
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® VTune™ Profiler Performance Analysis Cookbook」の「Software Optimization for Intel® GPUs」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
バージョン: 2020 (最終更新日: 2021 年 6 月 30 日)
インテル® VTune™ プロファイラーを使用して、インテル® GPU へオフロードする場合のオーバーヘッドを予測します。GPU にオフロードされた計算タスクのパフォーマンスを解析します。
コンテンツ・エキスパート: Alexander Kurylev、Vladimir Tsymbal
ヘテロジニアス・コンピューティングの普及に伴い、パフォーマンスを追求する開発者は、優れたパフォーマンスを発揮するワークロードの種類がハードウェア・アーキテクチャーによって異なることに気付きました。インテルは、CPU、GPU、および FPGA を含む、多くのハイパフォーマンスなアーキテクチャーを提供しています。この記事では、インテル® VTune™ プロファイラーを使用して、インテル® GPU にオフロードされた計算集約型ワークロードをプロファイルおよび最適化する方法を説明します。
インテル® GPU を理解する
- 並列処理の採用: ワークロード集約型の GPU から優れたパフォーマンスを引き出すには、GPU のアーキテクチャーと機能を理解することから始めます。GPU は、連携して動作するいくつかの小さなプロセシング・コアを利用した高レベルの並列構造を採用しています。GPU は、同時に実行可能なタスクに分割できるワークロードに適しています。GPU のシングルコアのシリアル・パフォーマンスは、CPU よりもかなり低くなります。そのため、アプリケーションは、GPU で利用可能な大規模な並列処理を活用する必要があります。
- データの適切な移動: GPU を使用するには、GPU との間でデータを移動する必要があります。データを適切に移動しないと、大きなオーバーヘッドが発生し、パフォーマンスに影響を与えます。GPU の時間と空間的な局所性を活用するように、データを適切に処理します。最高のパフォーマンスを得るには、レジスターとキャッシュを利用してデータを隣接して格納することが重要です。
- オフロードモデルの使用: ワークロードの最も重要な部分は GPU を利用して処理されますが、ほかのワークロード・タスクを実行する CPU も重要であることに変わりはありません。オフロードモデルで GPU を使用して、ワークロードの一部を GPU (ターゲット) デバイスにオフロードします。GPU は、GPU で優れたパフォーマンスを発揮する部分のアクセラレーターとして機能します。残りのワークロードは CPU (ホスト) で実行します。ソフトウェア・パフォーマンスの最適化は、次の 2 つのタスクで行われます。
- GPU への最適なオフロード
- GPU 向けの最適化
注
この記事では、汎用 GPU (GPGPU) の計算での利用について取り上げ、計算モデルで GPU を利用する次のポイントを説明します。
- オフロードするコード領域
- オフロードの方法
- GPGPU アルゴリズムの記述方法
- インテル® VTune™ プロファイラーの GPU オフロード解析を使用して GPU オフロードのパフォーマンスを解析する方法
この記事では、インテル® GPU のグラフィックスでの利用方法については取り上げていません。グラフィカル・アプリケーションの解析には、インテル® VTune™ プロファイラーの GPU 計算/メディア・ホットスポット解析やインテル® グラフィックス・パフォーマンス・アナライザー (インテル® GPA) を使用してください。
インテル® GPU のアーキテクチャー
GPU オフロードモデルを説明する前に、まずインテル® GPU (Gen9 GT2 GPU など) のアーキテクチャーを確認しておきましょう。このデバイスはインテル® マイクロアーキテクチャー (開発コード名 Skylake) に統合されています。この GPU は、OpenCL* や SYCL*/DPC++ などの高水準言語を使用してプログラムできます。
Gen9 GT2 GPU には 24 の実行ユニット (EU) を備えた 1 つのスライスがあります。実行ユニットは、GPU アーキテクチャーの基本的な構成要素です。
Gen9 GT2 GPU の実行ユニット (EU)
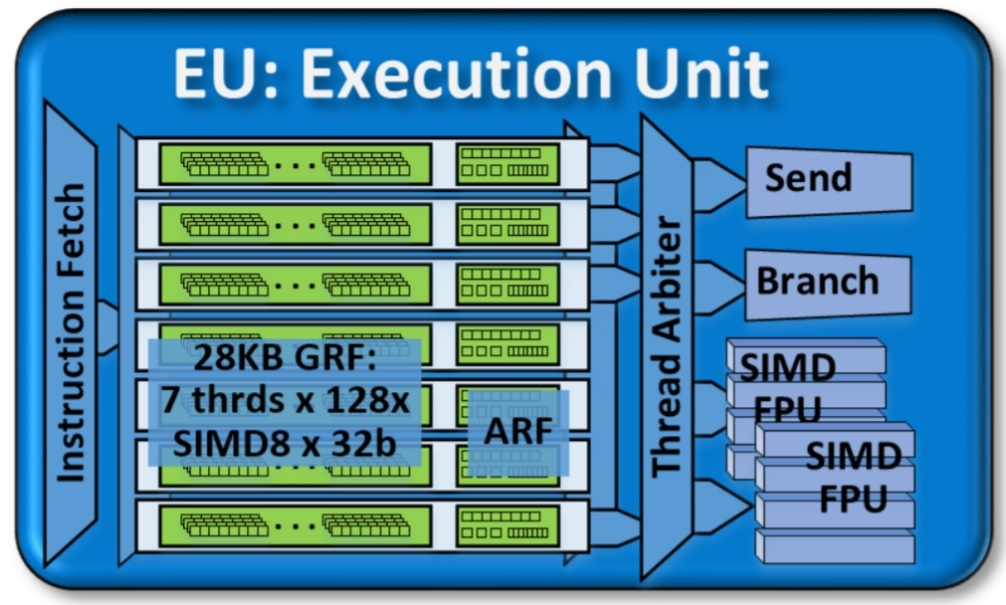
EU は、同時マルチスレッディング (SMT) と細粒度のインターリーブ・マルチスレッディング (IMT) を組み合わせたものです。EU は、複数の問題、SIMD ALU (Single Instruction Multiple Data 演算ユニット) を処理するコンピューティング・プロセッサーです。これらの SIMD ALU は、複数のスレッドでパイプライン化されます。SIMD ALU は、高スループットの浮動小数点演算と整数演算に役立ちます。EU の細粒度のスレッド化により、実行の準備ができた命令の継続的なストリームが保証されます。IMT は、メモリーのギャザー/スキャッター、サンプラー要求、その他のシステム通信などの、長い操作のレイテンシーも隠蔽します。
スレッドアービターは、操作の各サイクルでいくつかの命令をディスパッチします。これらの命令が機能ユニットに伝播しない場合、ストールが発生します。ストールの期間は、その状態で経過した実行サイクルの数で測定されます。この測定は、EU の効率を予測するのに役立ちます。EU Array Stalled (EU 配列ストール) メトリックは、EU がストールしたが少なくとも 1 つのスレッドがアクティブだった場合のサイクル数をカウントします。ストールは、EU がメモリー・サブシステムからのデータを待機する際に発生する可能性があります。関連する GPU メトリックの詳細は、『インテル® VTune™ プロファイラー・ユーザーガイド』の「GPU メトリック・リファレンス」を参照してください。
効率良いスケジューリングの重要性
超並列マシンの計算能力を最大限に使用するには、GPU のすべての EU に十分な計算を供給する必要があります。そのため、EU には機能処理ユニットよりも多くのハードウェア・スレッドがあります。多くのハードウェア・スレッドがあることで、実行する必要のある命令のオーバーサブスクリプションが発生する可能性がありますが、同時に待機中のデータによるストールを隠蔽するのにも役立ちます。
この方法によるスレッドのスケジューリングは、コストのかかる操作です。スケジューリングを効率良く費用効果の高いものにするには、すべての EU をできるだけビジーにすることが重要です。次のケースでは、スケジューリングの効果は低くなります。
- 計算量が少なすぎる。スケジューリングのオーバーヘッドが、有用な計算を完了するために費やされる時間に匹敵する可能性があります。
- 計算量が多すぎる。スレッド間のワークの分散が不均等になり、GPU のすべての EU の全体的な占有率が低くなる可能性があります。
これらの両方の状況を検出するには、EU Threads Occupancy (EU スレッドの占有期間) メトリックを使用します。スレッドの占有率が低いことは、スレッド間でワークロードが効率良く分散されていないことを示します。
それほど一般的ではない状況として、特定の期間 EU 向けのタスクがない場合にも発生することがあります。EU がアイドル状態になり、占有率に悪影響を与える可能性があります。この状況を検出するには、EU Array Idle (EU アレイアイドル) メトリックを使用します。
浮動小数点ユニットを使用した SIMD 実行
EU のプライマリー計算ユニットは SIMD 浮動小数点ユニット (FPU) のペアです。これらの FPU は、実際には浮動小数点と整数の両方の計算をサポートしています。次の表は、これらの FPU の SIMD 実行機能を説明したものです。
| データサイズ | データ型 | SIMD 操作の数 |
|---|---|---|
| 16 ビット | 整数 | 8 |
| 16 ビット | 浮動小数点 | 8 |
| 32 ビット | 整数 | 4 |
| 32 ビット | 浮動小数点 | 4 |
EU IPC Rate (EU IPC レート) メトリックは、FPU の飽和状態を示す指標です。たとえば、2 つの非ストールスレッドでマシンの浮動小数点計算スループットが飽和する場合、メトリックは 2 です。通常、このメトリックは理論上の最大値である 2 よりも低くなります。
FPU が飽和しておりデータ幅が狭い場合、命令レベルの並列処理は不適切であると言えます。この場合、SIMD Width (SIMD 幅) メトリックを確認します。
| SIMD 幅の値 | 意味 |
|---|---|
| 4 未満 | コンパイラーがループのベクトル化を妨げている原因を確認します。 |
| 4 以上 | コンパイラーによる命令のベクトル化は成功しています。データの依存関係を削除するか、コードにループアンロール手法を適用すると、この値をデータの局所性とキャッシュの再利用に適した 16 または 32 に増やすことができます。 |
メモリー・サブシステム
Gen9 GT2 GPU には、UMA (Unified Memory Architecture) を備えた独自のメモリー・サブシステムが用意されています。このメモリー・サブシステムは、物理メモリーを CPU と共有して、ゼロコピーバッファー転送を効率良く行います。この機能により、以下のように、CPU と GPU 間のデータ転送が高速化されます。
SOC レベルでのインテル® プロセッサー・グラフィックス Gen9 GT2 GPU のメモリー階層
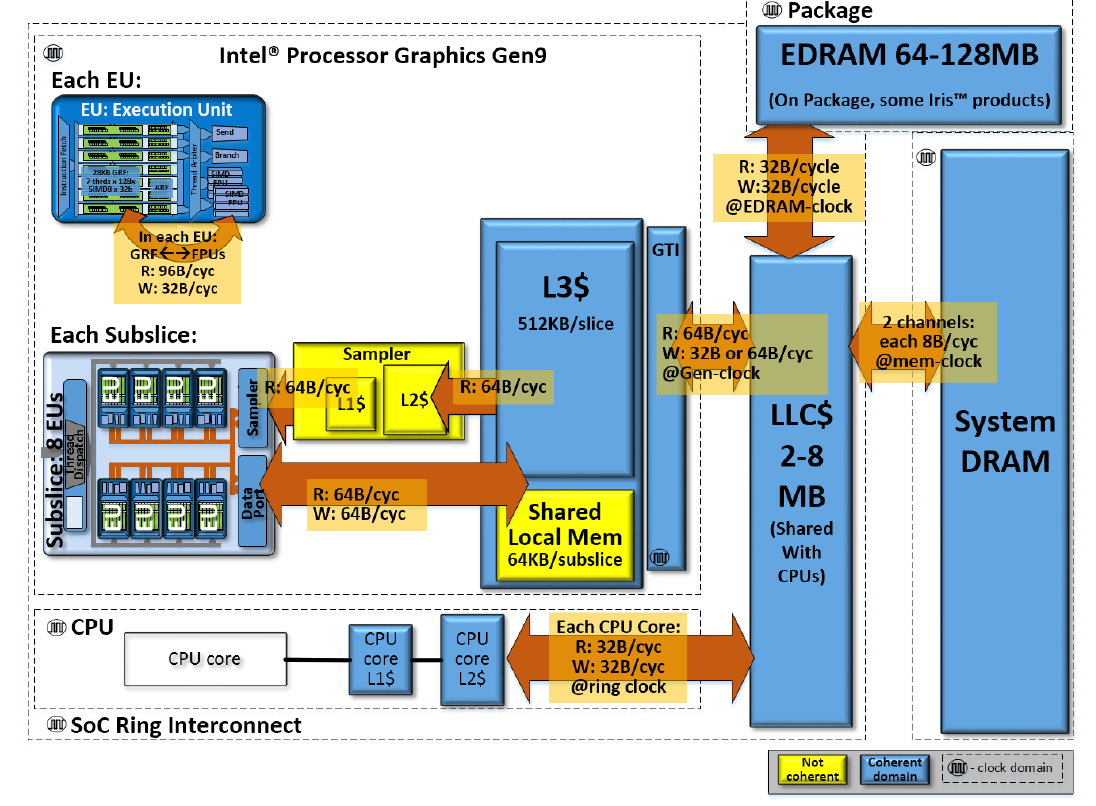
EU は DRAM/LLC メモリーからデータを受け取ります。GPU L3 または共有ローカルメモリー (SLM) にキャッシュされているデータブロックを再利用できます。大規模な並列処理により、すべての EU がメモリーからデータを要求すると、メモリー・サブブロックの帯域幅が飽和する可能性があります。
ローカル CPU キャッシュへのアクセスは、システムメモリーへのアクセスよりも高速です。理想的な状況では、データアクセスはローカル CPU キャッシュからも発生します。同様に、EU で読み取ったデータは、L3 GPU キャッシュに残しておくことができます。再利用する場合、キャッシュからのデータアクセスのほうが、メインメモリーからデータをフェッチするよりも高速になります。
Gen9 メモリー・アーキテクチャーでは、各スライスはそのスライスの L3 キャッシュにアクセスできます。各スライスには 2 つのサブスライスも含まれます。各サブスライスには、次のものが含まれます。
- ローカル・スレッド・ディスパッチャー
- 命令キャッシュ
- L3 へのデータポート
- 共有ローカルメモリー (SLM)
次のいずれかの方法で、データの局所性を制御できます。
- 特定のデータアクセス。L3 キャッシュにデータを格納するハードウェアを支援します。
- ワークグループでアクセス可能なローカルメモリーを割り当てる特別な API。ハードウェアにより SLM で提供されます。
L3 キャッシュのデータへのアクセスは非常に高速ですが、キャッシュ容量は大きくありません。大きな配列をトラバースすると、データが排出されてキャッシュを有効に利用できない可能性があります。L3 Cache Miss (L3 キャッシュミス) メトリックは、GTI の背後のメモリーからデータをフェッチするために必要なデータアクセスの量を示します。データ・ブロッキング手法は、キャッシュミスを減らすのにも役立ちます。例えば、SLM に収まるデータのブロックを保持する場合、サブスライスのローカル・スレッド・ディスパッチャーは最高レベルのデータの局所性を保持できます。インテル® VTune™ プロファイラーを使用して SLM トラフィックを追跡し、転送されたデータの量と転送速度に関する情報を確認できます。
インテル® VTune™ プロファイラーの GPU プロファイル機能
この記事では、GPU 解析をサポートするように調整されたインテル® VTune™ プロファイラーの主要な機能を取り上げています。次のワークフローは、これらの機能の説明です。
- アプリケーションの GPU オフロード解析を実行します。
- アプリケーションが CPU 依存か GPU 依存かを確認します。
- GPU 利用率を定義します。
- GPU EU が実行中にストールしていないか確認します。
- GPU をビジー状態に保つのに最も適した計算タスクを特定します。これらのタスクは、GPU の効率をさらに解析する際の候補と見なすことができます。
- GPU 計算/メディア・ホットスポットのプロファイルを収集します。次のメトリックを使用して、上位の計算タスクのリストを取得します。
- 実行時間
- EU 効率
- メモリーストール
- メモリー階層ダイアグラムを使用して、最も効率の悪い計算タスクに取り組みます。
- データ転送/帯域幅メトリックを解析します。
- 実行のボトルネックの原因となるメモリー/キャッシュユニットを特定します。
- GPU のマイクロアーキテクチャーの制約に基づいて、アルゴリズムのデータ・アクセス・パターンを決定します。
- カーネルで [Instructions Count (命令カウント)] プリセット解析を実行します。
- 命令セットと、コンパイラーにより生成された SIMD 命令の選択を確認します。
- コンパイラーが効率の良い命令を生成するように、特別なコンパイルオプションとプラグマを活用します。
- 大規模な計算カーネルには、GPU 計算/メディア・ホットスポット解析の [Basic Block Latency (基本ブロック・レイテンシー)] プリセットを使用します。
- 最大の実行レイテンシーの原因であるコード領域を特定します。
- [Source (ソース)] ビューで、ソースコード行に対するレイテンシー・メトリックを調べます。
- [Memory Latency (メモリー・レイテンシー)] プリセットを使用して、重大な実行ストールを示したメモリー・アクセス・コードを調べます。
- 個々の命令に対するレイテンシーを表示する [Assembly (アセンブリー)] ビューのアセンブリー命令から、メモリーアクセスの詳細を調べます。
- GPU 向けの既知の最適化手法を使用して、メモリーに適したパターンになるようにデータアクセスを再配置します。
- 目標のパフォーマンス・メトリックになるまで、改善したアルゴリズムで GPU 計算/メディア・ホットスポット解析を繰り返します。
インテル® GPU にオフロードする場合の最適化手法
ヘテロジニアス・アプリケーションは通常、アクセラレーターにオフロードするコード領域を特定して設計されます。オフロードするコード領域を特定できない場合は、インテル® Advisor のオフロードのモデル化 (英語) を使用して特定します。
この記事では、GPU にオフロードするコードをすでに特定していると仮定しています。次に、ホスト側でオフロードを実装する最適な方法を紹介します。
ステップ 1: デバイスの使用率を調べる
最適化手法は、CPU コアとアクセラレーター EU でアルゴリズムの実行に費やされる時間を効率良く分散する必要があります。デバイスの使用率を示す ([CPU Usage (CPU 利用率)] メトリックおよび [GPU Usage (GPU 利用率)] メトリック) は、この効率を早い段階で判断するのに役立ちます。これらの理想値は 100% ですが、実行にギャップや遅延がある場合、インテル® VTune™ プロファイラーを使用して、ギャップや遅延が発生したアプリケーション・コードの場所を特定します。
ステップ 2: GPU でのコード実行の効率を定義する
行列サンプル・アプリケーション (英語) を見てみましょう。このアプリケーションには、密行列 C = A B を使用した FP データに対する行列-行列乗算操作が含まれます。
コーディングを簡単にするため、A、B、C は n × n の正方行列とします。
注
可読性を高め、コンパクトに表現するため、簡素化されています。ベンチマークの行列乗算タイプはよく知られていて、アクセラレーター向けにも多くの計算最適化手法が開発されています。アルゴリズムの合成ではなく、アルゴリズムの解析を検討します。
for (size_t i = 0; i < w; i++)
for (size_t j = 0; j < w; j++) {
c[i][j] = T{};
for (size_t k = 0; k < w; k++)
c[i][j] += a[i][k] * b[k][j];
}
この例では、行列サンプルの簡素化された C++ バージョンを見ていきます。このバージョンでは、キューへのカーネル送信の詳細が省略されています。実際の行列サンプルは、データ並列 C++ (DPC++) で記述され、インテル® oneAPI DPC++/C++ コンパイラーでコンパイルされます。
アクセラレーターにオフロードするコード領域を特定します。通常は、最も外側のループが適切な候補です。しかし、この例では、最も内側のループが計算カーネルである可能性があります。また、このコードの最も内側のループは、必ずしもサンプルの最も内側のループであるとは限りません。高いレベルのライブラリー呼び出しやサードパーティーの機能は、コンピューターの反復構造全体をマスクする可能性があります。そのため、この手法の説明では、最も内側のループをオフロードすることを選択します。
for (size_t k = 0; k < w; k++)
c[i][j] += a[i][k] * b[k][j];
ステップ 3: GPU オフロード解析を実行する
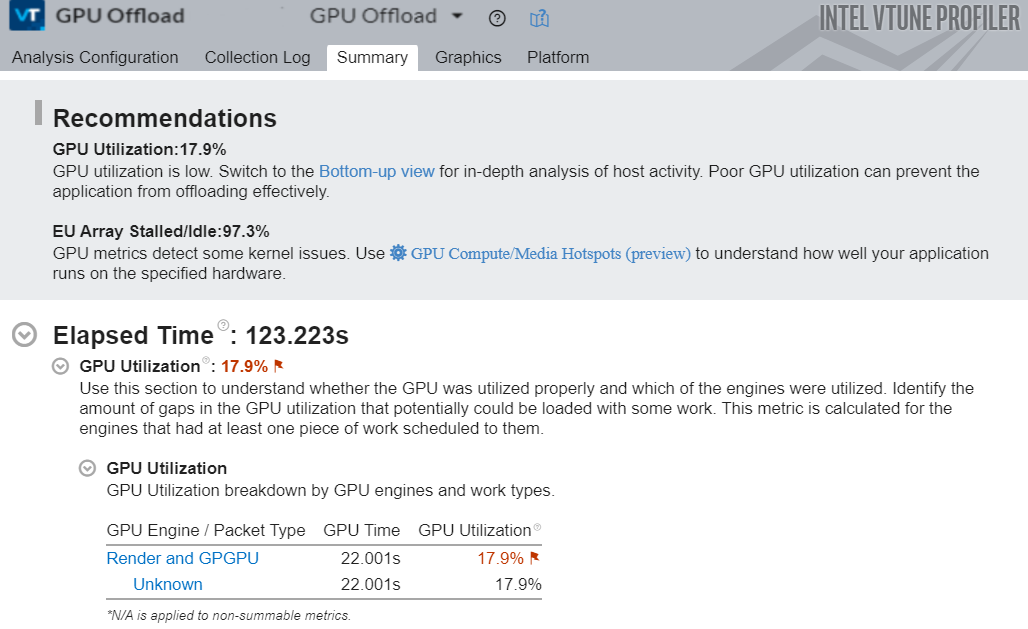
インテル® VTune™ プロファイラーの GPU オフロード解析を使用して、GPU にオフロードするホットな計算タスクを素早く特定します。これらのタスクを送信する際に、CPU アクティビティーを明確にすることもできます。以下の例では、1 つのアクティブな計算タスクに注目しています。そのため、ここでは CPU を無視できます。GPU オフロード解析を使用して、GPU での計算タスクの実行に関する情報を収集します。
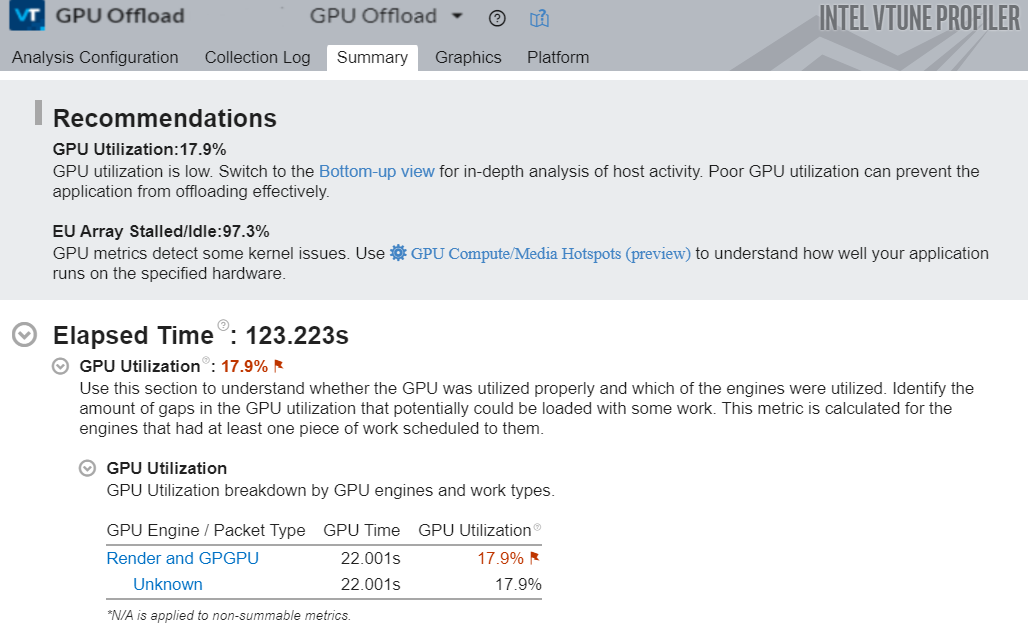
解析が完了すると、[Summary (サマリー)] ウィンドウに GPU 利用率と EU ストールの測定値に関する情報が表示されます。推奨事項に従って、まず低い GPU 利用率の原因となる可能性のあるホスト・アクティビティーを調べます。[Graphics (グラフィックス)] タブに切り替えて、[Bottom-Up (ボトムアップ)] ビューを開きます。

上の図の matrixMultiply1 カーネルの結果を見ます。
すばやくワークを解析するため、このバージョンのカーネルは 256X256 次元の行列を使用しています。[Instance Count (インスタンス・カウント) カラムは、カーネルが 65,536 回呼び出されたことを示しています。各インスタンスは非常に小さいため、カーネルの平均時間はゼロ秒に四捨五入されています。タイムラインのパターンは、カーネルの呼び出し速度が速いことも示しています。この場合、ほとんどの時間は小さなカーネルの作成に費やされます。[EU Array (EU アレイ)] セクションの [Idle (アイドル)] カラムは、EU が 92.6% の時間でアイドル状態だったことを示しています。非常に多くの短いカーネルを呼び出していることは、ワークの非効率性を示す重要な指標です。
[Work Size (ワークサイズ)] セクションから、ワークの分散が非効率だったことが分かります。外側のループをオフロードしてみましょう。
この処理により、計算カーネルのインスタンス数が 1 つ (matrixMultiply2) に減り、パフォーマンスが向上するはずです。次の図は、この改良バージョンのカーネルの GPU ホットスポット解析を示しています。このバージョンは、ナイーブ実装とも呼ばれます。
行列乗算サンプルのナイーブ実装のための GPU ホットスポット解析

このケースでは、行列のサイズは 2048 X 2048 に増加し、ウォールクロック・パフォーマンスは 10 倍以上高速でした。[EU Threads Occupancy (EU スレッドの占有期間)] メトリックは 95.7% と高い値です。これは、実行ユニットで利用できる十分なワークがあることを示しています。
デバイスの操作によるタスク時間の特徴付け

上の図のタイムラインを見ると、データ転送が 100 ミリ秒しかかかっていないのに対して、実行に 800 ミリ秒近くかかっている計算タスクが分かります。このデータ実行とデータ転送の比率は、アルゴリズムを改良することで改善できます。
コンパイラーが SIMD 幅 32 の SIMD 命令を生成していることに注意してください。データアクセスが変更された結果、前回の実行ではほぼゼロであった EU のアクティブな時間が、86.8% になりました。この例は、カーネルの各呼び出し内で十分なワークを提供することの重要性を示しています。
ステップ 4: GPU 計算/メディア・ホットスポット解析を実行する
行列乗算サンプルのナイーブ実装は初期バージョンよりも高速ですが、さらにパフォーマンスを向上できる可能性があります。
インテル® VTune™ プロファイラーは、高い [EU Threads Occupancy (EU スレッドの占有期間)] メトリック (95.7%) を示しています。この値から、EU 間でワークが適切に分散されていることが分かります。しかし、[EU Array Stalled (EU 配列ストール)] メトリックはわずか 9.2% であり、matrixMultiply2 カーネルで実行エンジンが十分に活用されていないことが推測できます。

カーネルを制限している要因を調査するため、GPU 計算/メディア・ホットスポット解析を実行します。この解析では、GPU でのカーネル実行に関する詳細な情報を確認できます。
最初に、カーネルが計算依存なのかメモリー依存なのかを特定します。
GPU ホットスポット解析には、いくつかの事前定義済みプロファイルやプリセットが用意されています。これらのプリセットを使用して、メモリーアクセスや計算効率に関連する異なるメトリックを収集できます。カーネル実行を適切に理解できるように、[Full Compute (完全な計算)] プリセットを使用しました。このプリセットの情報から、カーネル matrixMultiply2 の実行で、EU FPU が 63.5% の時間しかアクティブでなかったことが分かります。
計算カーネルの FPU アクティビティー

つまり、このカーネルは計算依存ではなくメモリー依存です。
次に、メモリー階層ダイアグラムを確認します。このダイアグラムは、EU とメモリーユニット間のデータ転送情報を提供します。この情報は、カーネルのコードの最適化ステップを定義するのに役立ちます。
[Overview (概要)] プリセットを選択すると、メモリー階層ダイアグラムに、メモリーユニット (GPU L3 キャッシュ、GTI インターフェイス、LLC および DRAM など) と EU 間のリンクの帯域幅の値と、転送された合計データが表示されます。
GPU メモリー・サブシステムのカーネルデータ転送
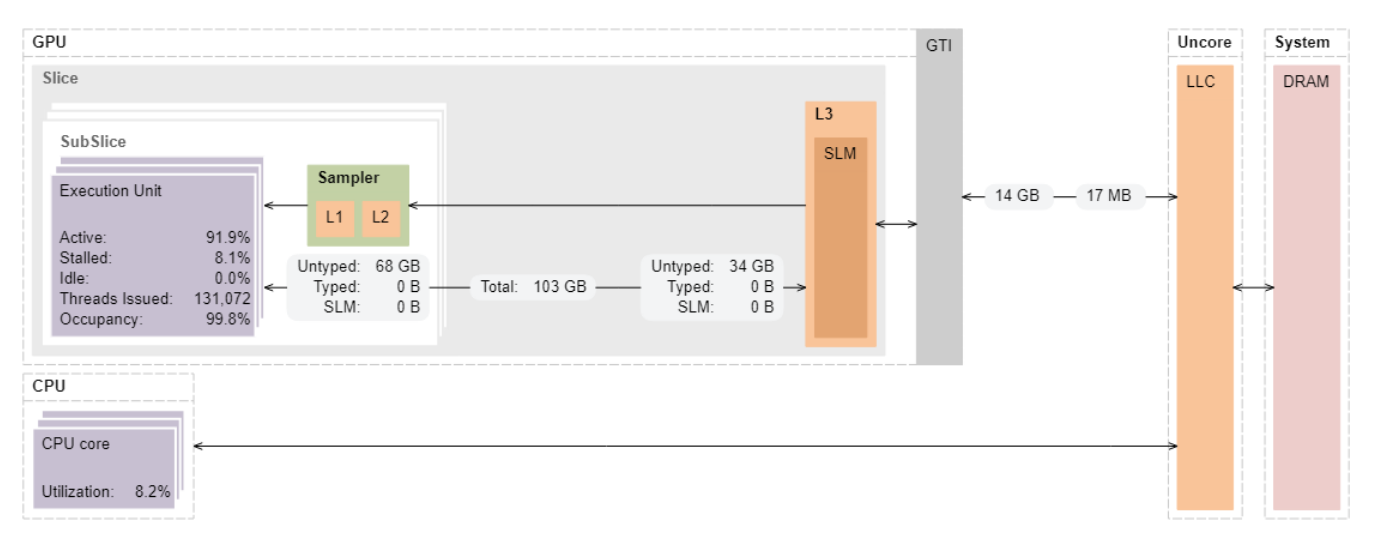
EU に転送されたデータの総量 (~68GB) と GTI インターフェイスを経由して LLC/DRAM から取得されたデータ (14GB) に注目します。
これらのデータサイズを各行列データ配列のサイズ (2048x2048x4=16MB) と比較すると、転送された量は非常に多くなっています。この状態では、グローバルメモリーにアクセスするため、実行は非効率になります。効率の良いデータアクセス (配列のユニット・ストライド・アクセスなど) やグローバルメモリーへの最小限のアクセスで、この問題に対処します。
ステップ 5: 追加のカーネルコードの最適化
グローバルメモリーからのデータのフェッチは、GPU の一般的な性能制限要因です。ディスクリート GPU では、この問題は悪化します。PCIe* バスで、帯域幅やレイテンシーがさらに制限されます。一般的ですが次善の最適化アプローチは、データの局所性と再利用を増やすことです。この最適化は、行列領域をブロックして、実行ユニットに近いキャッシュメモリーに収まる小さなブロック内で積算演算を完了します。次のいずれかの方法で、この最適化を実装できます。
- ハードウェアが頻繁にアクセスされるデータを認識し、そのデータを自動的にキャッシュ内で保持することを許可します。
- 共有ローカルメモリーに最も使用されるデータを配置して、データブロックへのアクセスを手動で制御します。
2 つ目の方法を次の条件で実装するときは注意してください。
- スレッドの管理が最適でない (SLM アクセスがスライスからスレッドに制限される) 場合。
- データアクセスが遅い (データの読み取り/書き込みの比率がしきい値未満の) 場合。
注
読み取り/書き込み比率の GPU パフォーマンスへの影響は GPU ハードウェアによって異なります。読み取り/書き込みの比率のしきい値は微妙で、GPU ハードウェアに依存します。しかし、書き込み操作の数が増えると、パフォーマンスが低下する可能性も高くなります。
行列乗算アルゴリズムで SLM を使用する 1 つのアプローチは、行列のグローバル・ワークセットをブロックまたはタイルに分割し、タイルでドット積演算を別々に実行することです。このアプローチでは、タイル全体が SLM 領域に収まるように、グローバル・メモリー・アクセスの数を減らす必要があります。データ配列への最適なアクセスは有効になりませんが、データの局所性が得られるため、アクセスは高速になります。
以下のコードで、擬似コードはローカル・インデックス空間のタイルへのデータアクセスのアイデアを示しています。
i, j // global idx
for (size_t tidx = 0; tidx < TILE_COUNT; tidx++)
ti, tj // local idx
ai, aj, bi, bj // global to local idx
ta[ti, tj] = a[ai, aj]
tb[ti, tj] = b[ai, aj]
for (size_t tk = 0; tk < TILE_SIZE; tk++)
c[i][j] += ta[ti][tk] * tb[tk][tj];
}
タイル化された乗算の実装により、データフローは再配布されます。matrixMultiply4 カーネルの解析 (次のメモリー階層ダイアグラムを参照) から、次のことが分かります。
共有ローカルメモリー (SLM) のタイル化されたカーネルデータ転送
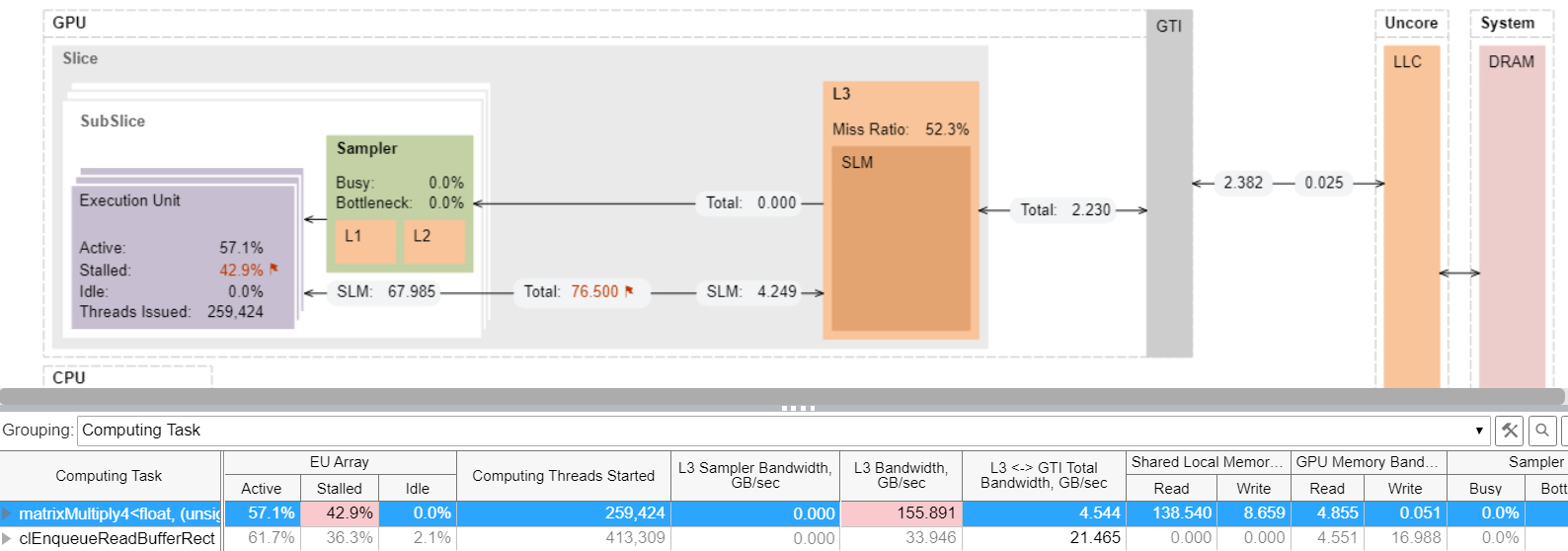
- GTI インターフェイスで LLCから得られたデータは ~2GB で、その多くは L3/SLM から得られています。
- L3 Bandwidth (L3 帯域幅) メトリック (上の表で強調) は、 155GB/秒に達しています。これは最大 L3 帯域幅の 70% 以上です。
- EU の約 43% はまだストールしています。
これらの結果から、高速なキャッシュメモリーを使用しているにもかかわらず、アルゴリズム実行はまだメモリー依存であることが分かります。この実装により、カーネルの実行速度はナイーブ実装の約 5 倍になりました。
次に、計算タスクの合計時間を調べます。
タイル化されたカーネルのタイミング

高速な実装のための方法はいくつかあります。
- 最適な方法で高レベルのデータアクセスを整理します。
データ分布にサブグループを使用すると、独自のローカルメモリーにアクセスする GPU のサブスライスを活用できます。
- 特定の GPU アーキテクチャー向けの低レベルの最適化を使用し、インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) などの最適化ライブラリーを使用します。
これらのステップは、GPU で最大のパフォーマンスを達成するのに役立ちます。しかし、GPU には、いくつかの既知の特性を使用して計算できる、パフォーマンスの理論上の制限があります。
例えば、Gen9 GPU でのアルゴリズム実行の理論上の最小時間を計算してみましょう。Gen9 GT2 GPU アーキテクチャーのパラメーターから、この GPU には 24 の EU が含まれていることが分かります。各 EU には 2 つの FPU (SIMD-4) があります。各 FPU は 2 つの演算 (乗算+加算) を実行できます。最大コア周波数は 1.20GHz で、最大 FP パフォーマンスは次のとおりです。
24 * 2 * 4 * 2 = 384 FLOP/サイクル (32 ビット浮動小数点)
384 * 1.2 = 460.8 GFLOPS
ナイーブ行列乗算実装の FP 演算の数は 2*N3 (N=2048 の場合、約 17.2 GOPS) です。
理論的には、データアクセスの非効率性および帯域幅の制約による制限がなかった場合、アルゴリズムは 17.2 / 460.8 = 0.037 秒 (37 ミリ秒) で計算できます。インテル® VTune™ プロファイラーの結果では、カーネルで実行された最良の時間は 490 ミリ秒であり、理論上の計算時間よりも 10 倍以上遅くなっています。つまり、パフォーマンスを向上する余地はまだあります。
スケーリング・パフォーマンス
行列乗算サンプルのような高度に並列化されたアプリケーションは、GPU リソースを使用することにより効率が向上します。スケーリングがメモリーのボトルネックによって制限されない限り、追加の計算リソースを使用するとパフォーマンスも向上するはずです。
Gen9 シリーズの GPU には、48 の EU を含む GT3 と 72 の EU を含む GT4 があります。しかし、組込み型の GPU には基本的な領域の制限があり、スケーリングを高めるために EU を追加したり、データアクセスを高速化するためにキャッシュブロックを大きくしたりすることはできません。ディスクリート GPU では、領域や電力の制約による制限は少なくなります。システムで 1 つまたは複数の GPU との統合が許可されている場合、アクセラレーターのパフォーマンスをスケールアップできます。
しかし、メイン CPU、メモリー、および GPU の間には、通信インターフェイス (PCIe* バスなど) が存在することに注意してください。通信インターフェイスには、帯域幅、レイテンシー、およびデータの一貫性に独自の制約がある場合があります。
PCIe* ディスクリート・グラフィックス・カード (開発コード名 DG1) と呼ばれていた、インテル® Iris® Xe MAX GPU を見てみましょう。
インテル® Iris® Xe MAX マイクロアーキテクチャーの高レベルのビュー

同じタイル化されたカーネル実装の解析結果は次のとおりです。
タイル化された matrixMultiply カーネルの GPU ホットスポット解析の結果

カーネル実行は約 4 倍高速化されました。
Gen9 GPU の 24 の EU に対してインテル® Iris® Xe MAX GPU には 96 の EU が含まれていることから、これは予想どおりの結果と言えます。しかし、次の表を見ると、EU が実行中に 51% の時間でまだストールしていることが分かります。これは、(一般的な行列アルゴリズムでよく知られている) メモリーからのデータの待機が原因であると考えられます。具体的な原因を調べてみましょう。
タイル化された matrixMultiply4 カーネルの EU Array (EU アレイ) メトリック

結果グリッドでモードを切り替えて最大帯域幅の割合を表示すると、L3 と GPU メモリーの帯域幅は最大値からかなり離れているため、ボトルネックではないことが分かります。データ転送の全体像を把握するため、メモリー階層ダイアグラムを見てみましょう。
データ転送メトリックを含むメモリー階層ダイアグラム
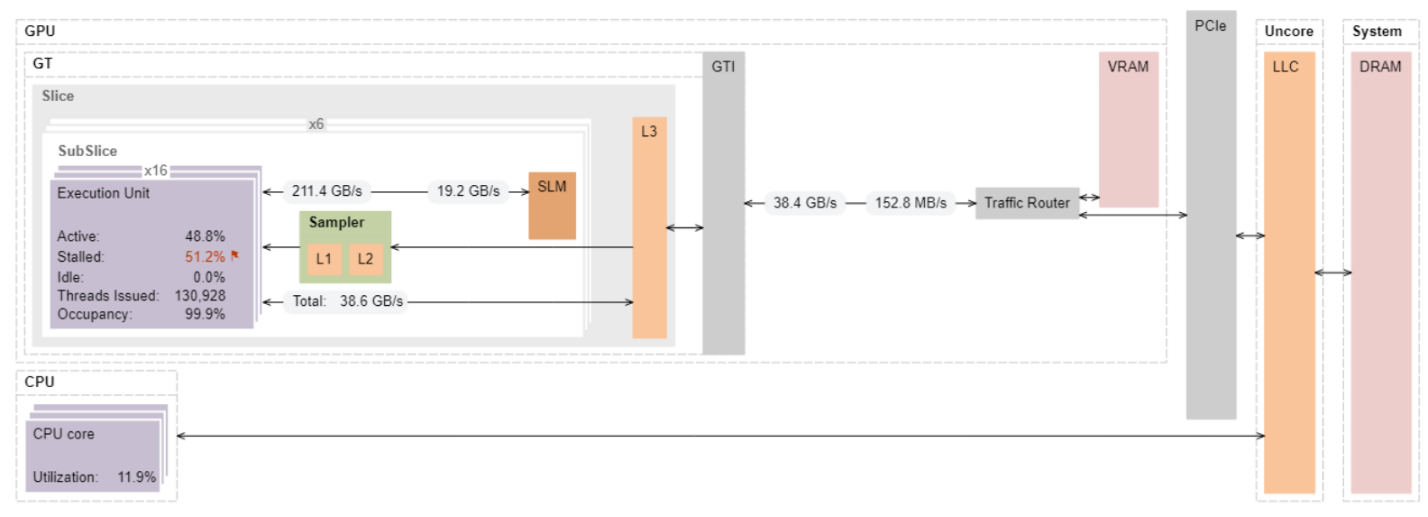
データは、GTI インターフェイスを経由して VRAM やメイン DRAM から取得されます。CPU 側で行列データを準備すると、行列 a と行列 b のデータが PCIe* 経由で GTI に転送されます。測定された GTI の帯域幅は、PCIe* インターフェイスに必要なデータ転送速度のおおよその指標です。測定されたデータ読み取り速度は GTI インターフェイスで 38GB/秒ですが、PCIe* 3.0×16 の理論上の最大値は片方向で 16GB/秒です。つまり、PCIe* の帯域幅に制限されていることが分かります。インテル® VTune™ プロファイラーを使用して PCIe* のデータ・トラフィックを測定するには、PCIe* パフォーマンス・カウンターを備えたサーバー・プラットフォームが必要です。
サーバーベースのセットアップでは、PCIe* の帯域幅はバスの制限よりもはるかに低くなります。次のように結論付けることができます。
- すべてのデータは VRAM と EU ストールからフェッチされています。これは、ビデオメモリーから EU へのデータ移動のレイテンシーで定義されます。
- EU と L3 間のデータ・トラフィックは GTI と外部トラフィック・ルーター間のデータ・トラフィックと同じであるため、L3 キャッシュを適切に再利用することにより、パフォーマンスをさらに最適化できます。例えば、各 GPU スライスの L3 キャッシュに収まるブロックサイズで、セカンドレベルの行列タイリングを行います。
まとめ
一般に、ヘテロジニアス・アプリケーションでは、特定のワークロードをアクセラレーターにオフロードする場合、GPU などの超並列アクセラレーター・マシンに十分な計算タスクを提供することが不可欠です。
- オフロードしたタスクのデータ転送とタスク・スケジューリングのオーバーヘッドを予測することにより、GPU の効率を向上します。
- インテル® VTune™ プロファイラーの GPU オフロード解析の [GPU Utilization (GPU 利用率)] メトリックおよび [GPU Occupancy (GPU 占有率)] メトリックを使用して、GPU 使用の非効率性を予測します。
- 計算タスク実行のパフォーマンスは、実行ユニットの不足、メモリー・サブシステムまたはインターフェイスのボトルネックの存在など、いくつかのマイクロアーキテクチャーの要因によって制限される場合があります。GPU 計算/メディア・ホットスポット解析を実行して、これらの制限を特定します。GPU メモリー階層ダイアグラムのボトルネックと、すべての計算タスクの詳細なマイクロアーキテクチャーのメトリックをハイライトします。複雑なカーネルの場合、レイテンシー解析を使用して、カーネル内の最も重要なコードを特定します。
関連情報
- DPDK アプリケーションのコア使用率
- インテル® Advisor ユーザー向けオフロードのモデル化のリソース (英語)
- インテル® VTune™ プロファイラー・ユーザーガイド日本語版
- DPC++ アプリケーションのプロファイル
- インテル® VTune™ プロファイラーを使用してインテル® GPU 向けにアプリケーションを最適化
- コマンドライン・インターフェイスを使用して GPU 上で実行する DPC++ アプリケーションのパフォーマンスを解析
- インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL)
インテル® VTune™ プロファイラー・パフォーマンス解析クックブックのトップに戻る
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex/ (英語) を参照してください。
