
注目ドキュメント
導入ガイド | ユーザーガイド | リリースノート (英語)
|
|
インテル® VTune™ Amplifier と Python* プロファイラー
|
インテル® Advisor とインテル® VTune™ Amplifier でメッセージ・パッシング・インターフェイス (MPI) を使用 Linux* 環境で MPI およびハイブリッド MPI & スレッドコードのパフォーマンス・データを取得する手順を説明します。すべてのランクまたは一部のランクをプロファイルする柔軟性を備えています。 |
オンライン・トレーニング
|
インテル® MKL や インテル® IPP などの最適化ライブラリーを使用するとともに、インテル® Advisor とインテル® VTune™ Amplifier による解析およびチューニングにより、クラウドでワークロードを最適化するワークフローを紹介します。 |
インテル® VTune™ Amplifier と OpenMP* でスレッドのパフォーマンスとスケーラビリティーを向上する方法を、サンプルプログラムを使用しながら紹介しています。 |
|
|
|
|
このビデオで説明する問題の検出と解決手順により、ハイブリッド・アプリケーションが期待通りに動作しない根本的な原因を見つけます。 |
|
|
|
|
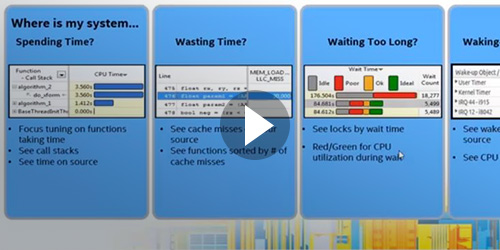
パフォーマンスとスケーラビリティーの問題を検出し、その原因がインバランス、ロック競合、生成のオーバーヘッドまたはスケジュールのオーバーヘッドであるかを特定します。 |
インテル® System Studio の主要な機能を使用して、ホットスポット、電量効率の低下、メモリーリーク、最適化されていないスレッド、その他のシステムの問題を解決します。 |
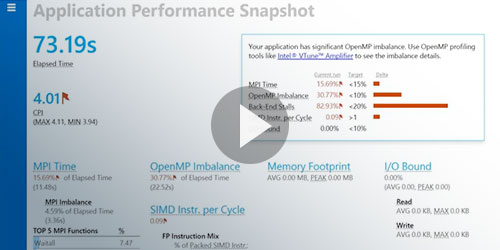
アプリケーション・パフォーマンス・スナップショットのデモをご覧ください。活用されていないパフォーマンスを素早く検出し、ハードウェアを最大限に利用します。 |
|
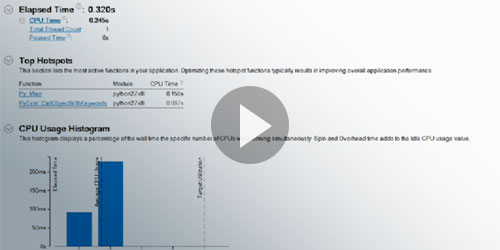
このビデオでは、Python* アプリケーションをプロファイルするニーズ、利点、および一般的なツールとテクニックについて説明します。デモとサンプルコードが含まれます。 |
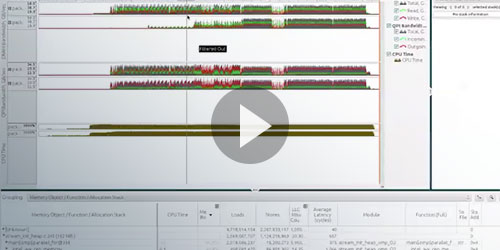
マルチソケットの不均一メモリーアクセス (NUMA) システムでは、ローカル・メモリー・サブシステムにメモリー・オブジェクトを配置することで最高のパフォーマンスが得られます。 |
アプリケーションに並列処理を実装する場所を特定してスケーラビリティーを確認します。 |
|







パフォーマンス解析クックブック
インテル® VTune™ Amplifier を使用した解析手法の利点を見つけてください。
パフォーマンス・チューニングの例と環境依存の構成を調査するいくつかのレシピをご覧ください。
|
|
マイクロアーキテクチャー全般解析を使用して、Data Plane Developer Kit (DPDK) を使用するアプリケーションのマルチソケット・システムにおける潜在的な設定の問題を解析します。 |
バリアやスケジュール・オーバーヘッドのインバランスなど、OpenMP* プログラムでよくある並列ボトルネックを検出して修正する方法を説明します。 |
|
Docker* コンテナーの Java* アプリケーションをプロファイル インテル® VTune™ Amplifier の解析向けに Docker* コンテナーを構成して、独立したコンテナー環境で動作している Java* アプリケーションのホットスポットを特定します。 |
Node.js* で JavaScript* コードをプロファイル Node.js* をリビルドし、インテル® VTune™ Amplifier を使用して、JavaScript* フレームとネイティブフレームから成る混在モードのコールスタックを含む JavaScript* コードのパフォーマンスを解析します。 |
Microsoft* .NET Core アプリケーションのプロファイル インテル® VTune™ Amplifier を使用して .NET Core ダイナミックコードをプロファイルし、マネージドコードのホットスポットを特定してパフォーマンスが向上するようにアプリケーションを最適化します。 |
トレーニング・サンプル
事前作成されたサンプルコードのプロジェクトを開いて、インテル® VTune™ Amplifier の使用方法を学びます。
インストール
インテル® VTune™ Amplifier のサンプルコードをインストールしてセットアップします。
- 製品のインストール先から圧縮ファイルをシステムの書き込み可能なフォルダーにコピーします。
- ファイルを展開します。
注:
- サンプルの結果は非決定論的です。実際の画面は、このチュートリアルで示されている画面とは異なることがあります。
- それぞれのサンプルは、インテル® VTune™ Amplifier の機能を説明するためだけに設計されており、コードをチューニングするベスト・プラクティス示すものではありません。結果は、解析の性質と適用されるコードによって変わります。
サンプル
| 名前 | 説明 |
|---|---|
| tachyon_find_hotspots |
|
| tachyon_analyze_locks |
|
| matrix |
|
| nqueens_parallel |
|
| serial_nqueens_csharp & parallel_nqueens_csharp |
|
| jitprofiling |
|
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
