

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Ready for 2X Moore’s Law: Intel Cluster Studio XE」(http://software.intel.com/en-us/blogs/2011/11/08/ready-for-2x-moores-law-intel-cluster-studio-xe/) の日本語参考訳です。
この記事では、優れたツールのコレクションである インテル® Cluster Studio XE について説明します。インテル® Cluster Studio XE は、クラスターとスーパーコンピューターを活用するため、MPI と他のプログラミング・モデルを使用して開発を行っている HPC プログラマー向けのツール群であり、インテル® Cluster Studio の MPI スケーリングとジョブ・コントロール機能にノードレベルの解析能力を加えた、ハイブリッド・プログラミングを支援する強力な機能を提供します。
ハイブリッド・プログラミングは、MPI (ノード間の並列化に使用) と、OpenMP*、インテル® スレッディング・ビルディング・ブロック (インテル® TBB)、インテル® Cilk™ Plus などの共有メモリーモデル (ノード内の並列化に使用) を組み合わせたものです。ハイブリッド・プログラミングを支援するため、インテル® Cluster Studio XE は、インテル® Inspector XE と インテル® VTune Amplifier XE のクラスター・インストールとクラスターでの使用をサポートしています。インストールは簡単に行うことができます。これらのツールをクラスターで使用することで、膨大なプロセスにおけるノードレベルのデータを収集できます。収集した結果は、アプリケーションの「ランク別」に階層フォーマットで表示されます。
インテル® Inspector XE を使用すると、メモリーリークなどのメモリーエラー、競合状態やデッドロックなどのスレッドエラーを正確に特定することができます。
インテル® VTune™ Amplifier XE を使用すると、正確なパフォーマンス情報を調査して、何がアプリケーションのパフォーマンスに影響を与えているかを完全に理解することができます。インテル® VTune™ Amplifier XE は、ノードレベルのパフォーマンスを調査して、インテル® Trace Analyzer/Collector (MPI 通信のパフォーマンスを調査) を補完します。これらのツールを使用することで、ハイブリッド・プログラムのパフォーマンスについて非常に優れた見解が得られます。
新しい SLURM ジョブ・マネージャーのサポート
インテル® MPI ライブラリー 4.0.3 では、SLURM (https://computing.llnl.gov/linux/slurm/) ジョブ・マネージャーのサポートにより、ジョブ・サブミッションとスタートアップ時間を、より詳細に制御できるようになりました。また、プログラムがエラーにより途中で終了した場合にプロセスをクリーンアップするための情報も提供されます。
MPI ライブラリーは、多くのランクとそれぞれのリソース使用率 (メモリー、CPU 使用率、キャッシュアクセス、その他) をジョブ・スケジューラーで確認および管理できるように拡張されました。これまでは、ジョブ・スケジューラーはリソースリークのような状態をもたらすランクが終了したかどうか分からなかったため (“kill -9” のようにプロセスを終了する必要がありました)、この状態で多くのプロセスを実行することは問題でした。拡張後は、SLURM でランク間のプロセスの状態を確認して、適切にクリーンアップできるようになりました。SLURM 互換ベースのジョブ・スケジューラーでこの機能をセットアップおよび使用する方法については、ドキュメントを参照してください。
ムーアの法則より速い?
スーパーコンピューターのパフォーマンスがムーアの法則の約 2 倍の速さで向上しているのは非常に興味深いことです。以下の Top500 パフォーマンス・グラフ (http://www.Top500.org/lists/2011/06/performance_development/ より転載) は、Top500 スーパーコンピューターのパフォーマンス向上率が毎年 80% 以上であることを示しています。これに対して、ムーアの法則のパフォーマンス向上率は毎年 40% に過ぎません。
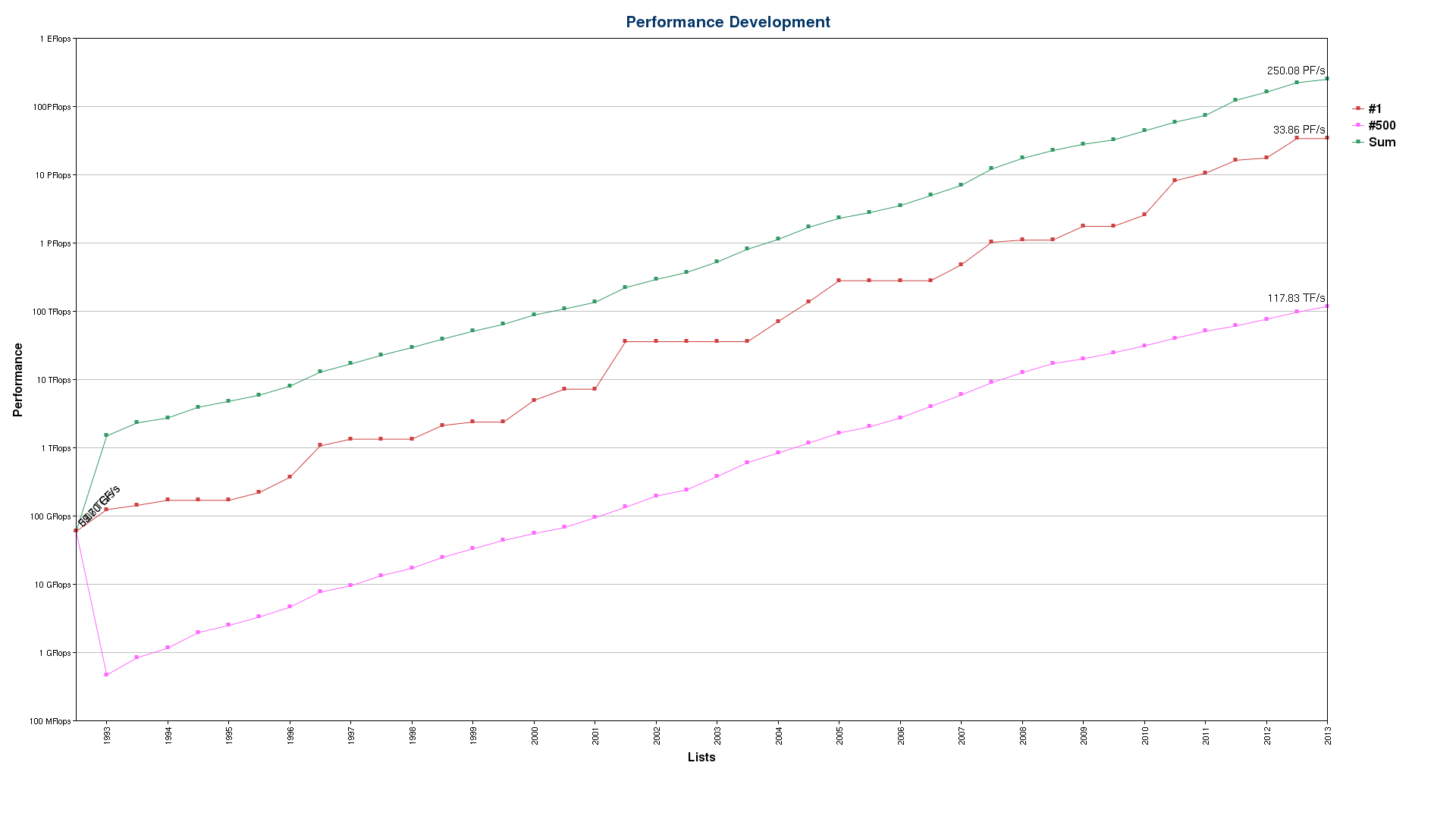
ムーアの法則は集積回路の密度が 2 年で 2 倍になることを予測したものであり、パフォーマンス向上率を示したものではありません。しかし、実際には、集積回路の密度が増加するに伴い、コンピューターのパフォーマンスは絶えず向上しています。この、年間で約 2 倍という高いパフォーマンス向上率を達成するため、スーパーコンピューターは複数のレベルで並列化を行えるように設計されています。
ハイブリッド・プログラミングは、この流れに沿うものです。10 年前、MPI プログラミングは大規模システム向けのものがほとんどでした。この 10 年の間、個々のクラスターノードは「より肥大化」しました。このノードレベルの「肥大化」により、HPC 開発者は、ノードレベルの並列化ではなく、ノード間の並列性をプログラムするようになりました。そのほとんどは MPI + OpenMP でプログラミングされており、ノードレベルのプログラミングの選択肢は多様化しています。
インテル® Cluster Studio XE がなぜ重要なのかという理由はここにあります (特に新しいハイブリッド・プログラミングについて検討する場合)。
インテル® Cluster Studio XE とインテル® Inspector XE/インテル® VTune Amplifier XE の違い
インテル® Cluster Studio XE は、インテルが提供している HPC ソフトウェア開発ツールのほぼすべてを組み合わせたものです。最大規模のスケーリング環境とアプリケーションで、「ムーアの法則を超えるパフォーマンス向上率」を保つには、利用可能なすべての手法を用いる必要があるためです。
インテル® Cluster Studio XE には、インテル® C/C++ コンパイラーとインテル® Fortran コンパイラーに加えて、インテル® プロセッサーおよび互換プロセッサー向けに高度に最適化された、インテル® マス・カーネル・ライブラリー (インテル® MKL) などのライブラリーが含まれています。
インテルの目標は、優れたパフォーマンスとさまざまな規格のサポートを提供することです。現在は、(大部分の) C++11、Fortran 2003、Fortran 2008、IEEE 754-2008 をサポートしています。これらの 4 つの新しい規格は、一部を除いてサポートされます。現時点で、これらの 4 つの規格をすべてサポートしている開発ツールはほかに存在しません。詳細については、製品に含まれるドキュメントを参照してください。各規格で最も重要で、かつ最も要望の多い部分はすでにサポートしており、残りについても対応中です。
また、最新のインテル® Cilk™ Plus 1.1、インテル® TBB 4.0、OpenMP 3.1 も完全にサポートしています。インテル® MKL には、BLAS、LAPACK、スパースソルバー、高速フーリエ変換、ベクトル演算などの主要な数学関数が含まれています。クラスター向けに ScaLAPACK の高度に最適化されたバージョンも含まれており、大幅にパフォーマンスを向上させることができます。
マルチコアだけでなく、将来のメニーコアにも対応
インテル® Cluster Studio XE には、現在のマルチコア・プログラミング向けのツールとモデルが含まれています。これらのツールとモデルは、将来のメニーコア・プログラミングにも対応します。コア数の増加に伴って、開発者に別のプログラミング手法を強いることは避けるべきです。スケーラブルなアプリケーションを作成するのは容易ではありませんが、少なくとも、2 つの作業ではなく 1 つの作業に集約することはできます。
マルチコア向けのスケーリングの手法とツールは、メニーコア向けに使用するものと同じです。インテル® Cluster Studio XE の将来のバージョンでは、すべてのマルチコアとメニーコアがサポートされる予定です。現在のマルチコアシステム向けの手法が将来のメニーコアシステムでも利用できることが保証されているため、新たに手法を学習する必要はありません。
メニーコアのプロトタイプ・システム (Knights Ferry) では制限付きでメニーコアをサポートしており、間もなく納入予定の最初のメニーコア・システムの 1 つ (Stampede (http://insidehpc.com/2011/09/23/taccs-stampede-a-home-run-for-intels-mic/)) にも現在対応中です。詳細は、Supercomputing カンファレンス 2011 (シアトルで開催) で紹介します。私も、インテルのソフトウェア開発製品チームのメンバーと一緒に参加する予定です。運がよければ、Dr. Fortran (http://software.intel.com/en-us/blogs/author/steve-lionel) にも会えるでしょう。今後もさまざまなソフトウェア・カンファレンスでお会いする機会があるでしょう。世界中の開発者の方々にお会いして、皆さんをどのように支援できるかお話できることを楽しみにしています。
インテル® Cluster Studio XE をぜひお試しください
インテル® Cluster Studio XE は、HPC 向けの最適なプログラムを開発するために MPI プログラマーが必要とする重要な機能を提供します。インテル® Cluster Studio XE は、これらの機能を必要とするプログラマーに、適正な価格で、インストールが簡略化された単一のパッケージを提供します。是非お試しになり、ご感想、ご要望をお寄せください。
編集部追加
インテル® Cluster Studio XE の価格やライセンスに関するご質問や、評価版のご利用に関するお問い合わせはエクセルソフト株式会社まで。評価中に不明点があれば、お問い合わせフォームより評価されている旨を添えることで、テクニカルサポートに問い合わせることができます。あるいは iSUS ユーザーフォーラムにて問題を共有し、解決方法を探ることもできます。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
