

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Improving the Compute Performance of Video Processing Software Using AVX (Advanced Vector Extensions) Instructions」(http://software.intel.com/en-us/articles/improving-the-compute-performance-of-video-processing-software-using-avx-advanced-vector-extensions-instructions/) の日本語参考訳です。
概要
最近の x86 CPU では、128 ビットのレジスターベクトルで命令レベルの並列処理 (SIMD など) を利用できます。第 2 世代インテル® Core™ プロセッサーは、並列処理を高速化する 256 ビットのレジスターベクトルを利用するインテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) を実装しています。この記事では、インテル® AVX 命令を使用して彩度補正アルゴリズムの計算パフォーマンスを向上するケーススタディーを紹介します。また、将来のインテル® AVX 整数命令により、ビデオ処理アルゴリズムにおいて SIMD 最適化とパフォーマンスをさらに向上する可能性についても触れます。
1. はじめに
最近の x86 CPU では、128 ビットのレジスターベクトルに対して SIMD (Single Instruction Multiple Data) などの命令レベルの並列性 (ILP) を実装しています。これらのレジスターベクトルを使用することで、より少ない命令で複数のデータ要素を処理することができます。第 2 世代インテル® Core™ プロセッサー (開発コード名: Sandy Bridge) は、インテル® ストリーミング SIMD 拡張命令 (インテル® SSE) の 256 ビット拡張である、インテル® AVX を実装しています。
インテル® AVX には、浮動小数点データの算術演算を行う計算負荷の高いアルゴリズムを高速化するさまざまな命令が含まれています。ただし、整数ベースのアルゴリズムであっても、インテル® AVX は計算結果の精度を損ねることなくアルゴリズムのパフォーマンスを向上できる可能性があります。
ビデオ処理アルゴリズムでは、たいていの場合、ピクセルチャネルは 8 ビットの符号なし整数 (バイト) として格納され、32 ビットまたはそれよりも大きなサイズの整数として処理されます。そのため、ほとんどのビデオ処理アルゴリズムではピクセルの型変換が必要になります。計算の精度を上げるにはより広いビット幅が使用され、格納領域を減らすにはより小さな型が使用されます。通常、浮動小数点演算は変換コストがかかるわりに大幅に精度が向上しないため使用されません。しかしながら、インテル® AVX は、並列性を高めることで、ビデオ処理ソフトウェアやその他多くのソフトウェアのパフォーマンスを大幅に向上することができます。
この記事は、インテル® AVX 命令を使用して彩度補正アルゴリズム (一般的なビデオフィルター) のパフォーマンスを向上するケーススタディーについて説明します。SIMD を使用していない状態のアルゴリズムを、インテル® AVX ベースの SIMD を活用するものに変更します。さらに、将来のインテル® AVX 2 命令による、ビデオ処理アルゴリズムの最適化とパフォーマンスのさらなる向上の可能性についても触れます。
2. インテルの SIMD 命令について
インテルの SIMD アーキテクチャーでは、ベクトルレジスターは単一のデータ型 (例えば、float や整数など) 要素をグループで格納することができます。Sandy Bridge✝ のベクトルレジスターは 256 ビットで、その他のインテル® Pentium® III プロセッサー以降のすべてのプロセッサーでは 128 ビットです。256 ビットのベクトルレジスター (Sandy Bridge✝ では YMM と呼ばれる) は、8 個の float、8 個の 32 ビット整数、32 個の char などを格納することができます。インテル® ストリーミング SIMD 拡張命令 (インテル® SSE) は 128 ビットのみ処理可能です。
SIMD 対応のプロセッサーは、複数のデータに対して単一の演算処理を実行できます。複数のデータ要素に対して同時に演算処理を実行することをベクトル処理といいます。SIMD ベクトル化とは、アルゴリズムをスカラー実装からベクトル実装に変換する処理を指します。以下の multiply 関数のサンプルコードを使って、スカラー処理と SIMD ベクトル処理の違いを見てみましょう。
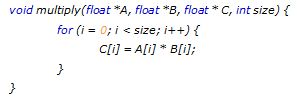

図 1:
この図は、スカラー処理とベクトル処理の違いを示しています。スカラーバージョンでは、16 個のロード、8 個の乗算、8 個のストアになります。インテル® SSE では、4 個のロード、2 個のベクトル乗算、2 個のストアで、インテル® AVX では、2 個のロード、1 個のベクトル乗算、1 個のストアです。VMUL は、それぞれの実装におけるベクトル乗算命令を表します。VMUL は、ベクトル A と B の各要素ペアの乗算を行い、結果を別のベクトルにストアします。
ここでは、ロードとストアには 3 サイクルが、すべての乗算には 1 サイクルがかかると仮定し、パイプラインの動作は無視します。スカラーバージョンでは 8 個の要素を計算するのに 80 サイクルかかりますが、インテル® AVX バージョンでは 10 サイクルだけで済み、理論的なスピードアップは 8 倍になります。このことから、SIMD ベクトル化がアプリケーションのパフォーマンスを最適化する上でいかに重要であるかは明らかです。また、SIMD を使用することでパフォーマンスが向上することから、自動 SIMD ベクトル化は高度なコンパイラーにおいて重要な機能になりました。
3. ビデオ処理コード
一般的なビデオ処理アルゴリズムは、各フレーム、各 X、各 Y を処理する 3 つの for ループを使用してピクセル値を計算します。通常、ここが CPU 利用率の高い領域 (つまり、hotspot) として顕著に現れます。ビデオ処理アプリケーションの hotspot は、インテル® AVX を使用して最適化するのに適しています。
SIMD を使用して最適化する簡単な方法は、インテル® AVX のような最新のプロセッサー技術の機能を利用することです。後続のセクションでは、インテル® AVX 命令を使用して彩度補正アルゴリズムのパフォーマンスを向上する最適化プロセスを説明します。まず、シリアルコードの実装について簡単に説明し、その後、インテル® AVX ベースの SIMD 命令を使って彩度補正アルゴリズムを最適化します。そして最後に、最適化したコードのパフォーマンス結果を検証します。
3.1. 彩度補正 – サンプルコード
彩度補正アルゴリズムの一般的な実装は、入力ピクセル値を使って輝度を計算します。計算された輝度は、イメージの彩度を補正するため、ビデオの出力処理の一部としてすべての出力ピクセルに適用されます。
以下のサンプルコードから分かるように、アルゴリズムは 1 行ずつ走査してピクセルデータを取得し、そのチャネル値 (青、緑、赤) を使って輝度を計算します。高い精度を得るため、1 バイトのチャネル値は単精度浮動小数点値に変換し、輝度を計算するためのドット積のような演算で使用しています。ピクセルチャネル値のバイトから float への変換は fLuminace(…) 関数で行っています。float への変換は各チャネル値を float 型にキャストすることで暗黙に行われ、fLuminance(…) 関数は重み付け (青、緑、赤の定数) を加味して、float 値を使って輝度を計算します。


チャネルデータのバイトから float への変換は、float への型キャストにより暗黙に行われます。スカラーコードは単純で分かりやすいように見えますが、コンパイラーにより生成されるアセンブリー・コードはやや複雑です。生成されたアセンブリー・コードを解析すると、より効率良いインテル® AVX 命令を使用することで、バイトから float への暗黙の変換をより少ない命令で実行できることが分かります。前述のように、シリアルコードでは一度に 1 つのチャネルと 1 つのピクセルの計算を行います。並列に計算されるものは全くありません (パイプラインと再配置は無視します)。アセンブリー・コードは、付録 A を参照してください。
3.2. 彩度補正 – インテル® AVX による最適化
このセクションでは、シリアルコードの変換について説明し、インテル® AVX、インテル® ストリーミング SIMD 拡張命令 4.1 (インテル® SSE4.1)、およびインテル® ストリーミング SIMD 拡張命令 2 (インテル® SSE2) により、どのように彩度補正アルゴリズムを最適化できるか見ていきましょう。セクション 2 の SIMD で説明したように、一度に複数のデータ要素を処理します。つまり、ロード、ストア、変換、算術演算を並列に処理することができます。以下のアルゴリズムは、(インテル® AVX 命令により) 命令レベルの並列処理を利用し、パフォーマンスを大幅に向上させます。このアルゴリズムでは、利用可能な命令だけを使用して記述されています。これは、後述する将来の命令では理想的ではありません。例えば、行 19、20、21 は中間ステップで、32 ビットの整数を 8 ビットの符号なし整数に変換したり、その他の処理を行っています。

図 2. 彩度補正アルゴリズム
図 2 の彩度補正アルゴリズムをベースに実際のコードを実装してみましょう。図 2 と 3 のようなプロシージャーを採用する理由は、次のとおりです。
- インテル® AVX は、従来の x86 のインテル® ストリーミング SIMD 拡張命令 (MMX、SSE、SSE2、SSE3、SSE4.1、SSE4.2) よりも単精度浮動小数点ユニットの並列処理で優れたスループットを発揮する。
- SIMD によるバイト (8 ビットの符号なし char) から整数 (32 ビットの符号付き整数)、そして単精度浮動小数点 (32 ビットの float) への型キャストとその逆の型キャストは、バイトや整数を使用する同等のコード (スカラー) を複数回呼び出すよりもコストが低い。
- このプロシージャーでバイトベースの SIMD を使用すると、精度が低くなる。並列パフォーマンスは考慮されない。
- このプロシージャーで整数ベースの SIMD を使用すると、許容範囲の精度が得られる。現在、インテル® AVX 命令は整数演算に対応していないため、256 ビット・レジスターを最大限に利用することができない。
- このプロシージャーで float ベースの SIMD を使用すると、高い精度と前述よりも優れたパフォーマンスが得られる。


図 3. インテル® AVX により最適化された彩度補正コード1
図 2 および 3 のアルゴリズムとインテル® AVX コードは、比較しやすいように行単位で処理を対応させています。行 9 と 16 だけが実際の計算処理を行っているのが分かります。これらの行では、16 個の乗算命令を実行する代わりに、8 個の単精度浮動小数点の乗算を並列に実行し、2 つの命令で合計 16 個の乗算を行っています。この 2 つの行以外は、並列命令や精度を向上させるためのオーバーヘッドです。
これらのオーバーヘッドにもかかわらず、コードのパフォーマンスはさらに 1.45 倍向上しました。2 インテル® AVX 2 で浮動小数点命令と同等の並列性を持つ整数ベースの命令が利用できるようになれば、パフォーマンスはさらに向上するでしょう。その場合、行 6、8、10、11、14、15、17、18 は削除することができます。行 9 と 16 は、浮動小数点ではなく、整数を使用して処理を行えます。行 19、20、21 は単一のパック命令 (整数からバイト) になります。もちろん、このほかにも将来のインテル® AVX 2 命令に追加される可能性のある命令はあるでしょう。パフォーマンス向上の可能性は、皆さんが考えてみてください。内側の [ix] ループで使用される組込み関数によって生成されるアセンブリー命令は、付録 B を参照してください。
3.3. 彩度補正 – パフォーマンスのテスト結果3
ここで説明したインテル® AVX により最適化された彩度補正アルゴリズムのパフォーマンスを測定したところ、シリアルコードと比べて 1.45 倍のスピードアップが得られました。パフォーマンス・データを収集するため、彩度補正アルゴリズムを 1440×1080 ピクセルのイメージに適用し、ループの反復を 100 回実行しました。イメージの彩度の補正にかかった経過時間 (ミリ秒) を測定したところ、一貫して以下の結果が得られました。
|
シリアルコード: |
1264 ミリ秒 |
|
インテル® AVX を使用したコード: |
873 ミリ秒 |
|
パフォーマンスのスケーリング: |
1.45 倍または 1264 ミリ秒/873 ミリ秒 |
アルゴリズムの実行には、小さなアプリケーション・プログラムを使用しました。これで 1.45 倍のスケーリングというのは、通常であれば、ワークロード・レベルでは 10% ~ 15% のパフォーマンス向上になります。ただし、ビデオ処理にこれを適用することはできません。彩度補正アルゴリズムを 1 分以上のビデオクリップに対して適用するケースについて考えてみましょう。その場合、処理するフレーム (イメージ) は 100 を超えます。理論的には、より多くのデータを処理しなければならないため、特に高画質 (つまり 1920×1080) のビデオでは 1.45 倍を超えるパフォーマンス向上の可能性があります。
4. パックド整数変換命令
最適化された彩度補正アルゴリズムでインテル® SSE4.1 命令の 1 つを使用しているため、ここではインテル® SSE4.1 の概要を説明します。ほかのビデオ処理アルゴリズムの最適化には、ほかのインテル® SSE4.1 命令を使用できる可能性があります。パックド整数変換命令セットには、パックド整数のビット幅を変換する 12 個の命令が含まれています。整数データのビット幅を拡張する場合に、これらの命令を利用してコードを最適化することができます。
図 5 の表は、インテル® SSE4.1 のパックド整数変換命令のリストです。これらの命令は、バイトからワード、バイトからダブルワード、バイトからクアッドワード、ワードからダブルワード、ワードからクアッドワード、ダブルワードからクアッドワードへの符号拡張およびゼロ拡張変換をサポートしています。さらに表では、インテル® SSE2 とインテル® SSE4.1 で、4 個の 1 バイト整数を 4 個の 32 ビット整数へ変換するのに必要な命令を比較しています。
彩度補正の最適化では、pmovzxbd (バイトからダブルワードに変換) 命令を合計 4 回使用しています。これらの命令で 256 ビット・レジスターが完全にサポートされれば、最適化されたアルゴリズムでこの命令は 2 回使用するだけで済みます。そして、ループのパフォーマンスをさらに向上することができます。
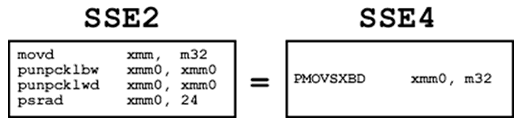
図 4. パックド整数のビット幅の変換命令
パックド整数変換命令のソースオペランドは、XMM レジスターまたはメモリーのいずれかです。デスティネーションは常に XMM レジスターです。メモリーにアクセスする場合は、アライメント・チェックが有効な場合を除き、アライメントを合わせる必要はありません。アライメント・チェックが有効な場合は、すべての変換のアライメントを参照するメモリーの幅に合わせる必要があります。変換可能な要素数とメモリー参照の幅は 図 5 に示します。アライメントのサイズは括弧で示します。
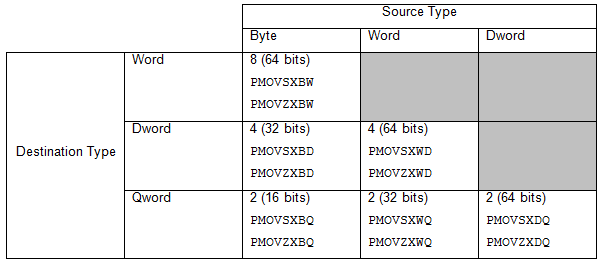
図 5. 処理可能な要素数。 P はパックド、MOV は移動 (レジスターのコピー)、ZX はゼロ拡張、SX は符号拡張、B はバイト、W はワード、D はダブルワード、Q はクアッドワードを表します。
5. まとめ
この記事では、第 2 世代インテル® Core™ プロセッサーでインテル® AVX 命令と 256 ビット・レジスターを利用して並列処理を向上する方法を説明しました。インテル® AVX 命令を使用して、彩度補正アルゴリズムの計算パフォーマンスを向上するケーススタディーを紹介し、将来のインテル® AVX 2 整数命令により、ビデオ処理アルゴリズムにおいて SIMD 最適化とパフォーマンスをさらに向上する可能性について触れました。また、サンプル・プロシージャーを使って、インテル® AVX 命令やその組込み関数により、どのようにビデオ処理アプリケーションのランタイムパフォーマンスが向上するのかを示しました。SIMD 処理のセットアップにオーバーヘッドがかかったものの、ビデオの彩度補正では素晴らしいパフォーマンスの向上を達成しています。
著者紹介
Eli Hernandez は、インテルのコンシューマー・クライアントおよびパワー・イネーブリング・グループのアプリケーション・エンジニアで、ソフトウェアの電力効率を向上させ、インテル製のハードウェアおよびソフトウェア向けに最適化できるように、ユーザーと協力して取り組んでいます。電気通信および化学の分野で 12 年間のソフトウェア開発経験があり、2007 年 8 月からインテルに在籍しています。シカゴのデポール大学から 1989 年に電気工学の学士号を、1992 年にコンピューター・サイエンスの修士号を取得しています。
Larry Moore は、2008 年にセントピーターズバーグ・カレッジを優秀な成績で卒業しました。Who’s Who Among Students Award を受賞し、Phi Theta Kappa Honor Society にも所属していました。2011 年にワシントン州デュポンのインテルで、アプリケーション・エンジニアとして 8 カ月間インターンシップを行いました。現在は、南フロリダ大学タンパ校でコンピューター工学の学士号と修士号の取得を目指しており、コンピューターを利用したリアルタイム・システムの確認とモデルチェックの研究に取り組んでいます。電気電子技術者協会 (IEEE) のメンバーでもあります。
付録 A: シリアルコードの内側のループのアセンブリー・コード
アルゴリズムの内側のループの反復では、約 45 命令を処理します。スループットは、反復ごとに 1 ピクセルです。
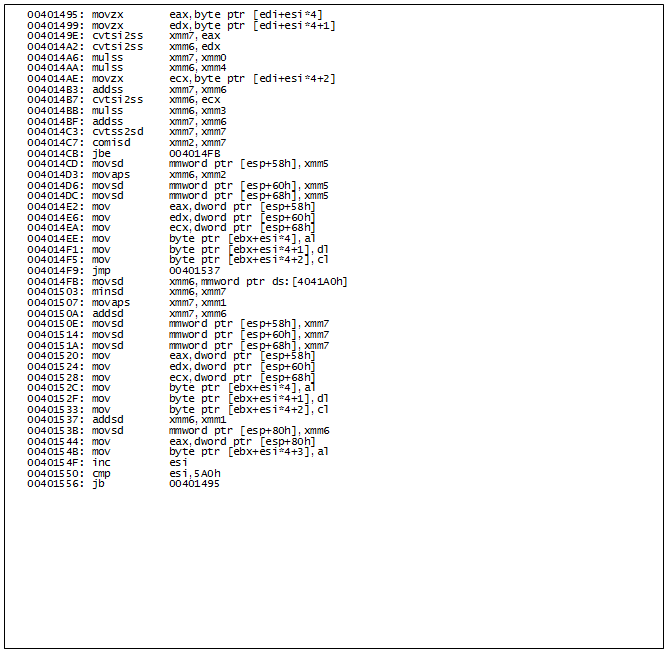
付録 B: インテル® AVX により最適化されたコードの内側のループのアセンブリー・コード
アルゴリズムの内側のループの反復では、約 30 命令を処理します。スループットは、反復ごとに 4 ピクセルです。

1 最適化されたコードのロードおよびストア操作では、データはアライメントされていると仮定します。
2 セクション 3.3 の脚注 3 を参照してください。
3 このセクションのパフォーマンス結果は、実際にテストを行って測定した値です。しかし、他の環境で同様の結果が得られるかどうかは保証できません。
✝開発コード名
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
