
この記事は、The Parallel Universe Magazine 43 号に掲載されている「Migrating from CUDA to DPC++ Using the Intel® DPC++ Compatibility Tool」の日本語参考訳です。

将来のコンピューティング・システムはヘテロジニアスになることが明白になりつつあります。テネシー大学の MAGMA (英語) プロジェクトは、LAPACK に似ていますが、最新の CPU および GPU システムを含むヘテロジニアス・アーキテクチャー向けの密線形代数ライブラリーを開発しています。異なるアーキテクチャーで優れたパフォーマンスを提供するスパースソルバーのコードサンプルを探していたとき、MAGMA は有力な候補でした。この記事では、インテル® DPC++ 互換性ツール (DPCT) を使用して MAGMA の CUDA* コードをデータ並列 C++ (DPC++) に移行する方法を説明します。
移行手順と必要な変更
ヘテロジニアス並列処理は、CFD 向けに CUDA* で実装されていました。基本的には、流体力学の 3 次元オイラー方程式を計算します。このアプリケーションは計算集約型であり、計算依存の問題があります。
移行する方法は 2 つあります。1 つ目の方法は、ファイルからファイルへの手動移行で、わずかなファイルを移行する場合に適しています。2 つ目の方法は、make または cmake を使用するプロジェクト向けの .json ファイルを作成することです。MAGMA には makefile が用意されているため、JSON アプローチを利用します。
入力プロジェクト・ファイルのビルドオプション (インクルード・パス、マクロ定義など) は、intercept-build make コマンドを使用して .json ファイルに格納します (Make 4.0 以降を使用していることを確認してください)。次に、dpct コマンドを実行します。このコマンドには、移行に役立つオプションが用意されています。MAGMA を移行するためのコマンドラインは次のとおりです。

表 1. オプションと説明

(その他のオプションは、コマンドライン・オプション・リファレンス (英語) を参照してください。)
次のステップは、アプリケーションで dpct を実行した後の出力を解釈することです。dpct は、コードを DPC++ 準拠にする、または構文的に正しくするため変更が必要な可能性のある場所に注釈を付けます。

大規模なプロジェクトの場合、移行ログをファイルにリダイレクトすることを推奨します。ツールでレポートされるエラーコード/診断の詳細は、こちら (英語) を参照してください。
図 1 と図 2 は、MAGMA ライブラリーからのカーネル呼び出しの正常な移行を示しています。–keep-original-code オプションを使用しているため、オリジナルコードも移行後のファイルに存在します (図 2)。
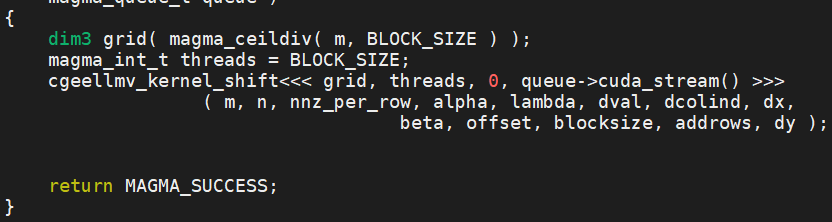
図 1. オリジナル CUDA* コード
図 2. 移行後の DPC++ コード
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
