

この記事は、The Parallel Universe Magazine 54 号に掲載されている「The Case for OpenMP* Target Offloading」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

以前の記事では、Fortran プログラムからアクセラレーターへの計算のオフロードについて紹介しました。
- Fortran、oneMKL、OpenMP* を使用して LU 因数分解を高速化
- Fortran と OpenMP* でヘテロジニアス・プログラミングの課題を解決
- oneMKL と OpenMP* ターゲットオフロードで線形システムを解く
- Fortran の DO CONCURRENT を使用したアクセラレーター・オフロード
この記事では、アクセラレーターへのオフロードに関して、Fortran DO CONCURRENT 文と OpenMP* target 構文の長所と短所を説明します。
DO CONCURRENT 構文は ISO Fortran 2008 で追加された機能で、DO CONCURRENT ループの反復が独立していて、任意の順序で実行できる (訳注: すなわち、並列に実行できる) ことをコンパイラーに通知またはアサートします。DO CONCURRENT ループはシーケンシャルに、あるいは並列に実行でき、OpenMP* バックエンドを使用して DO CONCURRENT ループをアクセラレーターにオフロードすることもできます。アクセラレーター・オフロード機能は 2013年の OpenMP* バージョン 4.0 で追加されました。OpenMP* target ディレクティブを使用すると、プログラマーは、アクセラレーターで実行するコードの領域や、ホスト・プロセッサーとアクセラレーター間で転送するデータを指定できます。
アクセラレーター・オフロードのどちらのアプローチも、標準準拠のコンパイラーを備えた任意のシステムに移植できます。DO CONCURRENT は、簡潔な ISO Fortran 構文であるという長所があります。ただし、ISO Fortran には ISO C++ と同じいくつかの制限があります(編集者注:ヘテロジニアス並列処理に関する ISO C++ の制限については、「SYCL* の事例」を参照してください)。デバイスや不連続メモリーの概念がないため、制御フローをアクセラレーターに転送したり、ホストとデバイス間のデータ転送を制御する標準的な方法はありません。OpenMP* は、これらの制限に対処します。OpenMP* は ISO 標準ではありませんが、25年以上にわたり成熟してきたオープンな業界標準です。OpenMP* target ディレクティブは冗長であり、プログラマーがコンパイラーに並列処理であることを説明する必要がありますが、次のコード例から分かるように、ホストとデバイス間のデータ転送を細かく制御し、並列領域を集約して効率を向上させることができます。
前号の記事「Fortran の DO CONCURRENT を使用したアクセラレーター・オフロード」では、単純なフィルターをバイナリーイメージに適用したエッジ検出について説明しました。今回は、より現実的なエッジ検出アルゴリズムを比較に使用します。Fortran DO CONCURRENT と OpenMP* target ディレクティブを使用して Sobel アルゴリズムを実装します。このアルゴリズムは、オリジナルの画像の各ピクセルに水平フィルターと垂直フィルターを適用して、変換された画像内に急激なピクセル強度の変化を抽出します。
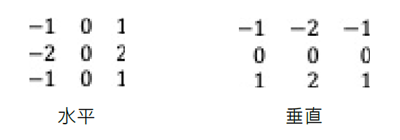
変換前と変換後の例を図 1 に示します。各ピクセルの演算は独立しているため、アルゴリズムは高度にデータ並列です。

