

この記事は、インテル® デベロッパー・ゾーンに掲載されている「Intel® Performance Counter Monitor – A better way to measure CPU utilization」(http://software.intel.com/en-us/articles/intel-performance-counter-monitor) の日本語参考訳です。
目次
- 共著者
- サポートと使用モデル。サポートに関しては、「Software Tuning, Performance Optimization & Platform Monitoring」 (英語) を参照してください。
- インテル® パフォーマンス・カウンター・モニター (インテル® PCM) の概要
- CPU 使用率を解析する
- パフォーマンス・モニタリング・ユニット (PMU) を抽象化する
- 出力イメージ
- コードから PCM を呼び出してリソース認識を有効にする
- リソース認識が有効なプログラムでパフォーマンスを最適化する例
- インテル® PCM 2.0 の機能
- インテル® Xeon® プロセッサー E5 ファミリー固有の機能
- pcm-power ユーティリティー
- Linux* ksysguard および Windows* perfmon GUI 用プラグインの拡張
- インテル® PCM の変更履歴
- 参考文献
- ライセンスとダウンロード
Roman Dementiev、Thomas Willhalm、Otto Bruggeman、Patrick Fay、Patrick Ungerer、Austen Ott、Patrick Lu、James Harris、Phil Kerly、Patrick Konsor
インテル® パフォーマンス・カウンター・モニター (インテル® PCM) の概要
Sandy Bridge EP/EN/E (開発コード名) マイクロアーキテクチャー・ベースのインテル® Xeon® プロセッサー E5 ファミリーをサポートするインテル® PCM 2.0 がリリースされました。バージョン 2.0 の新機能については、「インテル® PCM 2.0 の機能」節で簡単に説明します。
ここ数十年間にコンピューティング・システムは非常に複雑になりました。階層型キャッシュ・サブシステム、NUMA (Non-uniform Memory Architecture)、同時マルチスレッディング、アウトオブオーダー実行はすべて、現代のプロセッサーのパフォーマンスと計算処理能力に多大な影響を与えました。

図 1: 「CPU 使用率」はコア上でスレッドがスケジュールされている時間だけを測定
ソフトウェアは、プロセッサーのリソース使用状況を理解し、それに応じて動的に調整することで、パフォーマンスと消費電力の面で優位に立つことができます。インテル® パフォーマンス・カウンター・モニター (インテル® PCM) は、最新のインテル® Xeon® プロセッサーとインテル® Core™ プロセッサー内部のリソースの使用率を推定し、パフォーマンスを大幅に向上させるための C++ ルーチンのサンプルとユーティリティーを提供します。
オペレーティング・システムから取得した CPU 使用率は、製品のサイジング、処理能力計画、ジョブ・スケジューリングなどの評価基準として、さまざまな目的に使用されてきました。現在の実装 (UNIX* の “top” ユーティリティーや Windows* のタスク マネージャー) では、OS の CPU スケジューラーによってプログラムや OS の実行に割り当てられたタイムスロットは使用中、残りの時間はアイドル状態として表されます。計算を多用するワークロードの場合、現在のシステムと比べてパフォーマンスがより一定で予測しやすかった 1980 年代のアーキテクチャーでは、この方法で計算した CPU 使用率から残りの CPU 処理能力を推定することができました。しかしながら、コンピューター・アーキテクチャーの進化に伴い、マルチコアやマルチ CPU システム、複数レベルのキャッシュ、NUMA、同時マルチスレッディング (SMT)、パイプライン、アウトオブオーダー実行などが登場したことで、この方法では正確な評価基準が得られなくなりました。

図 2: 複雑な最近のマルチプロセッサー、マルチコアシステム
その顕著な例として、インテル® ハイパースレッディング・テクノロジー (インテル® HT テクノロジー) 対応プロセッサーにおける非線形の CPU 使用率が挙げられます。インテル® HT テクノロジーは、パフォーマンスを最大 30% 向上することができる優れた機能です。しかし、HT を知らないエンドユーザーにとって、報告される CPU 使用率は分かりづらいものです。例えば、各物理コア上でシングルスレッドを実行するアプリケーションでは、アプリケーションが実行ユニットの 70% ~ 100% を使用しているにもかかわらず、報告される CPU 使用率は 50% になることがあります。詳細は、巻末の参考文献 [1] を参照してください。
このほかにも、マルチコアシステムで「高いメモリー・スループット」を求めるワークロードの CPU 使用率の例では、メモリーバンド幅テスト用のベンチーマーク “stream” において、利用可能なコア数よりも少ないスレッド数でメモリー・コントローラーの処理能力を超えてしまうことがあります。
幸いにも、インテル® プロセッサーには、プロセッサー内部のパフォーマンス・イベントをモニターするための機能が備わっています。より正確な CPU 使用率を取得するには、インテル® プロセッサーに搭載されているパフォーマンス・モニタリング・ユニット (PMU) の動的データを利用します。ここでは、インテル® Xeon® プロセッサー 5500/5600/7500 番台および E5/E7 ファミリー、ならびにインテル® Core™ i7 プロセッサー・シリーズに実装されている高度な機能について見てみましょう [2-4]。
インテル® PCM には、ユーザーの C++ アプリケーションから呼び出し可能な CPU パフォーマンス評価基準をリアルタイムで提供する、高レベルなインターフェイスを備えた基本的なルーチン群が用意されています。そして、PAPI* や Linux* “perf” のようなほかの既存フレームワークとは対照的に、コアだけでなくインテル® プロセッサー (インテル® Xeon® 7500 番台を含む) のアンコア PMU もサポートしています。アンコアとは、CPU 内臓メモリー・コントローラーやプロセッサーと I/O ハブを接続するインテル® QuickPath インターコネクト (インテル® QPI) を含むプロセッサー部分のことです。インテル® PCM は、次の評価基準をサポートしています。
- コア: リタイアした命令数、経過したコアクロック数、インテル® ターボ・ブースト・テクノロジーを含むコア周波数、L2 キャッシュのヒット/ミス数、L3 キャッシュのヒット/ミス数 (スヌープを含む場合と含まない場合)。
- アンコア: メモリー・コントローラーからの読み込みバイト数、メモリー・コントローラーへの書き込みバイト数、インテル® QPI リンクにより転送されたデータ・トラフィック。
インテル® PCM バージョン 1.5 以降は、インテル® Atom™ プロセッサーもサポートしていますが、メモリー、インテル® QPI バンド幅、L3 キャッシュミスなどのカウンターは常に 0 になります。これは、インテル® Atom™ プロセッサーにオンダイ・メモリー・コントローラー、インテル® QPI リンク、L3 キャッシュがないためです。
インテル® PCM 1.6 は、第 2 世代インテル® Core™ プロセッサー・ファミリー (Sandy Bridge マイクロアーキテクチャー) のオンコア・パフォーマンス評価基準 (クロックサイクルあたりの命令数や L3 キャッシュミスなど) をサポートしています。また、いくつかの古いインテル® マイクロアーキテクチャー (開発コード名 Penryn など) も試験的にサポートしています (cpucounter.cpp で PCM_TEST_FALLBACK_TO_ATOM を定義すると有効になります)。
インテル® PCM の優れた点は、実装されているルーチンを簡単に利用できるようにコマンドライン・ユーティリティーとグラフィカル・ユーティリティーが提供されていることです。これらはすぐに使うことができ、コードにルーチンを追加しなくても、CPU 使用率をリアルタイムでモニターし、確認できます。
図 3 は、Windows* プラットフォーム上のコマンドライン・ユーティリティーのスクリーンショットです。Linux* バージョンでは、Linux* カーネルで提供される MSR モジュールを利用できますが、Windows* ではこれに相当するモジュールがありません。Windows* では、Windows* ドライバーのサンプル実装によって同様のインターフェイスが提供されます。

図 3: インテル® PCM コマンドライン・バージョン
さらに、Linux* オペレーティング・システムでは、KDE ユーティリティー ksysguard にプラグイン可能なアダプターが提供されます。このデーモンを使用することで、各種評価基準をリアルタイムでグラフ化できます。図 4 は、ワークロードの実行中に表示された評価基準のスクリーンショットです。
インテル® PCM 2.0 を使用した場合のスクリーンショットは図 9 と図 10 にあります。

図 4: Linux* の KDE ユーティリティー ksysguard でプラグインを使ってパフォーマンス・カウンターをグラフ化 (インテル® PCM 1.7 を使用)
これらのユーティリティーによりシステム内部を直接観察できるようになるため、基本的なパフォーマンス・ボトルネックをリアルタイムに発見することができます (ただし、インテル® VTune™ Amplifier XE と違い、これらのユーティリティーはアプリケーションのどのコード領域でパフォーマンス問題が発生しているかは通知しません)。
インテル® PCM バージョン 1.5 には、Microsoft* Windows* OS の perfmon プログラムで表示可能なパフォーマンス・カウンターを作成する Microsoft* .NET 2.0 以降ベースの Windows* サービスが含まれています。perfmon は、Windows* OS 上の多くの有益なパフォーマンス・カウンター (ディスク・アクティビティー、メモリー使用量、CPU 使用率など) を表示できます。Windows* 7 と Windows Server* 2008 R2 の perfmon に関する詳細は、こちらを参照してください (perfmon は、ほかの多くの Windows* バージョンでも利用できます)。インテル® PCM 用のサービスをインストール/削除する方法については、Windows_howto.rtf ファイルをお読みください。
Nehalem (開発コード名) と Westmere (開発コード名) ベースのプラットフォームでは、前述のすべてのハードウェア・カウンターに対応する perfmon カウンターが作成されるため、ファイルやデータベースのロギング時間など、perfmon でサポートされているすべての機能を利用できます。インテル® Atom™ プロセッサーでは、前述の理由により、メモリー、インテル® QPI バンド幅、L3 キャッシュミスの perfmon カウンターは常に 0 になります。インテル® PCM の将来のリリースでは、利用可能なカウンターのみが表示されるようになる予定です。

図 5: インテル® PCM 1.7 からのデータを表示している Windows* の perfmon
インテル® PCM の抽象化レイヤーにより、アプリケーションからプロセッサー評価基準を簡単にモニターすることができます。使用前にパフォーマンス・カウンターを初期化し、特定のコード領域の前後でカウンターの状態をキャプチャーします。個々のルーチンは、各コア、各ソケット、またはシステム全体のカウンターをキャプチャーし、対応するデータ構造にカウンターの状態を保存します。追加のルーチンを使用して、この状態から評価基準を計算することもできます。次のサンプルコードはルーチンの使用例を示したものです。
PCM * m = PCM::getInstance(); // program counters, and on a failure just exit if (m->program() != PCM::Success) return; SystemCounterState before_sstate = getSystemCounterState(); [ここに計測するコードを挿入] SystemCounterState after_sstate = getSystemCounterState(); cout << "Instructions per clock:" << getIPC(before_sstate,after_sstate) << "L3 cache hit ratio:" << getL3CacheHitRatio(before_sstate,after_sstate) << "Bytes read:" << getBytesReadFromMC(before_sstate,after_sstate) << [and so on]...
ここでは正確なリソース使用率を取得する利点を評価するため、シングルスレッドで計算を多用するジョブとメモリーバンド幅を多用するジョブをそれぞれ 1,000 ずつ実行する単純なスケジューラーを実装してテストを行いました。一般に、最近のマルチコンポーネント・システムにはサードパーティー製のコンポーネントが多数搭載されているため、テストでは予測不可能なシステムのバックグラウンド処理をどうするかが課題となりました。図 6 は、バックグラウンド・アクティビティーを意識しないスケジューラーによるスケジュール例を示したものです。

図 6: インテル® PCM を使用しないスケジューラー
スケジューラーが (インテル® PCM のルーチンを使用して) メモリーバンド幅の多くが別のプロセスによって使用されていることを検出できれば、スケジュールの調整が可能になります。テストでは、リソースを意識したスケジューラーのほうが、そうでないスケジューラーよりも、2,000 ジョブを 16% 速く処理することができました。

図 7: インテル® PCM を使用したスケジューラー
インテル® PCM 2.0 では、Sandy Bridge EP/EN/E マイクロアーキテクチャー・ベースのインテル® Xeon® プロセッサー E5 ファミリーのサポートが追加されています。このプロセッサーには、さまざまなモニタリング・オプションを備えた新しいアンコアがあります。
インテル® Xeon® プロセッサー E5 ファミリーに関する一般的な情報は、http://www.intel.com/content/www/us/en/processors/xeon/xeon-e5-overview-animation.html を参照してください。
インテル® Xeon® プロセッサー E5 ファミリーに関する技術情報は、http://www.intel.com/content/www/us/en/processors/xeon/xeon-processor-5000-sequence/Xeon5000TechnicalResources.html を参照してください。
以下は、『Intel® Xeon® Processor E5-2600 Product Family Uncore Performance Monitoring Guide』 (英語) から引用したこの新しいプロセッサーの略図です。
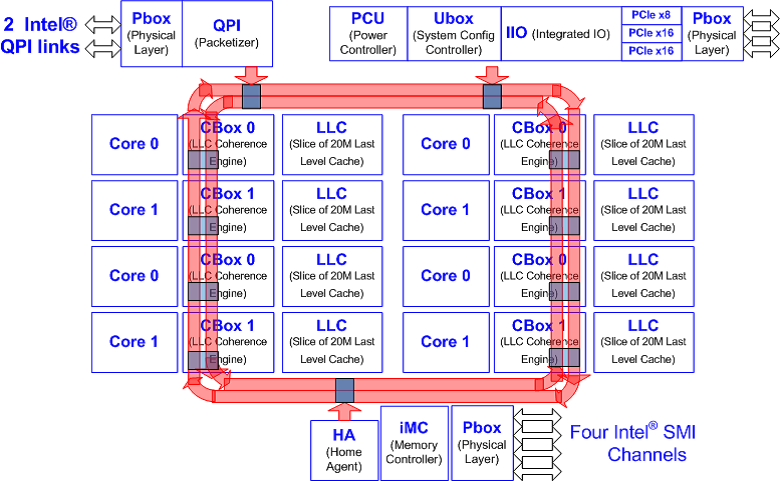
図 8: インテル® Xeon® プロセッサー E5 ファミリーの略図
インテル® Xeon® プロセッサー E5 ファミリーのアンコアには、インテル® Xeon® プロセッサー E7 ファミリー (インテル® Westmere-EX マイクロアーキテクチャー) と同様の複数の "ボックス" があります。インテル® PCM 2.0 は、この新しいプロセッサーのインテル® QPI とメモリーに関する評価基準をサポートしています。
インテル® Xeon® プロセッサー E7 ファミリー (インテル® Westmere-EX マイクロアーキテクチャー) ベースのシステムで、インテル® PCM 1.7 と 2.0 の 'pcm.exe 1' の出力を比較すると、次の点が大きく異なります。
- バージョン 2.0 は、各コアごとに (インテル® Xeon® プロセッサー E5 ファミリーでは各ソケットごとにも) 'TEMP' 列を出力します。'TEMP' は、TjMax 温度 (最大温度) への相対値を摂氏 1 度単位で表したものです。
- バージョン 2.0 は、C ステートのコアとパッケージも表示します。これは、コア (またはパッケージ全体) が C ステートの特定のレベルで費やした時間の割合で表されます。レベルが高くなるほど、より多くの消費電力を抑えることができます。
インテル® Xeon® プロセッサー E5 ファミリー固有の機能
インテル® PCM 2.0 に関する以下の記載は、インテル® Xeon® プロセッサー E5 ファミリー向けです。
インテル® PCM 2.0 では、インテル® QPI 情報が拡張されています。
- QPI 接続速度
- データの受信に使用された QPI バンド幅の割合
- リンクごとのデータおよびデータ以外の送信バイト数と送信リンクの使用率
利用可能なインテル® QPI 情報は、BIOS および BIOS 設定でサポートされているインテル® Xeon® プロセッサー E5 ファミリーのアンコア・パフォーマンス・モニタリング・ユニットに依存します。
インテル® PCM 2.0 は、消費電力も表示します。
- ソケットごとの消費電力
- DRAM の消費電力。BIOS でこの機能がサポートされていない場合、DRAM の消費電力はゼロになります。
インテル® Xeon® プロセッサー E5 ファミリーでは、インテル® PCM 2.0 の pcm-power ユーティリティーを利用できます。Windows* で利用可能なこのユーティリティーの Microsoft* Visual Studio* プロジェクト・ファイルは、PCM-Power_Win ディレクトリーにあります。
pcm-power ユーティリティーで常に表示される情報は次のとおりです。
- 各ソケットおよびインテル® QPI ポートごとに、L0p と L1 低電力ステートで費やされた QPI クロックの割合が表示されます。L0p 省電力ステートでは、QPI レーンの半分が無効になります。L1 ステートでは、すべてのレーンがスタンバイモードになります。これらの評価基準の詳細は、前述の『Intel® Xeon® Processor E5-2600 Product Family Uncore Performance Monitoring Guide』 (英語) の表 2-102 を参照してください。利用可能なインテル® QPI 情報は、BIOS および BIOS 設定でサポートされているインテル® Xeon® プロセッサー E5 ファミリーのアンコア・パフォーマンス・モニタリング・ユニットに依存します。
- 各ソケットごとに、消費電力、ワット数、最大温度が表示されます。
- プラットフォームでサポートされている場合、DRAM の消費電力とワット数が表示されます。サポートされていない場合、これらの値はゼロになります。
pcm-power で '-m' オプションを指定すると、IMC (内蔵メモリー・コントローラー) の PMU (パフォーマンス・モニタリング・ユニット) の電力ステートに関する情報が表示されます。次の値を設定できます。
- '-m 0' は、DRAM のランク 0 とランク 1 の 'CKE off' を表示します。
- 'CKE off' とは DRAM の省電力ステートで、'CKE off' モードで費やされる時間の割合が高いほど DRAM の消費電力が抑えられます。
- ランク 0 とランク 1 は、DRAM の 2 つのランクを指します。
- ほかの '-m' オプションが指定されていない場合、これがデフォルトの IMC PMU 表示になります。
- '-m 1' は、DRAM のランク 2 とランク 3 の 'CKE off' を表示します。
- '-m 2' は、DRAM のランク 4 とランク 5 の 'CKE off' を表示します。
- '-m 3' は、DRAM のランク 6 とランク 7 の 'CKE off' を表示します。
- '-m 4' は、DRAM のセルフリフレッシュを表示します。
- 'セルフリフレッシュ' モードは、DRAM の別の省電力モードです。
- '-m -1' を指定すると、IMC PMU 情報は表示されません。
- DRAM 情報が必要ない場合、このオプションにより出力を減らすことができます。
pcm-power で '-p' オプションを指定すると、PCU (電力制御ユニット) の PMU の電力ステートに関する情報が表示されます。次の値を設定できます。
- '-p 0' は、周波数帯を表示します。
- PCU PMU の周波数帯を使って、コアが 3 つの周波数帯で費やした時間の割合を表示します。
- デフォルトの周波数帯は 10、20、40 です。この値は、それぞれ '-a band0'、'-b band1'、'-c band2' で変更することができます。各周波数帯には 100 MHz が掛けられます。例えば、デフォルトの周波数帯の場合、コアが以下の周波数で費やした時間の割合が表示されます。
- Band0: 周波数 >= 1GHz
- Band1: 周波数 >= 2GHz
- Band2: 周波数 >= 4GHz
- '-p 0' が -p オプションのデフォルトです。
- アイドル状態のシステムで './pcm-power.x "sleep 5" -p 0 -a 0 -b 12 -c 27' を実行すると、次のような出力になります。
S0; PCUClocks: 3994206932; Freq band 0/1/2 cycles: 98.52%; 92.61%; 0.02%
つまり、ソケット 0 の PCU クロック数は 3994206932 で、各周波数帯でプロセッサーが費やした時間の割合は次のとおりです。- band 0: 周波数 >= 0 GHz で 98.52%
- band 1: 周波数 >= 1.2 GHz で 92.61%
- band 2: 周波数 >= 2.7 GHz で 0.02%
つまり、ほとんどの場合、ソケットは最大周波数 (2.7 GHz) またはターボモード (2.8 GHz 以上) に達していません。
- '-p 1' は、C ステートのコア数を表示します。
- 測定期間中、C0、C3、C6 ステートにあったソケット上のコア数が表示されます。
- ビジーなシステムの結果例を次に示します。
S0; PCUClocks: 26512878934; core C0/C3/C6-state residency: 7.28; 0.00; 0.72
つまり、ソケット 0 で測定期間中、それぞれのステートにあったコア数は、C0 (通常状態) が 7.28、C3 (低消費電力ステート) が 0.0、C6 (さらに低い消費電力ステート) が 0.72 です。
- '-p 2' は、Prochot (温度調整) と温度により周波数が制限されたサイクル数を表示します。
- ビジーなシステムの結果例を次に示します。
S0; PCUClocks: 50540355190; Internal prochot cycles: 0.00 %; External prochot cycles:0.00 %; Thermal freq limit cycles:0.00%
つまり、プロセッサーで温度調整が発生しなかったことを示しています。
- ビジーなシステムの結果例を次に示します。
- '-p 3' は、温度/消費電力/現在の使用状況により周波数が制限されたサイクル数を表示します。
- ビジーなシステムの結果例を次に示します。
S0; PCUClocks: 26724849741; Thermal freq limit cycles: 0.00 %; Power freq limit cycles:2.36 %; Clipped freq limit cycles:89.63 %
つまり、ソケット 0 では次のことが言えます。- 温度により周波数が制限された時間の割合は 0.0% です。これは、PCU イベント 0x4 FREQ_MAX_LIMIT_THERMAL_CYCLES を基に計算されます。
- 消費電力により周波数が制限された時間の割合は 2.36% です。これは、PCU イベント 0x5 FREQ_MAX_POWER_CYCLES を基に計算されます。
- 現在の使用状況により周波数が制限された時間の割合は 89.63% です。これは、PCU イベント FREQ_MAX_CURRENT_CYCLES を基に計算されます。
- ビジーなシステムの結果例を次に示します。
- '-p 4' は、OS/消費電力/現在の使用状況により周波数が制限されたサイクル数を表示します。
- ビジーなシステムの結果例を次に示します。
S0; PCUClocks: 26170529847; OS freq limit cycles: 6.09 %; Power freq limit cycles:2.39 %; Clipped freq limit cycles:91.51 %
つまり、ソケット 0 では次のことが言えます。- OS により周波数が制限された時間の割合は 6.09% です。これは、PCU イベント 0x6 FREQ_MAX_OS_CYCLES を基に計算されます。
- 消費電力により周波数が制限された時間の割合は 2.39% です。'-p 3' の 2 つ目のイベントと同じイベントを基に計算されます。
- 現在の使用状況により周波数が制限された時間の割合は 91.51% です。'-p 3' の 3 つ目のイベントと同じイベントを基に計算されます。
- ビジーなシステムの結果例を次に示します。
- '-p -1' を指定すると、PCU PMU 情報は表示されません。
Linux* ksysguard および Windows* perfmon GUI 用プラグインの拡張
コマンドライン・ツールに加えて、Linux* ksysguard 用と Windows* perfmon 用のグラフィカルなプラグインでも、基本的な電力評価基準 (C ステート、最大温度、プロセッサーと DRAM の消費電力) が追加されています。
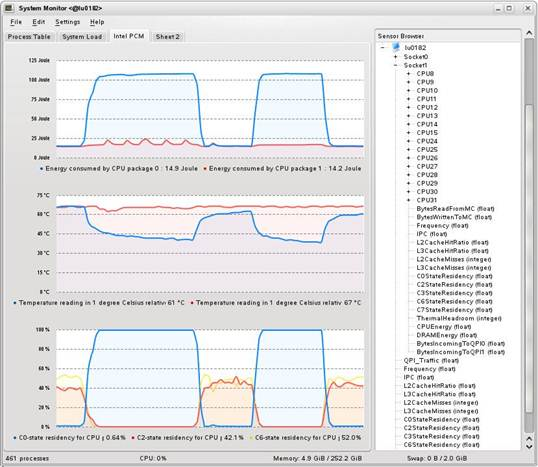
図 9: インテル® PCM 2.0 の Linux* ksysguard 用プラグインの電力評価基準
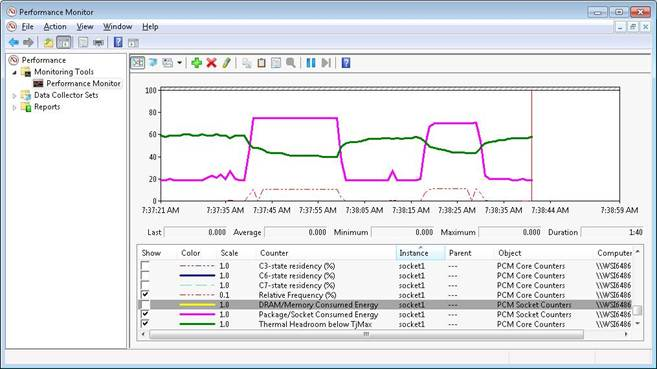
図 10: インテル® PCM 2.0 の Windows* perfmon 用プラグインの電力評価基準
バージョン 1.0
- 初期リリース
バージョン 1.5
- Windows* perfmon との統合
- インテル® Atom™ プロセッサーをサポート
バージョン 1.6
- インテル® Xeon® プロセッサー E7 ファミリー (インテル® Westmere-EX マイクロアーキテクチャー) をサポート
- 第 2 世代インテル® Core™ プロセッサー・ファミリー (Sandy Bridge マイクロアーキテクチャー) のオンコア・パフォーマンス評価基準
- いくつかの古いインテル® マイクロアーキテクチャー (Penryn など) を試験的にサポート (cpucounter.cpp で PCM_TEST_FALLBACK_TO_ATOM を定義すると有効になります。)
- Linux* KDE ksysguard プラグインの拡張
- コマンドライン pcm-ユーティリティーの新しいオプション
- Windows* 7 と Windows Server* 2008 R2 で 65 コア以上をサポート
- ほかのプロセッサーのパフォーマンス・モニタリング・エージェント (インテル® VTune™ Amplifier XE など) との衝突を避けるため『Performance Monitoring Unit Sharing Guide』 (英語) をサポート
バージョン 1.7
- BSD ライセンスの下で配布を開始 (zip に含まれる license.txt ファイルを参照してください。)
- インテル® Nehalem マイクロアーキテクチャー・ベースのほかのプロセッサー・モデルをサポート
- 新しい評価基準: RDTSCP 命令によるタイムスタンプ、C0 アクティブコア、その他の関連する評価基準
- カスタムコア設定機能/モードの拡張
- 問題の修正
バージョン 2.0
- Sandy Bridge EP/EN/E マイクロアーキテクチャー・ベースのインテル® Xeon® プロセッサー E5 ファミリーをサポート
- pcm コマンドライン・ユーティリティーで CSV 形式の出力に対応 (-csv オプション)
- 基本的な電力評価基準をサポート (利用可能な評価基準はプロセッサー・アーキテクチャーにより異なります。): コアとパッケージの C ステート、プロセッサーとメモリー DRAM の消費電力、最大温度
- インテル® Xeon® プロセッサー E5 ファミリー (Sandy Bridge EP/EN/E マイクロアーキテクチャー) で電力のモニタリングを拡張する新しいコマンドライン・ユーティリティー (pcm-power)
- 周波数帯の統計情報
- プロセッサーと DRAM の消費電力
- DRAM のスリープ CKE ステートの統計情報
- DRAM のセルフリフレッシュの統計情報
- QPI 省電力ステートの統計情報
- コアの C ステートの統計情報
- 周波数の制限に関する統計情報
- 2 ソケットのインテル® Xeon® プロセッサー E5 ファミリー (Sandy Bridge EP マイクロアーキテクチャー) 向け OpenGL* 3D 仮想化ツールを試験的にサポート
バージョン 2.1
- 第 3 世代インテル® Core™ プロセッサー・ファミリー (Ivy Bridge (開発コード名) マイクロアーキテクチャー) のオンコア・パフォーマンス評価基準
バージョン 2.2
- SGI UV 2 (最大 256 ソケット) をサポート
- Sandy Bridge E マイクロアーキテクチャー (1 ソケット) のアンコア評価基準をサポート
- pcm-power ツールに周波数の遷移の統計情報を追加
- 問題の修正
バージョン 2.3
- Apple* Mac OS X* 10.7 ("Lion") と OS X* 10.8 ("Mountain Lion") をサポート
- FreeBSD をサポート
- インテル® Xeon® プロセッサー E5 ファミリーでチャンネルごとのメモリー・トラフィックをモニタリングする新しいツール
バージョン 2.3.5
- Linux* perf ドライバーを試験的にサポート (詳細は、Makefile と LINUX_HOWTO.txt を参照してください。)
- Sandy Bridge EP/E マイクロアーキテクチャー・ベースのインテル® Xeon® プロセッサー E5 ファミリーでキャッシュ評価基準値の誤りを修正
- コアの C1 評価基準を追加
- ドキュメントとエラーメッセージを強化
バージョン 2.4
- 内蔵メモリー・コントローラーのカウンターを使用して (http://software.intel.com/en-us/articles/monitoring-integrated-memory-controller-requests-in-the-2nd-3rd-and-4th-generation-intel) 第 2 世代、第 3 世代、および第 4 世代のインテル® Core™ プロセッサーでメモリーバンド幅の評価基準をサポート (Linux*)
- インテル® Xeon® プロセッサー E5 ファミリー・ベースの追加のサーバーシステムでメモリーバンド幅の評価基準をサポート
バージョン 2.5
- 第 4 世代インテル® Core™ プロセッサー (開発コード名: Haswell) をサポート
- インテル® トランザクショナル・シンクロナイゼーション・エクステンション (インテル® TSX) に関連した評価基準 (トランザクションの成功 (合計/トランザクション/アボートのサイクル数) とインテル® TSX のカスタムイベント) をモニタリングするための新しいユーティリティー (pcm-tsx)
- インテル® Xeon® プロセッサー E5 ファミリーで PCIe トラフィックをモニタリングするための新しいユーティリティー (pcm-pcie)
- 新しい PCM::getAllCounterStates 呼び出しによりパフォーマンス・カウンターの読み込みスピードを最大 3 倍向上
- Windows Server* 2012 をサポート
バージョン 2.5.1:
- 内蔵メモリー・コントローラーのカウンターを使用して第 2 世代、第 3 世代、および第 4 世代のインテル® Core™ プロセッサーでメモリーバンド幅の評価基準をサポート (Apple* OS X*)
- インテル® Atom™ プロセッサー S1200 製品ファミリー (開発コード名: Centerton) でオンコア評価基準をサポート
- 問題の修正
インテル® PCM とその使用モデルに関して質問またはご意見がある場合は、Software Tuning, Performance Optimization & Platform Monitoring フォーラム (英語) を利用されることを推奨します。
[1] Drysdale、Gillespie、Valles 著「インテル® ハイパースレッディング・テクノロジーのパフォーマンスに関する考察」 [2] 『Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 3B: System Programming Guide, Part 2』 (英語) [3] 『Intel® Xeon® Processor 7500 Series Uncore Programming Guide』(http://www.intel.com/Assets/en_US/PDF/designguide/323535.pdf (英語)) [4] Peggy Irelan、Shihjong Kuo 著『Performance Monitoring Unit Sharing Guide』 (英語) [5] David Levinthal 著『Performance Analysis Guide for Intel® Core™ i7 Processor and Intel® Xeon™ 5500 processors』 (https://software.intel.com/sites/products/collateral/hpc/vtune/performance_analysis_guide.pdf)Intel、インテル、Intel ロゴ、Intel Atom、Intel Core、VTune、Xeon は、アメリカ合衆国および / またはその他の国における Intel Corporation の商標です。* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。インテル・プロセッサー・ナンバーはパフォーマンスの指標ではありません。プロセッサー・ナンバーは同一プロセッサー・ファミリー内の製品の機能を区別します。異なるプロセッサー・ファミリー間の機能の区別には用いません。詳細については、http://www.intel.co.jp/jp/products/processor_number/ を参照してください。
本資料に含まれるソフトウェア・ソース・コードはソフトウェア・ライセンス契約に基づいて提供されるものであり、その使用および複製はライセンス契約で定められた条件下でのみ許可されます。ソフトウェア・ライセンスに関する記載は、コードサンプルにあります。
インテル® ターボ・ブースト・テクノロジーを利用するには、同テクノロジーに対応したプロセッサーを搭載したシステムが必要です。ご使用のシステムがインテル® ターボ・ブースト・テクノロジーに対応しているかは、各システムメーカーにお問い合わせください。実際の性能はハードウェア、ソフトウェア、全体的なシステム構成によって異なります。詳細については、http://www.intel.co.jp/jp/technology/turboboost/ を参照してください。
結果はインテル社内での分析に基づいた推定値であり、情報提供のみを目的としています。システム・ハードウェア、ソフトウェアの設計、構成などの違いにより、実際の性能は掲載された性能テストや評価とは異なる場合があります。
本ソフトウェアは米国輸出管理規則 (U.S. Export Administration Regulations) およびその他の合衆国法の対象です。米国政府が輸出を禁止している国 (現在、ミャンマー、キューバ、イラン、北朝鮮、スーダン、シリア) への本ソフトウェアの輸出または再輸出は許可されていません。また、米国政府の各政府機関が規定する合衆国からの輸入を禁止されている個人や団体 (取引禁止業者 (Denied Parties)、特別指定国 (Specially Designated Nationals)、合衆国輸出管理局の企業リストにある個人や企業 (Bureau of Export Administration Entity List)、およびミサイル技術、核兵器、化学兵器、生物兵器にかかわる個人や団体を含む) に対しては輸出または再輸出は許可されていません。
インテル® パフォーマンス・カウンター・モニターの提供は終了しました。代替製品である「Processor Counter Monitor」の最新情報は、GitHub* (英語) をご覧ください。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。

コメント
[…] 1. ビルド 1.1 PCMのソースコードをダウンロードして任意の場所に解凍 Intelのサイトからダウンロードします。(ページの一番下です) ダウンロードしたら任意の場所に解凍します […]