

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Avoiding AVX-SSE Transition Penalties」(http://software.intel.com/en-us/articles/avoiding-avx-sse-transition-penalties/) の日本語参考訳です。
1. AVX-SSE 切り替えペナルティーの概要
インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) は、第 2 世代インテル® Core™ プロセッサー・ファミリーで利用可能な新しい SIMD 命令セットの拡張です。より広い 256 ビットのベクトル、新しい命令、および 3つ (またはそれ以上) のオペランドの命令をサポートする新しい拡張可能な命令エンコーディング・フォーマット (ベクトル・エクステンション、または VEX) を採用しています。また、インテル® AVX には、従来の 128 ビット インテル® SSE 命令すべてに対応する 128 ビット VEX エンコード命令が用意されます。
インテル® AVX 命令を使用する場合、256 ビットのインテル® AVX 命令と従来の (VEX エンコードでない) インテル® SSE 命令を混在して使用すると、切り替えペナルティーによりパフォーマンスが低下することがあります。256 ビットのインテル® AVX 命令は、既存の 128 ビット XMM レジスターを 256 ビットに拡張した 256 ビット YMM レジスターを使って処理します。128 ビットのインテル® AVX 命令は、YMM レジスターの下位 128 ビットを使用し、上位 128 ビットは 0 に設定します。
一方、従来のインテル® SSE 命令は、XMM レジスターを使って処理し、YMM レジスターの上位 128 ビットについては関知しません。そのため、256 ビットのインテル® AVX から従来のインテル® SSE に切り替える場合は、ハードウェアで YMM レジスターの上位 128 ビットを保存し、インテル® SSE からインテル® AVX (256 ビットまたは 128 ビット) に切り替える場合は、保存した値を復元します。この保存と復元操作はそれぞれ、1 処理につき数十サイクルのペナルティーを引き起こします。
AVX-SSE 切り替えはさまざまな状況で発生します。例えば、256 ビットのインテル® AVX 組込み命令やインライン・アセンブリーと以下のものを組み合わせた場合に発生します。
a. 128 ビットの組込み命令
b. インテル® SSE のインライン・アセンブリー
c. インテル® SSE 命令にコンパイルされた C/C++ 浮動小数点コード
d. 上記のものを含む関数やライブラリーの呼び出し
さらに、256 ビットのインテル® AVX 命令を実行中に割り込みが発生し、その割り込みサービスルーチン (ISR) に従来のインテル® SSE 命令が含まれている場合にも AVX-SSE 切り替えが発生します。このように、ISR によって切り替えペナルティーが発生する場合は、開発者がこれを回避する方法はありません。ISR 開発者は、ルーチン内で XMM/YMM レジスターを使用する場合、このペナルティーの可能性を考慮し、後述する方法で AVX-SSE 切り替えペナルティーを回避し、必要に応じてすべての YMM 状態の保存と復元を行うべきです。
通常、従来のインテル® SSE 命令に対応する VEX エンコード命令に変換することで、AVX-SSE 切り替えを排除することができます。排除できない場合は、YMM レジスターの上位 128 ビットを 0 に設定すると、ハードウェアはこれらの値を保存しなくなるため、ペナルティーを回避することができます。AVX-SSE 切り替えペナルティーを回避する方法は、セクション 3 で詳しく説明します。
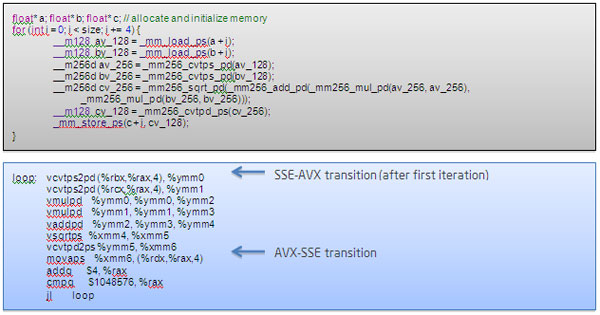
128 ビットと 256 ビットの組込み命令を使用する次の例について考えてみましょう。生成されるアセンブリー (以下を参照) のほとんどはインテル® AVX 命令 (プリフィックス “v” のもの) ですが、従来のインテル® SSE 命令 (movaps) も含まれています。movaps 命令の直前で、ハードウェアは YMM レジスターの上位 128 ビットの内容を保存し、次のインテル® AVX 命令 (次の反復) の前にその値を復元します。次のコードは、インテル® コンパイラー 12.0.4 を使って、–O3 オプションを指定し、コマンドラインでコンパイルされています。
図 1. AVX-SSE 切り替えの場所を示す C ソースと逆アセンブルの例
2. AVX-SSE 切り替えの検出
2.1. インテル® Software Development Emulator
インテル® Software Development Emulator (インテル® SDE) は、インテル® AVX に対応していないプロセッサー上でも、プログラム中の AVX-SSE 切り替えを動的に検出できる Windows* および Linux* 向けのコマンドライン・ツールです。インテル® SDE は、関数内の特定のブロックの AVX-SSE および SSE-AVX 切り替えの数をレポートします。
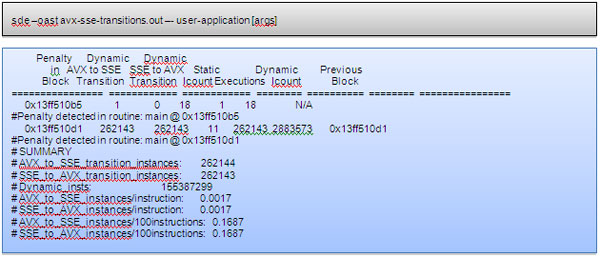
以下に、使用するコマンドと、AVX-SSE 切り替えの詳細情報を含むサンプル出力を示します。インテル® SDE は、インテル® AVX に未対応のプロセッサー上でも利用できますが、切り替えの原因である特定の命令は表示されません。詳細は、インテル® Software Development Emulator の Web サイト (英語) を参照してください。
図 2. インテル® SDE を使って AVX-SSE 切り替えを検出するためのコマンドとインテル® SDE のサンプル出力
2.2. インテル® VTune™ Amplifier XE の使用
第 2 世代インテル® Core™ プロセッサー・ファミリーは、256 ビットのインテル® AVX からインテル® SSE への切り替えと、インテル® SSE からインテル® AVX への切り替えをカウントするハードウェア・イベント (OTHER_ASSISTS.AVX_TO_SSE と OTHER_ASSISTS.SSE_TO_AVX) をサポートしています。第 2 世代インテル® Core™ プロセッサー・ファミリーでインテル® VTune™ Amplifier XE を使用し、これらのハードウェア・イベントを利用して、AVX-SSE 切り替えを検出できます。
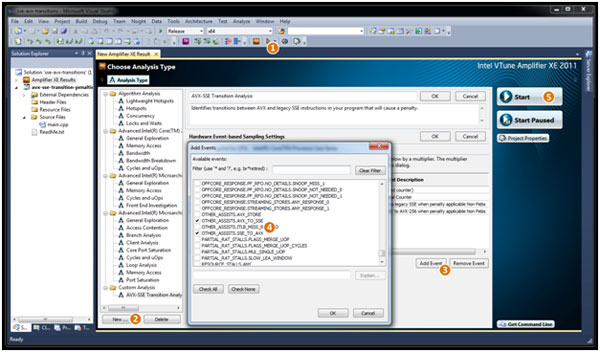
インテル® VTune™ Amplifier XE でこれらのイベントを利用するには、次の手順に従って、新しいハードウェア・イベント・ベースのカスタム解析を作成する必要があります。ここでは、Microsoft* Visual Studio* 2010 SP1 を使用しています (Microsoft* Visual Studio* 2010 でインテル® AVX を使用する場合は SP1 が必要です)。
- 新しい解析を作成します。
- [New (新規)] をクリックして、[New Hardware Event-based Sampling Analysis (新しいハードウェア・イベントベース・サンプリング解析)] を選択します。
- [Add Event (イベントの追加)] をクリックして、OTHER_ASSISTS.AVX_TO_SSE イベントと OTHER_ASSISTS.SSE_TO_AVX イベントを選択し、[OK] をクリックします。
- [Start (開始)] をクリックして、解析を開始します。
解析が終了すると関数別にイベント数が表示され、AVX-SSE 切り替えを含む関数を特定できます。関数をクリックして、ソースまたは逆アセンブルで特定のイベントの hotspot を確認することもできます。これにより、どの命令で切り替えが行われているかが分かります。
インテル® VTune™ Amplifier XE は、AVX-SSE 切り替えを検出し、ソースコードや逆アセンブルでその原因である命令を特定できますが、インテル® AVX 対応プロセッサー上でしか AVX-SSE 切り替えイベントを検出できません。
図 3. インテル® VTune™ Amplifier XE を使って、AVX-SSE 切り替えを検出するカスタム解析の作成手順
3. AVX-SSE 切り替えの回避方法
3.1. 方法 1: コンパイラー・オプションで自動的に VEX に変換する
AVX-SSE 切り替えからペナルティーを排除するにはさまざまな方法があります。AVX-SSE 切り替えペナルティーを回避する最も簡単な方法は、インテル® コンパイラーで –xavx (Windows* の場合は /Qxavx) か –mavx (Windows* の場合は /arch:avx) オプションを指定してコンパイルすることです。これらのオプションを指定すると、インテル® AVX 対応プロセッサー向けの専用命令が生成されます。–xavx オプションはインテル® AVX 対応プロセッサー向けのコード最適化も行います。
これらのオプションを指定すると、コンパイラーは必要に応じて、従来のインテル® SSE 命令の代わりに、自動で VEX エンコード命令を生成するため、インテル® AVX とインテル® SSE 間の切り替えを排除できます。また、YMM レジスターの上位 128 ビットを 0 に設定する vzeroupper 命令が自動で追加されます (次のセクションを参照)。どの引数も YMM レジスターでない場合や __m256/__m256d/__m256i データ型でない場合、インテル® AVX コードを含む関数の最初に vzeroupper 命令が追加されます。また、戻り値が YMM レジスターでない場合や __m256/__m256d/__m256i データ型でない場合、関数の最後に vzeroupper 命令が追加されます。vzeroupper 命令を追加することで、従来のインテル® SSE 命令が含まれている可能性のあるルーチンからそれらのファイルの関数を呼び出す際に、AVX-SSE 切り替えの発生を防ぎます。インテル® コンパイラーのプロセッサー固有の最適化オプションの詳細は、インテル® コンパイラーのドキュメントを参照してください。
この方法は、コンパイラーにより自動的に行われるだけでなく、128 ビットの組込み命令で VEX エンコード命令の生成を強制することができる唯一の方法です (–xavx や –mavx を使用しない場合、128 ビットの組込み命令が必ず VEX エンコード命令を生成するとは限りません)。状況によっては、コンパイラーは C/C++ 浮動小数点コードを x87 命令ではなく、インテル® SSE 命令にコンパイルすることがあります。その場合、–xavx や –mavx オプションを使用することが、VEX エンコード命令を確実に生成する方法です。x87 命令にコンパイルされた C/C++ 浮動小数点コードでは、切り替えペナルティーは発生しません。
ただし、この方法は関連するソースファイルへのアクセスが必要になるため、–xavx または –mavx オプションを指定してコンパイルされていない関数の呼び出しによる AVX-SSE 切り替えを回避できません。また、–xavx または –mavx オプションを指定してコンパイルされたファイル内のすべてのインテル® SSE コードが VEX 形式に変換され、インテル® AVX 対応プロセッサー上でしか実行できなくなる可能性があります。1 つのファイルに複数の異なるプロセッサーで実行するコードが含まれている場合は、機能ごとにファイルを分けて、適切なコンパイラー・オプションを指定し、それぞれのファイルをコンパイルすることを検討してください (セクション 4 の CPU ディスパッチの説明も参考にしてください)。
前述の例では、–xavx オプションを指定してコンパイルすると、コンパイラーは movaps 命令の代わりに vmovaps 命令を生成するため、AVX-SSE 切り替えを排除できます。切り替えを排除する前は、1 反復につき 230 サイクル以上かかっていましたが、–xavx オプションを指定してコンパイルした後は、1 反復につき約 70 サイクル1 になりました。
1インテル® Core™ i7 プロセッサー 2.3 GHz に Mac OS* X 10.6.8 を搭載したシステムで、インテル® コンパイラー 12.0.4 を使って –O3 オプションを指定してコンパイル
図 4. –xavx オプションを指定するとコンパイラーは 128 ビットの VEX エンコード命令を使用

3.2. 方法 2: プラグマで自動的に VEX に変換する
インテル® コンパイラーを使用して自動で VEX に変換する別の方法は、インテル® コンパイラー 12.1 で追加された新しいインテル固有のプラグマ #pragma intel optimization_parameter target_arch=avx を使用することです。関数の先頭にこのプラグマを追加すると、その関数だけに –mavx オプションが適用されます。そして、関数内で必要に応じて自動的に VEX エンコード命令が生成され、関数の最初と最後に vzeroupper 命令が自動的に追加されます。
この方法は、ファイルレベルではなく、関数レベルで –xavx と –mavx を適用できます。そのため、複数の異なるプロセッサーで実行されるコードを機能ごとに別々のファイルに分ける必要はありません。ただし、この方法は –xavx および –mavx と同様に、関連するソースファイルへのアクセスが必要になるため、アクセスできない関数への呼び出しによる AVX-SSE 切り替えを回避できません。また、このプラグマを指定した関数がインテル® コンパイラーによりインライン展開対象に選択されると、そのコードに –mavx は適用されません。これは、__declspec(noinline) キーワードを指定し、インテル® コンパイラーが関数をインライン展開しないようにすることで回避できます。
図 5. optimization_parameter プラグマと __declspec(noinline) キーワードの使用例

3.3. 方法 3: レジスターを 0 に設定する
例えば従来のインテル® SSE を使用するライブラリーを呼び出す必要がある場合など、インテル® AVX からインテル® SSE への切り替えを排除できないことがあります。その場合、組込み命令やインライン・アセンブリーを使用して、YMM レジスターの上位 128 ビットを 0 に設定する vzeroupper 命令を呼び出します (同様に、YMM レジスターの 256 ビットすべてを 0 に設定する vzeroall 命令を使用することもできます)。
vzeroupper 命令によって YMM レジスターの上位 128 ビットが 0 に設定されると、ハードウェアはそれらの値を保存しなくてもいいため、ペナルティーは発生しません。vzeroupper 命令は、256 ビットのインテル® AVX コードの後とインテル® SSE コードの前に記述する必要があります。そうすることで、保存と復元の両処理を排除できます。XOR などを使って YMM レジスターを 0 に設定する別の方法では、AVX-SSE 切り替えペナルティーを回避できません。
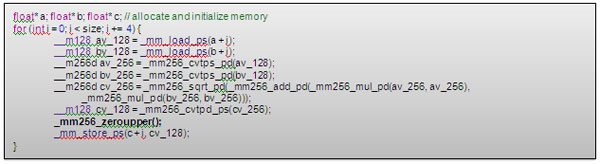
vzeroupper / vzeroall 命令は、開発者が制御できない従来のインテル® SSE を含む関数やライブラリーを使用する場合に AVX-SSE 切り替えペナルティーを回避できる唯一の方法です。さらに、アセンブリー・コードを記述しなくても、組込み命令 _mm256_zeroupper() と _mm256_zeroall() を使用して実装できます。ただし、この方法では、vzeroupper 命令を正しい位置に配置しなければなりません。
前述の例では、vzeroupper の呼び出しを (_mm256_zeroupper() 組込み命令を使用して) 最後の 256 ビットのインテル® AVX 組込み命令の直後と、128 ビットの組込み命令の前に追加する必要があります。YMM レジスターの上位 128 ビットを 0 に設定するコードを追加すると、1 反復につき約 70 サイクルに減ります。
図 6. レジスターを 0 に設定して AVX-SSE 切り替えペナルティーを排除
3.4. 方法 4: アセンブリーを手動で VEX に変換する
AVX-SSE 切り替えペナルティーを回避する最後の方法は、従来のインテル® SSE アセンブリー命令を対応する VEX エンコード命令に手動で変換し、AVX-SSE 切り替えを排除する方法です。VEX エンコード命令については、『Intel® Architectures Software Developer’s Manuals』 (英語) を参照してください。
手動で VEX に変換する利点は、–xavx オプションですべてを変換する場合と異なり、ファイル内のアセンブリーの中から選択したものだけを変換できることです。また、–xavx やプラグマを使用できない場合にも、手動でアセンブリーを VEX に変換できます。

さらに、手動で VEX に変換することで、アセンブリーで非破壊的 3 オペランド形式の恩恵が得られます。ただし、この方法は、手動で変換しなければならず、アセンブリー・コードでしか作業できない上に、変換後のコードはインテル® AVX 対応プロセッサー上でしか実行できません。
4. AVX-SSE 切り替えと CPU ディスパッチ
多くの場合、1 つの関数に対して複数のバージョンを用意し、それぞれのバージョンで特定のプロセッサー機能 (例えば、インテル® SSE2 やインテル® AVX など) 向けに最適化したほうが良いでしょう。例えば、インテル® AVX とそれ以外のバージョンを生成することで、インテル® AVX の利点を利用しつつ、インテル® AVX 以外もサポートできます。このような場合、CPU ディスパッチを使用して、プログラムを実行するプロセッサーに最適な関数のバージョンが “ディスパッチ” されます。CPU ディスパッチは次の 3 つの方法で実装できます。
(1) インテル® コンパイラーを使用して自動で実装する
(2) インテル® コンパイラーの手動ディスパッチ機能を使用して実装する
(3) 開発者が独自のメカニズムを使って手動で実装する
ここでは、インテル® コンパイラーを使用する自動および手動の CPU ディスパッチと AVX-SSE 変換への影響について説明します。ここで紹介する方法は、ほかのコンパイラーでは動作しない可能性があります。また、ほかのコンパイラーでは、CPU ディスパッチは開発者が自身の責任で行わなければならないこともあります。
4.1. インテル® コンパイラーの自動ディスパッチ機能
インテル® コンパイラーの自動ディスパッチ機能を利用するには、–axavx オプション (Windows* の場合は /Qaxavx) を指定します。このオプションを指定すると、インテル® コンパイラーはインテル® SSE からインテル® AVX までの各種命令セットを使用して、既存のコードの最適化の可能性を探します。十分なパフォーマンスの向上が得られる場合、最適化された既存の関数のプロセッサー固有のコードを生成し、実行時に適切な関数を自動ディスパッチする機能も提供します。インテル® コンパイラーは、常にオリジナルコードを含む汎用関数を生成しますが、特定のプロセッサー固有バージョンは生成しないことがあります。インテル® コンパイラーの自動ディスパッチ機能の詳細は、「インテル® SSE およびインテル® AVX 世代 (SSE2、SSE3、SSSE3、ATOM_SSSE3、SSE4.1、SSE4.2、ATOM_SSE4.2、AVX、AVX2) 向けのインテル® コンパイラー・オプションとプロセッサー固有の最適化」を参照してください。
インテル® コンパイラーの自動ディスパッチ機能を使用すると、コンパイラーは関数ごとに自動ディスパッチされるプロセッサー固有バージョンを生成するかどうか決定します。コンパイラーが関数を自動ディスパッチの対象とし、インテル® AVX 向けに最適化されたコードパスを生成する場合、必要に応じてインテル® AVX 命令が生成され、関数内の関連するすべての命令が自動で VEX エンコード命令に変換されて、vzeroupper 命令が関数の最初と最後に自動で追加されます。
ただし、関数が自動ディスパッチの対象ではなく、開発者が手動でインテル® AVX 組込み命令を追加した場合、関数内の関連するすべての命令が VEX エンコード命令に変換される保証はなく、vzeroupper 命令は自動的に追加されません。つまり、–axavx を指定しただけではインテル® コンパイラーがインテル® AVX 向けにコードを最適化する保証はなく、–axavx を指定しなかった場合と同じ AVX-SSE 変換がプログラムに含まれる可能性があります (–axavx は –xavx とは異なります)。
4.2. インテル® コンパイラーの手動ディスパッチ機能
インテル® コンパイラーの手動ディスパッチ機能により、開発者は関数のプロセッサー固有のバージョンを明示的に定義できます。手動ディスパッチを使用すると、インテル® コンパイラーは、実行時に適切なバージョンを自動でディスパッチする機能を生成します。手動ディスパッチは、関数のインテル® AVX バージョンを明示的に定義するとともに、インテル® AVX に対応していないプロセッサーも明示的にサポートする場合 (例えば、インテル® AVX バージョン、インテル® SSE バージョン、および汎用バージョンをサポートする場合) に役立ちます。
手動ディスパッチの実装には、__declspec(cpu_dispatch()) および __declspec(cpu_specific()) キーワードを使用します。__declspec(cpu_dispatch(cpuid,…)) キーワードはディスパッチされる関数のスタブの上に配置し、cpuid パラメーターには明示的にサポートする特定のプロセッサーをすべて指定します。__declspec(cpu_specific(cpuid, …)) キーワードは関数のプロセッサー固有の実装の上に配置し、cpuid にはサポートする 1 つ以上の特定のプロセッサーを指定します。インテル® AVX 対応プロセッサーをサポートする場合は、cpuid を core_2nd_gen_avx にします。インテル® コンパイラーの手動ディスパッチ機能の詳細と例は、「インテル® AVX をサポートする第2 および第 3 世代 インテル® Core™ プロセッサー・ファミリー向けに手動でコードを配置するには」を参照してください。
cpuid が core_2nd_gen_avx の関数バージョンでは、関連するすべての組込み命令とインライン・アセンブリー2 は自動的に VEX エンコード命令となり、vzeroupper 命令が関数の最初と最後に自動的に追加されます。cpuid が core_2nd_gen_avx でないのに、インテル® AVX 命令を含む関数では、インテル® AVX に対応していないプロセッサーが対象となり、実行時に例外が発生します。
表 1: コンパイラー・オプションとディスパッチのコード生成への影響
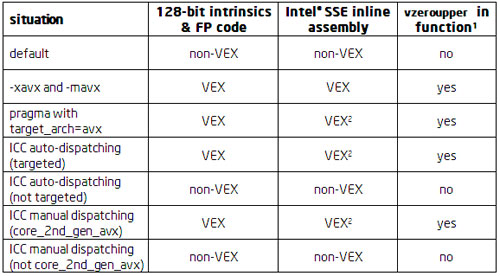
1関数のどの引数も YMM レジスターでない場合または __m256/__m256d/__m256i データ型でない場合は関数の最初に追加。戻り値が YMM レジスターでない場合または __m256/__m256d/__m256i データ型でない場合は関数の最後に追加。
2現在、このケースでは、インテル® コンパイラーは、インテル® SSE のインライン・アセンブリーを VEX エンコード命令に変換しません。これは意図された動作と異なります。インテル® SSE のインライン・アセンブリーを VEX エンコード命令に変換するのが正常な動作です。この問題は現在調査中で、将来解決される予定です。
5. まとめと推奨事項
256 ビットのインテル® AVX 命令とインテル® SSE 命令間の切り替えを行うと、ハードウェアは YMM レジスターの上位 128 ビットを保存/復元するため、パフォーマンス・ペナルティーが発生します。このペナルティーを排除するには、–xavx または -mavx オプションを指定してインテル® コンパイラーを使用するか、新しいインテル固有のプラグマを使用するか、あるいは手動でアセンブリーを変換して従来のすべてのインテル® SSE 命令を対応する VEX エンコード命令に変換します。切り替えを排除できない場合は、vzeroupper 命令を使用して 256 ビットのインテル® AVX 命令の後とインテル® SSE 命令の前に YMM レジスターを 0 に設定することでペナルティーを排除できます。
インテル® AVX の利用に伴う問題を最小限に抑えるため、インテル® AVX 対応プロセッサー向けのソースファイルは -xavx オプションを指定してコンパイルしてください。コードに複数の異なるプロセッサーで実行される関数が含まれている場合は、-xavx を指定してコンパイルする代わりに、新しいインテル固有のプラグマを使用したほうが良いでしょう。また、AVX-SSE 切り替えを回避するため、128 ビットの VEX エンコード命令を使用してください。
コードに従来のインテル® SSE コードが含まれていない場合も、コードで 256 ビットのインテル® AVX を使用した後は vzeroupper 命令や組込み命令を使用してレジスターを 0 に設定したほうが良いでしょう。そうすることで、将来コードで切り替えが発生したり、コードを使用するプログラムで切り替えが発生するのを防ぐことができます。最後に、インテル® AVX を含むプログラムを開発する場合は、常にインテル® Software Development Emulator やインテル® VTune™ Amplifier XE を使って AVX-SSE 切り替えをチェックすることを推奨します。
6. 著者紹介
 Patrick Konsor は、米国カリフォルニア州サンタクララにあるインテルの Apple 推進チームのアプリケーション・エンジニアで、ソフトウェアの最適化に取り組んでいます。ウィスコンシン大学オークレア校でコンピューター・サイエンスの学士号を取得しています。趣味は読書とサイクリングです (Go Schlecks!)。
Patrick Konsor は、米国カリフォルニア州サンタクララにあるインテルの Apple 推進チームのアプリケーション・エンジニアで、ソフトウェアの最適化に取り組んでいます。ウィスコンシン大学オークレア校でコンピューター・サイエンスの学士号を取得しています。趣味は読書とサイクリングです (Go Schlecks!)。
編集部注釈:古いバージョンのコンパイラー(V12.0)では、__declspec(cpu_dispatch()) および __declspec(cpu_specific()) キーワードの cupid に core_2nd_gen_avx の代わりに future_cpu_16 を利用できることがあります。現状では、future_cpu_16 は第 2 世代の Core™ プロセッサー・ファミリーを識別できますが、将来は分かりません。future_cpu_16 を利用している場合、core_2nd_gen_avx に変更してください。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
