

この記事は、The Parallel Universe Magazine 39 号 (https://software.intel.com/en-us/download/parallel-universe-magazine-issue-39-january-2020) に掲載されている「Heterogeneous Programming Using oneAPI」の日本語参考訳です。

今日のハードウェアが達成可能な最大パフォーマンスを引き出すには、ハードウェア機能を適切に使用することと、移植性が高く保守が容易な電力効率の良いコードのバランスをうまく取ることです。これらの要因は必ずしも連携して作用するとは限りません。ユーザーのニーズに応じて優先順位付けする必要があります。ユーザーにとって、アーキテクチャーごとに個別のコードベースを維持することは容易ではありません。スカラー、ベクトル、行列、および空間アーキテクチャーでシームレスに動作する標準化に準拠して簡素化されたプログラミング・モデルは、コードの再利用を高め、習得への投資を軽減することで開発者の生産性を高めます。
oneAPI は、これらの利点を提供するインテル主導の業界イニシアチブです。標準およびオープン仕様に基づいており、データ並列 C++ (DPC++) (英語) 言語とドメイン・ライブラリー群が含まれます。oneAPI の目標は、業界のハードウェア・ベンダーがそれぞれの CPU やアクセラレーター向けに独自の互換性のある実装を開発することです。これにより、開発者は複数のアーキテクチャーとベンダーデバイスにわたって、単一の言語とライブラリー API でコーディングすることができます。
インテル製 CPU とアクセラレーター向けのインテルのベータ版 oneAPI 開発ツール実装には、インテル® oneAPI ベース・ツールキット (英語) に加えて、異なるユーザー向けのいくつかのドメイン固有のツールキット—インテル® oneAPI HPC ツールキット (英語)、インテル® oneAPI IoT ツールキット (英語)、インテル® oneAPI DL フレームワーク・デベロッパー・ツールキット、およびインテル® oneAPI レンダリング・ツールキット (英語)—があります。
図 1 は、ベータ版インテル® oneAPI (英語) 製品とインテル® oneAPI ベース・ツールキットの各種レイヤーを示しています。インテル® oneAPI ベース・ツールキットには、インテル® oneAPI DPC++ コンパイラー、インテル® DPC++ 互換性ツール、複数の最適化ライブラリー、高度な解析およびデバッグツールが含まれます。さまざまなアーキテクチャーにわたる並列性は、Khronos Group の SYCL* をベースとした DPC++ 言語を使用して表現されます。DPC++ 言語は、最新の C++ 機能とインテル固有の拡張によりアーキテクチャーを効率良く使用します。コードは CPU で実行することも、利用可能なアクセラレーターへオフロードすることもできるため、コードの再利用が可能です。フォールバック・プロパティーにより、アクセラレーターが利用できない場合、コードは CPU で実行されます。ホストとアクセラレーターでの実行とメモリー依存関係は明確に定義されます。
インテル® DPC++ 互換性ツールを使用して、CUDA* から DPC++ へコードを移行することもできます。このツールは、開発者が短期間で移行できるように支援し、通常はコードの 80 ~ 90% を自動的に移行します。
DPC++ に加えて、インテル® oneAPI HPC ツールキットは、コードを GPU へオフロードできる OpenMP* 5.0 機能をサポートします。ユーザーは、DPC++ を使用するか、既存の C/C++/Fortran コードのオフロード機能を使用することができます。API ベースのプログラミングは、インテル® GPU 向けに最適化されたライブラリー群 (例えば、インテル® oneAPI マス・カーネル・ライブラリー (英語)) によってサポートされます。
ベータ版インテル® oneAPI 製品は、インテル® VTune™ プロファイラー1 とインテル® Advisor2 でも新しい機能を提供しており、アクセラレーターへオフロードしたコードをデバッグしたり、オフロードコードのパフォーマンス・メトリックを確認できます。
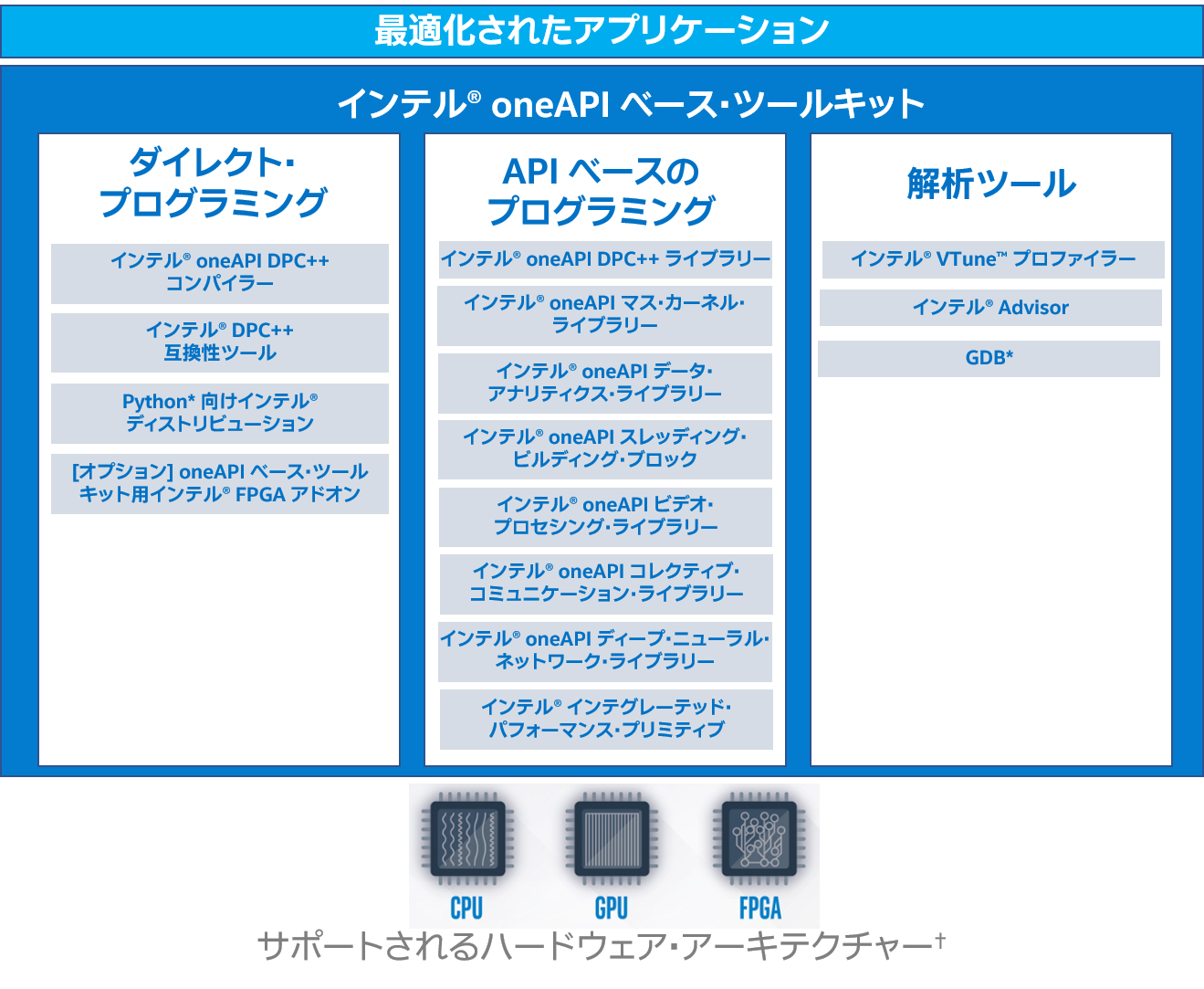
図 1. ベータ版インテル® oneAPI ベース・ツールキットのコンポーネント
この記事では、ヘテロジニアス・プログラミングを推進するベータ版インテル® oneAPI 製品を紹介します。インテル® oneAPI ソフトウェア・モデルについて述べ、コンパイルモデルとバイナリー生成手順を説明します。インテル® oneAPI は、すべてのアーキテクチャーに対応した単一のバイナリーを生成するため、コンパイルとリンク手順が通常のバイナリー生成方法と異なります。最後に、いくつかのサンプルプログラムを検証します。この記事では、「アクセラレーター」、「ターゲット」、「デバイス」という用語を同じ意味で使用していることに注意してください。
インテル® oneAPI ソフトウェア・モデル
SYCL* 仕様ベースのインテル® oneAPI ソフトウェア・モデルは、コード実行とメモリー使用の観点からホストとデバイス間の相互作用を表します。モデルは 4 つの部分で構成されます。
- プラットフォーム・モデルは、ホストとデバイスを指定します。
- 実行モデルは、デバイスで実行されるコマンドキューとコマンドを指定します。
- メモリーモデルは、ホストとデバイス間のメモリー使用を指定します。
- カーネルモデルは、計算カーネルのターゲットをデバイスにします。
プラットフォーム・モデル
インテル® oneAPI プラットフォーム・モデルは、ホストと、互いにまたはホストと通信する複数のデバイスを指定します。ホストはデバイス上のカーネルの実行を制御し、複数のデバイスが存在する場合はそれらの間で調整します。各デバイスは、複数の計算ユニットを持つことができます。そして、各計算ユニットは、複数の処理要素を持つことができます。プラットフォームがインテル® oneAPI ソフトウェア・モデルの最小要件を満たしていれば、インテル® oneAPI 仕様は GPU、FPGA、ASIC など、複数のデバイスをサポートできます。通常、特定のオペレーティング・システム、特定の GNU* GCC バージョン、デバイスに必要な特定のドライバーがホストにインストールされている必要があります(プラットフォーム要件の詳細は、インテル® oneAPI の各コンポーネントのリリースノートを参照)。
実行モデル
インテル® oneAPI 実行モデルは、ホストとデバイスでのコードの実行方法を指定します。ホスト実行モデルは、カーネルの実行とホストとデバイス間のデータ管理を調整するためコマンドグループを作成します。コマンドグループは、インオーダーまたはアウトオブオーダー・ポリシーで実行可能なキューに送信されます。次のコマンドが実行される前にデバイス上の更新データをホストが利用できるように、キュー内のコマンドを同期できます。
デバイス実行モデルは、アクセラレーターでの計算処理を指定します。実行範囲には、一連の要素 (1 次元または多次元のデータセット) が含まれており、図 2 の 3 次元の場合に示すように ND-Range、work-group、sub-group、および work-item の階層に分割されます。
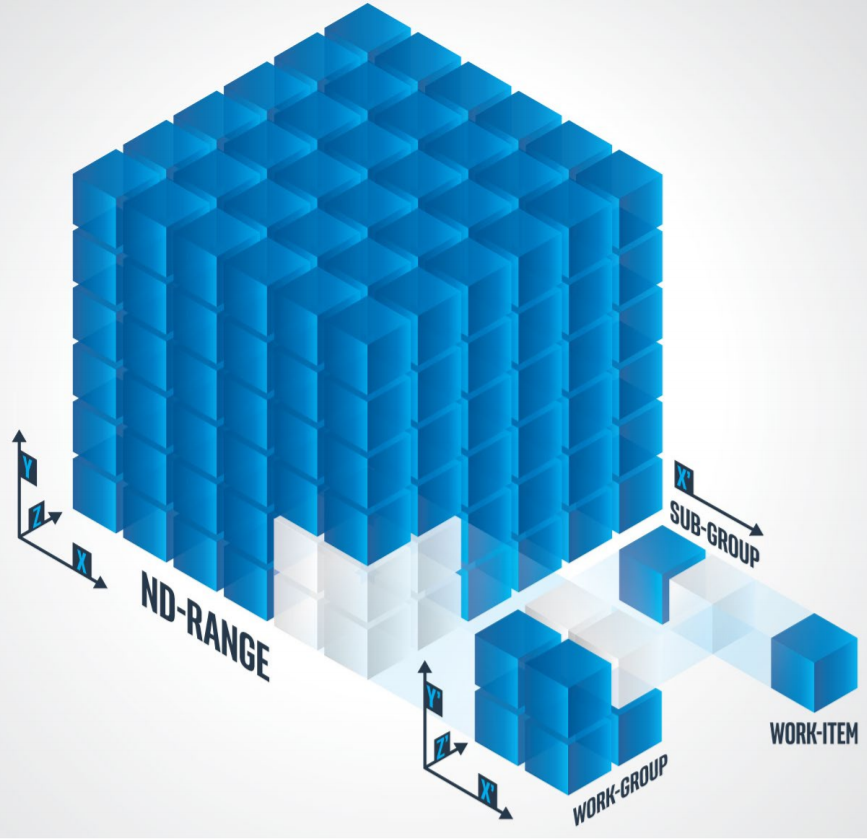
図 2. ND-Range、work-group、sub-group、および work-item の関係
これは、インテル拡張である sub-group を除いて SYCL* モデルに似ています。work-item は、カーネル内の最小実行単位です。work-group は、work-item 間のデータ共有方法を決定します。この階層レイアウトは、パフォーマンスを向上するために使用すべきメモリーの種類も決定します。例えば、work-item は通常デバイスメモリーに格納されている一時データを操作し、work-group はグローバルメモリーを操作します。sub-group は、ベクトルユニットを備えたハードウェア・リソースをサポートするために追加されました。これにより要素の並列実行が可能です。
図 2 から ND-Range 内の work-group または work-item の場所が重要であることは明らかです。これは、計算カーネル内で更新されるデータポイントを決定します。各 work-item が操作する ND-Range のインデックスは、nd_item クラスの組込み関数 (global_id、work_group_id、sub_group_id、および local_id) を使用して決定されます。
メモリーモデル
インテル® oneAPI メモリーモデルは、ホストとデバイスによるメモリー・オブジェクトの処理を定義します。これは、アプリケーションのニーズに応じて、ユーザーがメモリーの割り当て場所を決定するのに役立ちます。メモリー・オブジェクトは、タイプバッファーまたはイメージとして分類されます。メモリー・オブジェクトの場所とアクセスモードは、アクセサーを使用して指定できます。アクセサーは、ホスト上のオブジェクト、デバイス上のグローバルメモリー、デバイスのローカルメモリー、またはホスト上のイメージに対して異なるアクセスターゲットを提供します。アクセスタイプは、読み取り、書き込み、アトミック、または読み書きです。
統合共有メモリーモデルにより、ホストとデバイスは明示的なアクセサーを使用せずにメモリーを共有できます。イベントを使用する同期は、ホストとデバイス間の依存関係を管理します。ユーザーは、ホストまたはデバイスで更新されたデータをいつ再利用できるようにするか制御するイベントを明示的に指定するか、暗黙的にこの決定をランタイムまたはデバイスドライバーに任せることができます。
カーネル・プログラミング・モデル
インテル® oneAPI カーネル・プログラミング・モデルは、ホストとデバイスで実行されるコードを指定します。並列処理は自動では行われません。ユーザーが言語構造を使用して明示的に指定する必要があります。
DPC++ 言語は、ホスト側で C++11 以降の機能をサポートできるコンパイラーを必要とします。しかし、デバイスコードには、C++03 機能と、ラムダ式、可変引数テンプレート、右辺値参照、エイリアス・テンプレートなどの特定の C++11 機能が必要です。std::string、std::vector、および std::function サポートも必要です。仮想関数と仮想継承、例外処理、ランタイム型情報 (RTTI)、および new と delete 演算子を使用するオブジェクト管理を含むデバイスコードには特定の制限があります。
ユーザーは、さまざまな方法でホストコードとデバイスコードを区別できます。ラムダ式は、カーネルコードとホストコードを一致させることができます。ファンクターは、ホストコードを同じソースファイルの別の関数として保持できます。OpenCL* コードを移行するユーザー、またはホストとデバイスコード間に明示的なインターフェイスを必要とするユーザー向けに、カーネルクラスは必要なインターフェイスを提供します。
ユーザーは、3 つの異なる方法で並列処理を実装できます。
- 単一のタスク: 単一の work-item でカーネル全体を実行します。
parallel_for構造: 処理要素全体でタスクを分散します。parallel_for_work_group:parallel_for_work_group構造は、work-group全体でタスクを分散します。work-group内のwork-itemは、バリアを使用して同期できます。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
