
この記事は、インテル® デベロッパー・ゾーンに公開されている「Code Sample: Intel® AVX512-Deep Learning Boost: Intrinsic Functions」(https://software.intel.com/en-us/articles/intel-advanced-vector-extensions-512-intel-avx-512-new-vector-neural-network-instruction) の日本語参考訳です。
ファイル: |
ダウンロード (英語) |
| ライセンス: | 三条項 BSD ライセンス (英語) |
| 動作環境 | |
|---|---|
| オペレーティング・システム: | Linux* |
| ハードウェア: | 第 2 世代インテル® Xeon® スケーラブル・プロセッサー |
| ソフトウェア: (プログラミング言語、ツール、IDE、フレームワーク) |
インテル® C++ コンパイラー 19、インテル® Parallel Studio XE 2019 |
| 必要条件: | C++ の使用経験 |
これは、第 2 世代インテル® Xeon® スケーラブル・プロセッサーの新しいインテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) とインテル® ディープラーニング・ブースト (インテル® DL ブースト) 命令の活用方法を説明するサンプルコードです。
次のサンプルは、組込み関数を使用した新しい機能のテスト方法を示します。
インテル® AVX-512 とインテル® DL ブースト
第 2 世代インテル® Xeon® スケーラブル・プロセッサーには、ベクトル・ニューラル・ネットワーク命令 (VNNI) を含む、インテル® DL ブーストと呼ばれる新しいインテル® AVX-512 拡張命令が含まれています。この命令は整数線形代数のスループットを向上するように設計されたもので、2 つの 8 ビット (または 16 ビット) 整数の乗算を行って 32 ビット整数変数に結果を累算する一部の畳み込みニューラル・ネットワーク (CNN) のループを高速化します。
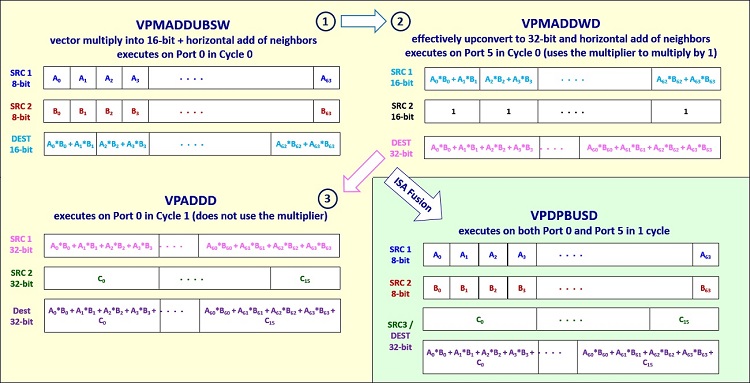
VNNI 機能は、低い精度 (8 ビットおよび 16 ビット) の乗算と 32 ビット累算を行う融合命令を含みます。この命令は、インテル® AVX-512 の積和演算 (FMA) 命令の一部である 3 つの命令シーケンスを置換します。図 1 は、新しい VNNI VPDPBUSD 命令が 3 つの FMA 命令 (VPMADDUBSW、VPMADDWD、および VPADDD) をどのように置換するかを示しています。
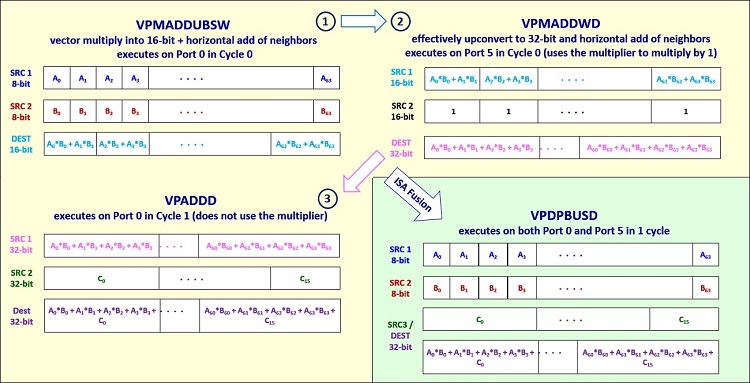
図 1. インテル® AVX-512 のインテル® DL ブースト命令 VPDPBUSD は、8 ビット乗算と 32 ビット累算を行う
3 つの個別の FMA 命令 (VPMADDUBSW、VPMADDWD および VPADDD) を置換します。
画像の出典: Israel Hirsh および Bob Valentine。
インテル® AVX-512 のインテル® DL ブースト融合命令と FMA ベースの命令の詳細な説明、および理論上のピーク計算ゲインは、「低い数値精度でのディープラーニングのトレーニングと推論」を参照してください。
サンプルコード
このサンプルコードは、インテル® AVX-512 の組込み関数を使用した VNNI 融合命令と 3 つの等価な FMA ベースの命令の利用方法を示します。
インテル® AVX-512 の組込み関数の定義は、ヘッダーファイル immintrin.h 内にあります。
#include <immintrin.h>
インテル® AVX-512 の組込み関数は、512 ビット・レジスターを表すオペランドとして C データ型を使用します。__m512i データ型は、64 の 8 ビット整数値、32 の 16 ビット値、または 16 の32 ビット値を保持できます。
uint8_t op1_int8[64]; int8_t op2_int8[64]; int32_t op3_int[16]; int16_t op4_int16[32]; int32_t result[16]; __m512i v1_int8; __m512i v2_int8; __m512i v3_int; __m512i v4_int16; __m512i vresult;
メモリーデータは _mm512_loadu_si512 関数を使用してレジスターにロードできます (データは特定の境界でアライメントされている必要はありません。データが 64 ビット境界でアライメントされている場合、_mm512_load_si512 関数を代わりに使用できます)。
v1_int8 =_mm512_loadu_si512(op1_int8); v2_int8 =_mm512_loadu_si512(op2_int8); v3_int =_mm512_loadu_si512(op3_int); v4_int16 =_mm512_loadu_si512(op4_int16);
データがロードされたら、_mm512_dpbusds_epi32 組込み関数を使用して vpdpbusds 融合関数を呼び出し、ドット積演算を行います。この命令は、4 つの隣接する v1_int8 の符号なし 8 ビット整数と v2_int8 の対応する符号付き 8 ビット整数のペアを乗算して、4 つの中間値 (符号付き 16 ビット整数) を生成します。次に、符号付き飽和処理を使用して 4 つの結果と v3_int の対応する 32 ビット整数を加算し、パックド 32 ビット整数を返します。
// 融合命令を使用してドット積演算を実行する
vresult = _mm512_dpbusds_epi32(v3_int, v1_int8, v2_int8);
_mm512_storeu_si512((void *) result, vresult);
printf("RESULTS USING FUSED INSTRUCTION: \n");
for (int j = 15; j >= 0; j--){
cout << result[j]<<" ";
}
3 つの個別の FMA 命令、vpmaddubsw、vpmaddwd、および vpaddd (それぞれ、_mm512_maddubs_epi16、_mm512_madd_epi16、および _mm512_add_epi32 組込み関数を使用して呼び出します) を使用して同じドット積演算を行うこともできます。
// 3 つの命令シーケンスを使用してドット積演算を実行する
// 2 つの 8 ビット整数を垂直乗算した後、
// 隣接する 16 ビット整数のペアを水平加算する
__m512i vresult1 = _mm512_maddubs_epi16(v1_int8, v2_int8);
// 32 ビットに変換して隣接する値を水平加算し、1 を掛ける
__m512i vresult2 = _mm512_madd_epi16(vresult1, v4_int16);
// パックド 32 ビット整数を加算する
vresult = _mm512_add_epi32(vresult2, v3_int);
_mm512_storeu_si512((void *) result, vresult);
printf("RESULTS USING SEQUENCE OF 3 INSTRUCTIONS: \n");
for (int j = 15; j >= 0; j--)
cout << result[j]<<" ";
関連情報
インテル® AVX-512 の組込み関数の詳細な説明は、インテルの組込み関数ガイド (英語) を参照してください。VNNI 命令の詳細な説明とインテル® MKL-DNN ライブラリー (英語) での実装方法は、「低い数値精度でのディープラーニングのトレーニングと推論」を参照してください。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
