
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Advisor Cookbook」の「Model GPU Application Performance for a Different GPU Device」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
このレシピでは、インテル® Advisor の Offload Modeling パースペクティブを実行して、異なる GPU アーキテクチャー上でアプリケーション・パフォーマンスを予測する方法を説明します。
パフォーマンス予測は、次世代の GPU アーキテクチャー向けに次のステップを決定する上で重要な役割を果たします。このような場合、CPU と GPU の実行フローには本質的な違いがあるため、CPU から GPU へのモデル化よりも GPU から GPU へのモデル化のほうが精度は高くなります。
このレシピでは、インテル® Advisor を使用して、Offload Modeling パースペクティブの GPU から GPU へのモデル化フローで SYCL* アプリケーション・パフォーマンスを解析し、アプリケーションをインテル® Iris® Xe MAX グラフィックス (gen12_dg1 構成) にオフロードする利点を予測します。
手順:
コンポーネント
ここでは、このレシピで示す結果を得るために使用したハードウェアとソフトウェアをリストします。
- パフォーマンス解析ツール: インテル® Advisor 2021
スタンドアロン版 (英語) またはインテル® oneAPI ベース・ツールキット (英語) の一部としてダウンロードできます。 - アプリケーション: oneAPI サンプルに含まれる Mandelbrot (英語) サンプル・アプリケーションの SYCL* 実装
- コンパイラー: インテル® oneAPI DPC++/C++ コンパイラー 2021
インテル® oneAPI ベース・ツールキット (英語) の一部としてダウンロードできます。 - オペレーティング・システム: Ubuntu* 20.04
- ベースライン GPU: インテル® Iris® Plus グラフィックス 655
マンデルブロ・アプリケーションの事前収集されたオフロードのモデル化レポートをダウンロード (英語) し、このレシピの手順に従って解析結果を調べることもできます。
必要条件
- oneAPI ツールの環境変数を設定します。
source <oneapi-install-dir>/setvars.sh - GPU カーネルを解析するため、システムを設定 (英語) します。
- マンデルブロ・アプリケーションの SYCL* 実装をビルドします。
cd mandelbrot/ && mkdir build && cd build && cmake .. && make
GPU から GPU へのパフォーマンスのモデル化を実行
インテル® Advisor のコマンドライン・インターフェイス (CLI)、Python* スクリプト、またはインテル® Advisor のグラフィカル・ユーザー・インターフェイス (GUI) を使用して GPU から GPU へのモデル化を実行できます。
このセクションでは、Offload Modeling パースペクティブの特別なコマンドライン収集プリセットと --gpu オプションを使用して、1 つのコマンドで GPU から GPU へのモデル化のすべてのパースペクティブを実行します。
advisor --collect=offload --project-dir=./mandelbrot-advisor --gpu --config=gen12_dg1 -- ./mandelbrot注:
--config オプションで異なる値を指定することで、モデル化するターゲット GPU を変更できます。詳細とオプションの一覧は、config (英語) を参照してください。
このコマンドは、デフォルトの「medium」精度でパースペクティブを実行して、次の解析を 1 つずつ実行します。
- Survey 解析を実行して、ベースライン・パフォーマンス・データを収集します。
- Characterization 解析を実行して、トリップカウントと FLOP を収集し、データ転送をモデル化します。
- ベースラインのインテル® UHD グラフィックス P630 デバイスからターゲットのインテル® Iris® Xe MAX グラフィックスへのパフォーマンスをモデル化します。
重要: コマンドライン収集プリセットは MPI アプリケーションをサポートしていません。MPI アプリケーションを解析 (英語) するには、個別に解析を実行する必要があります。
解析が完了すると、結果のサマリーがターミナルに出力されます。インテル® Advisor の GUI で結果を確認することも、任意のウェブブラウザーでインタラクティブな HTML レポートを確認することもできます。
ターゲット GPU 上のパフォーマンス・スピードアップの検証
このセクションでは、HTML を調査して GPU から GPU へのモデル化の結果を理解します。CLI から、または Python* スクリプトを使用して Offload Modeling を実行すると、HTML レポートが自動生成され、./mandelbrot-advisor/e000/report/advisor-report.html に保存されます。このレポートは任意のウェブブラウザーで開くことができます。
注:
このインタラクティブな HTML レポートでは、左上のドロップダウンを使用して、Offload Modeling と GPU Roofline Insights パースペクティブの結果を切り替えることができます。
[Top Metrics] ペインは、マンデルブロ・アプリケーションの 1 つのコード領域を、ベースラインのインテル® Iris® Plus グラフィックス 655 GPU デバイスからターゲットのインテル® Iris® Xe MAX グラフックス GPU デバイスへオフロードすることで、平均 5.311 倍のスピードアップが得られることを示しています。
[Program Metrics] ペインは、ベースライン GPU 上で測定された実行時間とターゲット GPU 上での予測実行時間を示しています。
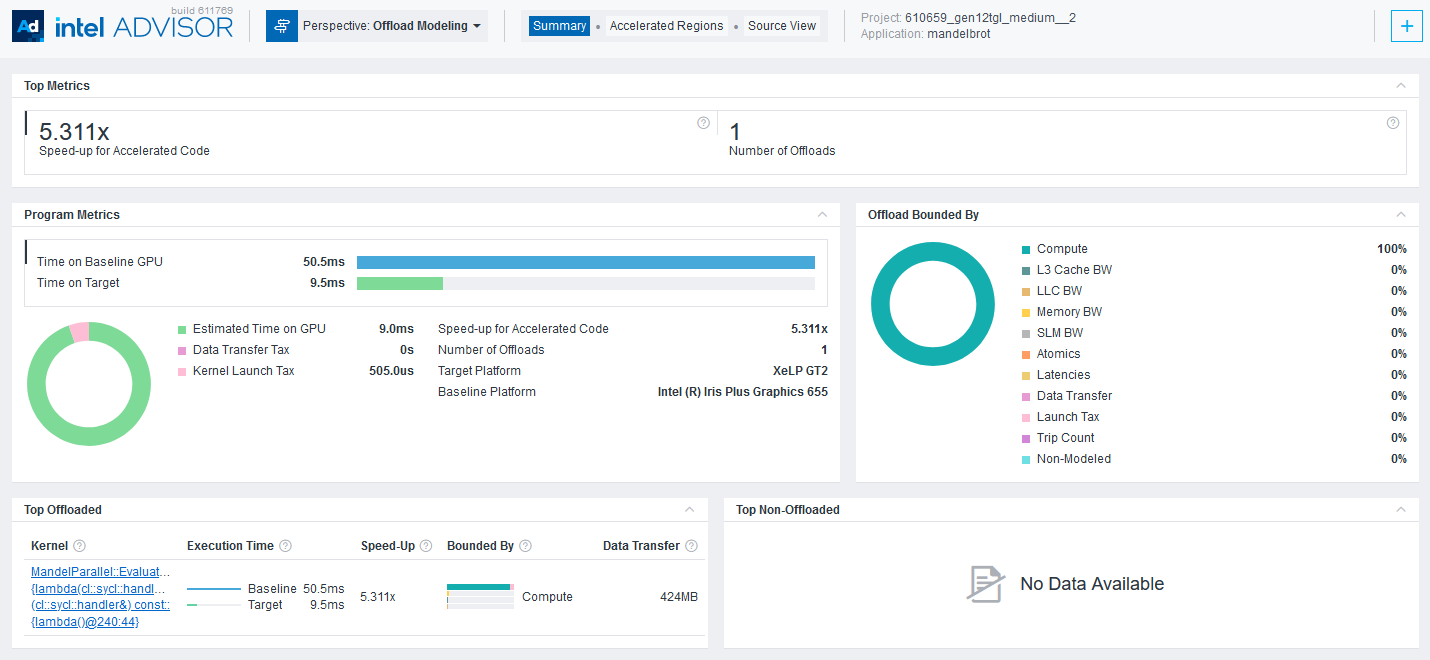
[Summary]、[Accelerated Regions]、および [Source View] タブを利用して、オフロード領域に関する詳細を理解し、有用なメトリックとパフォーマンス・ゲインを調査できます。
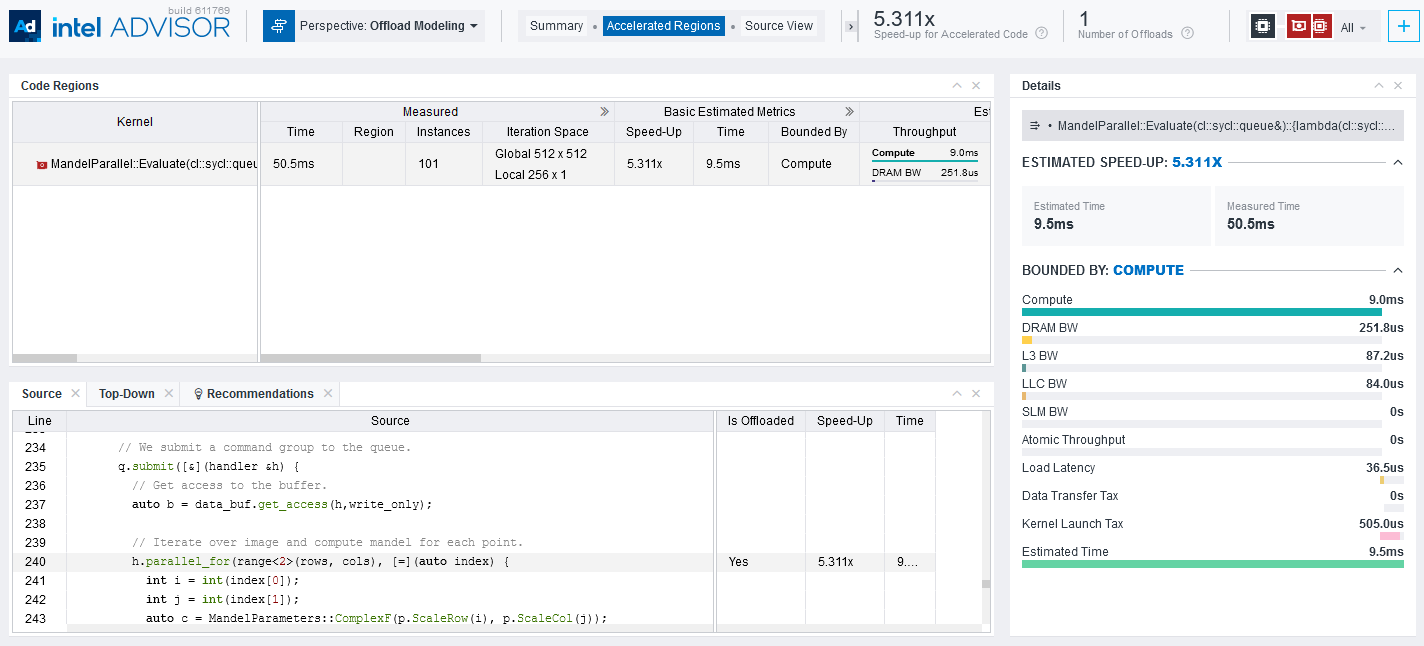
[Accelerated Regions] タブは、オフロードコード領域の詳細な情報と、下部のペインでソースコードを提供します。ここでは、注目するオフロード領域の有用なさまざまなメトリックを調査できます。例えば、ベースライン GPU 上で実行するカーネルでは、測定された反復空間、スレッド占有率、SIMD 幅、ローカルサイズ、グローバルサイズなどのメトリックを調査します。
そして、ターゲット GPU では、パフォーマンスの問題、スピードアップ、再利用とデータ転送などの予測メトリックを調査します。
これらのメトリックの詳細な説明と解釈については、「アクセラレーター・メトリック」 (英語) を参照してください。
別の方法
インテル® Advisor のコマンドライン・インターフェイス (CLI)、Python* スクリプト、またはインテル® Advisor の GUI を使用して GPU から GPU へのモデル化を実行できます。
(Offload Modeling 収集プリセットの代わりに) インテル® Advisor の Python* スクリプトを実行
インテル® Advisor に同梱される専用の Python* スクリプトを使用して、GPU から GPU へのモデル化を実行します。これらのスクリプトは、インテル® Advisor の Python* API を使用して解析を実行します。
例えば、run_oa.py スクリプトと --gpu を使用して、次のように 1 つのコマンドでパースペクティブを実行します。
$ advisor-python $APM/run_oa.py ./mandelbrot-advisor --collect=basic --gpu --config=gen12_dg1 -- ./mandlebrot注:
--config オプションで異なる値を指定することで、モデル化するターゲット GPU を変更できます。オプションの一覧は、config (英語) を参照してください。
run_oa.py スクリプトは、次の解析を 1 つずつ実行します。
- Survey 解析を実行して、ベースライン・パフォーマンス・データを収集します。
- Characterization 解析を実行して、トリップカウントと FLOP を収集し、データ転送をモデル化します。
- ベースラインのインテル® UHD グラフィックス P630 デバイスからターゲットのインテル® Iris® Xe MAX グラフィックスへのパフォーマンスをモデル化します。
重要: コマンドライン収集プリセットは MPI アプリケーションをサポートしていません。MPI アプリケーションを解析 (英語) するには、インテル® Advisor の CLI を使用します。
解析が完了すると、結果のサマリーがターミナルに出力されます。インテル® Advisor の GUI で結果を確認することも、任意のウェブブラウザーでインタラクティブな HTML レポートを確認することもできます。
(Offload Modeling 収集プリセットの代わりに) インテル® Advisor の GUI を実行
必要条件: マンデルブロ・アプリケーションのプロジェクトを作成します。
インテル® Advisor の GUI で GPU から GPU へのモデル化を実行するには、次の操作を行います。
- [Perspective Selector] ウィンドウで [Offload Modeling] パースペクティブを選択します。
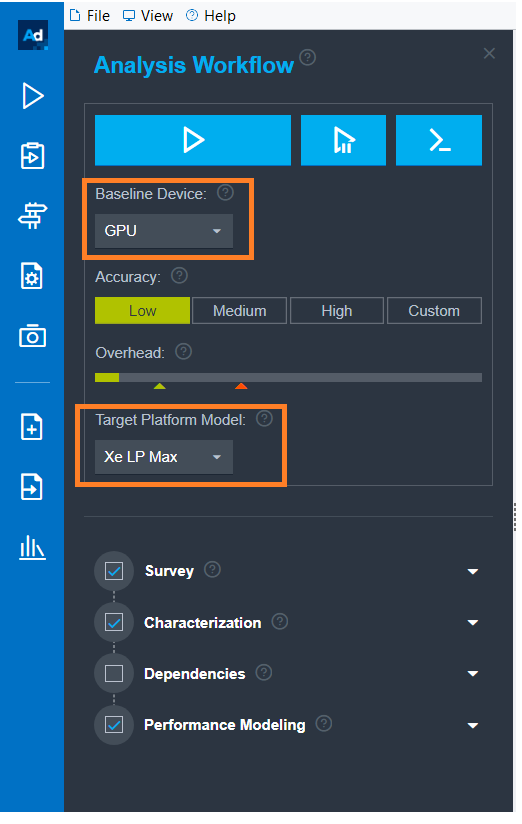
- [Analysis Workflow] ペインで以下を選択します。
- [Baseline Device] ドロップダウンから [GPU] を選択します。
- [Target Platform Model] ドロップダウンから [Xe LP Max] を選択します。
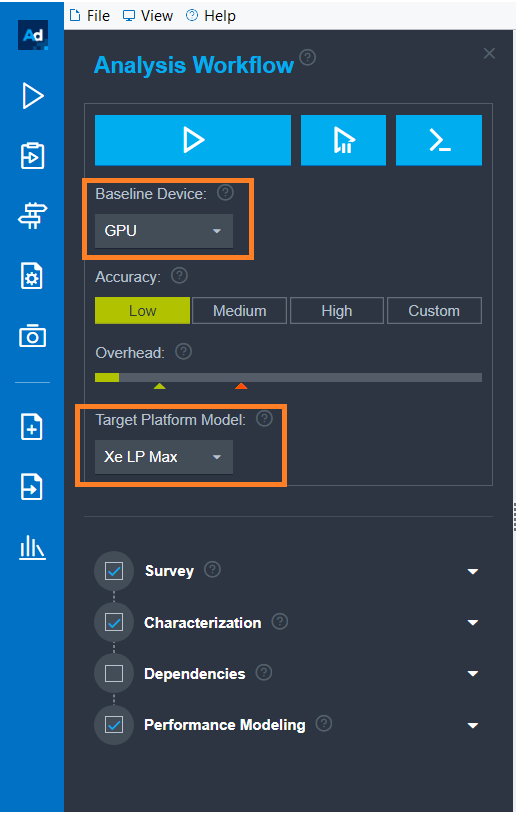
- パースペクティブを実行します。
パースペクティブの実行が完了すると、GPU から GPU へのオフロードのモデル化の結果が右側のペインに表示されます。
要約
GPU から GPU へのモデル化では、ハードウェアがなくても、次世代の GPU 上でのアプリケーション・パフォーマンスをより正確に予測できます。Offload Modeling によって収集されるメトリックは、ベースライン GPU で実行するカーネルのパフォーマンスを理解するのに役立ちます。新しいインタラクティブな HTML レポートは GUI のような体験を提供し、Offload Modeling と GPU Roofline Insights パースペクティブを簡単に切り替えることができます。
