
この記事は、インテル® デベロッパー・ゾーンに掲載されている「Use the Intel® SPMD Program Compiler for CPU Vectorization in Games」(https://software.intel.com/en-us/articles/use-the-intel-spmd-program-compiler-for-cpu-vectorization-in-games) の日本語参考訳です。
はじめに
オープンソースの LLVM* (英語) をベースとするインテル® SPMD Program Compiler (英語) (以前のドキュメントでは ISPC と呼ばれていました) は、GNU* コンパイラー・コレクション (GCC) や Microsoft* C++ コンパイラーを置き換えるものではありません。これは、インテル® ストリーミング SIMD 拡張命令 2 (インテル® SSE2)、インテル® ストリーミング SIMD 拡張命令 4 (インテル® SSE4)、インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX)、インテル® AVX2 などの各種命令セット向けのベクトル命令を生成する CPU 対応のシェーダー・コンパイラーであると考えることができます。入力シェーダーやカーネルは C ベースであり、出力は事前コンパイルされたオブジェクト・ファイルとアプリケーションにインクルードされるヘッダーファイルです。使用するキーワードを少なくすることで、コンパイラーは CPU のベクトルユニットにワークを分割する方法を明確に指示できます。
明示的なベクトル化によるパフォーマンスの向上は、開発者がコードベースに直接組込み関数を記述することで達成可能ですが、それは複雑であり保守のコストもかかります。インテル® SPMD Program Compiler のカーネルは、高レベル言語を使用して記述されるため開発コストは低くなります。コードが動作している CPU で最良のパフォーマンスを得るには、複数の命令セットをサポートする最小公分母を提供するよりも、インテル® SSE4 などを使用した方が良いでしょう。
この記事は、開発者にインテル® SPMD Program Compiler カーネルを記述する方法を伝えることを目的としたものではありません。Microsoft* Visual Studio* ソリューションにインテル® SPMD Program Compiler を統合する方法を示し、上位レベル・シェーディング言語 (HLSL) の計算シェーダーをインテル® SPMD Program Compiler カーネルにポーティングする方法を紹介します。インテル® SPMD Program Compiler に関する詳細は、オンライン・ドキュメント (英語) を参照してください。
この記事で提供されるサンプルコードは、インテル® SPMD Program Compiler のベクトル化された計算カーネルをサポートするためポーティングされた Microsoft* DirectX* 12 N 体サンプル (英語) の修正版をベースにしています。これは GPU に対するパフォーマンス比較を提供するものではありませんが、標準スカラー CPU コードからベクトル化された CPU コードへの移行で大幅なパフォーマンス・ゲインが達成可能なことを示します。
オリジナルのサンプルコードの CPU 負荷は非常に軽量であるため、このアプリケーションはゲームそのものを表現するわけではありませんが、複数の CPU コア上でベクトルユニットを活用するパフォーマンス・スケーリングの可能性を示しています。

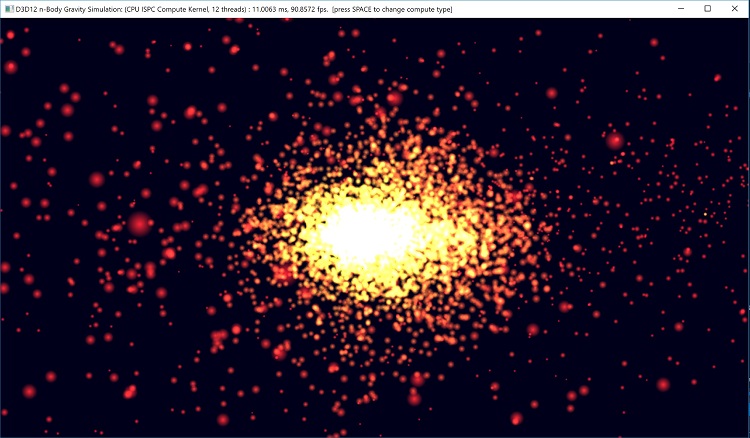
図 1. 修正版 N 体重力サンプルのスクリーンショット
オリジナルの DirectX* 12 N 体重力サンプル
インテル® SPMD Program Compiler へのポーティングを始める前に、オリジナルのサンプルを理解しておきましょう。DirectX* 12 N 体重力サンプルは、DirectX* 12 の異なる計算エンジンを使用して非同期計算を行う方法を紹介するために記述されています。パーティクルのレンダリングは、すべての GPU 上のパーティクルの更新と並列に行われます。サンプルコードは 10,000 個のパーティクルを生成し、各フレームでそれらを更新およびレンダリングを行います。更新にはそれぞれのパーティクルとほかのパーティクルとの相互作用が関連し、シミュレーション・ティックあたり 100,000,000 (1 億) の相互作用が生成されます。
HLSL 計算シェーダーは、計算スレッドをそれぞれのパーティクルに割り当てて更新を行います。パーティクル・データは各フレームでダブルバッファーされ、次のフレームに備えてバッファーを排出する前に GPU がバッファー 1 からレンダリングし、非同期にバッファー 2 を更新します。
非同期計算タスクは CPU 上で完璧に動作するため、インテル® SPMD Program Compiler 向けにポーティングする最適な候補と言えます。コードとエンジンはすでに平行実行パスで計算を行うように設計されているため、負荷の一部を十分に活用されていない CPU に転送することで、CPU を完全に使用する間に GPU はフレームをすばやく完了するかより多くのワークを処理できます。
インテル® SPMD Program Compiler へポーティング
推奨されるアプローチは、最初に HLSL からスカラー C/C++ へポーティングすることです。これにより、アルゴリズムが正しいことを保証し、正しい結果が得られ、ほかのアプリケーションと正確に対話して、必要に応じて複数のスレッドを適切に処理できます。これは些細なことに思われますが、いくつかの考慮すべきことがあります。
- GPU と CPU 間でメモリーをどのように共有するか。
- GPU と CPU 間でどのように同期を行うか。
- SIMD (単一命令/複数データ) とマルチスレッド向けにどのようにワークを分割するか。
- HLSL からスカラー C へのポーティング。
- スカラー C からインテル® SPMD Program Compiler カーネルへのポーティング。
これらの一部はほかよりも容易です。
共有メモリー
私たちは、CPU と GPU 間でメモリーを共有しなければならないことを理解していますが、どのようにしたら良いでしょう? 幸いなことに、DirectX* 12 は GPU バッファーを CPU メモリーにマッピングするなど、いくつかのオプションを提供しています。このサンプルを単純に保ちコードの変更を最小限にするため、GPU パーティクル・バッファーの初期化に使用したパーティクル・アップロードのステージバッファーを再利用し、CPU アクセス用のダブルバッファー化された CPU コピーを作成します。使用モデルは次のようになります。
- CPU からアクセス可能なパーティクル・バッファーを CPU から 更新します。
- GPU パーティクル・バッファーをターゲットとして、元のアップロード・ステージ・バッファーを使用して DirectX* 12 のヘルパー関数 UpdateSubresources を呼び出します。
- GPU パーティクル・バッファーとレンダ―をバインドします。
同期
元の非同期計算コードでは、計算とレンダリング間の相互作用を調整するため DirectX* 12 の Fence オブジェクトがすでに使用されているので、同期は自然に行われます。これは、レンダリング・エンジンがコピーを完了したことを通知するため再利用されます。
ワークの分割
ワークを分割する際、最初に GPU がどのようにワークを分割しているかを考慮すべきです。これは、CPU にそのまま適用できる可能性があるためです。計算シェーダーはワークの分割を制御するため 2 つの方法を使用します。1 つはディスパッチ・サイズであり、コマンドストリームを記録する際に API 呼び出しに渡されるサイズです。これは、実行されるワークグループの次元と数を示します。2 つ目は、シェーダー自身にコピーされるローカル・ワークグループのサイズと次元です。ローカル・ワークグループ内の各項目はワークスレッドであると考えることができ、共有メモリーが使用されている場合、ワークグループ内のそれぞれのスレッドはほかのスレッドと情報を共有できます。
nBodyGravityCS.hlsl 計算シェーダーを見ると、ローカル・ワークグループのサイズは 128 x 1 x 1 であることが分かります。いくつかのパーティクルの負荷を最適化するため共有メモリーを使用しますが、CPU 上では必要ありません。それ以外に、各スレッドが内部ループでほかのすべてのパーティクルと相互に作用しながら、スレッド間の相互作用がなく外部ループとは異なるパーティクルで動作します。
これは CPU のベクトル幅に上手く適合するように思われるため、インテル® AVX2 向けには 128 x 1 x 1 を 8 x 1 x 1 で置き換え、インテル® SSE4 向けには 4 x 1 x 1 で置き換えます。また、コードをどのようにマルチスレッド化するか、そのヒントとしてディスパッチ・サイズを使用できるため、SIMD 幅に応じて 10,000 パーティクルを 8 または 4 で割ることができます。各スレッド間には依存関係がないことが判明しているため、単純にスレッドプールで利用可能なスレッド数、またはデバイス上の利用可能な論理コア (インテル® ハイパースレッディング・テクノロジーが有効な一般的なクアッドコア CPU では 8 コア) でパーティクル数を割ることができました。その他の計算シェーダーをポーティングする際には、さらに考察が必要になるかもしれません。
次のような疑似コードについて考えてみます。
各スレッドで
N 個のパーティクルを処理 (N は 10000/スレッド数)
N の M パーティクルごとに (M は SIMD 幅)
10,000 すべてのパーティクルで相互作用をテスト
HLSL をスカラー C へポーティング
はじめてインテル® SPMD Program Compiler カーネルを記述する場合、最初にスカラー C バージョンを記述することを推奨します。これにより、ベクトル化を開始する前にすべてのアプリケーション周辺コード、マルチスレッド化、およびメモリー操作が動作することを確実します。
そのため、nBodyGravityCS.hlsl のほとんどの HLSL コードは、パーティクルを処理する外部ループを追加し、シェーダーの数学ベクトルタイプを等価な C ベースに変更する以外、最小限の変更で C コードを動作させることができます。この例では、float4/float3 タイプは DirectX* XMFLOAT4/XMFLOAT3 タイプに拡張され、いくつかのベクトル算術操作が等価なスカラー操作に分割されています。
CPU のパーティクル・バッファーは読み取りと書き込みに使用され、書き込みバッファーは前述のように同期に元のフェンスを使用することで GPU へアップロードされます。サンプルをスレッド化するには、マイクロソフト社の並列パターン・ライブラリーの concurrency::parallel_for 構文を使用します。
コードは、D3D12nBodyGravity::SimulateCPU() と D3D12nBodyGravity::ProcessParticles() にあります。
スカラーコードが動作することを確認したら、インテル® SPMD Program Compiler へ移行する前に、解決すべきアルゴリズムのホットスポットがないことを確認するため簡単なパフォーマンス・チェックを行う必要があります。このサンプルでは、インテル® VTune™ Amplifier ツールの基本ホットスポット解析により、ホットなパスで逆数平方根 (sqrt) がハイライトされています。これは、精度低下の顕著な影響なしにわずかなパフォーマンス向上をもたらす、Quake* の高速逆数 sqrt (英語) 近似で置き換えられています。
スカラー C プログラムをスカラーのインテル® SPMD Program Compiler へポーティング
ビルドシステムをインテル® SPMD Program Compiler カーネルをビルドし、アプリケーションとリンクするように変更したなら (Microsoft* Visual Studio* の変更方法については後述します)、インテル® SPMD Program Compiler 向けのコードを記述してアプリケーションにフックすべきです。
フック
アプリケーション・コードからインテル® SPMD Program Compiler カーネルを呼び出すには、関連する自動生成されたヘッダーファイルをインクルードして、通常のライブラリーと同様にエクスポートされた関数を呼び出してます。すべての宣言は、ispc 名前空間でラップされます。この例では、SimulateCPU() 関数内で ispc::ProcessParticles を呼び出しています。
ベクトル演算
フックを定義したら、次はインテル® SPMD Program Compiler のスカラーコードを動作させ、その後にベクトル化します。ほとんどのスカラー C コードは、単純な変更のみでインテル® SPMD Program Compiler カーネルに置き換えできます。この例では、インテル® SPMD Program Compiler はテンプレート付きのベクトルタイプを提供していますが、タイプはストレージのみに必要なため、すべてのベクトル演算タイプを定義する必要があり、新しい構造体を定義しました。これにより、すべての XMFLOAT タイプが Vec3 と Vec4 タイプへ変換されました。
キーワード
ベクトル化とコンパイルを支援するため、インテル® SPMD Program Compiler 固有のキーワードを使用してコードを修飾する必要があります。最初のキーワードは export であり、これは呼び出し規約のように関数シグネチャーで使用され、インテル® SPMD Program Compiler にカーネルのエントリーポイントであることを通知します。これは 2 つのことを意味します。最初に、必要な構造体と自動生成されたヘッダーファイルに関数シグネチャーを追加しますが、すべての引数がスカラーである必要があるため、関数シグネチャーにはいくつかの制限が生じます。varying と uniform の 2 つのキーワードを使用します。
uniform 変数は共有されないスカラー変数を表しますが、その内容はすべての SIMD レーンで共有されます。varying 変数はベクトル化されすべての SIMD レーン間で一意の値を保持します。すべての変数はデフォルトで varying でありキーワードを追加できますが、この例では使用していません。このカーネルのスカラーバージョンを作成する最初の段階では、すべての変数を uniform キーワードで修飾して確実にスカラーであることを保証します。
インテル® SPMD Program Compiler の標準ライブラリー
インテル® SPMD Program Compiler は、高速逆数 sqrt 関数で浮動小数点キャストを行う際に必要な floatbits() や intbits() 関数などポーティングに役立つ多くの共通関数を含む標準ライブラリー (英語) を提供します。
インテル® SPMD Program Compiler のカーネルをベクトル化
インテル® SPMD Program Compiler カーネルが期待どおりに動作したら、ベクトル化に着手します。ここで考慮しなければならないことは、どこをどのように並列化するか決定することです。経験則として、GPU 計算シェーダーをポーティングする際は、複数の GPU 実行ユニットで並列に起動されるコア計算カーネルを持つ GPU ベクトル化の原型に従うことです。そうすることで、スカラーバージョンのパーティクル更新用に外部ループを追加した場合、この外部ループは自然にベクトル化されるはずです。
スキャッター/ギャザー操作は高価なベクトル ISA となる可能性があるため (インテル® AVX2 命令セットでは改善されています)、データのレイアウトも重要になります。通常、頻繁なロード/ストアでは連続したメモリー位置が推奨されます。
並列ループ
N 体の例では、この経験則に従って外部ループがベクトル化され、内部ループはスカラーのまま残されます。したがって、8 つのパーティクルがインテル® AVX レジスターにロードされ、8 個すべてが 10,000 個のパーティクル全体に対してテストされます。この 10,000 個の位置はすべてスカラー変数として扱われ、スキャッター/ギャザーのコストなしですべての SIMD レーンで共有されます。インテル® SPMD Program Compiler は、実際のベクトル幅を隠匿します (実際に知りたい場合を除き)。これは、インテル® SSE4 やインテル® AVX-512 など異なる SIMD 幅を透過的に抽象化します。
ベクトル化は、外部 for ループをインテル® SPMD Program Compiler の foreach ループに置き換えることで実現されます。インテル® SPMD Program Compiler に、N サイズのチャンク (N はベクトル幅) で範囲を反復するように指示します。したがって、foreach ループのイテレーター ii を使用して配列変数を逆参照する場合、ii の値はそれぞれの SIMD ベクトルのレーンでは異なり、各レーンは異なるパーティクルを操作できます。
データレイアウト
ここでデータレイアウトに触れておきます。CPU 上でベクトルレジスターを使用する場合、それらは効率良くロードおよびアンロードされる必要があります。さもないと、大幅なパフォーマンスの低下につながる可能性があります。これを達成するには、ベクトルレジスターは配列構造体 (SoA) のデータソースからロードされたデータを保持する必要があり、メモリー上で連続した数値を単一の命令で直接ワーキング・ベクトル・レジスターにロードできます。これが不可能である場合、隣接しない値をベクトルレジスターにロードするため、低速なギャザー操作を行う必要があり、またデータを再び保存するにはスキャッター操作が必要です。
この例では、多くのグラフィックス・アプリケーションと同様にパーティクル・データは構造体配列 (AoS) レイアウトで保存されています。スキャッター/ギャザーを回避するため SoA への変換が可能ですが、アルゴリズムの性質上外部ループで必要なスキャッター/ギャザーは、内部ループ内の 10,000 個のスカラー・パーティクルを処理するのと比べてコストが少なくなるため、AoS のまま残します。
ベクトル変数
ここでの狙いは、外部ループをベクトル化して、内部ループをスカラーのまま保つことです。そのため、外部ループのパーティクルのベクトル幅は、すべて同じ内部ループのパーティクルを処理します。これを達成するには、pos、vel、および accel を連続して宣言することで、外部ループのパーティクルから、位置、速度、および加速度をベクトルレジスターにロードします。これは、スカラーカーネルに追加した uniform 宣言を削除することで行われますが、インテル® SPMD Program Compiler は変数のベクトル化が必要であることを認識できます。
これは、bodyBodyInteraction と Q_rsqrt 関数を介して、それらがすべて適切にベクトル化されていることを確実にする必要があります。これは、変数のフローに続いてコンパイラーのエラーを確認するだけです。その結果、Q_rsqrt は完全にベクトル化され、bodyBodyInteraction は内部ループのパーティクル位置 thatPos がスカラーであるのを除いてほとんどがベクトル化されます。
これらの作業がすべて行われると、インテル® SPMD Program Compiler のベクトル化されたカーネルを実行でき、スカラーバージョンを上回る優れたパフォーマンスが得られます。
パフォーマンス
修正版の N 体アプリケーションは、2 種類の異なる CPU で検証され、パフォーマンス・データは PresentMon (英語) を使用して取得し、それぞれ 10 秒間の実行を 3 回繰り返したフレーム時間を記録して平均を求めました。スカラー C/C++ コードから、インテル® SPMD Program Compiler カーネルをターゲットとするインテル® AVX2 まで、8 – 10 倍のパフォーマンス・スケーリングを達成できました。2 つのデバイスは Nvidia* 1080 GTX GPU と使用可能なすべての CPU コアを使用します。
| プロセッサー | スカラー CPU 実装 |
インテル® SPMD Program Compiler で コンパイルされた インテル® AVX2 実装 |
スケーリング |
| インテル® Core™ i7-7700K プロセッサー |
92.37ms | 8.42ms | 10.97x |
| インテル® Core™ I7-6950X プロセッサー エクストリーム・ エディション |
55.84ms | 6.44ms | 8.67x |
インテル® SPMD Program Compiler を Microsoft* Visual Studio* に統合する方法
- インテル® SPMD Program Compiler のコンパイラーをパスに定義するか、Microsoft* Visual Studio* から容易に検索できるようにします。
- インテル® SPMD Program Compiler カーネルをプロジェクトにインクルードします。ファイルタイプが認識できないため、デフォルトではビルドできません。
- ファイルを右クリックして、プロパティーで [項目タイプ] が [カスタム・ビルド・ツール] になるようにします。

- [OK] をクリックしてプロパティー・ページを再度開き、カスタム・ビルド・ツールを変更できるようにします。
- 次のコマンドライン形式を使用します。
ispc -O2 <filename> -o <output obj> -h <output header> --target=<target backends> --opt=fast-math
- この例では次のコマンドラインを使用します。
$(ProjectDir)..\..\..\..\third_party\ispc\ispc -O2 "%(Filename).ispc" -o "$(IntDir)%(Filename).obj" -h "$(ProjectDir)%(Filename)_ispc.h" --target=sse4,avx2 --opt=fast-math
- 関連するコンパイラーが生成した出力を追加します (例えば、ie.obj ファイル)。
$(IntDir)%(Filename).obj;$(IntDir)%(Filename)_sse4.obj;$(IntDir)%(Filename)_avx2.obj
- リンク・オブジェクトを Yes (はい) に設定します。

- 次のコマンドライン形式を使用します。
- インテル® SPMD Program Compiler をコンパイルします。正常終了すると、ヘッダーファイルとオブジェクト・ファイルが生成されます。
- プロジェクトにヘッダーを追加して、アプリケーションのソースコードでインクルードします。
- 関連する場所からインテル® SPMD Program Compiler カーネルを呼び出します。カーネルからエクスポートする関数は、インテル® SPMD Program Compiler の名前空間にあります。

まとめ
この記事の目的は、インテル® SPMD Program Compiler を使用して、高度にベクトル化された GPU 計算カーネルを、ベクトル化された CPU コードに簡単に移行できることを示すことでした。これにより余剰の CPU サイクルを完全に活用して、より豊かなゲーム体験をユーザーに提供することができます。スカラーコードの代わりにインテル® SPMD Program Compiler カーネルを使用することで、自然にベクトル化されるワークロードにほとんど手を加えることなくパフォーマンスの向上し、インテル® SPMD Program Compiler を使用することで開発および保守時間を短縮できます。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
