
この記事は、The Parallel Universe Magazine 52 号に掲載されている「Solve Heterogeneous Programming Challenges with Fortran and OpenMP*」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

急速な技術革新は、ヘテロジニアス・コンピューティングの新しい時代をもたらしています。ハードウェアの多様性と増大する計算能力の要求により、ヘテロジニアス並列処理を利用できるプログラミング・モデルが求められています。これらのモデルは、さまざまなベンダーのハードウェアでプログラムを実行できるように、オープンで、移植性に優れていなければなりません。Fortran は古い言語ですが、今でも科学や工学の分野で活発に利用されている重要なプログラミング言語です。同様に、1997年にリリースされたコンパイラー主導の並列処理のオープンな標準である OpenMP* も、ヘテロジニアス・コンピューティングをサポートするように進化し、計算をアクセラレーター・デバイスにオフロードして不連続メモリー間でデータを移動するディレクティブが含まれるようになりました。開発者は、ホストとデバイスメモリーの概念、テクスチャー/サーフェスや定数メモリーなどのより繊細なメモリータイプを、OpenMP* ディレクティブを通じて利用できます。
タスクをアクセラレーターにオフロードすると、一部の計算はより効率的になります。例えば、高度なデータ並列計算では、GPU の多くの処理要素を活用できます。この記事では、Fortran + OpenMP* がヘテロジニアス・コンピューティングの 3 つの主な課題である、アクセラレーターへの計算のオフロード、不連続メモリーの管理、ターゲットデバイス上での既存の API の呼び出し、をどのように解決するかを示します。
アクセラレーターへの計算のオフロード
最初に、簡単な例から始めましょう。リスト 1 は、OpenMP* の target、teams,および distribute parallel do 構文を使用して入れ子のループを実行する方法を示しています。target 構文はターゲットデバイス上の並列領域を作成します。teams 構文はチームのリーグ (つまり、スレッドのグループ) を作成します。この例では、チームの数は num_blocks パラメーター以下です。各チームには、block_threads 変数以下の数のスレッドがあります。各チームのプライマリー・スレッドは、teams 領域でコードを実行します。外部ループの反復は、各チームのプライマリー・スレッドに分散されます。チームのプライマリー・スレッドが distribute parallel do 構文を検出すると、チーム内のほかのスレッドがアクティブになります。チームは並列領域を実行した後、内部ループの実行をワークシェアします。この一連の処理を図式化したのが図 1 です。
program target_teams_distribute
external saxpy
integer, parameter :: n = 2048, num_blocks = 64
real, allocatable :: A(:), B(:), C(:)
real :: d_sum = 0.0
integer :: i, block_size = n / num_blocks
integer :: block_threads = 128
allocate(A(n), B(n), C(n))
A = 1.0
B = 2.0
C = 0.0
call saxpy(A, B, C, n, block_size, num_blocks, block_threads)
do i = 1, n
d_sum = d_sum + C(i)
enddo
print '("sum = 2048 x 2 saxpy sum:"(f))', d_sum
deallocate(A, B, C)
end program target_teams_distribute
subroutine saxpy(B, C, D, n, block_size, num_teams, block_threads)
real :: B(n), C(n), D(n)
integer :: n, block_size, num_teams, block_threads, i, i0
!$omp target map(to: B, C) map(tofrom: D)
!$omp teams num_teams(num_teams) thread_limit(block_threads)
do i0 = 1, n, block_size
!$omp distribute parallel do
do i = i0, min(i0 + block_size - 1, n)
D(i) = D(i) + B(i) * C(i)
enddo
enddo
!$omp end teams
!$omp end target
end subroutine
リスト 1. OpenMP* ディレクティブ (青で表示) を使用して入れ子のループをアクセラレーターにオフロード
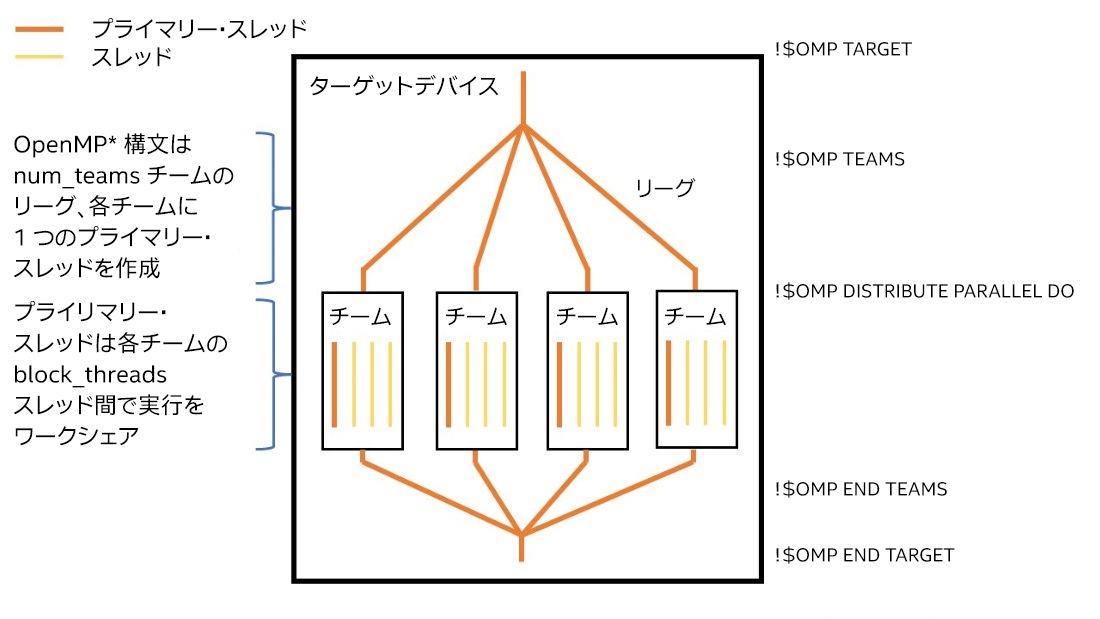
図 1. OpenMP* target、teams、および distribute parallel do 領域の概念図
ホストとデバイス間のデータ転送
次に、ホストとデバイス間のメモリー管理とデータ移動について説明します。OpenMP* には 2 つのアプローチが用意されています。1 つ目のアプローチは、data 構文を使用して、不連続メモリー間のデータをマップします。例えば、リスト 1 は、targetディレクティブの map(to: B, C) 節と map(tofrom: D) 節で配列 B、C、および D をデバイスにコピーし、デバイスから D の最終値を取得します。2 つ目のアプローチは、OpenMP* ランタイム・ライブラリー・ルーチンの 1 つ、デバイス・メモリー・アロケーターの呼び出しです。この記事では、2 つ目のアプローチは説明しません。
リスト 2 は、target data 構文で新しいデバイスデータ環境 (ターゲットデータ領域とも呼ばれる) を作成し、配列 A、B,、および C をマップしています。target data 領域は、2 つの target 領域を囲んでいます。最初の領域は、map(to: A, B) および map(from: C) データモーション節に従って囲んでいるデバイスデータ環境から A、B、および C を継承する新しいデバイスデータ環境を作成します。ホストは、1 つ目のターゲット領域が完了するのを待ってから、データ環境の A と B に新しい値を割り当てます。target update 構文は、デバイスデータ環境で A と B を更新します。2 つ目のターゲット領域が終了すると、デバイスデータ環境の終了時に C の結果がデバイスからホストメモリーにコピーされます。この一連の処理を図式化したのが図 2 です。
