 イメージ
イメージ Cinema 4D* でリアルな 3D シーンを作成する
この記事は、インテル® デベロッパー・ゾーンに公開されている「Create Realistic 3D Scenes with Cinema 4D*」( の日本語参考訳です。この記事の PDF 版はこちらからご利用になれます。息を呑むような ...
 イメージ
イメージ 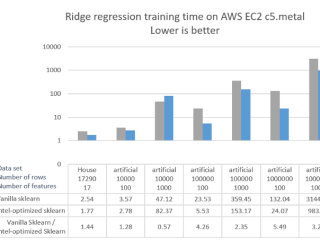 インテル® ディストリビューションの Python*
インテル® ディストリビューションの Python* 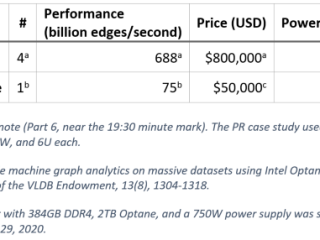 その他
その他  AI
AI 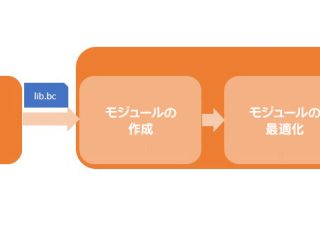 インテル® DPC++/C++ コンパイラー
インテル® DPC++/C++ コンパイラー  AI
AI  インテル® DPC++/C++ コンパイラー
インテル® DPC++/C++ コンパイラー  インテル® GPA
インテル® GPA 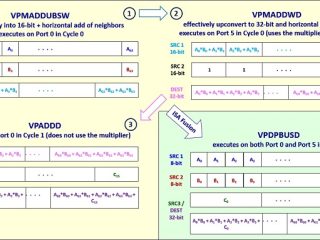 マシンラーニング
マシンラーニング  AI その他
AI その他  HPC
HPC 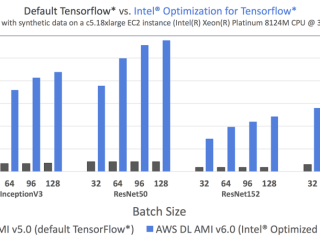 インテル® oneMKL
インテル® oneMKL  インテル® Parallel Studio XE
インテル® Parallel Studio XE 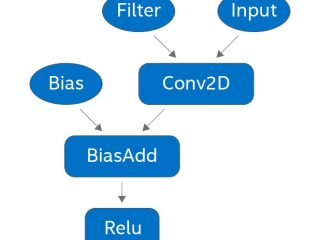 インテル® oneMKL
インテル® oneMKL 