

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Designing Artificial Intelligence for Games (Part 4)」(http://software.intel.com/en-us/articles/designing-artificial-intelligence-for-games-part-4/) の日本語参考訳です。
AI の活用: スレッド化
これまでの記事は、この記事の基礎となるものです。その 1 からその 3 の説明でゲーム AI とは何かを理解し、自身のゲームに実装および適用する方法を検討されていることでしょう。最後にシステムのパフォーマンス向上に取り組むことにしましょう。
どんなに素晴らしいゲーム AI を開発できたとしても、システムが遅くなるのでは意味がありません。効率的なプログラミングと最適化を行うことで、システムのパフォーマンスはある一定までは向上させることができます。しかし、シングルコアの限界を超えるには、並列処理を行う必要があります (図 1 を参照)。

図 1: Blizzard Entertainment* の Starcraft* II では、同時に大量のユニットすべてが独自の AI を実行。並列処理を行う最適な方法はマルチスレッド化。
複数のプロセッサーまたはマルチコア・プロセッサーを搭載したシステムでは、処理を複数のプロセッサーやコアに分割することができます。これには、タスク並列とデータ並列の 2 つのアプローチがあります。
タスク並列
アプリケーションをマルチスレッド化する最も簡単な方法は、特定のタスクに処理を分割することです (図 2 を参照)。ゲームエンジンを構成する異なるタスクは、ほかのシステムと通信できるようにカプセル化されます。
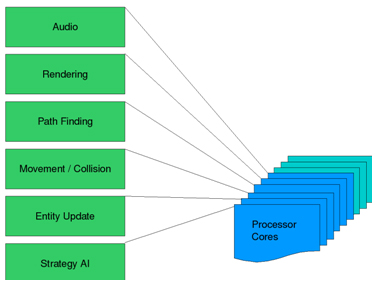
図 2: 機能ごとに並列化して各サブシステムに独自のスレッドとコアを割り当てると、タスクよりもコアの数が多いシステムでは一部のコアが十分に活用されない
例えば、ゲームエンジンのオーディオシステムが良い例です。オーディオはほかのシステムと対話する必要はなく、オンデマンドで音を演奏およびミックスするだけです。通信関数は音を再生および停止するために呼び出されるため、オーディオは独立した機能であり、機能ごとの並列化に最適です。並列化を支援するスレッド化解析ツールを使用すると、オーディオシステムを独自のスレッドに分割して、そのスレッドを実行するコード領域の前後で呼び出すようにできます。
AI システムでこの機能ごとの並列化をどのように利用できるのか確認していきましょう。ゲームの必要に応じて、個々のタスクで、独自のスレッドを処理することになります。ここでは、パス検索、戦略 AI、エンティティー・システムの 3 つについて見ていきます。
パス検索
パス検索を実装する手法として、パスを検索する各エンティティーが、必要な場合に自身のパス検索を行う方法が考えられます。この手法は問題なく動作しますが、パスが要求されるたびに、エンジンはパスファインダーを待つことになります。パス検索を独自のシステムとして再構築すれば、パス検索を独自のスレッドに分割して処理できます。パスファインダーは、(新しいパスをリソースとする) リソース・マネージャーのように機能します。
パスを検索するエンティティーは、パス検索リクエストを送ると、パスファインダーから直ちに「チケット」を受け取ります。このチケットは、パス検索システムがパスの検索に使用する一意のハンドルです。エンティティーは、ゲームループの次のフレームまでこの状態を継続し、チケットがまだ有効かどうかを確認して、チケットが有効な場合はパスを戻します。有効でない場合は待機を続けながら必要な処理を行います。
パス検索システム内で、チケットはパスリクエストを追跡するために使用されます。システムのパフォーマンスに与える影響を心配する必要はありません。このシステムでは、思いがけない副産物として発見したパスの自動追跡が可能になります。以前発見したパスをリクエストすると、パスファインダーは既存のパスへのチケットを渡します。この手法は、多くのエンティティーがパス検索を行うシステムに最適です。そのようなシステムでは、以前見つかったパスを再利用する可能性が高いからです。
戦略 AI
前回の記事で説明したように、ゲーム全体を見渡す AI システムは、独自のスレッドにするのが適切です。この AI は、プレイ領域を分析して、エンティティーが周りを解析できるように、異なるエンティティーにコマンドを送ることができます。
エンティティー・システムは、独自のスレッドで、意思決定マップのための情報を収集します。収集された情報は、意思決定マップの更新リクエストとして戦略 AI システムに送られます。戦略 AI は、更新時にこれらのリクエストを解析して、意思決定マップを更新し、判定を行います。2 つのシステム (戦略 AI とエンティティー) が同期しているかどうかは重要ではありません。AI の決定に影響を与えるほど同期がずれていなければ問題ありません。(ここでの「同期」とは、フレーム単位での話です。プレイヤーは AI の反応が 1/60 秒遅れたとしても気付くことはないでしょう。)
データ並列
機能ごとの並列化は、マルチコアシステムに最適です。ただし、大きな欠点があります。機能ごとの並列化は利用可能なすべてのコアを十分利用しない可能性があります。タスクよりもコアの数が多いと、プログラムが利用しないコアが存在し処理能力を十分に活用できません (プログラムが動作しているプラットフォームによってこの問題が解決される場合を除く。ただし、一般的なアプリケーションの機能には依存するべきではありません)。データ並列 (図 3) の説明に移りましょう。
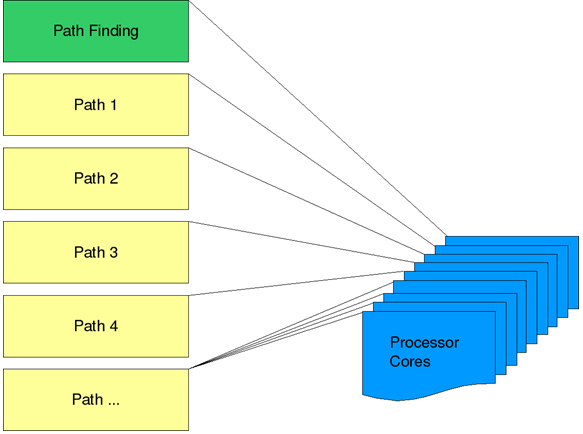
図 3: データ並列では単一の機能がすべての利用可能なコアを利用できる
機能ごとの並列化では、各サブシステムに独自のスレッドを割り当てました。単一のジョブを分割して複数のスレッドで作業を行うことで、システムのコア数に応じてスケールアップすることができます。
8 コアのシステムをお持ちですか? それはいいですね。では 64 コアのシステムはいかがですか? 機能ごとの並列化では指定したコード領域をスレッドとして実行することができますが、データ並列処理をスムーズに実行するには多少の追加作業が必要になります。
その 1 つは、それぞれのスレッドが何を行っているか追跡するコアスレッド (「マスター」スレッド) を使用することです。別のスレッドによって同じタスクが 2 回実行されないように、サブスレッドはメインスレッドに「作業」をリクエストする必要があります。
コアスレッドを使ったデータ並列処理の管理は、実際にはハイブリッド・アプローチです。コアスレッドは機能ごとの並列化を行ってから (タスク並列)、異なるコアにデータを分割して並列に処理します (データ並列)。
実装
OpenMP* (ほとんどのオペレーティング・システムで利用可能) のようなスレッド化ツールを使用すると、コードを個別のスレッドに分割する作業を従来よりも容易に行うことができます。コンパイラー宣言子を使用して分割できるコード領域をマークすると、OpenMP* が残りの処理を行います。作業ブロックで分割するには、前述のリソースを検索するループ内で呼び出しをスレッド化するだけです。
パス検索システムの例では、パスファインダーがリクエストされたパスのリストを管理します。パスファインダーはこのリストをループし、個々のリクエストで実際のパス検索関数を実行して、見つかったパスをパスリストに格納します。このループをスレッド化して、ループの各反復を異なるスレッドに分割することができます。これらのスレッドは利用可能なコアで実行され、処理能力を最大限に活用します。コアがアイドル状態になるのは、何も行うことがなくなったときだけです。
これらのシステムでは、同じジョブに対して複数のリクエストが送られる可能性があります。パスファインダーは、リクエストがすでに処理済みかどうかを自動的に確認します。しかしながら、データ並列処理では、同じパスへの複数のリクエストが同時に発生することがあります。その場合、処理が冗長になり、スレッド化の意味がなくなってしまいます。
この問題やその他の冗長性を回避するには、システムが処理中のタスクを追跡し、処理が完了した後にリクエストキューから削除する必要があります。それには、リクエストが送られたら、パスをチェックしてすでにリクエスト済みの場合は、チケットが割り当てられた既存のパスを返すようにします。
新しいスレッドの生成にはコストがかかります。プロセスはオペレーティング・システム (OS) にスレッド生成のシステムコールを呼び出します。OS は、呼び出しを受け取ると必要なコードをまとめてスレッドを生成します。この処理には時間がかかります (システムの処理速度に依存します)。このため、不必要なスレッドを生成することは避けるべきです。リクエストされたジョブがすでに処理済みの場合、タスクを実行しないでください。また、タスクが非常に単純な場合 (非常に近い 2 点間のパス検索など) は、タスクを細かく分割する価値はないでしょう。
それでは、パス検索関数の機能スレッドが何を行っているか、また作業をどのようにデータスレッドに分割するか、具体的に説明しましょう。
- RequestPath(start, goal) – この関数は、パスファインダーの外で呼び出され、スレッドを取得します。次のタスクを実行します。
- 完了リクエストリストを確認して、パス (またはそれに近いパス) がすでに見つかっているかどうかを判断し、そのパスのチケットを返します。
- (パスがまだ見つかっていない場合) アクティブ・リクエスト・リストにパスがあるかどうかを調べ、パスがあった場合は未解決パスのチケットを返します。
- (パスがアクティブ・リクエスト・リストになかった場合) 新しいリクエストを生成して新しいチケットを返します。
- CheckPath(“ticket”) – この関数は、完了リクエストリストにチケットが有効なパスがあるかどうかを調べて、その結果を返します。
- UpdatePathFinder() – この関数は、パス検索スレッドのオーバーヘッドを制御する保護関数です。次のタスクを実行します。
- 新しいリクエストの解析: 異なるコアから同じパスへの複数のリクエストが同時に送られることがありますが、この領域では冗長性を排除し、同じパスへのそれぞれのリクエストに対してチケットを割り当てます。
- アクティブなリクエストのループ: この関数は、すべてのアクティブなリクエストを調べてスレッド化します。各ループの最初と最後で、スレッドによって実行される領域がマークされ、各スレッドは、(1) リクエストされたパスを検索して、(2) 完了リクエストリストにチケットとともに保存し、(3) アクティブなリストからジョブを削除します。
競合の解決
このセットアップでは問題が発生する可能性があります。例えば、リクエストキューに書き込みを行うスレッドやデータを追加するスレッドが複数ある場合、あるスレッドがスロット A に書き込んでいるときに、同時に別のスレッドがスロット A に書き込みを行うと競合が発生します。この状態は、「競合状態」としてよく知られています。
書き込みの競合を回避するには、そのコード領域をクリティカル・セクションとしてマークします。クリティカル・セクションでは、一度に 1 つのスレッドだけがその領域にアクセスして処理を実行できます。同じクリティカル・’セクションで処理を行う必要がある (同じメモリーにアクセスする) ほかのすべてのスレッドは処理が完了するまで待機します。
この方法では、複数のスレッドが互いにメモリーアクセスをブロックしてしまうと、グリッドロックのような重大な問題が発生します。実際には、このセットアップではグリッドロックは回避されています。スレッドが実際に作業する際には、ほかのスレッドで必要になる可能性のある領域を制限することなく、利用可能な場合にメモリーのクリティカル・セクションへアクセスすることができます。
同期の利用
ここまでで、個別の AI サブシステムをすべて自律型にし、利用可能なすべての処理能力を活用できるようなりました。しかし、動作が速くなっても制御できなくては意味がありません。
ゲームを正しく制御するには、エンジンが同期を保たなければなりません。例えば、ゲーム要素の半分だけを数フレーム先に処理することはできず、対応するユニットがすでに移動しているときに残りのユニットがパスを待ってアイドル状態になっては困ります。つまり、すべてのものを公平に処理する必要があるということです。
ゲームエンジンのメインループは、レンダリングと更新の 2 つを処理します。シリアル・プログラミングでは、これらの処理を同期するのは容易です。最初に、すべての更新を実行し、レンダリングは更新された部分を描画します。並列プログラミングでは、この処理は少し複雑になります。
移動の更新のほうが、レンダラーよりも数フレーム速く実行されます。その結果、アニメーションが滑らかでなくなり、エンティティーがジャンプしているように見えたり、不自然なスピードで移動しているように見えたりします。また、その世界のエンティティーの位置を考慮しなければならないパス検索では、処理に無効なデータが使用される場合もあります。
さまざまなシステム間の同期を保つ方法はかなり単純です。実際に、ほとんどのエンジンではすでにその方法で同期が行われています。メインループが更新されると、ゲームエンジンはグローバル・タイム・インデックスを追跡します。すべてのスレッドは、現在および過去 (将来は含まない) のタイム・インデックスの更新のみを処理する必要があることを確認します。
現在のタイム・インデックスで指定されているタスクのすべての作業が完了すると、スレッドは新しいタイム・インデックスまでスリープすることができます。この動作により、処理が互いに同期されることが保証されるだけでなく、必要のないときにスレッドがコアを利用しないことも保証されます。したがって、移動ジョブは衝突と移動を次々と解決し、その処理が早く終わった場合は、ほかの処理を助けてあげることができます。これにより、利用可能なコアが活用されます。
スレッド化のガイドライン
マルチスレッド・システムを設計する場合、次の点に留意する必要があります。
- 機能の並列化: システムを自律型にできるときに使用します。競合と冗長性を解決するため、いくつかの機能をシステムに追加する必要があります。
- データの並列化:
- 大量の処理を実行するときに使用します。
- ライトバックが最小になるように、またプロセスの最後に行うように設定します。
- ほかのスレッドで編集可能な更新情報を可能な限りまたは全く使用しないようにします (情報が 1/60 秒で古くなるとすれば、どうすればいいのでしょう)。
- 実行に必要な別のシステムからの作業 (「パスのリクエスト」、「パスの確認」) をスレッドが待機しないようにします。
スレッド化するべきでないケース
場合によっては、スレッド化を行わないほうが良いこともあります。OpenMP* のようなツールで、システムで使用するスレッド数を容易に調整することができます。また、インテル® VTune™ Amplifier XE のようなツールを使用すると、さまざまな並列化レベルにおけるシステムの効率を知ることができます。ただし、次のような場合には、スレッド化しないほうが良いでしょう。
- 非常に複雑なシステム: サブシステムが、サブシステムあるいはほかのシステムを絶えず待機させる多くのシステムと連動している場合、スレッド化しないほうが良いでしょう。この場合、システムを再設計することを検討してください。
- 分割できない作業: サブシステムの作業を分割できない場合、並列化はできません。オーディオをミキシングするタスクはスレッドで実行できますが、タスクの作業は最終的にスピーカーに流される複数のチャンネルに複数のサウンドをミックスすることです。システムがミックスを行う前にオーディオの個々のチャンクについて計算を行う場合、その計算をスレッド化することは可能です。
- 高価なオーバーヘッド: 一部のシステム (例えば、パス検索) ではコードの追加が必要になります。そのオーバーヘッドがスレッド化によるメリットよりも大きい場合は、スレッド化を行わないほうが良いでしょう。特に要素 (エンティティー、パス、その他) の数が少ないシステムでは注意が必要です。
- コードの繰り返し: 複数のスレッドが同じコードで生成され、何もしないまま破棄されるか無視されることがあります。そのうちのほとんどは、作業を開始する前に冗長性を確認することで回避できます。
複数のプロセッサーとマルチコア・プロセッサー (および複数のマルチコア・プロセッサー) を利用すると、より適切に最適化を行うことができます。すべてのプログラマーの目標は、利用可能な処理能力を最大限活用することです。システムの AI には、ハードウェアを利用しないことによる制限ではなく、現実のハードウェアによる制限が課せられるべきです。これまでスレッド化を行っていなかった場合でも、最新のツールを使用してコードを設計することで、スレッド化を容易に実装することが可能です。
まとめ
効率良く動作するダイナミックで魅力的な AI システムは容易に構築できます。その最初のステップは効率性と最適化です。タスク並列とデータ並列を活用するようにシステムを構成することで、今後、より多くのコアが搭載されたシステムが標準になっても、システムが可能な限り高速に実行されることを保証できます。
今回の一連の記事で説明したように、ゲーム AI は知的というよりは人工的なものです。現実世界の相当物の動作をエミュレートするように、システム・エージェントの能力を作成するのは、我々プログラマーの仕事です。低レベルのルールやパス検索から高レベルの戦術 AI や戦略 AI まで、基本的なコンポーネントに注目すれば、それほど複雑ではありません。
関連記事
- その 1: 設計と実装
- その 2: 知覚とパス検索
- その 3: 戦術 AI と戦略 AI
- その 4: AI のスレッド化
著者紹介
Donald “DJ” Kehoe: ニュージャージー工科大学の IT プログラムのインストラクターとして、ゲーム開発を分業化し、多くのプログラムのコース (ゲーム・アーキテクチャー、プログラミング、レベルデザイン) や、ゲームと 3D グラフィックスを統合したコースを教えています。現在は、ゲームと仮想世界を利用して神経と筋肉のリハビリテーションの効果を高める研究で、生物工学の博士号取得を目指しています。
著作権と商標について
*StarCraft* II は Blizzard Entertainment, Inc. の商標および登録商標であり、使用許諾を受けて使用しています。
インテル® ソフトウェア製品のパフォーマンス/最適化に関する詳細は、最適化に関する注意事項 (英語) を参照してください。
