
この記事は、The Parallel Universe Magazine 46 号に掲載されている「Cost Matters: On the Importance of Cost-Aware Hyperparameter Optimization」の日本語参考訳です。
この記事では、Conference on Uncertainty in Artificial Intelligence(英語)で発表した弊社のコスト制約のあるベイズ最適化への非短絡的アプローチ(英語)に関する研究を紹介します。この研究は、Facebook や Amazon のサイエンティストと共同で行われました。この要約では、この研究の動機となった要因について説明します。
通常のハイパーパラメーター最適化:反復による進捗状況の測定
ほとんどの実用的なハイパーパラメーター最適化パッケージは、一定の反復回数を実行して最適なハイパーパラメーターを決定しようとします。例えば、HyperOpt*、Optuna*、SKOpt、SigOpt を 100 回ずつ反復する例について考えてみます。
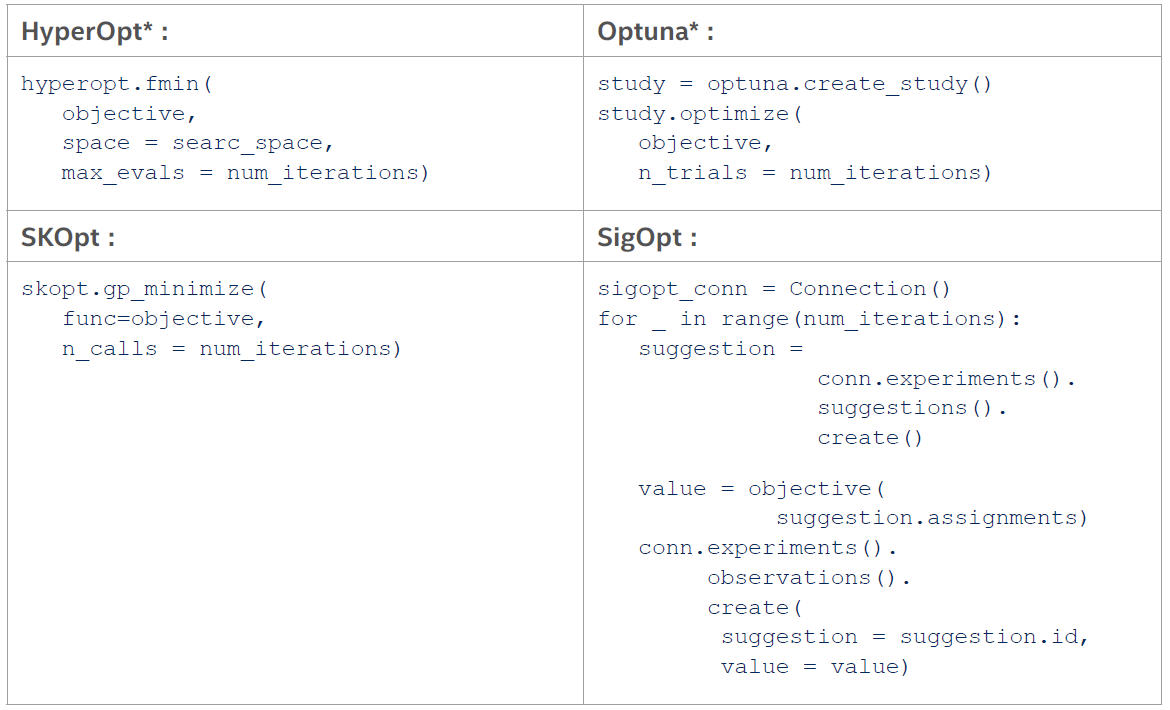
ほとんどのオプティマイザーのインターフェイスは基本的に同じで、最大化/最小化したいもの(最適化の目的)と実行する反復回数を入力します。多くの開発者はこのインターフェイスを当たり前のように使っていますが、これは本当に目的を最適化する最良の方法なのでしょうか? 累積トレーニング時間などが重要である場合に反復回数を求めることは、パフォーマンスを重視していないと言えます。
課題:ハイパーパラメーターの評価コストのばらつき
最適化の進捗状況を反復回数で測定することは、各評価にかかる時間が同じであれば合理的ですが、ハイパーパラメーター最適化(HPO)では、ハイパーパラメーターにより設定のトレーニング時間が大きく異なる場合があります。前述の研究では、最も一般的に使用されている 5 つのマシンラーニング・モデルでこれを確認しています。
- K 近傍法(KNN)
- 多層パーセプトロン(MLP)
- サポート・ベクトル・マシン(SVM)
- 決定木(DT)
- ランダムフォレスト(RF)
これらのモデルは、データ・サイエンティストが使用する一般的なモデルの大部分を構成しています。ここでは、ディープラーニング・モデルは省略していますが、これらのモデルについても結果は同じです。
5 つのモデルは、一般的なベンチマークである OpenML* w2a データセットで、標準の探索空間からランダムに選択した 5,000 個のハイパーパラメーター設定を使用してトレーニングしました。そして、各モデルのトレーニング時間の分布を図にしました(図 1)。各モデルのトレーニング時間は大きく異なり、1 桁以上の差があることも珍しくないことが分かります。これは、各モデルにおいて、いくつかのハイパーパラメーターが、モデルのパフォーマンスだけでなく、トレーニング時間にも大きく影響するためです(ニューラル・ネットワークの層のサイズや、フォレストのツリーの数など)。実際に、ほとんどすべての実用アプリケーションにおいて、評価コストは探索空間の異なる領域で大きく変化することが分かっています。
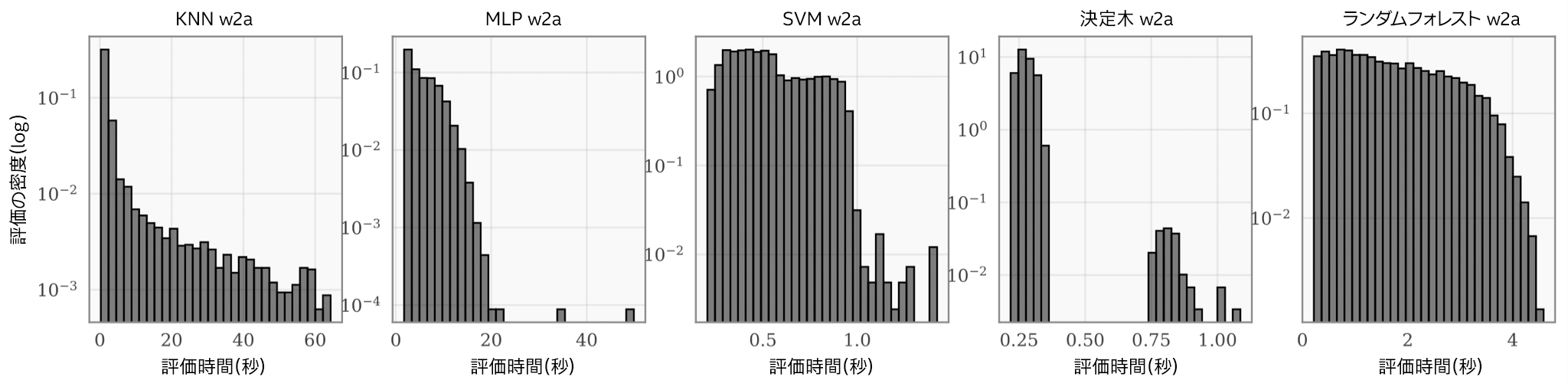
図 1.KNN、MLP、SVM、DT、RF の各ハイパーパラメーター最適化問題について、ランダムに選択した 5,000 点のランタイム分布(ログスケール)。各ヒストグラムの X 軸はランタイム、Y 軸は密度(全評価数に対する割合)を示します。
そのため、これらのハイパーパラメーターのチューニングにかかる累積トレーニング時間は、反復回数に正比例しません。実際、図 1 のヒストグラムから、あるオプティマイザーが 1 つのハイパーパラメーター設定を評価し、別のオプティマイザーが 100 個のハイパーパラメーター設定を評価した場合に、両者の時間が同じになる可能性は十分にあります。
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
