
この記事は、インテル® デベロッパー・ゾーンに公開されている『Intel® VTune™ Profiler Performance Analysis Cookbook』の「PCIe Traffic in DPDK Apps」日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
インテル® VTune™ Amplifier の PCIe* 帯域幅メトリックを使用して、パケット・フォワーディングを行う DPDK ベースのアプリケーションの PCIe* トラフィックを調査します。
コンテンツ・エキスパート: Ilia Kurakin (英語)、Roman Khatko (英語)
10/40 GbE NIC を搭載したシステムで実行するデータ・プレーン・アプリケーションは通常、プラットフォーム I/O 機能を多く利用します。特に、CPU とネットワーク・インターフェイス・カード (NIC) 間のインターフェイスである PCIe* リンクの帯域幅を集中的に消費します。このようなワークロードでは、パケット転送と通信制御のバランスを保つことにより、PCIe* リンクを効率的に利用することが重要です。PCIe* 転送を理解することは、パフォーマンス問題の特定と解決に役立ちます。
DPDK ベースのワークロードにおける PCIe* パフォーマンス解析の方法論の詳細は、https://fd.io/wp-content/uploads/sites/34/2018/01/performance_analysis_sw_data_planes_dec21_2017.pdf (英語) を参照してください。
このレシピでは、DPDK によるパケット・フォワーディングの段階と PCIe* 帯域幅消費の理論的な推定値を調べた後、理論的な推定値とインテル® VTune™ Amplifier で収集したデータを比較します。
- 使用するもの
- 手順:
使用するもの
以下は、このレシピで使用するハードウェアとソフトウェアのリストです。
- アプリケーション: シングルコアで L2 フォワーディングを実行する DPDK testpmd アプリケーション。インテル® VTune™ Amplifier のプロファイル・サポートが有効な DPDK でコンパイルされています。
- パフォーマンス解析ツール:
- インテル® VTune™ Amplifier 2019 Update 3: 入力と出力解析
注
- インテル® VTune™ プロファイラー評価版のダウンロードと製品サポートについては、https://www.isus.jp/intel-vtune-amplifier-xe/ を参照してください。
- このクックブックのレシピはすべてスケーラブルであり、インテル® VTune™ Amplifier 2018 以降に適用できます。バージョンにより設定がわずかに異なることがあります。
- ベータ版インテル® oneAPI ベース・ツールキット向けのバージョンから、インテル® VTune™ Amplifier の名称がインテル® VTune™ プロファイラーに変わりました。引き続き、インテル® Parallel Studio XE またはインテル® System Studio のコンポーネントとして、あるいはスタンドアロン版のインテル® VTune™ プロファイラーをご利用いただけます。
- インテル® VTune™ Amplifier 2019 Update 3: 入力と出力解析
- システムの設定: トラフィック・ジェネレーターおよび testpmd アプリケーションがパケット・フォワーディングを実行し、インテル® VTune™ Amplifier がパフォーマンス・データを収集する被試験システム (SUT)。
- CPU: インテル® Xeon® Platinum 8180 プロセッサー (38.5MB キャッシュ、2.50GHz、28 コア)
インバウンド/アウトバウンド PCIe* 帯域幅メトリックを理解する
PCIe* 転送は PCIe* デバイス (NIC など) と CPU の両方により開始されます。そのため、インテル® VTune™ Amplifier は、次の帯域幅タイプで、PCIe* 帯域幅メトリックを識別します。
- [Inbound PCIe Bandwidth (インバウンド PCIe* 帯域幅)]: システムメモリーをターゲットとするデバイスのトランザクションが消費する帯域幅を示します。
- [Read (リード)]: メモリーからデバイスへの読み取りを示します。
- [Write (ライト)]: デバイスからメモリーへの書き込みを示します。
- [Outbound PCIe Bandwidth (アウトバウンド PCIe* 帯域幅)]: デバイスの MMIO 空間をターゲットとする CPU のトランザクションが消費する帯域幅を示します。
- [Read (リード)]: デバイスの MMIO 空間から CPU への読み取りを示します。
- [Write (ライト)]: CPU からデバイスの MMIO 空間への書き込みを示します。
入力と出力解析を設定して実行する
[Inbound PCIe Bandwidth (インバウンド PCIe* 帯域幅)] および [Outbound PCIe Bandwidth (アウトバウンド PCIe* 帯域幅)] データを収集するには、入力と出力解析を使用します。
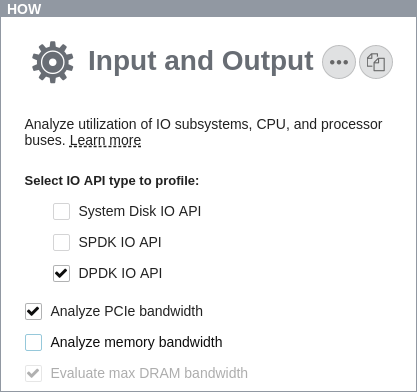
GUI で、プロジェクトを作成し、[HOW (どのように)] ペインで [Input and Output (入力と出力)] 解析を選択して、[Analyze PCIe bandwidth (PCIe* 帯域幅を解析)] オプションを有効にします。
コマンドラインで、collect-pcie-bandwidth knob (デフォルトで true に設定) を使用します。例えば、次のコマンドは DPDK メトリックを使用して PCIe* 帯域幅データの収集を開始します。
amplxe-cl -collect io -knob kernel-stack=false -knob dpdk=true -knob collect-memory-bandwidth=false --target-process my_process
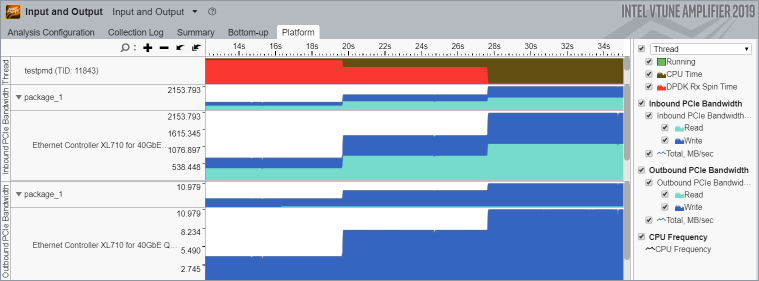
結果が収集されたら、GUI で [Platform (プラットフォーム)] タブに移動し、[Inbound PCIe Bandwidth (インバウンド PCIe* 帯域幅)] および [Outbound PCIe Bandwidth (アウトバウンド PCIe* 帯域幅)] セクションに注目します。
注
インテル® マイクロアーキテクチャー開発コード名 Skylake 以降のサーバー・プラットフォームでは、デバイスごとに PCIe* 帯域幅メトリックを収集できます。root 権限が必要です。
パケット・フォワーディングに必要な PCIe* 転送を理解する
DPDK によるパケット・フォワーディングは、パケットを受信 (rx_burst DPDK ルーチン) した後に、パケットを送信 (tx_burst) します。「DPDK アプリケーションのコア使用率」レシピの、Rx 記述子を含む Rx キューを利用したパケット受信の詳細が参考になります。DPDK によるパケット送信はパケット受信と同じように動作します。パケットを受信するため、実行コアは Tx 記述子 (パケットアドレス、サイズ、その他の制御情報を格納する 16 バイトのデータ構造) を使用します。Tx 記述子のバッファーは連続するメモリーのコアにより割り当てられ、Tx キューと呼ばれます。Tx キューはリングバッファーとして処理され、長さ、Head、Tail で定義されます。Tx キューからのパケット送信はパケット受信に非常に似ています。コアは Tx キューの Tail で新しい Tx 記述子を準備し、NIC は Head から処理します。
Rx キューと Tx キューの Tail ポインターは、新しい記述子が利用可能であることを通知するため、ソフトウェアにより更新されます。Tail ポインターは MMIO 空間にマップされる NIC レジスターに格納されます。つまり、Tail ポインターはアウトバウンド書き込み (MMIO 書き込み) で更新されます。MMIO アドレス空間はキャッシュできないため、アウトバウンド書き込みとアウトバウンド読み取りには非常にコストがかかります。そのため、これらのトランザクションは最小限にするべきです。
パケット・フォワーディングを行う場合、PCIe* トランザクションのワークフローは次のようになります。
- コアが Rx キューを準備して、Rx キューの Tail のポーリングを開始します。
- NIC が Rx キューの Head の Rx 記述子を読み取ります (インバウンド・リード)。
- NIC が Rx 記述子で指定されたアドレスにパケットを送ります (インバウンド・ライト)。
- NIC が Rx 記述子を書き戻して、コアに新しいパケットが到着したことを通知します (インバウンド・ライト)。
- コアがパケットを処理します。
- コアが Rx 記述子を解放して、Rx キューの Tail ポインターを移動します (アウトバウンド・ライト)。
- コアが Tx キューの Tail の Tx 記述子を更新します。
- コアが Tx キューの Tail ポインターを移動します (アウトバウンド・ライト)。
- NIC が Tx 記述子を読み取ります (インバウンド・リード)。
- NIC がパケットを読み取ります (インバウンド・リード)。
- NIC が Tx 記述子を書き戻して、コアにパケットが送信され Tx 記述子を解放できることを通知します (インバウンド・ライト)。
PCIe* トラフィックの最適化を理解する
最大パケットレートを増やしてレイテンシーを軽減するため、DPDK は次の最適化を使用します。
- アウトバウンド・リードを行わない。Rx および Tx キューの Head の位置を把握するためにコストのかかるアウトバウンド・リード (MMIO 読み取り) を行いません。代わりに、NIC は Rx および Tx 記述子を書き戻してソフトウェアに Head の位置が移動したことを通知します。
- Tx 記述子に関連するインバウンド・ライト帯域幅を減らす。コアに Tx キューの Head の位置と再利用できる Tx 記述子を通知するには Tx 記述子の書き戻しが必要です。パケット受信では、できるだけ早く Rx 記述子を書き戻してコアに新しく到着したパケットの情報を通知することが重要です。パケット送信では、Tx 記述子を書き戻す必要はありません。コアにパケット送信の成功を定期的に (例えば、32 パケットごとに) 通知すれば、その前のすべてのパケットも正常に送信されたことが伝わります。NIC は Tx 記述子の RS (レポートステータス) ビットがセットされると Tx 記述子を書き戻します。DPDK 側には、RS ビットしきい値 (英語) があります。この値は、RS ビットがセットされる頻度、つまり NIC が TX 記述子を書き戻す頻度を定義します。この最適化は、Tx 記述子に関連するインバウンド・ライトを減らします。
- アウトバウンド・ライトを平均化する。DPDK はパケット受信と送信をバッチで行い、アプリケーションはパケットのバッチが処理された後に Tail ポインターを更新します。rx_burst の一部の実装は、Rx 解放しきい値 (英語) を使用しています。このしきい値を使用すると、アプリケーションが Rx キューの Tail ポインターを更新する前に処理される Rx 記述子の数を設定できます (このしきい値はバッチサイズよりも大きい場合にのみ有効になることに注意してください)。アウトバウンド書き込みはパケット間で平均化されます。
プラットフォーム・レベルでは、トランザクションはキャッシュラインの粒度で行われるため、ハードウェアは、常に読み取りと書き込みをまとめて、一部のキャッシュラインが転送されないように試みます。
PCIe* 帯域幅消費を推定する
最適化されたパケット・フォワーディングは、次の式を適用して指定されたパケットレートの PCIe* 帯域幅消費を推定できます。
![]()
![]()
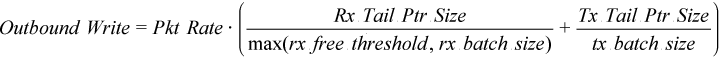
![]()
上記のアウトバウンド・ライト帯域幅の式は、パケットが同じサイズのバッチで処理された場合にのみ有効です。パケットが複数のサイズのバッチで送信された場合、式の精度は低くなります。
単純なフォワーディングでは、コアは受信したパケットをすべて送信します。testpmd は完了までまとめて実行するモデルで設計されたアプリケーションであるため、tx_burst は rx_burst と同じパケットのバッチで動作すると推測できます。つまり、[DPDK Rx Batch Statistics (DPDK Rx バッチ統計)] (「DPDK アプリケーションのコア使用率」レシピを参照) はパケット受信とパケット送信の両方の統計値を反映します。そのため、[DPDK Rx Batch Statistics (DPDK Rx バッチ統計)] を使用して汎用的なケースのアウトバウンド・ライト帯域幅を推定できます。
Tx バッチサイズの代わりに、「平均」Tx バッチサイズを考えます。
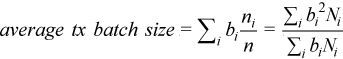
ここで、![]() はバッチサイズ、
はバッチサイズ、![]() は rx_burst 呼び出しの回数 (バッチサイズ
は rx_burst 呼び出しの回数 (バッチサイズ ![]() )、
)、![]() は [DPDK Rx Batch Statistics (DPDK Rx バッチ統計)] の i 番目のピークのパケット数、
は [DPDK Rx Batch Statistics (DPDK Rx バッチ統計)] の i 番目のピークのパケット数、![]() はフォワードされたパケットの総数です。次の図はこの計算の例です。この例では、バッチ統計にはバッチサイズ 8、10、12 の 3 つのピークがあり、計算された平均バッチサイズは 11 です。
はフォワードされたパケットの総数です。次の図はこの計算の例です。この例では、バッチ統計にはバッチサイズ 8、10、12 の 3 つのピークがあり、計算された平均バッチサイズは 11 です。
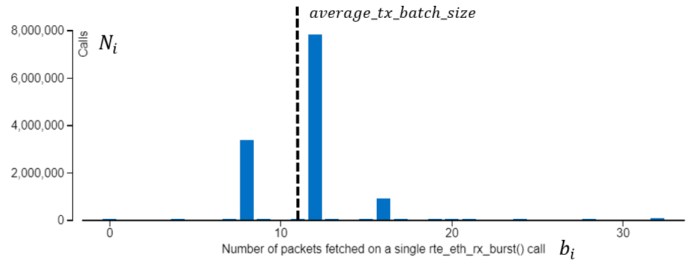
単純にするため、Rx 解放のしきい値がその最大 Rx バッチサイズよりも大きいと考えます。アウトバウンド・ライト帯域幅の最終的な計算は次のようになります。

推定値と解析結果を比較する
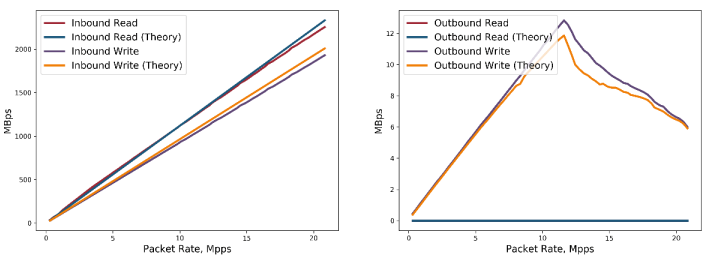
次の 2 つの図は、下記の表にリストされた値で設定された testpmd アプリケーションの、PCIe* 帯域幅の理論的な推定値とインテル® VTune™ Amplifier で収集された PCIe* 帯域幅を示しています。
| パケットサイズ、B | 64 |
| Rx 記述子サイズ、B | 32 |
| RS ビットしきい値 | 32 |
| Rx 解放しきい値 | 32 |
アウトバウンド・ライトの値はほぼ中央のポイントから低下しています。この低下は、処理するパケット数の増加による [DPDK Rx Batch Statistics (DPDK Rx バッチ統計)] の変更が原因です。このポイント以前は [DPDK Rx Batch Statistics (DPDK Rx バッチ統計)] にはバッチサイズ 0 と 4 の 2 つのピークがあり、このポイント以降はバッチサイズ 8 に新しいピークが現れています (下記の 2 つのヒストグラムを参照)。上記の式に当てはめると、平均バッチサイズは増え、アウトバウンド・ライト帯域幅は減ります。
10 Mpps:
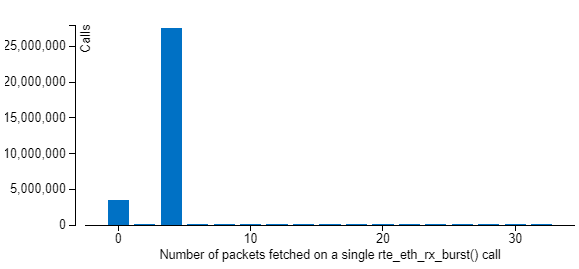
13 Mpps:
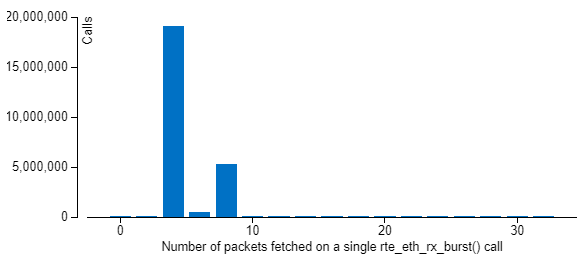
式で考慮していない要素が原因と思われる多少の違いはありますが、概して、理論的な推定値はインテル® VTune™ Amplifier でレポートされたデータに非常に近くなっています。
このレシピで使用したデータ・プレーン・アプリケーションは、すでに適切に最適化されていました。しかし、実際のアプリケーションで I/O 中心のパフォーマンス解析を行う際は、このレシピを利用することを推奨します。
関連情報
- i40e ドライバーの 16/32 バイト Rx 記述子の切り替え (英語)
- testpmd で利用可能なしきい値およびしきい値の変更方法 (英語)
- https://fd.io/wp-content/uploads/sites/34/2018/01/performance_analysis_sw_data_planes_dec21_2017.pdf (英語)
