
この記事は、The Parallel Universe Magazine 52 号に掲載されている「Accelerate AI with an Intel® End-to-End AI Optimization Kit」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

人工知能 (AI) は、ヘルスケア、小売、製造業など、事実上すべての業界に革命をもたらしました。しかし、今日の AI ソリューションのほとんどは高コストであり、その利用は少数のデータ・サイエンティストに限定されています。これは複数の要因によるものです。第一に、最新のエンドツーエンドの AI パイプラインは複雑です。データ処理、特徴量エンジニアリング、モデルの開発、モデルのデプロイ、保守など、複数の段階が必要です。これらの段階の反復的な性質により、プロセスには時間がかかります。第二に、AI ソリューションの開発には、多くの場合、深い専門知識が必要です。これは、初心者や一般のデータ・サイエンティストにとって参入の障壁となります。第三に、人々は精度を高めるため、より大きく、より深いモデルを開発する傾向があります。これらの「過度にパラメーター化された」モデルは多大な計算量を必要とし、リソースに制約のある環境でのデプロイを妨げます。
インテル® End-to-End AI Optimization Kit (英語) は、エンドツーエンドの AI パイプラインをより高速に、シンプルに、アクセスしやすくし、どこでも、誰でも AI にアクセスできるようにするために開発されました。一般的なハードウェア上でハイパフォーマンスかつ軽量なモデルを効率良く提供する、エンドツーエンドの AI 最適化を実現する構成可能なツールキットです。このツールキットは、PyTorch* 向けインテル® エクステンション (IPEX) (英語)、TensorFlow* 向けインテル® エクステンション (ITEX) (英語)、インテル® AI アナリティクス・ツールキット (AI キット) など、インテルが最適化した一連のフレームワークに基づいて構築されています。また、ハイパーパラメーター最適化のため、SigOpt (英語) を統合します。インテル® End-to-End AI Optimization Kit は、データ準備、モデル最適化、およびモデル構築向けの独自のコンポーネントと機能も提供します。
エンドツーエンドの AI パイプラインのスケールアップとスケールアウトの効率を向上し、複雑なディープラーニング (DL) モデルの「夜間トレーニング」を可能にします。推論スループットが高く、リソース要件が低い軽量の DL モデルを提供します。また、エンドツーエンドの AI をよりシンプルにします。Click-to-Run ワークフローと SigOpt AutoML を使用してパイプラインを自動化し、データ処理と特徴量エンジニアリングの複雑な API を抽象化し、分散トレーニングを簡素化し、既存またはサードパーティーのマシンラーニング (ML) ソリューションやプラットフォームと簡単に統合できます。複雑な計算集約型の DL モデルを一般的なハードウェアで使用できるようにし、Smart Democratization Advisor (SDA) によって生成されたパラメーター化されたモデルを通じてビルトインの最適化されたモデルと、ニューラル・アーキテクチャー検索 (NAS) テクノロジーで構築されたドメイン固有のコンパクト・ニューラル・ネットワークを提供します。これらすべてにより、データ・サイエンティストが AI にアクセスしやすくなります。
アーキテクチャー
さまざまなドメインの一般的なモデル (RecSys、CV、NLP、ASR、RL など) が、インテル® End-to-End AI Optimization Kit (図 1) の入力となります。これらのストックモデルは、重く、トレーニングに時間がかかり、チューニングや最適化が複雑です。モデルの種類に応じて、インテル® End-to-End AI Optimization Kit は、モデル・アドバイザーまたはニューラル・ネットワーク・コンストラクターのいずれかを使用してモデルを最適化します。最適化されたモデルは、FLOPS (1 秒あたりの浮動小数点演算数) とトレーニング時間がストックモデルの 1/10 で済み、精度の低下も同等か最小限に抑えられると期待されます。
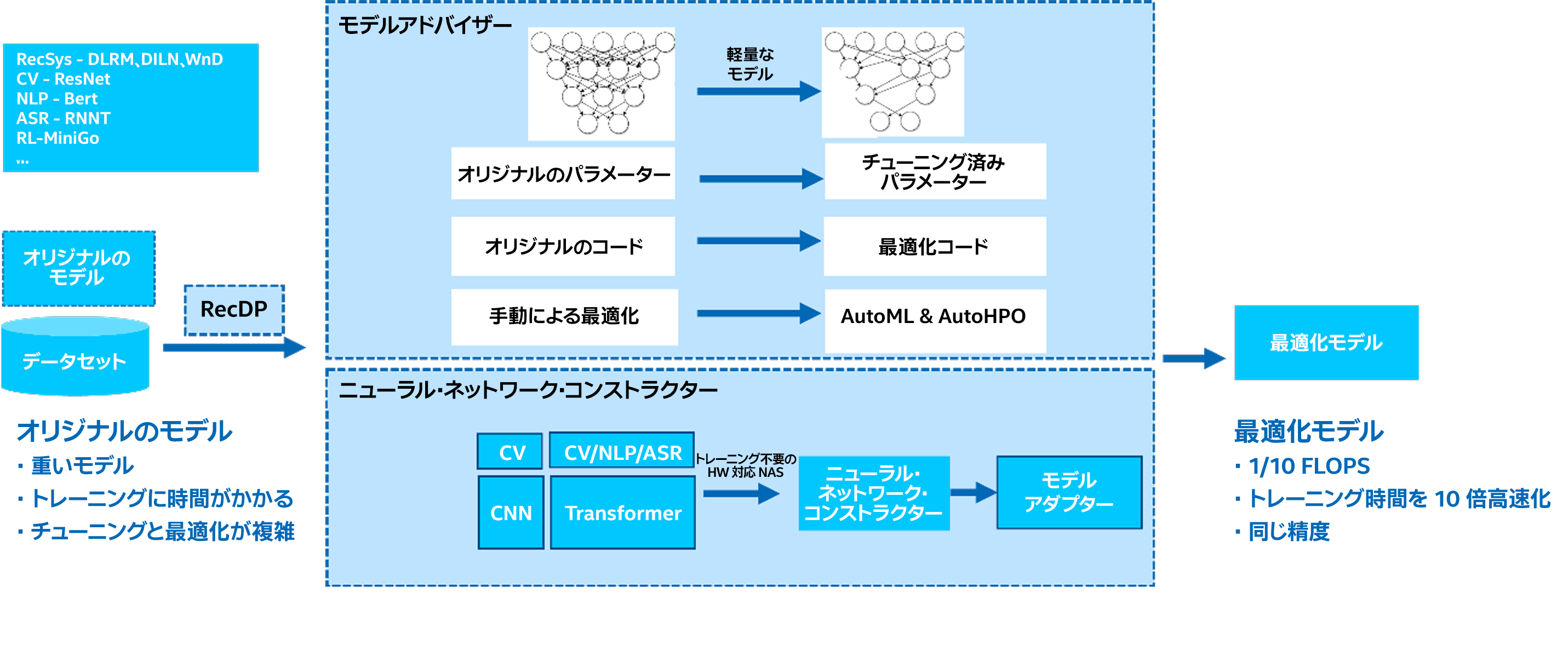
図 1. インテル® End-to-End AI Optimization Kit のアーキテクチャーとワークフロー
RecDP
RecDP は、PySpark* 上に構築された並列データ処理および特徴量エンジニアリング・ライブラリーであり、Modin (英語) などのデータ処理ツールに拡張可能です。主な特徴と機能は次のとおりです。
- 表形式のデータセット処理ツールキット
- Spark* プログラミングの複雑さを隠す抽象 API
- アダプティブ・クエリー・プランと戦略による最適化されたパフォーマンス
- ターゲット・エンコーディングやカウント・エンコーディングなどの一般的な特徴量エンジニアリング機能のサポート
- サードパーティー・ソリューションへの簡単な統合
RecDP は、パフォーマンスを向上するため、「遅延実行」を使用します。操作を融合し、データ統計のコレクションを活用して、データセットの不要なパススルーを回避します。これは、大規模なデータセットを処理する場合に重要です。RecDP は、Optimized Analytics Package for Spark* Platform (英語) によって提供される、ネイティブの単票形式の SQL エンジン機能を活用して、パフォーマンスを向上することもできます。
Smart Democratization Advisor (SDA)
SDA は、自動化を促進するユーザーガイド付きツールです。パラメーター化されたモデルによりビルトインのインテリジェンスを提供し、ハイパーパラメーター最適化 (HPO) およびビルトインの最適化モデル (RecSys、CV、NLP、ASR、および RL など) に SigOpt を活用します。また、手動によるモデルのチューニングと最適化を変換して、AutoML と AutoHPO を支援します。
ニューラル・ネットワーク・コンストラクター
ニューラル・ネットワーク・コンストラクターは、ニューラル・アーキテクチャー検索テクノロジーに基づいています。定義済みのスーパーネットを使用して、特定のドメインのニューラル・ネットワーク構造を直接構築します。主な特徴と機能は次のとおりです。
- CV、NLP、ASR ドメインのモデルなど、マルチモデルのサポート
- 統合された Transformer ベースのスーパーネットを使用
- ハードウェア対応 NAS は、FLOPS やレイテンシーなどのメトリックをしきい値として使用してモデル・アーキテクチャーとモデルサイズを決定
- トレーニング不要の NAS は、候補を評価する際にトレーニング精度ではなく、ゼロコストのプロキシーメトリックを使用。トレーニング可能性、表現力、多様性、顕著性など、複数のネットワークの特徴が考慮されます
- モデルアダプターを活用して、ユーザーの運用環境にモデルをデプロイ。モデルアダプターは、微調整、知識蒸留、およびドメイン適応機能を提供する転移学習ベースのコンポーネントです
例
ここでは、ツールキットが DL 推奨モデル (DLRM) (英語) でどのように機能するか例を紹介します。これには、環境設定、データ処理、ビルトイン・モデル・アドバイザーとパッチコード、および最適化プロセス全体を開始する 1 行のコマンドが含まれます。
