

この記事は、インテル® デベロッパー・ゾーンに公開されている「New Deep Learning Workbench Profiler Features」(https://software.intel.com/en-us/blogs/2019/12/10/new-deep-learning-workbench-profiler-features) の日本語参考訳です。
インテル® ディストリビューションの OpenVINO™ ツールキットに含まれるディープラーニング・ワークベンチ (DL ワークベンチ) は、開発者に次の機能を提供します。
- 開発者がパフォーマンス・ボトルネックを特定してチューニングできるように、さまざまなインテル® アーキテクチャー上でディープラーニング・モデルのスループット、レイテンシー、精度をプロファイルして視覚化。
- 精度を INT8 または Winograd に下げることで、特に高負荷によりオーバーサブスクライブ状態にあるエッジ推論デバイス上でパフォーマンスを大幅に向上。
DL ワークベンチの概要は、以前のブログ「新しいディープラーニング・ワークベンチ・プロファイラーはパフォーマンスの詳細を提供」 (https://software.intel.com/en-us/blogs/2019/08/26/introducing-the-new-openvino-dl-workbench#) を参照してください。
インテル® ディストリビューションの OpenVINO™ ツールキットの最新リリース (R3.1) (英語) では、DL ワークベンチはオリジナルモデルのインポート機能によりモデル・オプティマイザーの統合を提供します。これにより、インターネットから一般的な DL モデルをインポートしたり、オリジナルのフレームワーク形式のカスタムモデルをインポートできます。その結果、モデル・オプティマイザーによってオフラインで生成された IR ファイルを DL ワークベンチで指定する必要がなくなりました。ただし、必要な場合は、引き続きこのオプションを使用できます。このリリースには、次の機能も含まれます。
- ディープラーニング・ワークベンチ (DL ワークベンチ) 内でのモデル・オプティマイザーのサポート。オリジナルのトレーニング済みモデルで DL ワークベンチの使用を開始し、直感的かつ明確な変換ステップに従ってモデルのプロファイルと最適化に進むことができます。変換ステップは、提供されたモデルの内部解析によって簡素化され、必要なモデル・オプティマイザー・パラメーターが提案されます。
- ディープラーニング・ワークベンチ (DL ワークベンチ) でのモデルインポート処理の簡素化。新しいフローでは、インポート手順中に精度測定パラメータを設定する必要がありません。精度測定を行う場合や INT8 キャリブレーションを行う場合のみ、パラメーターを設定する必要があります。これにより、上級ユーザーが必要とするすべての機能を維持したまま、初めて推論を試すユーザーの負担を大幅に軽減します。
- ディープラーニング・ワークベンチ (DL ワークベンチ) の Docker* Hub によるインストールの簡素化。これまでと同様にインテル® ディストリビューションの OpenVINO™ ツールキットから DL ワークベンチをビルドすることもできますが、Docker* Hub からビルド済みの DL ワークベンチをダウンロードできるようになりました。
このリリースでは、Tensorflow*、Caffe*、Apache* MxNet、PyTorch*、Paddle Paddle* (ONNX*) を含む業界の主要フレームワークで FP32 と FP16 データ型のさらに多くのモデルと、最適化された INT8 バージョンのモデルがサポートされました。現在、DL ワークベンチの Linux* バージョンは、CPU、統合 GPU、インテル® Movidius™ VPU をサポートしていますが、INT8 または Winograd の最適化の利点が得られるのは CPU だけです。
DL ワークベンチのバックエンドは Docker* コンテナーであるため、開発者は Docker* Hub で提供されている事前ビルド済み DL ワークベンチを使用することも、自身でビルドしたものを使用することもできます。現在のバージョンの DL ワークベンチを開始する最も簡単な方法は、このコマンドを実行することです (Linux* の例)。
-
sudo docker run -p 127.0.0.1:5665:5665 --name workbench --privileged -v /dev/bus/usb:/dev/bus/usb -v /dev/dri:/dev/dri -e PORT=5665 -e PROXY_HOST_ADDRESS=0.0.0.0 -it openvino/workbench:latest
- Linux* システムで実行中のウェブブラウザーで http://0.0.0.0:5665 を開きます。これで、DL ワークベンチ・プロファイラーを取得できます。
インストール手順と実行手順は https://docs.openvinotoolkit.org/latest/_docs_Workbench_DG_Install_Workbench.html (英語) を参照してください。
- 次に、適切な形式の互換性のあるデータセットをインポートします。現在、ImageNet (分類) と Pascal VOC (オブジェクト検出) がサポートされています。適切なファイル構造と注釈ファイル形式 (ImageNet* または VOC*) に変換されていれば、独自のデータセットをインポートすることもできます。
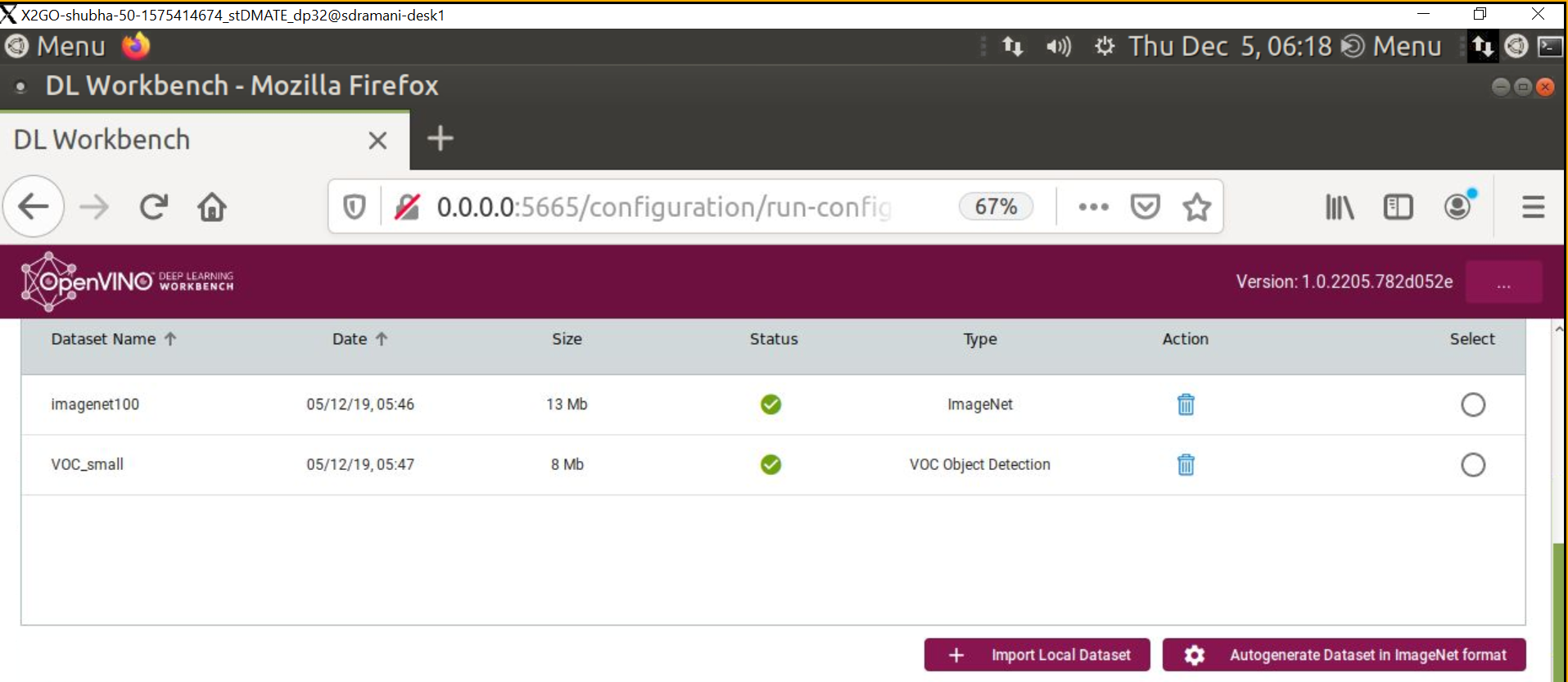
データセットがない場合、DL ワークベンチを使用して ImageNet (ファイル構造と注釈ファイル) 形式の独自のデータセットを自動生成できます。このオプションを使用すると、画像にはランダムなノイズが含まれます。これは、パフォーマンスの測定には十分ですが、精度の測定には不十分です。
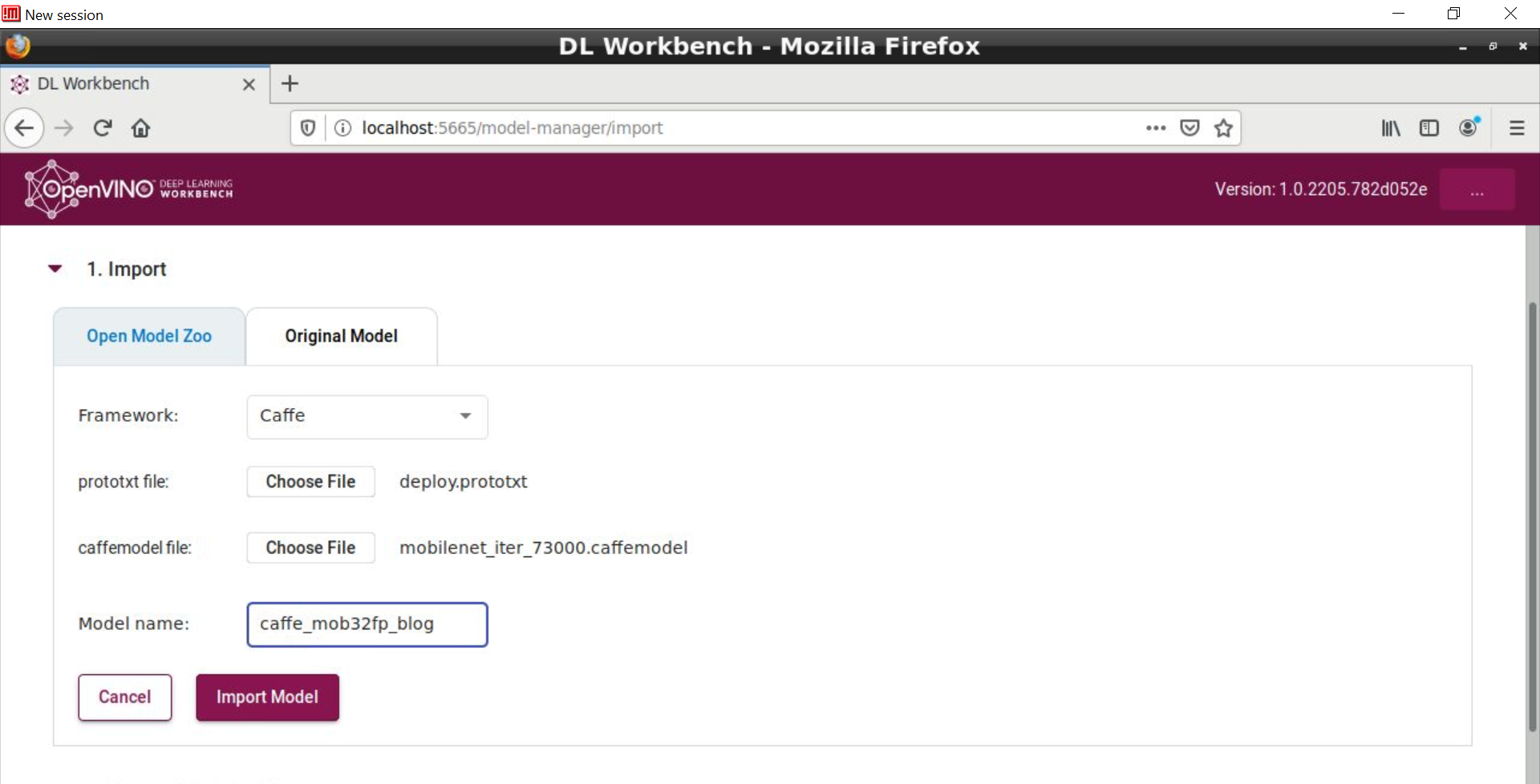
40 以上の選択肢がある Model Zoo からモデルをインポートすることを推奨します。これらのモデルには、インテルが開発したものと、インターネットで確認、テスト、場合によっては最適化 (INT*) され配布されているものがあります。[Import Original Model] ボタンを使用することもできます。その場合、DL ワークベンチは自動的に内部でモデル・オプティマイザー・コマンドを実行して、関連モデルファイルをインポートするようにユーザーに促します。以下は、Caffe* ssd-mobilenet の例です。
DL ワークベンチ画面を進むと、画像サイズに加えて、通常モデル・オプティマイザー・コマンドライン・ツールで渡される –mean_values、–scale_values、–reverse_input_channels 前処理オプションの入力も求められます。以前のブログで述べたとおり、モデルのトレーニング方法を反映する正しい IR を生成するため、これらの前処理オプション (平均値、スケール値、入力チャネルの順序) は明示的に定義して、モデル・オプティマイザー (そして、DL ワークベンチ) に入力する必要があります。
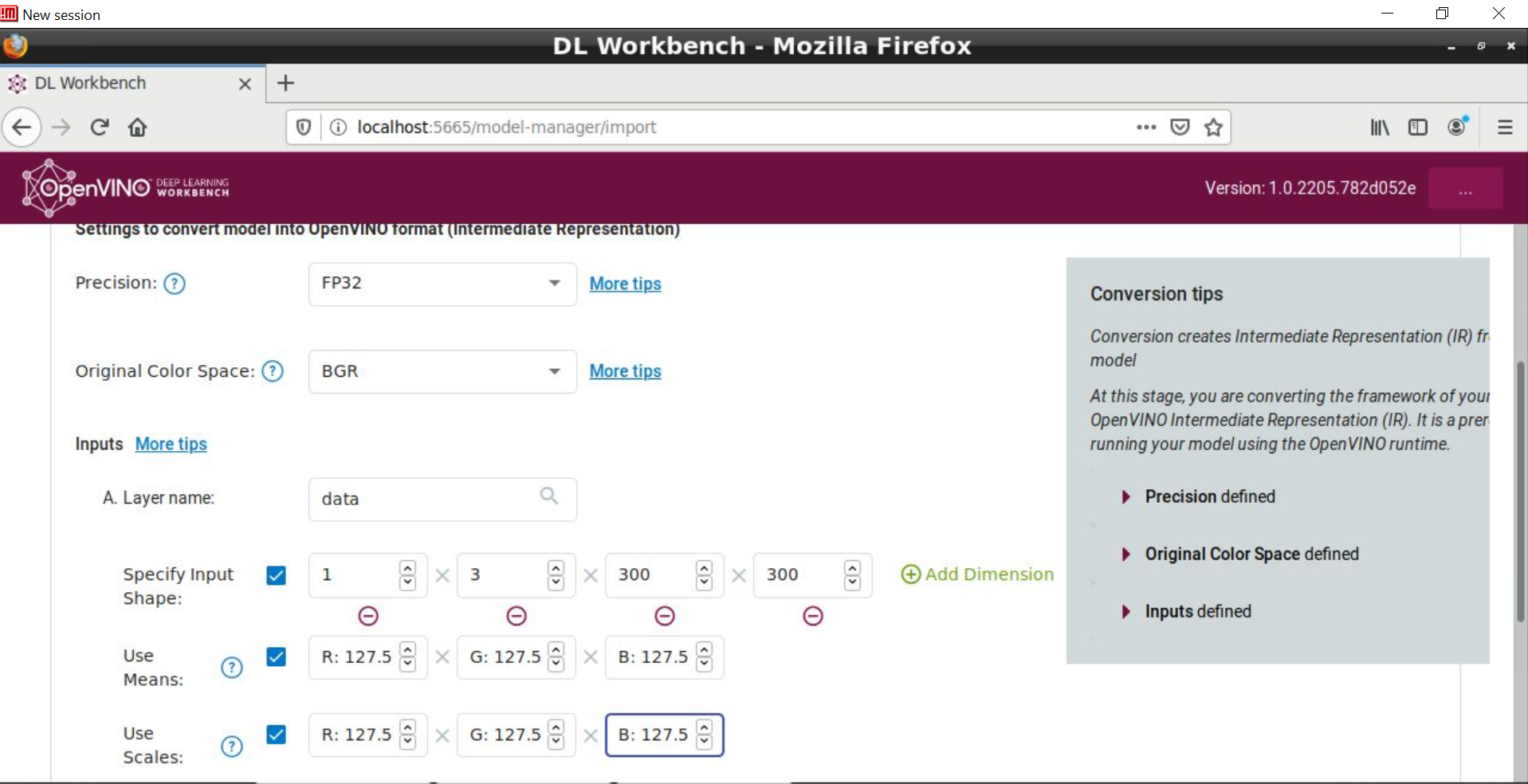
Model Zoo とオリジナルモデルのどちらのシナリオでも、DL ワークベンチは内部でモデル・オプティマイザーを呼び出し、後者では、モデルが DL ワークベンチでサポートされる場合、前処理オプションはシームレスに実行されます。オリジナルモデルの場合、オプションでフレームワーク・タイプ (OpenVINO™ (IR)、Caffe*、Apache* MxNet、ONNX*、および Tensorflow*) をインポートできます。OpenVINO™ (IR) は、オリジナルモデルが DL ワークベンチによって認識されない場合や、モデル・オプティマイザー・プロセスを細かく制御する場合に使用され、モデルに対してモデル・オプティマイザーを実行した後、生成された *.xml と *.bin ファイルを手動でインポートする必要があります。また、Model Zoo からインポートする場合、モデルタイプ (分類またはオブジェクト検出) は DL ワークベンチによって自動判定されます。
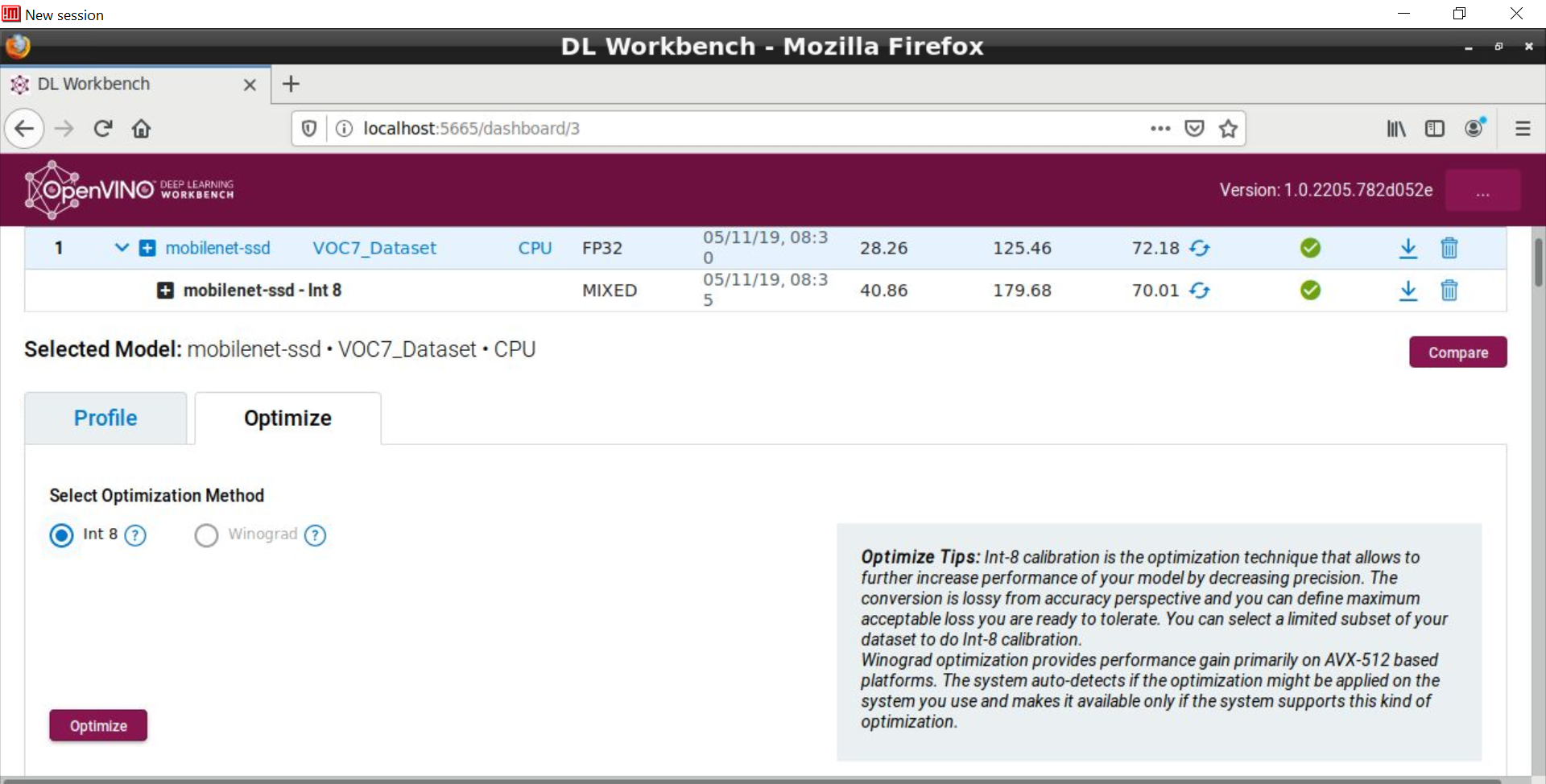
このバージョンの DL ワークベンチは、以下に示す最適化のヒントなど、いくつかの役立つヒントを提供します。
https://software.intel.com/en-us/forums/computer-vision または #OpenVINO on Stack Overflow (英語) を使用して、お気軽にご意見、コメント、質問をお寄せください。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
