
この記事は、インテル® Advisor 2021 に同梱の「Get Started with Intel® Advisor」 (<install-dir>\documentation\en\welcomepage\get_started.htm) の日本語参考訳です。
目次
デフォルトのインストール・パス
環境設定
ベクトル化が最も有効な場所の特定
ルーフラインを使用したパフォーマンス・ボトルネックの特定
GPU オフロードにより大きな効果が得られる候補の特定
GPU ルーフラインを使用した GPU パフォーマンス・ボトルネックの測定
スレッド化のプロトタイプの作成
関連情報
著作権と商標について
インテル® Advisor は、Fortran、C、C++、.NET (Windows*)、OpenCL*、およびデータ並列 C++ (DPC++) アプリケーションが、最新のプロセッサーで最大限のパフォーマンスを達成できるように支援するツール群で構成されています。
インテル® Advisor は、スタンドアロン製品 (英語) またはインテル® oneAPI ベース・ツールキット (英語) の一部として利用できます。
インテル® Advisor を使用して、次のパースペクティブからコードを解析できます。
- ベクトル化パースペクティブを使用したベクトル化が最も有効な場所の特定。
- CPU ルーフライン・パースペクティブを使用した CPU パフォーマンス・ボトルネックの特定。
- オフロードのモデル化パースペクティブを使用した GPU オフロードによる潜在的なパフォーマンス・ゲインの特定。
- GPU ルーフライン・パースペクティブを使用した GPU パフォーマンス・ボトルネックの特定。
- スレッド化パースペクティブを使用したスレッド化のプロトタイプの作成。
このドキュメントは、インテル® Advisor を使用してアプリケーションの潜在的なパフォーマンス向上を達成する一般的なワークフローについてまとめています。
デフォルトのインストール・パス
Windows* のデフォルトの <install-dir> は、次のとおりです。
- スタンドアロンのインテル® Advisor の場合: C:\Program Files (x86)\IntelSWTools\Advisor (特定のシステムでは、Program Files (x86) の代わりに Program Filesとなります)
- インテル® oneAPI ベース・ツールキットの一部として提供される場合: C:\Program Files (x86)\Intel\oneAPI\advisor\<version> (特定のシステムでは、Program Files (x86) の代わりに Program Filesとなります)
Linux* のデフォルトの <install-dir> は次のとおりです。
- スタンドアロンのインテル® Advisor の場合:
- root ユーザーの場合: /opt/intel/advisor/
- 非 root ユーザーの場合: $HOME/intel/advisor/
- インテル® oneAPI ベース・ツールキットの一部として提供される場合:
- root ユーザーの場合: /opt/intel/oneapi/advisor/<version>
- 非 root ユーザーの場合: $HOME/intel/advisor/<version>
macOS* のデフォルトの <install-dir> は次のとおりです。
- スタンドアロンのインテル® Advisor の場合: /Applications
- インテル® oneAPI ベース・ツールキットの一部として提供される場合: /opt/intel/oneapi/advisor/<version>
環境設定
注: インテル® Advisor のコマンドライン・インターフェイス (advisor) またはコマンドラインから GUI (advisor-gui) 起動する場合、環境変数を設定します。
Windows*:
インテル® Advisor の環境変数を設定するには、<install-dir>\env\vars.bat スクリプトを実行します。
Linux*:
インテル® Advisor の環境変数を設定するには、source <install-dir>/env/vars.sh スクリプトを実行します。
macOS* :
インテル® Advisor の環境変数を設定するには、次のいずれかのコマンドを実行します。
- <install-dir>/env/vars.sh
- <install-dir>/env/vars.csh
インテル® Advisor クックブックの「ローカル macOS* システムからリモートでパフォーマンスを解析し結果を表示」(https://software.intel.com/content/www/us/en/develop/documentation/advisor-cookbook/top/analyze-performance-remotely-and-visualize-results-on-macos.html) で、macOS* マシンで結果を表示する方法の説明をご覧ください。
ベクトル化が最も有効な場所の特定
べクトル化パースペクティブは、ベクトル並列処理から最も恩恵を得られるループを特定するベクトル化解析ツールセットです。サーベイツールを使用してアプリケーションをプロファイルし、ベクトル化されていない、または効率良くベクトル化されていない時間のかかる関数/ループを検出して、ベクトル化により達成されるパフォーマンス・ゲインを計算します。
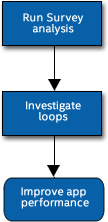
ベクトル化パースペクティブの実行
[解析ワークフロー] ペインで、ドロップダウン・メニューから [ベクトル化とコードの調査] パースペクティブを選択し、データ収集の精度レベルを [低] に設定して、 ボタンをクリックします。パースペクティブを選択すると、インテル® Advisor は実行する解析を自動的に設定します。[精度] ペインで、選択した精度レベルで実行される解析のリストを表示できます。完了するとインテル® Advisor は [サーベイレポート] を表示します。
ボタンをクリックします。パースペクティブを選択すると、インテル® Advisor は実行する解析を自動的に設定します。[精度] ペインで、選択した精度レベルで実行される解析のリストを表示できます。完了するとインテル® Advisor は [サーベイレポート] を表示します。

サーベイレポート – ベクトル化により最も利点が得られる場所、ベクトル化されたループにより利点が得られるかどうかと利点が得られない場合はその理由、ベクトル化できなかったループとその理由、そして一般的なパフォーマンスの問題を示す、コンパイラーの最適化レポートとパフォーマンス・データを統合したものを提供します。
注: Visual Studio* IDE に [ワークフロー] が表示されない場合、インテル® Advisor ツールバーの  アイコンをクリックします。
アイコンをクリックします。
次にすることは?
すべてのループが適切にベクトル化され、パフォーマンスの目標に達成できたら、作業完了です。おめでとうございます!
いくつかのループがベクトル化されず、パフォーマンス目標を達成できていない場合は、以下を考慮してください。
- インテル® Advisor のさまざまな機能を使用してアプリケーションのパフォーマンスを向上させます。
 [パフォーマンスの問題] カラムと関連する [推奨事項] タブの情報。
[パフォーマンスの問題] カラムと関連する [推奨事項] タブの情報。- インテル® Advisor ユーザーガイドの「ベクトル化されていないか、効率良くベクトル化されていないループの調査」の提案。
- さらに詳しく調査するオプションの依存関係とメモリー・アクセス・パターン (MAP) 解析。
- 変更したコードをリビルドします。
- すべてのループが適切にベクトル化され、パフォーマンス目標を達成できたか検証するため、サーベイ解析を再度実行します。
インテル® Advisor クックブックの「MPI アプリケーションのベクトル化とメモリーアクセスを解析」で説明されている、MPI アプリケーションのデータを収集して結果を表示するためのインテル® Advisor のベクトル化およびメモリー固有の機能について調査します。
ルーフラインを使用したパフォーマンス・ボトルネックの特定
CPU ルーフライン・パースペクティブは、ハードウェアによって課せられるパフォーマンスの上限に対して実際のパフォーマンスを視覚化し、主な制限要因 (メモリー帯域幅や計算処理能力) を検証するのに役立ちます。ルーフライン解析を実行すると、インテル® Advisor は次のことを行います。
- サーベイ解析を実行して、マシンのハードウェアの制限を測定し、ループ/関数のタイミングを収集します。
- トリップカウントと FLOP 解析を実行して、浮動小数点と整数操作のデータおよびメモリーデータを収集します。
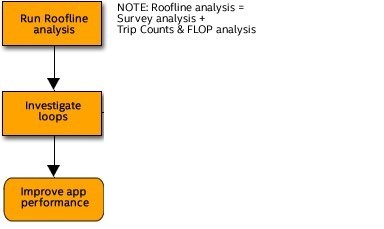
CPU ルーフライン・パースペクティブの実行
[解析のワークフロー] ペインで、ドロップダウン・メニューから [CPU/メモリー・ルーフラインの調査] パースペクティブを選択して、 ボタンをクリックします。完了すると、インテル® Advisor は [ルーフライン] グラフを表示します。
注: Visual Studio* IDE に [ワークフロー] が表示されない場合、インテル® Advisor ツールバーの アイコンをクリックします。
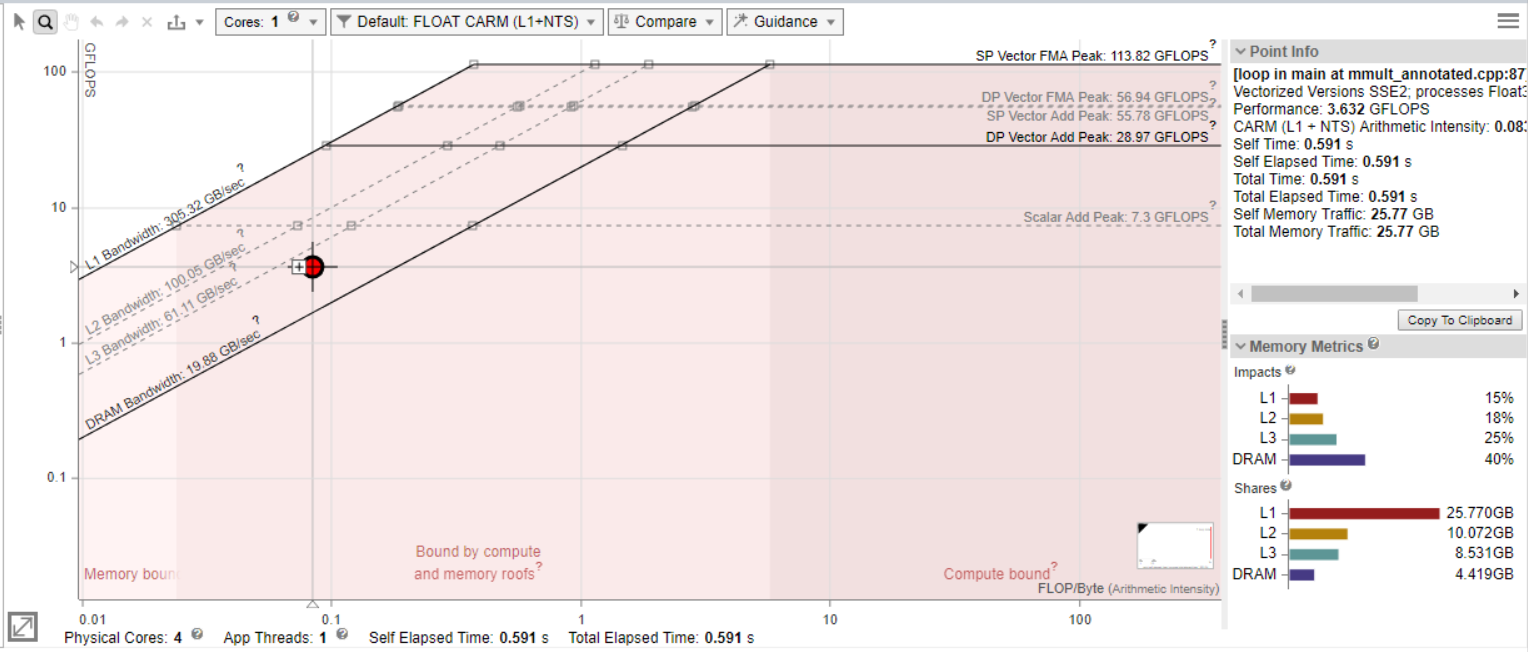
[ルーフライン] グラフは、マシンの達成可能な最大パフォーマンスに対して、アプリケーションのパフォーマンスと演算強度を表示します。
- 演算強度 (x 軸) – CPU/VPU とメモリー間で転送されたループ/関数アルゴリズムに基づく、1 バイトあたりの浮動小数点操作 (FLOP) または 整数操作 (INTOP) の数です。
- パフォーマンス (y 軸) – 1 秒あたりのギガ単位の浮動小数点操作 (GFLOPS) または整数操作 (GINTOPS) の数です。
一般に次のことが言えます。
- [ルーフライン] グラフのドットの大きさと色は、各ループ/関数の相対的な実行時間を示します。大きな赤いドットは最も時間を消費しているため、最適化の最良の候補となります。小さな緑のドットは消費時間が少ないため、最適化する必要はないと考えられます。
- [ルーフライン] グラフの斜線は、最適化なしではループ/関数がパフォーマンスを向上できない、メモリー帯域幅の上限を示します。例えば、[L1 帯域幅] ルーフラインは、ループが常に L1 キャッシュにヒットする場合に、特定の演算強度で実行可能な最大ワーク量を示します。データセットによりループが頻繁に L1 キャッシュをミスする場合、ループは高速な L1 の恩恵を受けられず、実際にヒットする速度が遅い L2 キャッシュの制限を受けます。そのため、L1 キャッシュを頻繁にミスし、L2 キャッシュにはヒットするループを示すドットは、[L2 帯域幅] ルーフライン下に表示されます。
- [ルーフライン] グラフの水平線は、最適化なしではループ/関数がパフォーマンスを向上できない、計算能力の上限を示します。例えば、[スカラー加算ピーク] は、これらの状況下でスカラーループが実行可能な加算命令のピーク数を示します。[ベクトル加算ピーク] は、これらの状況下でベクトル化されたループが実行可能な加算命令のピーク数を示します。ループがベクトル化されていない場合、ループを示すドットは [スカラー加算ピーク] ルーフラインの下に表示されます。
- 最上位のルーフラインはマシンの最大能力を示すため、ドットがこれらのルーフラインを超えることはありません。しかし、すべてのループがマシンの最大能力を活用できるわけではありません。
ドットと達成可能な最上位のルーフとの距離が遠いほど、パフォーマンス向上の可能性は高くなります。
次にすることは?
いくつかのループがベクトル化されず、パフォーマンス目標を達成できていない場合は、以下を考慮してください。
- [ルーフライン] グラフの表示を解釈するため、関連するインテル® Advisor のビューを参照します。例えば、[サーベイサポート] の [ベクトル化されたループ/効率] または、[コード解析] タブのデータを確認します。
- インテル® Advisor のさまざまな機能を使用してアプリケーションのパフォーマンスを向上します。
- [コード解析] タブと関連する [推奨事項] タブの情報。
- インテル® Advisor ユーザーガイドの「メモリーレベル間の関係の調査」の提案。
さらに詳しい情報が必要な場合、次の調査を行います。
 カラムで、より詳細に解析するためループ/関数をマーク (選択) します。
カラムで、より詳細に解析するためループ/関数をマーク (選択) します。- コンパイラーが依存関係を仮定しループ/関数をベクトル化しなかった理由を調査するため依存関係解析を実行し、コストの高いメモリー命令を特定するためメモリー・アクセス・パターン (MAP) 解析を実行します。
インテル® Advisor クックブックの「反復的にボトルネックを特定する: キャッシュを考慮したルーフライン」に記載されている、パフォーマンス・ボトルネックを特定する反復的なアプローチを調査します。
GPU オフロードにより大きな効果が得られる候補の特定
[オフロードのモデル化] パースペクティブを使用すると、GPU にオフロードすることで利点が得られるコード領域とオフロードには向かないコード領域を特定できます。オフロードのオーバーヘッドとともに、アクセラレーターのパフォーマンス・スピードアップを予測し、さらにアクセラレーターのパフォーマンス・ボトルネックを特定します。
オフロードのモデル化パースペクティブの実行
[解析のワークフロー] ペインで、ドロップダウン・メニューから [オフロードのモデル化] パースペクティブを選択し、データ収集の精度レベルを [低] に設定して、 ボタンをクリックします。パースペクティブを選択すると、インテル® Advisor は実行する解析を自動的に設定します。[精度] ペインで、選択した精度レベルで実行される解析のリストを表示できます。完了するとインテル® Advisor は[オフロードのモデル化サマリー] を表示します。
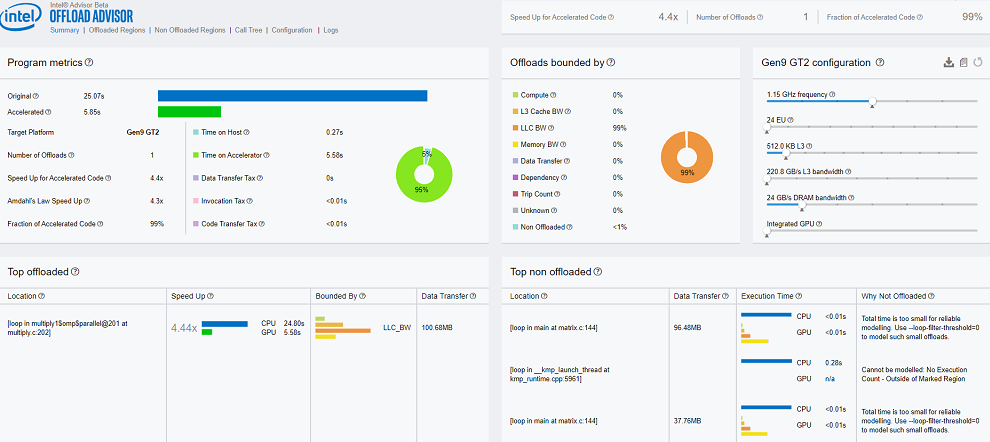
[オフロードのモデル化サマリー] は、ターゲット GPU プラットフォームにオフロードすることで達成可能なアプリケーションの全体的なスピードアップ、呼び出しツリーの上位 5 つのオフロード領域、オフロードの利点がない上位 5 つの領域、関数/ループのオフロード数、および元のコードに対するオフロードされたコードの割合に関する情報を表示します。
CLI インターフェイスを使用してオフロードのモデル化パースペクティブを実行
重要: DPC++、OpenCL*、または OpenMP* ターゲット・アプリケーションを解析する場合、環境変数 INTEL_JIT_BACKWARD_COMPATIBILITY=1 を設定します。
いくつかの方法があります。それぞれの方法は、単純性と柔軟性が異なります。
注: 以下のコマンドで、<APM>はオフロードのモデル化スクリプトのあるディレクトリーを示すインテル® Advisor の環境変数です。Linux* では$APM、Windows* では%APM%に置き換えます。
方法 1: oa.py を実行
この方法は最も簡単ですが、柔軟性が低く、MPI アプリケーションでは使用できません。次に例を示します。
advisor-python <APM>/run_oa.py <project-dir> -- <target> [target-options]
方法 2: collect.py + analyze.py
この方法は簡単で適度な柔軟性がありますが、MPI アプリケーションはサポートされません。collect.py はプロファイルを自動化し、analyze.py はターゲットデバイスでパフォーマンスのモデル化を実装します。次に例を示します。
- アプリケーションのパフォーマンス・メトリックを収集するには、collect.py を実行します。
advisor-python <APM>/collect.py <project-dir> -- <target> [target-options]
- ターゲットデバイス (GPU) で実行されているアプリケーションのパフォーマンスをモデル化するには、analyze.py を実行します。
advisor-python <APM>/analyze.py <project-dir>
注: 並列化されていない領域の依存関係データを収集するには、–collect full オプションを使用して collect.py を実行します。
方法 3: advisor + analyze.py
この方法は最も柔軟性が高く、MPI アプリケーションにも使用できます。この方法を使用するには次を実行します。
- –dry-run オプションを指定してcollect.pyを実行し、構成に対応するコマンドを取得します。
advisor-python <APM>/collect.py <project-dir> --dry-run -- <target> [target-options]
advisor 収集のいくつかのコマンドラインが表示されます。マークアップ・コマンド (advisor-python collect.py –markup <markup-type>) を省略すると、収集のオーバーヘッドは増加しますが、より多くのデータを取得できます。
- 表示されるすべてのコマンドを実行します。次に例を示します。
- サーベイ解析を実行します。
advisor -collect=survey --auto-finalize --stackwalk-mode=online --static-instruction-mix --project-dir=<project-dir> --profile-jit --data-transfer-analysis -- <target> [target-options]
- トリップカウントと FLOP 解析を実行します。
advisor --collect=tripcounts --flop --stacks --enable-cache-simulation --cache-config=<cache-configuration> --enable-data-transfer-analysis --project-dir=<project-dir> -- <target> [target-options]
- [オプション]: 依存関係解析を実行します。OpenMP* や DPC++ などの既存の並列領域の解析には必要ありませんが、デフォルトモードである一般的な解析では強く推奨されます。
advisor --collect=dependencies --loops="scalar" --filter-reductions --loop-call-count-limit=16 --project-dir=<project-dir> -- <target> [target-options]
- サーベイ解析を実行します。
- ターゲットデバイスで実行されるアプリケーションのパフォーマンスをモデル化するには、analyze.py を実行します。
advisor-python <APM>/analyze.py <project-dir>
注: 現在のバージョンでは、OpenMP*、DPC++、oneAPI スレッディング・ビルディング・ブロック (oneTBB)、およびインテル® データ・アナリティクス・アクセラレーション・ライブラリー (インテル® DAAL) の並列領域を解析できます。並列領域にはループ伝搬依存関係がなく、依存関係チェックを行う必要はありません。解析時間を短縮するには、analyze.py で-assume-parallel / –no-assume-parallel オプションを使用して、依存関係チェックをスキップできます。
データ収集後、オフロード・アドバイザーはパフォーマンス予測レポートを生成します。レポートは、report.html ファイルに生成されます。ファイルには複数のセクションが含まれます: サマリー、オフロード領域、非オフロード領域、呼び出しツリー、設定、ログ。左上にあるボックスのリンクを使用して、異なるセクションを切り替えることができます。右上のボックスは、全体のスピードアップ、オフロードされたループと関数の数、およびアクセラレートされたコードをハイライト表示します。
次にすることは?
データ転送解析を実行して、コード領域のデータ転送を調査し、アプリケーションがターゲット GPU プラットフォームでどのように実行されるか正確なデータを取得します。
インテル® Advisor クックブックの「GPU にオフロードするコード領域を特定して GPU の使用状況を可視化する」で説明されている、GPU の使用を最適化する典型的なシナリオを調べます。
GPU ルーフラインを使用した GPU パフォーマンスの測定
GPU ルーフライン・パースペクティブは、ベンチマークとハードウェア・メトリックのプロファイルを使用して、ハードウェアによって課せられるパフォーマンスの上限に対して GPU カーネルの実際のパフォーマンスを推測して視覚化し、主な制限の要因を特定するのに役立ちます。インテル® Advisor で GPU ルーフライン解析を実行します。
- GPU プロファイルとサーベイ解析を使用して、OpenCL* カーネルのタイミングとメモリーデータを収集し、ハードウェアの制限を測定します。
- トリップカウントと FLOP 解析と GPU プロファイルを使用して、浮動小数点と整数操作のデータを収集します。
GPU ルーフライン・パースペクティブの実行
[解析のワークフロー] ペインで、ドロップダウン・メニューから [GPU ルーフラインの調査] パースペクティブを選択して、 ボタンをクリックします。完了すると、インテル® Advisor は [GPU ルーフライン・サマリー] を表示します。[GPU ルーフライン・グラフ] を表示して、アプリケーションのパフォーマンスを制限する主な要因を特定します。
重要: GPU プロファイルは、インテル® プロセッサー・グラフィックスにのみ適用できます。
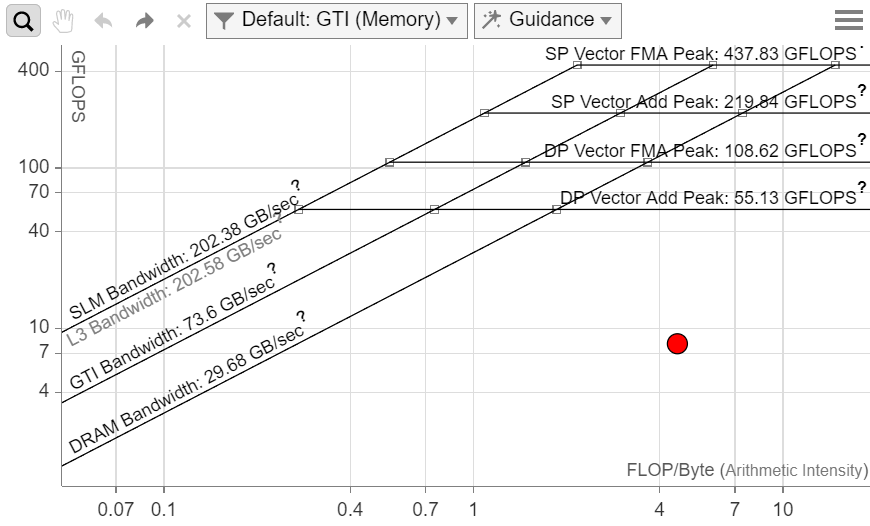
[ルーフライン] グラフは、マシンが達成可能な最大パフォーマンスに対して、アプリケーションのパフォーマンスと演算強度を表示します。
- 演算強度 (x 軸) – GPU とメモリー間で転送されたカーネルのアルゴリズムに基づく、1 バイトあたりの浮動小数点操作の数です。
- パフォーマンス (y 軸) – 1 秒あたりのギガ単位の浮動小数点操作 (GFLOPS) の数です。
一般に次のことが言えます。
- ルーフのドットの大きさと色は、各カーネルの相対的な実行時間を示します。大きな赤いドットは最も時間を消費しているため、最適化の最良の候補となります。小さな緑のドットは消費時間が少ないため、最適化する必要はないと考えられます。
- ルーフの斜線は、最適化なしではカーネルがパフォーマンスを向上できない、メモリー帯域幅の上限を示します。
- L3 キャッシュルーフ: 現在使用しているグラフィックス・ハードウェアの L3 キャッシュの最大帯域幅を示します。最適化されたロード命令のシーケンスを使用して、L3 キャッシュに収まる配列を反復処理して測定します。
- SLM キャッシュルーフ: 現在使用しているグラフィックス・ハードウェアの共有ローカルメモリーの最大帯域幅を示します。SLM のみにアクセスする最適化されたロードおよびストア命令のシーケンスを使用して測定します。
- GTI ルーフ: GPU と残りの SoC 部分との間の最大帯域幅を示します。この推測値は、現在使用しているグラフィックス・ハードウェアの最大周波数を基にした解析式で計算されます。
- DRAM ルーフ: 現在使用しているグラフィックス・ハードウェアで利用可能な DRAM メモリーの最大帯域幅を示します。最適化されたロード命令のシーケンスを使用して、GPU キャッシュに収まらない配列を反復処理して測定します。
- 水平線は、最適化なしではカーネルがパフォーマンスを向上できない計算能力の上限を示します。
- 最上位のルーフラインはマシンの最大能力を示すため、ドットがこれらのルーフラインを超えることはありません。しかし、すべてのループがマシンの最大能力を活用できるわけではありません。
- ドットと達成可能な最上位のルーフとの距離が遠いほど、パフォーマンス向上の可能性は高くなります。
GPU ルーフライン・グラフは、CPU ルーフライン・グラフをベースにしていますが、いくつか違いがあります。
- グラフのドットは、OpenCL* カーネルに対応していますが、CPU バージョンでは個々のループに対応します。
- 表示される情報とコントロールの一部 (スレッド/コア数など) は、GPU ルーフラインにはありません。詳細については次の表を参照してください。
- 統合されたグラフは単一カーネルの複数のドットを示します。これらのドットは、演算強度の計算で使用される各種メモリーレベルに対応しています。ドットにマウスをホバーすると演算強度が分かります。グラフの特定のドットを表示/非表示にするには、[メモリーレベル] ドロップダウン・フィルターを使用します。
次にすることは?
[GPU ルーフライン・サマリー] を使用して、CPU と GPU デバイス実行されるアプリケーションのパフォーマンスを比較します。
インテル® Advisor クックブックの「GPU にオフロードするコード領域を特定して GPU の使用状況を可視化」で説明されている、GPU の使用を最適化する典型的なシナリオを調べます。
スレッド化のプロトタイプの作成
スレッド化パースペクティブを使用すると、並列化に最適な候補を特定し、スレッド化を設定するプロトタイプを作成して、特定の関数/ループの並列処理を妨げるデータ依存関係を確認できます。
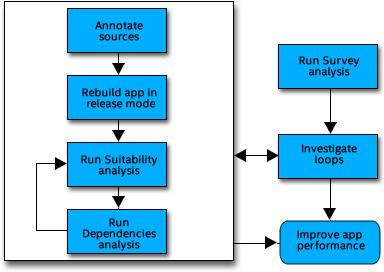
スレッド化パースペクティブの実行
[解析のワークフロー] ペインで、ドロップダウン・メニューから [スレッド化] パースペクティブを選択し、データ収集の精度レベルを [低] に設定して、 ボタンをクリックしパースペクティブを実行します。結果を基に、スレッドを使用した並列化の候補を見つけます。
注: Visual Studio* IDE に [ワークフロー] が表示されない場合、インテル® Advisor ツールバーの アイコンをクリックします。
ソースにアノテーションを挿入
スレッドによる並列実行を可能にする並列フレームワークと置き換え可能な候補となる場所にアノテーション・マークを挿入します。
インテル® Advisor の主なアノテーション・タイプは以下の場所をマークします。
- 並列サイト。並列サイトとは、ワークを分散するため 1 つ以上の並列スレッドで並列に実行する可能性があるタスクを 1 つ以上含むコード領域です。効果的な並列サイトは、一般にアプリケーションの実行時間を消費するホットスポットを含んでいます。頻繁に実行される命令を同時に実行できる異なるタスクに分散する場合、最良の並列サイトは通常ホットスポットではなく、呼び出しツリーの上位にあります。
- 並列サイト内の 1 つ以上の並列タスク。タスクとは、ワークを分散するため 1 つ以上の並列スレッドで実行できる、データを含む多くの実行時間を消費するコード領域です。
- 同期ロックは、並列アプリケーションでデータへの相互排他アクセスが必要な場所を示します。
アノテーションを追加して、[スータビリティー解析] を使用してスレッド化設計のプロトタイプを作成するためアプリケーションをリビルドします。
スータビリティー解析の実行
[解析ワークフロー] ペインで、データ収集の精度レベルを [中] に設定して、アプリケーションの実行中にスータビリティー・データを収集します。完了するとインテル® Advisor は [スータビリティー・レポート] を表示します。
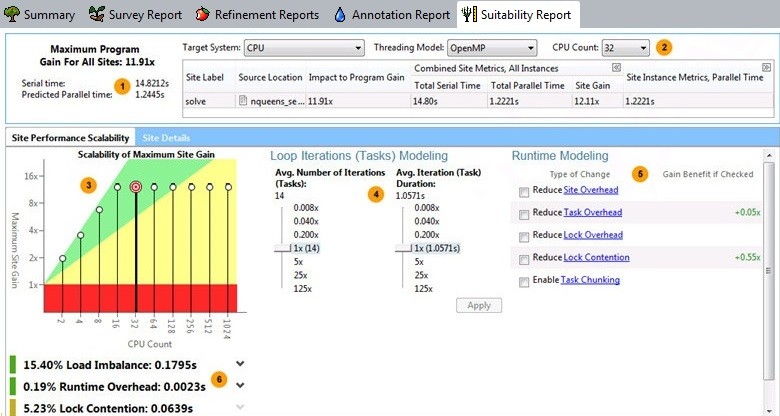
[スータビリティー・レポート] は、挿入されたアノテーションと次のようなモデル化パラメーターに基づいて、アプリケーションの最大スピードアップを予測します。
- 異なるハードウェアと並列フレームワーク
- 異なるトリップカウントと実行時間
- 並列フレームワークのコードをアプリケーションに実装する際の、並列化のオーバーヘッド、ロックの競合、またはタスクのチャンクに関連した対応
結果を基に、スレッド並列処理の最良の候補を見つけます。
依存関係解析の実行
データ収集の精度レベルが [中] に設定されている場合、スレッド化アドバイザーはアプリケーションの実行中に依存関係データを収集します。予測される最大スピードアップによって労力を正当化できる場合、この情報を基にデータ共有の問題を解決します。
次にすることは?
予測される最大スピードアップによってアプリケーションをスレッド化する労力を正当化できる場合、次の作業を行います。
- 提案された並列化の変更に関して、開発者/設計者による設計とコードレビューを行います。
- oneTBB、OpenMP*、Microsoft* タスク並列ライブラリー (TPL) など、アプリケーションの並列プログラミング・フレームワーク (スレッド化モデル) を選択します。
- ビルド環境に並列フレームワークを追加します。
- 共有データリソースへのアクセスを同期するため、oneTBB や OpenMP* ロックなどの並列フレームワークのコードを追加します。
- 並列タスクを生成する並列フレームワーク・コードを追加します。
選択した並列フレームワークから適切な並列コードを追加したら、インテル® Advisor のアノテーションは、コメントアウト、置換、またはそのままにすることができます。
関連情報
| リソース | 説明 |
|---|---|
| インテル® Advisor ユーザーガイド (英語) | コマンドラインの使い方、解析タイプの詳細情報、GUI の使用法などについてはこのガイドを参照してください。 |
| インテル® Advisor ユーザー向けのベクトル化リソース | ベクトル化を適用することでアプリケーションのパフォーマンスを向上するのに役立つリソースを示します。 |
| インテル® Advisor ユーザー向けのルーフライン・リソース (英語) | インテル® Advisor の CPU/GPU ルーフライン・パースペクティブを使用して、ハードウェアによって課せられる上限を特定するのに役立つリソースを示します。 |
| インテル® Advisor クックブック | インテル® Advisor の典型的な使用例を紹介します。手順に従って、さらに多くのコア、ベクトル化、またはヘテロジニアス環境での処理を効率良く利用できるようにします。 |
| フローグラフ・アナライザー・ユーザーガイド | oneAPI スレッディング・ビルディング・ブロック (oneTBB)、OpenMP*、データ並列C++ (DPC++) アプリケーションのフローグラフの可視化と解析に役立つグラフィカル・ツールの情報が得られます。 |
| ローカル macOS* システムからリモートでパフォーマンスを解析し結果を表示 https://software.intel.com/content/www/us/en/develop/documentation/advisor-cookbook/top/analyze-performance-remotely-and-visualize-results-on-macos.html |
macOS* マシンで、インテル® Advisor のパースペクティブの結果を視覚化する手順を説明します。 |
| インテル® Advisor リリースノートと新機能 (英語) | インテル® Advisor の新しい機能を確認できます。 |
| オフラインのリソース | ベクトル化パースペクティブの機能の 1 つに、コード固有のベクトル化の問題を修正する方法を示す GUI 組込みのアドバイスがあります。GUI のアドバイスで示される引数などをすぐに参照できるよう、インテル® Advisor はオフラインのコンパイラーの「ミニガイド」を用意しています。また、ミニガイドと同じ場所には「オフラインの推奨事項」と「コンパイラー診断の詳細」を提供するアドバイス・ライブラリーも用意されています。これらの HTML ファイルに含まれる問題と推奨は、展開/折りたたむことができます。
Linux* ではオフラインのドキュメントは、<advisor-install-dir>/documentation/<locale>/ にインストールされます。 Windows* ではオフラインドキュメントは、<advisor-install-dir>\documentation\<locale>\ にインストールされます。 |
注: ドキュメントを表示する際に、次のような問題が発生することがあります。
- Microsoft* Windows Server* 2012 システム: 信頼済みサイトの警告が表示される。
解析策: [ツール] > [インターネット オプション] > [セキュリティ] タブで、[信頼済みサイト] のリストに about:internet を追加します。追加した項目は、ドキュメントを確認後に削除できます。 - Microsoft* Internet Explorer* 11 ブラウザー: [目次] ペインで項目を選択しても内容が表示されない。
解析策: [ツール] > [インターネット オプション] > [セキュリティ] タブで、[信頼済みサイト] のリストに http://localhost を追加します。追加した項目は、ドキュメントを確認後に削除できます。 - Microsoft Edge* ブラウザー:
- 状況依存ヘルプの呼び出し (F1 キーなど) で、対応する特定のトピックの代わりにドキュメントのタイトルページが開く。
解析策: 別のブラウザーを使用してください。 - ペインの一部しか表示されず、適切なスタイルシートが適用されていない。
解析策: 別のブラウザーを使用してください。
- 状況依存ヘルプの呼び出し (F1 キーなど) で、対応する特定のトピックの代わりにドキュメントのタイトルページが開く。
著作権と商標について
インテル® テクノロジーの機能と利点はシステム構成によって異なり、対応するハードウェアやソフトウェア、またはサービスの有効化が必要となる場合があります。
絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。
実際のコストと結果はシステム構成によって異なります。
本資料は、(明示されているか否かにかかわらず、また禁反言によるとよらずにかかわらず) いかなる知的財産権のライセンスも許諾するものではありません。
本資料で説明されている製品には、エラッタと呼ばれる設計上の不具合が含まれている可能性があり、公表されている仕様とは異なる動作をする場合があります。現在確認済みのエラッタについては、インテルまでお問い合わせください。
インテルは、明示されているか否かにかかわらず、いかなる保証もいたしません。ここにいう保証には、商品適格性、特定目的への適合性、および非侵害性の黙示の保証、ならびに履行の過程、取引の過程、または取引での使用から生じるあらゆる保証を含みますが、これらに限定されるわけではありません。
© Intel Corporation. Intel、インテル、Intel ロゴは、アメリカ合衆国およびその他の国における Intel Corporation またはその子会社の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
本資料は、(明示されているか否かにかかわらず、また禁反言によるとよらずにかかわらず) いかなる知的財産権のライセンスも許諾するものではありません。
本資料で説明されている製品には、エラッタと呼ばれる設計上の不具合が含まれている可能性があり、公表されている仕様とは異なる動作をする場合があります。現在確認済みのエラッタについては、インテルまでお問い合わせください。
インテルは、明示されているか否かにかかわらず、いかなる保証もいたしません。ここにいう保証には、商品適格性、特定目的への適合性、および非侵害性の黙示の保証、ならびに履行の過程、取引の過程、または取引での使用から生じるあらゆる保証を含みますが、これらに限定されるわけではありません。
