
この記事は、The Parallel Universe Magazine 44 号に掲載されている「Using oneAPI to Speed Up the Finite-Difference Method」の日本語参考訳です。

リバース・タイム・マイグレーション (RTM) では、有限差分法 (FD) を使用して音響波動方程式の近似値を計算します。これは、RTM アプリケーションの計算上のボトルネックとなっており、炭化水素探査のリソースを割り当てる際に、タイムリーな結果と効率を保証するため最適化する必要があります。この記事では、インテル® DPC++ 互換性ツールを使用して、CUDA* ベースの RTM コードをデータ並列 C++ (DPC++) に移行した経験について説明します。
RTM の概要と入力データ
いくつかの地震探査法では、FD スキームにおいて、波動方程式の数値解としてステンシルが適用されています。石油ガス産業で地下構造の画像を生成するために広く使用されている RTM でもこの方法を採用しています。この方法には利点がありますが、2 つの大きな計算上のボトルネックがあります。伝播ステップで浮動小数点演算が多いことと、メインメモリーへの波動場の保存が困難なことです。これらのボトルネックの影響を軽減するため、エンジニアはタスクの並列性と計算リソースの最適化の両方を追求し、さまざまなアクセラレーターで実行可能なソリューションを設計しています。この方法の最適化は、井戸掘削におけるエラーの可能性を軽減させるため、探査地球物理学に大きな経済的利点をもたらします。Claerbout が提案したように、RTM アルゴリズムは通常、前方時間伝播、後方伝播、および画像条件の相互相関を行います。RTM アルゴリズムのフローチャートでは、これらのステップをホストとデバイスの通信とともに示しています (図 1)。
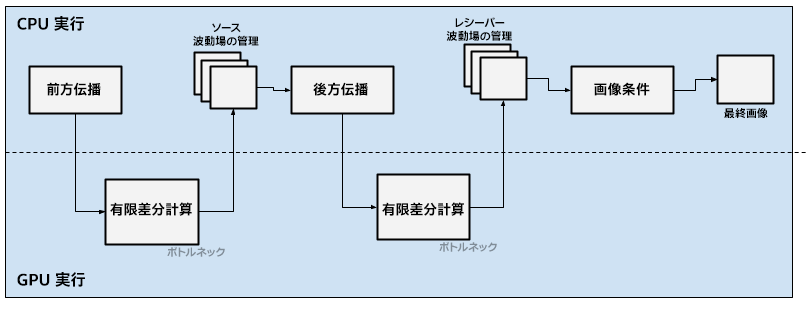
図 1. 簡易 2 次元 RTM フローチャート
図 2 は、2 次元の CUDA* ベースの実装におけるステンシル計算を示しています。order は FD スキームの次数、nx と nz は 2 次元音響速度モデルを表す入力行列のサイズ、p はソース / レシーバーの波動場、cx と cy はそれぞれ FD 係数の x 軸と y 軸、l は外挿された波動場を表しています。RTM アルゴリズム全体では、ベクトル P は異なる時間ステップにおける圧力ポイントの状態を格納しています。RTM は、計算量とデータ量が多いため、専用の処理ユニットによる高速化に適しています。
Input: order, nx, nz,*p, *l, *cx, *cy
Output: *l
Assignments: h_order ← order/2
i← h_order + blockId.x * blockDim.x + threadId.x
j ← h_order + blockId.y * blockDim.y + threadId.y
mult ← i * nz
if < nx – h_order then
if < nz - h_order then
for k = 0 to h_order do
aux = k - h_order
aux += p[mult + j+aux] * cz[k]
aux += p[(i+aux)*nz + j] * cx[k]
end for
l[mult + j] = accz + accx
accz = 0
accx = 0
end if
end if
図 2. RTM ステンシル計算アルゴリズム
リファレンス RTM から oneAPI への移行
インテル® DPC++ 互換性ツールは、CUDA* 言語カーネルやライブラリーの API 呼び出しを DPC++ に移行するのを支援します。通常、CUDA* ソースコードの 80 ~ 90% は自動的に移行されるため、このプロセスは「準備」、「移行」、「レビュー」の 3 つの段階で構成されます。準備段階では、ソースコードを移行ツールに適応させることを目指します。この段階では、すべての CUDA* ヘッダーファイルがデフォルトの場所、または --cuda-include-path=<path/to/cuda/include> オプションで指定したカスタムの場所にあることを確認する必要があります。移行段階では、インテル® DPC++ 互換性ツールがオリジナルのアプリケーションを入力として受け取り、注釈付きの DPC++ コードを生成します。レビュー段階では、自動変換されたコードを確認し、移行されなかったコードを手動で変換するための注釈をレビューし、コードの改善の可能性を探ります。
最初の移行では、図 3 に示すように、インテル® DPC++ 互換性ツールによって、CUDA* のメモリーコピー API 呼び出しが sycl::queue.memcpy() に移行されることを確認しました。正常に動作し、エラーのない DPC++ ソースコードが得られても、明示的なメモリー管理では最高のパフォーマンスが得られない可能性があります。メモリー管理の改善について調査するため、移行後のソースコードを手動で変更し、各データ・オブジェクトで SYCL* のバッファーとアクセサーを使用するようにしました。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
