
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Advisor Tutorial: Use the Automated Roofline Chart to Make Optimization Decisions」の「Address Memory Bandwidth Bottlenecks」の日本語参考訳です。
バージョン: 2021.1 (更新日: 12/04/2020)
このトピックは、自動ルーフライン・グラフを使用して、優先度の高い最適化を決定する方法を紹介するチュートリアルの一部です。
以下のステップを実行します。
このトピックでは、以下について説明します。
- メモリー帯域幅のボトルネックは、一般にキャッシュの最適化により解決できます。
- ルーフライン・グラフの解釈をサポートするため、インテル® Advisor のほかのビューのデータを確認します。
注
時間とハードウェア依存性を考慮して、ここでは事前に収集された解析結果を使用します。
結果のスナップショットを開く
次のいずれかの操作を行います。
- スタンドアロン GUI: [File] > [Open] > [Result] から Result1.advixeexpz 結果を選択します。
- Visual Studio* IDE: [File] > [Open] から Result1.advixeexpz 結果を選択します。
最も興味のあるルーフライン・グラフのデータに注目
- 表示の切り替えを使用して、ルーフライン・グラフとサーベイレポートを並べて表示します。
- インテル® Advisor ツールバーの [Loops And Functions] フィルター・ドロップダウンから [Loops] を選択します。
![インテル® Advisor: [Filters]](https://www.isus.jp/wp-content/uploads/image/853_advisor-tutorial-roofline_memory_bandwidth_figure1.jpeg)
- ルーフライン・グラフで次の操作を行います。
- [Use Single-Threaded Loops] チェックボックスをオンにします。
![インテル® Advisor: [Roofline] メニュー](https://www.isus.jp/wp-content/uploads/image/853_advisor-tutorial-roofline_memory_bandwidth_figure2.gif) コントロールをクリックして、すべての SP… ループの [Visibility] チェックボックスをオンにします (このサンプルコードの変数はすべて倍精度であるため、単精度のルーフラインを非表示にします)。
コントロールをクリックして、すべての SP… ループの [Visibility] チェックボックスをオンにします (このサンプルコードの変数はすべて倍精度であるため、単精度のルーフラインを非表示にします)。![インテル® Advisor: [Roofline] メニュー](https://www.isus.jp/wp-content/uploads/image/853_advisor-tutorial-roofline_memory_bandwidth_figure2.jpeg)
[Point Colorization] セクションで [Colors of Point Weight Ranges] を選択して、ランタイム別にドットを色分けします (赤、黄、緑)。
 をクリックして変更を保存します。
をクリックして変更を保存します。 コントロールをクリックします。x 軸のフィールドで既存の値を Backspace キーで消去し、0.1 と 0.4 を入力します。y 軸のフィールドで既存の値を Backspace キーで消去し、7.4 と 45.5 を入力します。
コントロールをクリックします。x 軸のフィールドで既存の値を Backspace キーで消去し、0.1 と 0.4 を入力します。y 軸のフィールドで既存の値を Backspace キーで消去し、7.4 と 45.5 を入力します。![インテル® Advisor: [Save] コントロール](https://www.isus.jp/wp-content/uploads/image/853_advisor-tutorial-roofline_memory_bandwidth_figure5.gif) ボタンをクリックして変更を保存します。
ボタンをクリックして変更を保存します。
ルーフライン・グラフのデータの解釈
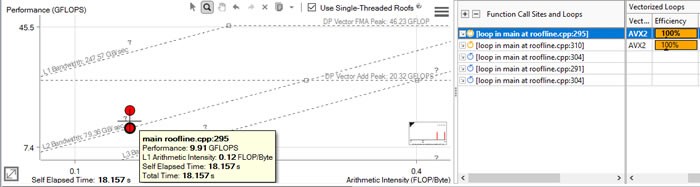
このルーフライン・グラフの下のドットは、roofline.cpp:295 の main にあるループを表しており、(画面には表示されていない) Scalar Add Peak ルーフラインと L2 Bandwidth ルーフラインの上にあります。
なぜこの位置にドットがあるのでしょうか?
ループのパフォーマンスが L2 キャッシュに関連したメモリー帯域幅のボトルネックにより制限されている可能性が考えられます。
これを検証するため、以下の操作を行います。
- サーベイレポートを確認します。
- roofline.cpp:295 の main にあるループの Vectorized Loops/Efficiency 値が 100% です。
ベクトル化効率が 100% であるため、このドットは (スクリーンには表示されていない) Scalar Add Peak ルーフラインの上にあります。
- roofline.cpp:295 の main にあるループのデータ行をクリックして、[Source] タブに関連するソースコードを表示します。
- roofline.cpp:295 の main にあるループの Vectorized Loops/Efficiency 値が 100% です。
- [Source] タブでソースコードの 89 – 96 行目にスクロールして、関連するデータ構造体の定義を確認すると、配列構造体 (SOA) であることが分かります。
![インテル® Advisor: [Source] タブ](https://www.isus.jp/wp-content/uploads/image/853_advisor-tutorial-roofline_memory_bandwidth_figure7.jpeg)
SOA はベクトル化効率の良いデータレイアウトですが、このサンプルコードではチュートリアルのデータセットが L1 キャッシュに収まらず、L2 キャッシュからのロードが頻繁に発生します (この原因については、動画「インテル® Advisor 2017 のルーフライン解析」(英語) をご覧ください)。
roofline.cpp:295 の main にあるループは、実際に L2 キャッシュに関連したメモリー帯域幅のボトルネックによりパフォーマンスが制限されるため、L2 Bandwidth ルーフラインの上にあります。
メモリー帯域幅のボトルネックを解消する方法として、キャッシュ利用を最適化するためコードを再構成することが考えられます。
roofline.cpp:310 の main にあるループはキャッシュ利用が最適化されているため、このループのドット (前出のルーフライン・グラフの上のドット) は L2 Bandwidth ルーフラインの上にあります。
- サーベイレポートで、roofline.cpp:310 の main にあるループのデータ行をクリックします。
- [Source] タブでソースコードの 97 – 101 行目にスクロールして、関連するデータ構造体の定義を確認すると、配列構造体配列 (AOSOA) であることが分かります。roofline.cpp:310 の main にあるループが AOSOA データレイアウトの場合、このサンプルコードではチュートリアルのワークロードが 2 つのステップ分割され、それぞれのステップのデータセットは L1 キャッシュに収まります。
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex/ (英語) を参照してください。
