス・ライブラリー、解析およびデバッグツール、CUDA* コードからデータ並列 C++ (DPC++) への移行を支援する互換性ツールが含まれます。HPC、AI、IoT、レンダリング向けのアドオン・ツールキットは、特殊なワークロードの高速化を支援するツールとコンポーネントを提供します。インテル® oneAPI ツールキットは、無料でダウンロード (英語) してローカルで使用することも、インテル® デベロッパー・クラウド (英語) で使用することもできます。インテル® DevCloud では、さまざまなインテルの CPU、GPU、FPGA でコードとワークロードを開発してテストできます。パッケージは、ウェブ・ダウンロード、リポジトリー、コンテナーから入手できます。
そのほかにも、以下の発表がありました。
- 商用版では、インテルのテクニカル・コンサルティング・エンジニアによるサポートを世界中から受けることができます。既存のインテル® Parallel Studio XE とインテル® System Studio は、インテル® oneAPI 製品に移行します。インテル® oneAPI 製品は上位互換であり、現在のすべての機能に加えて、新しい機能とツールを備えています。
- oneAPI エコシステムの進展: ニジニ・ノヴゴロドのロバチェフスキー大学 (UNN) が、oneAPI クロスアーキテクチャー・プログラミングにより、CPU、GPU、その他のアクセラレーターを利用して現代物理学の研究を促進する新たな oneAPI 研究拠点 (CoE) の開設を発表 (英語) しました。
- oneAPI エコシステム・サポート: 60 以上の主要な研究機関、企業、大学が oneAPI イニシアチブをサポートしており、インテル® oneAPI ツールキットを使用して成功を収めているものもあります。詳細は、賛同者の声 (英語) を参照してください。最新の oneAPI アプリケーション・カタログ (英語) には、oneAPI を利用した 240 以上のアプリケーションの詳細が記載されています。
ニジニ・ノヴゴロドのロバチェフスキー大学が oneAPI を使用して量子プロセスの研究を高速化
2020年12月8日 | oneAPI イニシアチブ (英語)
ニジニ・ノヴゴロドのロバチェフスキー大学 (UNN) が、oneAPI クロスアーキテクチャー・プログラミングにより、CPU、GPU、その他のアクセラレーターを利用して現代物理学の研究を促進する新たな oneAPI 研究拠点 (CoE) の開設を発表しました。新しいセンターは、ヘテロジニアス・アーキテクチャー上でハイパフォーマンス・コンピューティング (HPC) を必要とする研究課題に取り組むとともに、次世代の科学者を育成するためのソフトウェア・カリキュラムを拡充することを目的としています。
詳細は、こちら (英語) を参照してください。

2020年12月にインテル® oneAPI ツールキットを出荷開始
インテル® oneAPI ツールキットは開発者がアーキテクチャーを超えて自由にコードを記述し、XPU 時代のコンピューティングを高速化できるように支援
2020年11月11日 | インテル® oneAPI、oneAPI イニシアチブ (英語)

インテルは、標準化されたソフトウェア抽象化により、さまざまなアーキテクチャーの組み合わせに多様なワークロードを素早く展開できるようにする取り組みにおいて、以下を含む重要なマイルストーンを発表しました。
- 12月にインテル® oneAPI ツールキット (英語) を出荷開始
- インテルのハードウェアとソフトウェアを組み合わせた設計アプローチの一環として、ソフトウェア・スタックに新たな追加された機能
- 高密度、低レイテンシーの Android* クラウドゲームやメディア・ストリーミング向けに設計された、Xe-LP マイクロアーキテクチャー・ベースのインテル初のデータセンター向けディスクリート GPU 「インテル® サーバー GPU」のデビュー
これらのマイルストーンは、AI から HPC、グラフィックスに至るまで、専門的なワークロードの増加に対応するハードウェアとソフトウェア・ソリューションを提供する上で重要です。詳細は、https://newsroom.intel.com/news/intel-xpu-vision-oneapi-server-gpu/ を参照してください。
インテル® oneAPI ツールキット: 新機能
インテルの CPU、GPU、FPGA をサポートするインテル® oneAPI ツールキットは 12月に出荷され、ローカルおよびインテル® DevCloud で無料で利用できます。このツールキットは、開発者がターゲット・ハードウェアの潜在的なパフォーマンスを発揮し、ソフトウェアの開発と保守コストを軽減するのに役立つだけでなく、独自のベンダー固有のソリューションと比較して、高速化されたコンピューティングのデプロイに伴うリスクを軽減します。インテル® oneAPI ツールキットは、インテルの CPU 開発ツールの豊富な経験を基に構築され、XPU に拡張されています。そのほかにも、以下の発表がありました。
- インテルのテクニカル・コンサルティング・エンジニアによるワールドワイドなサポートを含むインテル® oneAPI ツールキットの商用版。既存のインテル® Parallel Studio XE とインテル® System Studio は、インテル® oneAPI 製品に移行します。
- oneAPI エコシステムの進展 – イリノイ大学ベックマン先端科学技術研究所が新たな oneAPI 研究拠点を開設 (英語)、Microsoft* Azure*、TensorFlow* などが oneAPI を支持
- インテル® DevCloud に新しいインテル® Xe GPU ハードウェアが追加され、パブリック・アクセス向けのインテル® Iris® Xe MAX グラフィックスと、一部の開発者向けのインテル® Xe-HP が利用可能に
詳細は、「インテル® oneAPI 製品: 12月にリリース」 (https://techdecoded.intel.io/resources/intel-oneapi-products-gold-release-coming-in-december) ブログ | 「インテル® oneAPI ファクトシート」 (https://newsroom.intel.com/wp-content/uploads/sites/11/2020/11/intel-oneapi-product-fact-sheet.pdf) を参照してください。
イリノイ大学が NAMD に oneAPI クロスアーキテクチャー・プログラミング・モデルを導入
2020年11月11日 | oneAPI イニシアチブ (英語)
イリノイ大学ベックマン先端科学技術研究所は、ライフサイエンス・アプリケーション NAMD に oneAPI プログラミング・モデルを導入し、新たなヘテロジニアス・コンピューティング環境を追加するため、新しい oneAPI 研究拠点の設立を発表 (英語) しました。大規模な生体分子システムをシミュレーションする NAMD は、COVID-19 のような現実世界の課題に取り組むのに役立っています。
SC 2020 でお会いしましょう
2020年11月6日 | oneAPI @ SuperComputing 2020 (英語)、oneAPI イニシアチブ (英語)、DPC++ (英語)
間もなく SC 2020 が開催されます。統一された標準ベースのモデルを介してヘテロジニアス・プログラミングを簡素化する oneAPI イニシアチブに関する取り組みの進捗状況を、コミュニティーの皆さんと共有できることを楽しみにしています。
oneAPI、DPC++、SYCL*、OpenMP*、MPI に加えて、パフォーマンス・チューニングやビジュアライゼーション・ツールなど、幅広いトピックをカバーします。技術的な話から詳細なワークショップ、デモやライブチャットまで、この 2 週間さまざまな方法で皆さんと交流できることを楽しみにしています。詳細は、こちら (英語) を参照してください。
インテル® oneAPI beta10 リリース
2020年10月27日 | インテル® oneAPI、インテル® VTune™ プロファイラー、インテル® DPC++/C++ コンパイラー (英語)、インテル® OSPRay Studio (英語)
間もなく発表予定の Gold 製品のリリースに向けて、beta10 では次の機能が追加/強化されています。
- インテル® VTune™ プロファイラーを使用して、DPC++ と OpenMP* の両方でオフロードコストをプロファイルして、パフォーマンスを低下させるメモリー転送を検出できます。
- インテル® VTune™ プロファイラーで CPU の電力解析を行い、スロットリングの問題をデバッグしたり、ワットあたりの FLOPS をチューニングできます。GPU 電力解析も近日中に実装される予定です。
- インテル® ディストリビューションの Modin と完全な機能互換性を保持しつつ、pandas API の 95% を並列化します。OmniSci バックエンドは、ノードあたり 6TB のインテル® Optane™ メモリーを追加して、大規模なデータを効率良くスケーリングし、手動でクラスターを生成することなくローカルのノートブックからクラウドへシームレスに拡張します。
- SYCL* とインテル® GPU サポートにより高速化されたネイティブ・ライブラリーと NumPy* 形式の API である Data Parallel NumPy* (dpnp) の初期リリースは、Python* の数学コードを高速化します。
- サポートベクトル分類 (SVC)、ランダムフォレスト、K 近傍法分類器を含む scikit-learn アルゴリズムの追加の最適化により、インテル® CPU 上でのモデル適合と予測を高速化します。
- XGBoost と LightGBM からトレーニング済みのモデルを変換し、daal4py ライブラリーを使用してインテル® CPU 上でモデルの予測を高速化します。
- インテル® oneAPI DPC+/C++ コンパイラーを使用して、インライン CPU アセンブリーと GPU 仮想命令セットコードを混在させることができます。
- 直感的なインターフェイスを備えたシーングラフ・アプリケーションである新しいインテル® OSPRay Studio を使用して、高忠実度の、レイトレースされた、インタラクティブな、リアルタイム・レンダリングを実行できます。
インテル® oneAPI をぜひお試しください (英語)。beta10 は、インテル® デベロッパー・クラウド (英語) で利用することも、インテル® oneAPI ページからダウンロードすることも、コンテナーやリポジトリー経由で入手することもできます。
追加のインテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) オープンソース・インターフェイス
2020年10月9日 | oneMKL インターフェイス (英語)、インテル® oneMKL (英語)
インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) のオープンソース・インターフェイスは拡大を続けており、開発者は複数のベンダーのアーキテクチャーで実行される移植性の高い演算集約型アプリケーションを効率良くコーディングできます。今年初めにリリースされたインテル® oneMKL の密線形代数 BLAS ドメインのインターフェイスに加えて、インテル® oneMKL の乱数ジェネレーター (RNG) ドメインのインターフェイスが追加されました。この新しいインターフェースは、モンテカルロ・シミュレーション、財務予測、リスク管理、暗号、その他のアプリケーションでよく使用される、連続分布と離散分布の疑似乱数や非決定論的エンジンを実装するルーチンを提供し、一般的な数学関数を幅広くカバーします。
追加のクロスアーキテクチャー、クロスベンダー・ハードウェアをサポートするため、oneAPI パートナーは、ダウンロード可能なこれらのインターフェイスを使用することを推奨します。詳細は、https://techdecoded.intel.io/resources/now-available-additional-oneapi-open-source-math-library-interfaces を参照してください。
ハイデルバーグ大学コンピューティング・センター (URZ) が oneAPI 研究拠点を開設
2020年9月29日 | oneAPI イニシアチブ (英語)、インテル® DPC++ (英語)
ハイデルバーグ大学コンピューティング・センターは、AMD* GPU、NVIDIA* GPU、および CPU ベースのシステムをサポートする hipSYCL に高度なデータ並列 C++ (DPC++) 機能を追加することを目的とした oneAPI 研究拠点 (英語) の開設を発表しました。
oneAPI のクロスアーキテクチャー言語である DPC++ は、生産性が高く、可読性に優れており、学習しやすく、開発者がベンダー固有の言語やツールに強制されることなくアクセラレーターのパフォーマンスを引き出すのに役立ちます。新しい DPC++ 拡張機能は SYCL* 2020 暫定仕様の一部であり、hipSYCL や対応プラットフォームに統合共有メモリーなどの機能をもたらします。この研究拠点は、ソフトウェア・コミュニティーがこの機能を実現するための大きな一歩を提供し、生産性とパフォーマンスの両方を備えたクロスアーキテクチャー、クロスベンダーのプログラミング・ソリューションを作成する oneAPI 業界イニシアチブを促進します。
詳細は、こちら (英語) を参照してください。
oneAPI v1.0 仕様リリース
2020年9月28日 | oneAPI イニシアチブ (英語)
oneAPI v1.0 仕様 (英語) がリリースされました。これにより、容易にアクセラレーター・プログラミングを取り入れて、データ集約型ワークロードに対応できるようになりました。今回のリリースは、産官学の第一線で活躍するテクノロジストによる 1 年間の取り組みの集大成であり、クロスアーキテクチャー開発のオープンな道を切り開くものです。
本仕様は、言語に加えて、数学ライブラリー、ディープラーニングおよびマシンラーニングのインターフェイス、ビデオ解析 API、低レベルのハードウェア抽象化インターフェイスやランタイム API など、アクセラレーターにより利点が得られる多くのドメインをカバーしています。誰でも利用でき、任意のプログラムに移植可能なオープンソース・スタックが公開されています。詳細は、デベロッパー・ソフトウェア・エンジニアリング・マネージャーの Sanjiv Shah の投稿 (英語) を参照してください。
次世代のアクセラレーター・ソフトウェアに影響を与えたり、多種多様なアクセラレーター向けの新しい言語を開発したり、oneAPI 準拠のツールを開発したり、ハードウェアに接続してこのソフトウェア・スタックを活用したいと考えている方は、仕様書や GitHub* (英語) 上のオープンソース実装にぜひ貢献してください。
インテル® oneAPI beta09 リリース
2020年9月14日 | インテル® oneAPI、DPC++ (英語)、インテル® oneMKL (英語)、インテル® oneVPL (英語)、インテル® Advisor、インテル® VTune™ プロファイラー
今回のリリースでは、今年後半に予定されている Gold リリース に向けて、多数のツール (コンパイラー、ライブラリー、および解析ツール) に加えて、DL フレームワークをサポートするインテル® Low Precision Optimization、インテル® Advisor の GPU ルーフライン解析、インテル® oneAPI ビデオ・プロセシング・ライブラリーでの H.264 & MJPEG ソフトウェア・デコード/エンコードのサポートが追加されています。
詳細:
- 今年後半に予定されている Gold リリースに向けて、すべてのコンパイラー、ライブラリー、ツールのパフォーマンスと安定性が向上しました。
- インテル® AI アナリティクス・ツールキットに、複数のディープラーニング・フレームワークをサポートする統一された低精度推論インターフェイスである、インテル® Low Precision Optimization Tool が追加されました。FP32 モデルを int8 や Bfloat16 に簡単に変換したり、精度を重視したチューニング戦略を活用したり、パフォーマンス、モデルサイズ、およびメモリー使用を最適化できます。
- インテル® Optimization for PyTorch* とインテル® oneAPI コレクティブ・コミュニケーション・ライブラリー (インテル® oneCCL) の連携により、CPU 上で効率良い分散トレーニングが可能になりました。モデルデータ型の自動混合精度もサポートされました。
- インテル® Advisor の新しいテクニカルプレビュー機能では、GPU ルーフライン解析とオフロード・アドバイザーが統合されたユーザー・インターフェイス・ワークフローとツールバーや、オフロード・アドバイザーでデータ転送の最適化に関する推奨事項を利用できるようになりました。
- インテル® VTune™ プロファイラーでは、遅い MMIO 書き込みが行われた場所を特定するように改善された I/O 分析を使用して、パフォーマンスを低下させる I/O 書き込みが発生するモジュールを見つけることができます。
- インテル® VTune™ プロファイラーで FPGA の各計算ユニットのストールとデータ転送に関する情報を収集し、より少ない推測で FPGA ソフトウェア・パフォーマンスを最適化できます。
- インテル® MPI ライブラリーでは、GPU プログラミングがサポートされ、Mellanox * ファブリック上の独立した MPI ジョブの連結が可能になりました。
- インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) に、RNG 移動オペレーター、LAPACK バッファー、ポインターベース (統合共有メモリー) インターフェイスを含む、CPU および GPU 向けの DPC++ 関数が追加されました。
- インテル® oneAPI ビデオ・プロセシング・ライブラリー (インテル® oneVPL) に、H.264 & MJPEG ソフトウェア・デコード/エンコード、ビデオの前処理 (サイズ変更、色変換、クロップ関数を含む)、および内部割り当てバッファーのサポートが追加されました。
- Python* 向けインテル® ディストリビューションでは、Numba 関数内のデータ並列カーネルの GPU 自動オフロードと、scikit-image 変換関数とフィルターの最適化のマルチスレッド化が Windows* でサポートされました。
インテル® oneAPI をぜひお試しください (英語)。beta09 は、インテル® デベロッパー・クラウド (英語) で利用することも、インテル® oneAPI ページからダウンロードすることも、コンテナーやリポジトリー経由で入手することもできます。
未来のレイトレーシング・ソリューションを開発
2020年8月24日 | インテル® oneAPI、RenderKit (英語)、インテル® デベロッパー・クラウド (英語)
インテルは、コンピューター・グラフィックスの世界的なイベントである SIGGRAPH 2020 において、インテル® oneAPI レンダリング・ツールキット (英語) の新機能を発表し、ハードウェア、メモリー、ネットワーク、およびソフトウェア・テクノロジーを含む、インテルの強力なレイトレーシング・プラットフォームを活用した顧客の成功事例を発表しました (プレスリリース全文は https://newsroom.intel.com/news/siggraph-2020-intel-oneapi-rendering-toolkit-unleashes-film-fidelity/#gs.ec01ex)
以下は、インテル® oneAPI レンダリング・ツールキットのレイトレーシングとレンダリング向け新機能の一部です。
- インテル® OSPRay Studio – 高忠実度のレイトレーシングされた、インタラクティブなリアルタイム・レンダリングを実現するシーン・グラフ・アプリケーションです。3Dモデルや時系列の複数のフォーマットを可視化する機能を提供します。インテル® OSPRay とほかのインテル® レンダリング・ライブラリー (インテル® Embree、インテル® Open Image Denoise など) を組み合わせて作成されており、信頼性の高いサイエンティフィック・ビジュアライゼーションと写実的なレンダリングに使用されます。2020年後半にリリース予定です。
- インテル® OPSRay for Hydra – アニメ映画や 3D CAD/CAM モデリング向けのビューポートにフォーカスしたインターフェイスを備えた、高忠実度のスケーラブルなレイトレーシング・パフォーマンスとリアルタイム・レンダリングを提供する、Universal Scene Description (USD) Hydra API に準拠したレンダラーです。
- インテル® DevCloud for oneAPI デスクトップ可視化機能 – リモート・デスクトップを介して、レンダリングを可視化して反復処理を行い、リアルタイムでインタラクティブなアプリケーションを作成する、新しいビジュアル開発機能。インテル® oneAPI レンダリング・ツールキットを使用して、最新のインテル® ハードウェア (CPU、GPU、FPGA) で可視化パフォーマンスを最適化し、ワークロードを評価できます。インストール、セットアップ、設定が不要な無料のアクセスを利用できます。興味のある方は、http://software.intel.com/DevCloud/oneAPI/sign-up からサインアップできます。
SIGGRAPH 2020 のウェブサイト (https://software.intel.com/content/www/us/en/develop/events/siggraph.html) で、インテルや Tangent Studios、Chaos Group、Bentley Motors などの業界リーダーによる SIGGRAPH デモ、技術セッション、講演をご覧ください。
LAIKA Studios とインテルが共同でストップモーション映画制作の可能性を拡大
2020年8月11日 | インテル® oneAPI、インテル® AI アナリティクス・ツールキット (英語)、インテル® oneAPI レンダリング・ツールキット (英語)、インテル® デベロッパー・クラウド (英語)
 Laika Studios とインテルの Applied Machine Learning チームは、ストップモーション・アニメーションの無限の可能性を実現するために協力しています。制作技術ディレクターの Jeff Stringer 氏と視覚効果監修者の Steve Emerson 氏が、インテル® oneAPI ツールを使用して AI の力を映画に取り入れる方法について述べます。
Laika Studios とインテルの Applied Machine Learning チームは、ストップモーション・アニメーションの無限の可能性を実現するために協力しています。制作技術ディレクターの Jeff Stringer 氏と視覚効果監修者の Steve Emerson 氏が、インテル® oneAPI ツールを使用して AI の力を映画に取り入れる方法について述べます。
- 視聴する (英語) [2:38 分]
- 記事を読む (英語) [4 分]
- インテル® oneAPI ツールに関する情報 (https://software.intel.com/oneapi) ー インテル® DevCloud でコードを試す方法を含む
インテル® oneAPI beta08 リリース
2020年7月31日 | インテル® oneAPI、インテル® oneVPL (英語)、インテル® oneTBB (英語)、インテル® oneAPI レンダリング・ツールキット (英語)、インテル® VTune™ プロファイラー、インテル® Advisor
本リリースでの変更点は、分散 (および高速) データ・アナリティクス前処理向けインテル® Distribution of Modin and OmniSci の導入、インテル® oneAPI レンダリング・ツールキットでの最大 4 倍のレンダリング・スピードアップと粒子体積のサポート、迅速な初期解析を提供するインテル® VTune™ プロファイラーのパフォーマンス・スナップショット・プロファイル、インテル® Advisor のメモリーレベルのルーフライン解析、インテル® oneAPI ビデオ・プロセシング・ライブラリーの H.265 および AV1 CPU ソフトウェア・コーデック、および、インテル® oneAPI スレッディング・ビルディング・ブロックの NUMA の最適化機能などです。
詳細:
- インテル® oneAPI ビデオ・プロセシング・ライブラリー (インテル® oneVPL) のメジャー・アップデート。H.265 および AV1 CPU ソフトウェア・コーデック、インテル® メディア SDK との上位互換性などが含まれます。
- インテル® oneAPI スレッディング・ビルディング・ブロック (インテル® oneTBB) のメジャー・アップデート。詳細な NUMA アフィニティー管理機能や最新の C++ との整合性などが含まれます。
- インテル® oneAPI DPC++ コンパイラーの CPU アーキテクチャー向けのコード・パフォーマンスが向上しました。
- インテル® VTune™ プロファイラーでは、OpenMP* オフロードプラグマに対応したメトリックの追加により、GPU アクセラレーターの解析が改良されました。また、最初のプロファイル・ステップとして、パフォーマンス・スナップショットが追加され、最も大きな最適化の機会を特定するため詳細な解析 (メモリー、スレッドなど) を提案します。
- インテル® Advisor にメモリー階層 (L1、L2、L3、または DRAM) のボトルネックをピンポイントで特定するメモリーレベルのルーフライン解析が追加されました。
- インテル® C++ コンパイラーに OpenMP* 5.0 の GPU オフロードの初期サポートが追加されました。
- Anaconda* チャネル (英語) でリリースされているインテル® Distribution of Modin の導入により、インテル® AI アナリティクス・ツールキットのデータ・アナリティクス・ワークフローが大幅に拡張されました。pandas と同一の API を持つこのインテリジェントな分散型データフレーム/ライブラリーを使用して、複数のノード間でデータの前処理をシームレスにスケーリングします。バックエンドでは、既存および最新のインテル® ハードウェアの計算処理能力を活用するように最適化された、エンドツーエンド分析のためのパフォーマンス・フレームワークである OmniSci がサポートしています。
- インテル® AI アナリティクス・ツールキットも PyTorch* 1.5 にアップグレードされ、Bfloat16 データ型と最新の第 3 世代インテル® Xeon® スケーラブル・プロセッサー (開発コード名 Cooper Lake) をサポートしています。
- Python* 向けインテル® ディストリビューションでは、Linux* 上の Python*/Numba コードの GPU サポートが追加され、Python* Data Parallel Processing Library (PyDPPL) が導入されました。PyDPPL は、DPC++ と SYCL* 向けの軽量な Python* ラッパーで、インテル® CPU やインテル® GPU のデバイス管理機能を効率的に活用するデータ並列インターフェイスと抽象化を提供します。
- インテル® OSPRay とインテル® オープン・ボリューム・カーネル・ライブラリーに粒子体積のサポートが追加されました。さらに、インテル® OSPRay では、パノラマカメラ用のステレオ 3D モードと光源のスケーラビリティーをサポートされました。
- インテル® オープン・ボリューム・カーネル・ライブラリーとインテル® Open Image Denoise のパフォーマンスが向上し、レンダリング速度が最大 4 倍高速になり、画質が向上しました。
- インテル® Embree で光子マップがサポートされました。
- インテル® オープン・ボリューム・カーネル・ライブラリーでは、設定可能なフィルター/再構築メソッド、ストリームワイドのサンプリングと勾配 API、イテレーター割り当て API、およびストライドデータ配列もサポートされました。
- インテル® Open Image Denoise では、追加の Feature Buffers により画質が向上されました。また、新しい XTraining Code 機能とその他の改善が含まれています。
- インテル® oneAPI レンダリング・ツールキットとインテル® C++ および Fortran コンパイラー、インテル® oneAPI ベース・ツールキットのほとんどのライブラリー、および解析ツールの結果ビューアーで macOS* CPU がサポートされました。
- Singularity コンテナーが新たにサポートされました。
インテル® oneAPI をぜひお試しください (英語)。beta08 は、インテル® デベロッパー・クラウド で利用することも、インテル® oneAPI ページからダウンロードすることも、コンテナーやリポジトリー経由で入手することもできます。
リモート・コラボレーションの未来を開く Huddl.ai
2020年7月22日 | Open WebRTC Toolkit (英語)、OpenVINO™ ツールキット (英語)、インテル® oneAPI
Slack* と Zoom* と Google Drive* を合わせたような新しいビデオ・コラボレーション・プラットフォームの Huddl.ai は、元サンフランシスコ 49ers の Ronnie Lott 選手をはじめとする著名な投資家の支援を受け、インテルのハードウェアおよびソフトウェア技術を搭載しています。リモート・コラボレーションを変革し、リアルタイムのメモ共有アプリケーション、音声を検索可能なテキストに変換する自動音声認識機能、参加者に基づいて会議の議題を提案する推奨エンジンを利用して、すべての会議内容を自動的に管理します。
「リモートコラボレーションの未来は、オーディオとビデオだけではありません。ディープラーニングと高度なメディア機能を活用して、場所に関係なく問題解決をより生産的に行えるようにするソリューションが求められます。Huddl.ai は、インテル® Xeon® プロセッサー・ベースのサーバー上にクラウド・データ・プラットフォームを展開し、ビデオ会議用のインテルの Open WebRTC Toolkit と、顔とテキストを検出する oneAPI のインテル® ディストリビューションの OpenVINO™ ツールキットを統合することで、高いスケーラビリティーと革新的な AI ベースの会議体験を実現します。」— インテル コーポレーション データセンター XPU 製品 & ソリューション担当副社長 Jeff McVeigh
「Huddl.ai は、21 世紀の仮想会議プラットフォームです。Nutanix では、Huddl.ai を使用することで、全体的により良い会議体験が得られました。具体的には、会議で話し合った案件のフォローアップが増え、会議時間を効率良く利用できるようになりました。」— Nutanix 社 CIO Wendy M. Pfeiffer 氏
プレスリリースを読む (英語)
Huddl.ai の詳細 (https://www.huddl.ai/features)
ベントレーとインテルのコラボレーションがデジタル・クラフトマンシップの未来を導く
2020年7月8日 | インテル® oneAPI レンダリング・ツールキット (英語)、インテル® OSPRay (英語)、インテル® oneAPI
高級車ベントレーのオンライン・コンフィギュレーター (英語) に新型のベンテイガが追加されたことで、未来のデジタル・クラフトマンシップの基準が確立されました。このコンフィギュレーターは、インテル® oneAPI レンダリング・ツールキット (英語) のコンポーネントである インテル® OSPRay (英語) の高度なレイ・トレーシング機能により、リアルタイムで高精度の視覚化を使用して 170 万以上のイメージをレンダリングし、ベントレーの全モデルで無限のオプションを提供します。
インテル® アーキテクチャー、インテル® OSPRay への人工知能 (AI) の統合、ベントレーからのデータとフィードバックにより、コンテンツが 600% 増加したにもかかわらず、エラーの発見が 33% 改善 され、画像をこれまで以上に高速にレンダリングできるようになりました。ベントレーのコンフィギュレーターは、顧客の自動車購入体験を高めることを目的としています。
詳細: https://www.bentleymedia.com/en/newsitem/1119
テクノロジーを進化させる 2 人の女性イノベーター
2020年7月7日 | インテル® DevMesh (https://devmesh.intel.com/topics/77)、インテル® oneAPI
テクノロジーは、ユニークなニーズを持つ多様な個人のために設計されており、性別、人種、文化、宗教、性的指向、思想など、多様性に富んだコミュニティーによって構築されるのが最善です。多くの女性が科学や技術などの分野のイノベーションを進めていますが、Forbes が発表した 2020年の アメリカで最も革新的なリーダートップ100 (https://www.forbes.com/lists/innovative-leaders/) リストに含まれていた女性はたった 1 人でした。この記事では、インテル® DevCloud でインテル® oneAPI を使用してイノベーションに取り組む 2 人の女性について取り上げます。1 つのプロジェクトは、スペイン政府から資金提供を受け、Springer から出版されており、もう 1 つは、まだプロジェクトを開始したばかりです。これらはほんの一例にすぎません。どちらのプロジェクトも、有望でイノベーション精神に富んでおり、魅力的で向上心が掻き立てられるものです。
詳細: https://techdecoded.intel.io/resources/celebrating-women-innovators/
インテルが高度な oneAPI DPC++ 機能を SYCL* 2020 暫定仕様に提供
2020年6月30日 | インテル® oneAPI DPC++ コンパイラー (英語)、インテル® oneAPI
グラフィックスとコンピュートの相互運用性規格を作成する、業界をリードする企業によるオープンなコンソーシアムである Khronos Group は、新たなプログラミング抽象化についてインテルが多大な貢献をした「SYCL* 2020 暫定仕様」を発表しました。新しい機能は、HPC、マシンラーニング、および計算集約型アプリケーション向けのヘテロジニアス並列プログラミングを高速化します。
インテルのデータセンター XPU 製品 & ソリューション担当副社長の Jeff McVeigh は次のように述べています。 「SYCL* 2020 暫定仕様は、生産性が高く、使い慣れた C++ プログラミング構造により、ヘテロジニアス・コンピューティング・システムのプログラミングにおいて、短期間でパフォーマンスを達成できるように支援する重要なマイルストーンです。Khronos Group との積極的なコラボレーションにより、新しい仕様には、SYCL* 2020 に組みこまれた統合共有メモリー、グループ・アルゴリズム、サブグループなど、oneAPI のデータ並列 C++ で開発された重要な機能が含まれています。今後、SYCL* ベースのインテル® oneAPI DPC++ コンパイラー (英語) を含む インテル® oneAPI ツールキットは、オープンなクロスアーキテクチャー・プログラミングに生産性とパフォーマンスをもたらします。」
詳細は、次のリンクを参照してください。
- Khronos Group: SYCL* 2020 暫定仕様に関するプレスリリース (英語)
- インテル PR パートナーによる記事: インテルが高度な oneAPI DPC++ 機能を SYCL* 2020 暫定仕様に提供
https://newsroom.intel.com/articles/intel-contributes-advanced-oneapi-dpc-capabilities-sycl-2020-provisional-spec/ - 業界標準を推進するインテルの取り組みを紹介した記事: InsideHPC: 新しいオープンな DPC++ 拡張が SYCL* と C++ を補完 (https://insidehpc.com/2020/06/new-open-dpc-extensions-complement-sycl-and-c/)
- oneAPI Code Together ポッドキャスト: ヘテロジニアスの未来を構築するためのコラボレーション (英語、20 分) – Xilinx 社の Ronan Keryell 氏とインテルの Jeff Hammond とのインタビュー。オープン言語とプログラミング・モデルの価値、ISO C++、SYCL* 2020 暫定仕様の注目すべき点などを説明しています。
TensorFlow* による oneAPI 業界イノベーションのサポート
2020年6月24日 | インテル® oneaAPI、エコシステム・サポート (英語)
AI、マシンラーニング、データ中心のアプリケーションの成長に伴い、業界は、プロセッサー・アーキテチャーの急速なイノベーションを開発者が利用できるプログラミング・モデルを必要としています。TensorFlow* は、oneAPI 業界イニシアチブと標準ベースのオープン仕様をサポートしています。oneAPI は、TensorFlow* のモジュール設計を補完し、ハードウェア・ベンダーとソフトウェア・アーキテクチャーの選択肢を広げ、次世代アクセラレーターを迅速にサポートできるようにします。TensorFlow* は、現在インテル® Xeon® プロセッサー上で oneAPI を使用していますが、今後のインテル® アーキテクチャー上で oneAPI を使用して実行できることを楽しみにしています。
oneAPI 業界イニシアチブの詳細 (英語) とエコシステム・サポート (英語)
SeRC とインテルが oneAPI Center-of-Excellence を設立
2020年6月22日 | インテル® oneAPI、SeRC (英語)
Swedish e-Science Research Center (SeRC) は、インテル初の学術研究拠点 (COE) として oneAPI イニシアチブに対する支援を広げることを発表しました。ストックホルム大学と KTH 王立工科大学が主催のこのセンターでは、oneAPI の統合ヘテロジニアス・プログラミング・モデルを使用して、分子動力学シミュレーション向けに設計され、広く利用されている無料のオープンソース・アプリケーションである GROMACS を使用する研究を加速させます。
インテル® oneAPI beta07 リリース
2020年6月20日 | インテル® oneAPI、インテル® oneAPI AI アナリティクス・ツールキット (英語)、DPC++ (英語)
本リリースでの変更点は、インテル® AI アナリティクス・ツールキットの多くの新機能 (Model Zoo、DBSCAN および SVM アルゴリズムの GPU サポート、scikit-learn アルゴリズム向けの CPU の最適化)、DPC++ コンパイラーのパフォーマンス、言語定義、およびインテル® DPC++ 互換性ツールの向上、インテル® VTune™ プロファイラーおよびインテル® MPI ライブラリーの機能強化、およびインテル® システム・デバッガーの新機能などです。
詳細:
- インテル® AI アナリティクス・ツールキットの新しい Model Zoo。インテル® アーキテクチャー向けに最適化された一般的なオープンソースのディープラーニング・トポロジー用のトレーニング済みモデルとサンプルスクリプトが含まれます。
- インテル® AI アナリティクス・ツールキットに DBSCAN および SVM アルゴリズムの GPU サポートと、scikit-learn アルゴリズム向けの CPU の最適化が追加されました。画像処理関数を高速化する scikit-image パッケージのドロップイン置換である scikit-ipp 1.0.0、およびインテル® CPU 向けにトレーニングを高速化するように最適化された最新のヒストグラム木成長法を備えた XGBoost 1.1 リリースを含みます。
- CPU プラットフォームにおける DPC++ コンパイラーのパフォーマンスが向上しました。
- 新しい C++ 言語標準機能を使用して DPC++ 言語定義を簡素化および現代化しました。
- インテル® VTune™ プロファイラーが最新のインテル® GPU (Gen9 および Gen11 統合グラフィックス、プレリリースの Gen12 統合 GPU とディスクリート GPU) をサポートし、GPU ハードウェア・パフォーマンス・メトリックでアノテーションされた GPU メモリー階層ダイアグラムが追加されました。
- インテル® MPI ライブラリーがインテル® Xe アーキテクチャー・デバイスの GPU ピニングを初期サポートし、Mellanox ConnectX* サポートを拡張しました。
- インテル® DPC++ 互換性ツールにおける CUDA* の数学、テクスチャー、および並列ライブラリー呼び出しの移行が向上しました。
- インテル® System Debugger のターゲット接続アシスタントに新しい自動検出メカニズムが追加され、ターゲットシステムへのデバッグ接続を素早く確立できるようになりました。また、システム TraceCLI 設定サポートが拡張され、開発者は、インタラクティブ・モードとスクリプトモードのインターフェイスを容易に設定できるようになり、システム・デバッグ・サンプルにより、システムデバッグ機能の使用法を簡単に学ぶことができます。
インテル® oneAPI をぜひお試しください (英語)。Beta07 は、インテル® DevCloud で利用することも、インテル® oneAPI ページからダウンロードすることも、コンテナーやリポジトリー経由で入手することもできます。
