
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Advisor Cookbook」の「Visualize Performance Improvements with Roofline Compare」(https://software.intel.com/en-us/advisor-cookbook-visualize-performance-improvements-with-roofline-compare) の章の日本語参考訳です。
ルーフラインの比較機能を使用して、開発者は異なるルーフライン結果から類似するループや関数を識別して、適切な最適化を選択することができます。ここでは、2 つのルーフライン解析結果を比較して、アプリケーションのループと関数に対する改善を視覚化する手順を説明します。
シナリオ
このレシピでは、ルーフラインの比較機能を使用して、一連の最適化ステップでもたらされる改善点を示します。
コンポーネント
ここでは、このレシピで示される特定の結果を得るために使用されたハードウェアとソフトウェアをリストします。
- パフォーマンス解析ツール: インテル® Advisor 2019 Update 4
最新バージョンは、https://www.isus.jp/intel-advisor-xe/ からダウンロードできます。 - アプリケーション: インテル® Advisor のインストール・ディレクトリーにあるサンプルパッケージに含まれる vec_sample コード。このレシピで紹介するコードと最適化の手順は『ベクトル化アドバイザーを使用したコードの効率良い SIMD 並列化』チュートリアルの一部です。インテル® Advisor 2019 のチュートリアルは https://software.intel.com/en-us/articles/advisor-tutorials から入手できます。
- コンパイラー: Microsoft* C/C++ 最適化コンパイラー、バージョン 19.14.26431 x64 版
- オペレーティング・システム: Microsoft* Windows* 10、バージョン 1709
- CPU: インテル® Core™ i5-7300HQ プロセッサー
ベースラインのルーフライン結果を収集
デフォルトのコンパイラー最適化オプション O2 で、ルーフライン解析を行い、スナップショット機能 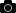 を使用して結果を保存します。この結果を Snapshot_Baseline とします。次のようにルーフライン・グラフを表示します。マウスをドットに移動すると、ループのパフォーマンス・メトリックが表示されます。ループ間に示される十字線にマウスをホバーすると水平線と垂直線が青色に強調され、プログラム全体のパフォーマンス・メトリックが表示されます。
を使用して結果を保存します。この結果を Snapshot_Baseline とします。次のようにルーフライン・グラフを表示します。マウスをドットに移動すると、ループのパフォーマンス・メトリックが表示されます。ループ間に示される十字線にマウスをホバーすると水平線と垂直線が青色に強調され、プログラム全体のパフォーマンス・メトリックが表示されます。
結果を見やすくするため、[ルーフの設定] の L1、L2、L3、および DRAM の帯域幅の値を次のように変更します。また、アプリケーションは単精度 (SP) のみを使用するため、倍精度 (DP) のピークの [表示] チェックボックスをオフにします。[保存] ボタンをクリックして、ビューに名前を付けて json ファイルとして保存します。保存したファイルを [ロード] することで、以降ルーフラインを表示する際に同じ設定を適用できます。
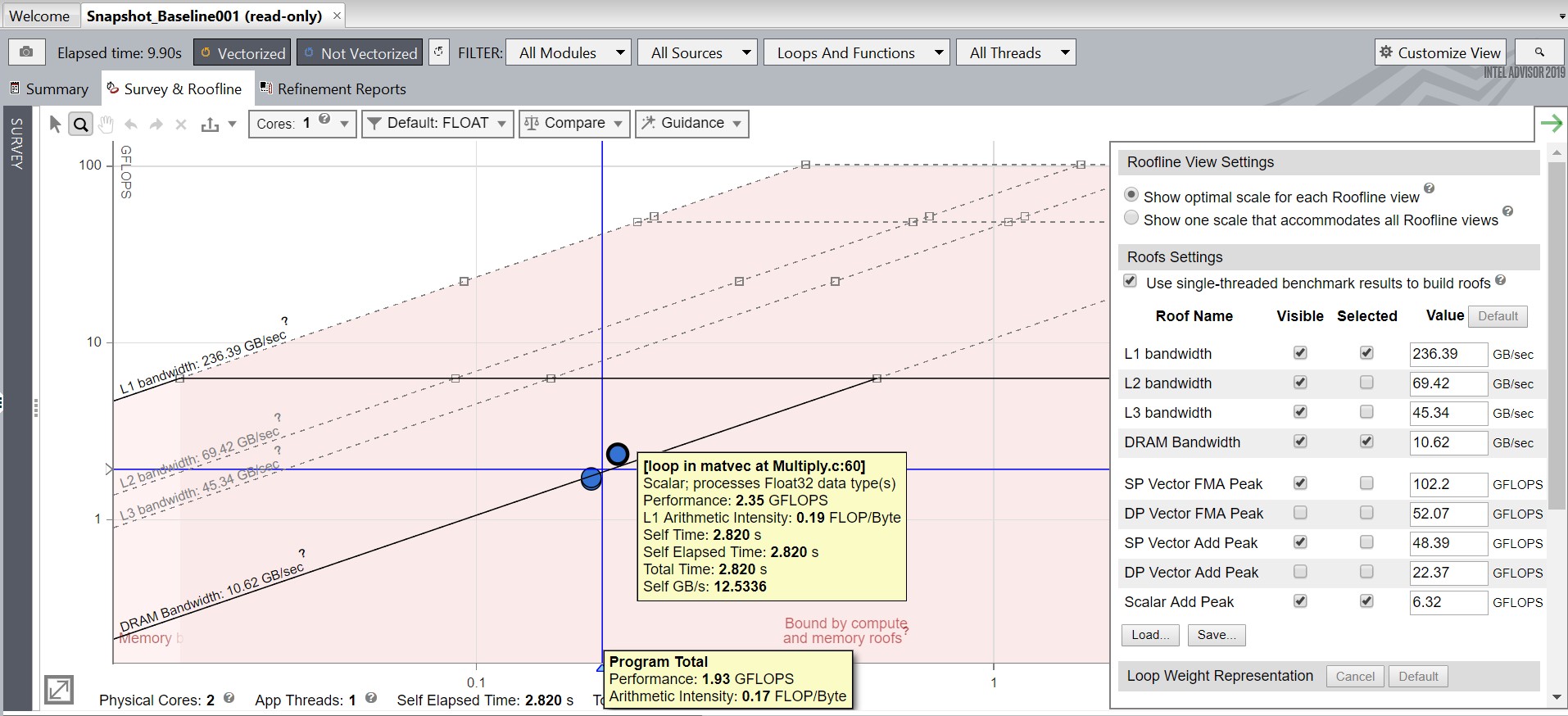
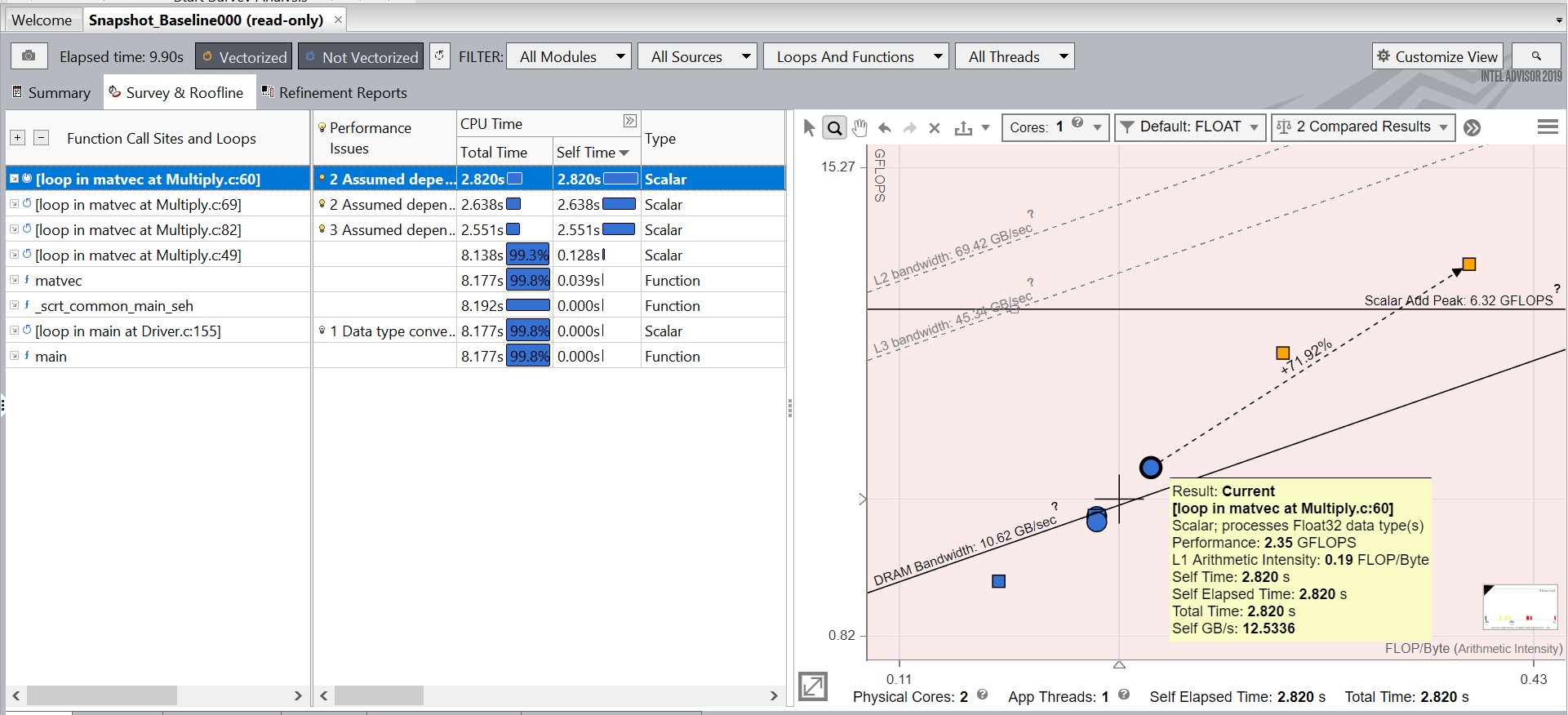
Snapshot_Baseline のサーベイレポートの次の点に注意してください。
- 画面の左上にある [経過時間] の値。これは、以降のパフォーマンス向上を測定する際のベースラインとなります。
- [タイプ] カラムでは、検出されたループはすべてスカラーです。
- [ベクトル化できない理由] カラムには、コンパイラーが検出または想定したループのベクトル化を妨げる理由が表示されます。
NOALIAS マクロで最適化
- [ベクトル化できない理由] タブをクリックし、コンパイラーが依存関係を検出または想定したループをクリックします。
- [推奨事項] セクションまでスクロールして、ループをベクトル化に関する提案を表示します。次の例では restrict キーワードの使用が提案されています。
![Snapshot_Baseline の [ベクトル化できない理由 (No Vectorization?)] タブ](https://www.isus.jp/wp-content/uploads/248E04F3-32D9-4EDE-A6BB-A6AFD0F37CC9.jpg)
restrict は、2 つのポインターがオーバーラップするメモリー領域を指すことがないことを確実にします。コンパイラーは、メモリーブロックへのポインターが 1 つしかないことを知っていると、より最適化されたベクトルコードを生成できます。最初の最適化では NOALIAS マクロを使用してコンパイラーに情報を提供することで、ポインターのエイリアシングによる影響を緩和します。
- Visual Studio* IDE で、[ソリューション エクスプローラー] にある vec_samples プロジェクトを右クリックして、[プロパティ] を選択します。
- [構成プロパティ] > [C/C++] > [コマンドライン] を選択します。[追加のオプション] に、/DNOALIAS を追加します。
- [適用] をクリックし [OK] で設定を終了します。
- [ビルド] メニューから [ソリューションのリビルド] を選択します。
ルーフライン解析の再実行
- [ベクトル化ワークフロー] ペインで、[ルーフラインを実行] にある [Collect] ボタンをクリックし、生成された結果を Snapshot_NoAlias として保存します (必須ではありませんが、新しいディレクトリーに保存することを推奨します)。
- 右上の角にある
 メニューアイコンをクリックして、保存した json ファイルをロードします。ファイルがロードされると、ルーフは Snapshot_Baseline の設定に従って調整されます。
メニューアイコンをクリックして、保存した json ファイルをロードします。ファイルがロードされると、ルーフは Snapshot_Baseline の設定に従って調整されます。 - 以下に示すように、プログラムの合計パフォーマンスと matvec の Multiply.c:60 にあるループの改善に注目してください。
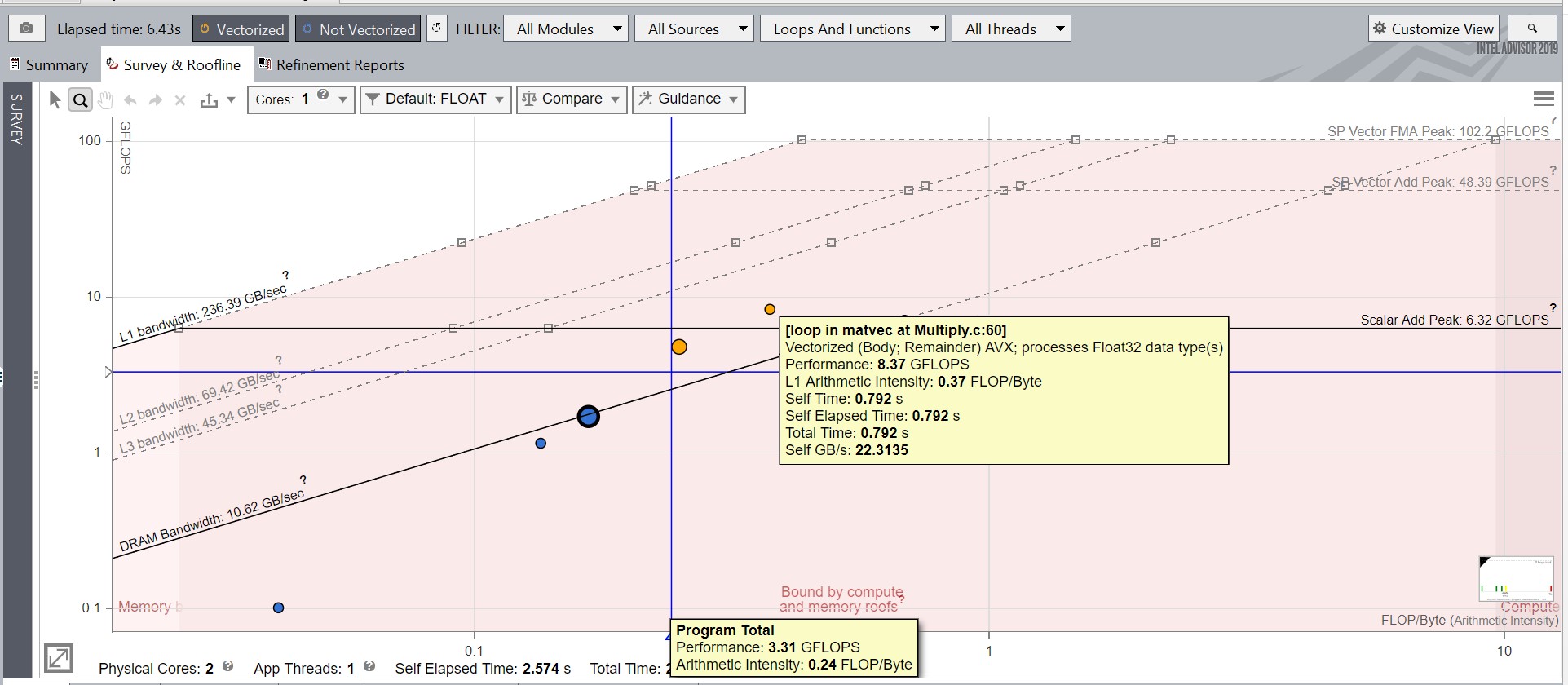
- サーベイレポートでは次に注目します。
- [ベクトル ISA] カラムの値は、おそらく AVX2/AVX/SSE2 です。これは、デフォルトのベクトル命令セット・アーキテクチャー (ISA) です。
- コンパイラーは、matvec の Multiply.c:69 と Multiply.c:60 を適切にベクトル化しています。
- [経過時間] も大幅に改善されています。
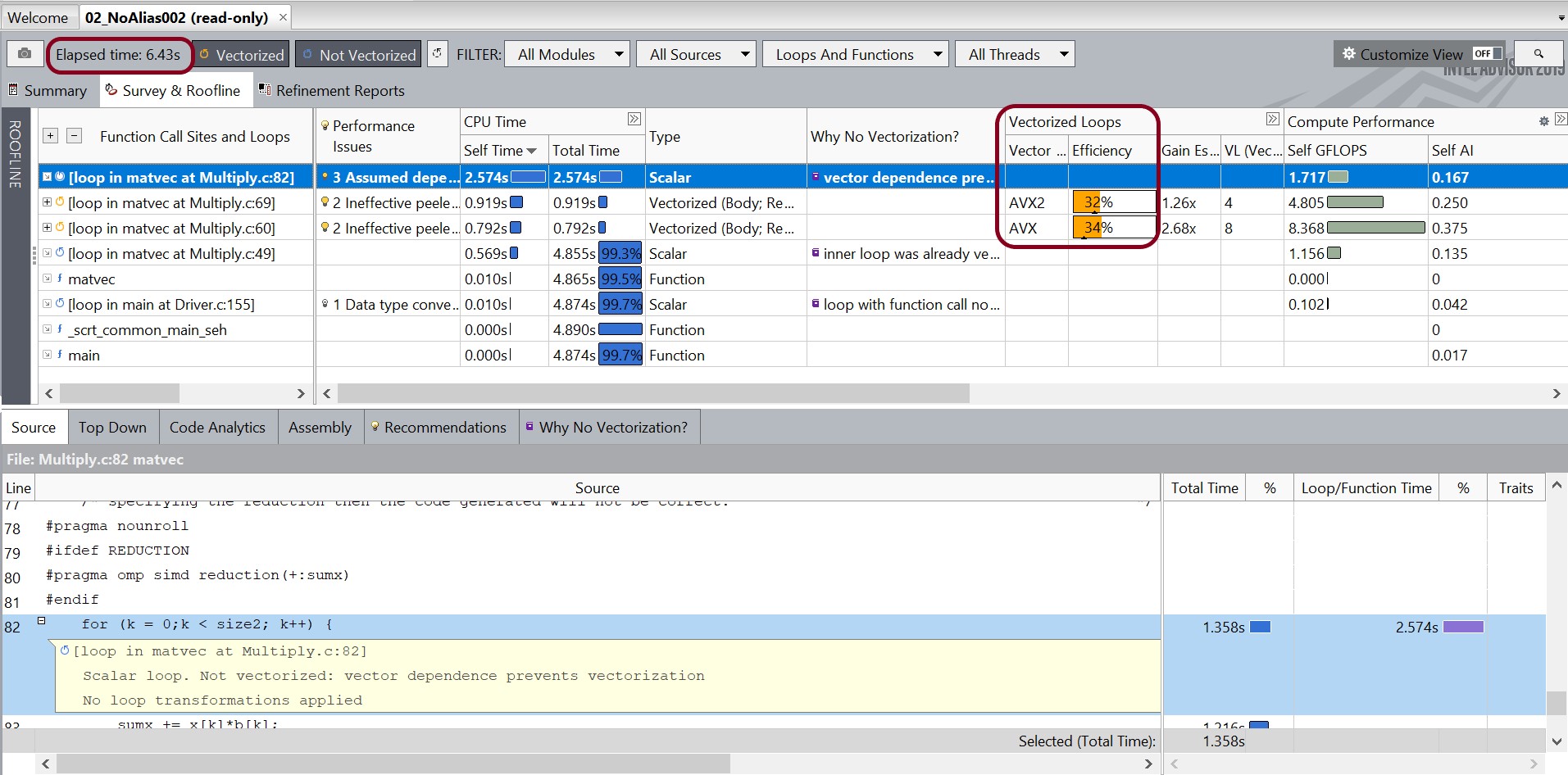
- Snapshot_Baseline スナップショットを開きます。
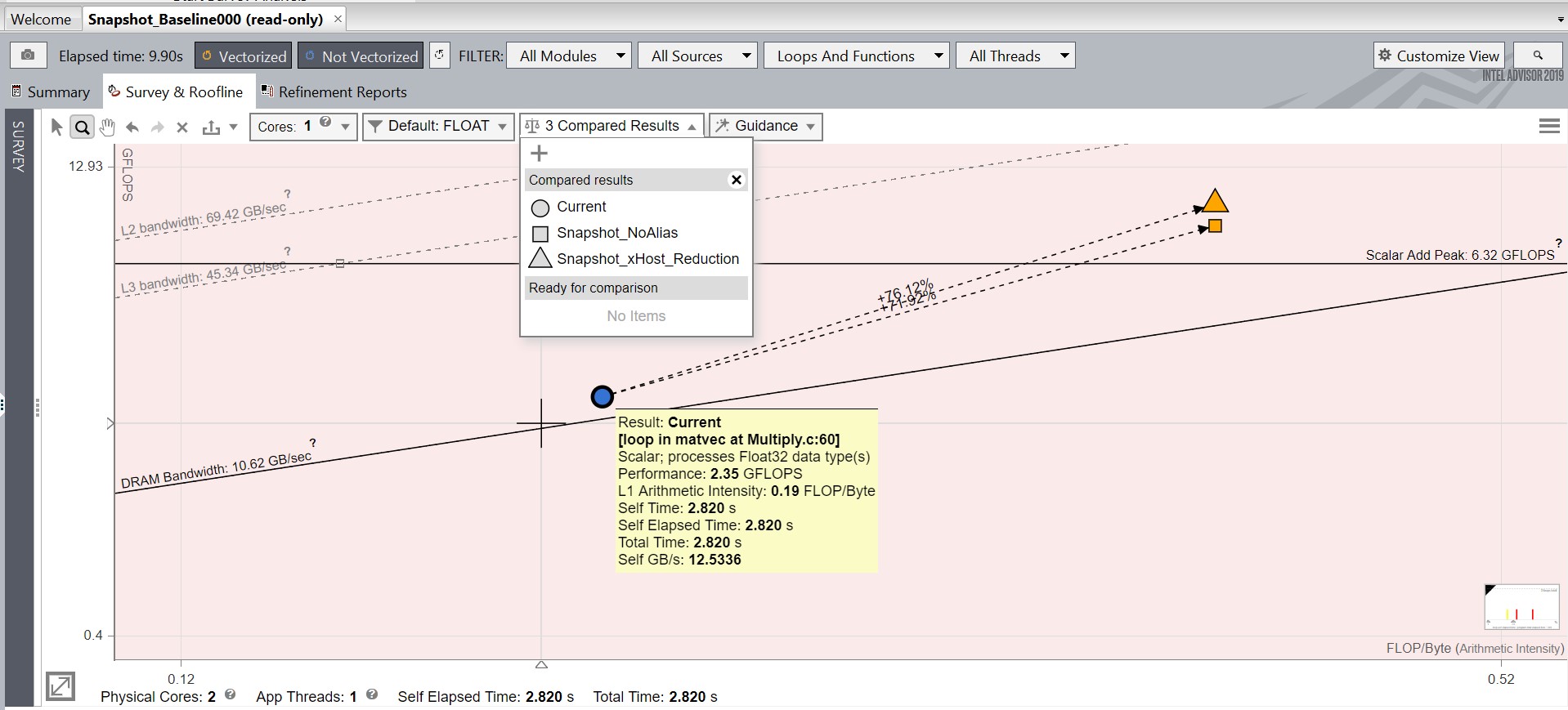
- Snapshot_Baseline でルーフライン・グラフに移動し、[比較] ドロップダウン・リスト
 をクリックして、[+ 比較結果を読み込み] アイコンをクリックします。インテル® Advisor は、Snapshot_Baseline と同じディレクトリーにあるすべてのスナップショットを [比較の準備完了] リストに表示します。これらのスナップショットをルーフラインの比較に使用できます。[+ 比較結果を読み込み] オプションを使用して Snapshot_NoAlias を選択します。
をクリックして、[+ 比較結果を読み込み] アイコンをクリックします。インテル® Advisor は、Snapshot_Baseline と同じディレクトリーにあるすべてのスナップショットを [比較の準備完了] リストに表示します。これらのスナップショットをルーフラインの比較に使用できます。[+ 比較結果を読み込み] オプションを使用して Snapshot_NoAlias を選択します。
注
[x 比較結果をクリア] アイコンを使用して比較する結果を削除できます。
![[+ 比較結果を読み込み] アイコンを使用して新しいルーフライン結果を追加し、(現在の) Snapshot_Baseline 結果と比較](https://www.isus.jp/wp-content/uploads/30493242-E033-46EE-9A09-24112CBA5433.jpg)
以降では、最適化されたスナップショットと Snapshot_Baseline を比較し、現在の結果は Snapshot_Baseline を指します。スナップショットごとにループと関数を表示するため、ドットは異なる形 (三角や四角形など) となります。例えば次の例では、円は現在の結果を示し、四角形は Snapshot_NoAlias の結果を示しています。
結果を見やすくするため、インテル® Advisor の [選択をフィルターイン] 機能を使用します。ルーフライン・グラフの注目するループや関数を右クリックして、[選択をフィルターイン] を選択します。これにより、ルーフライン・グラフに選択したループのみが表示されます。この機能は、数百のループや関数を持つアプリケーションで、注目するループをフィルター処理する際に有効です。ここでは、matvec の Multiply.c:60 にあるループにフィルターインしています。フィルターを削除するには、ルーフライン・グラフを右クリックして [フィルターをクリア] を選択します。
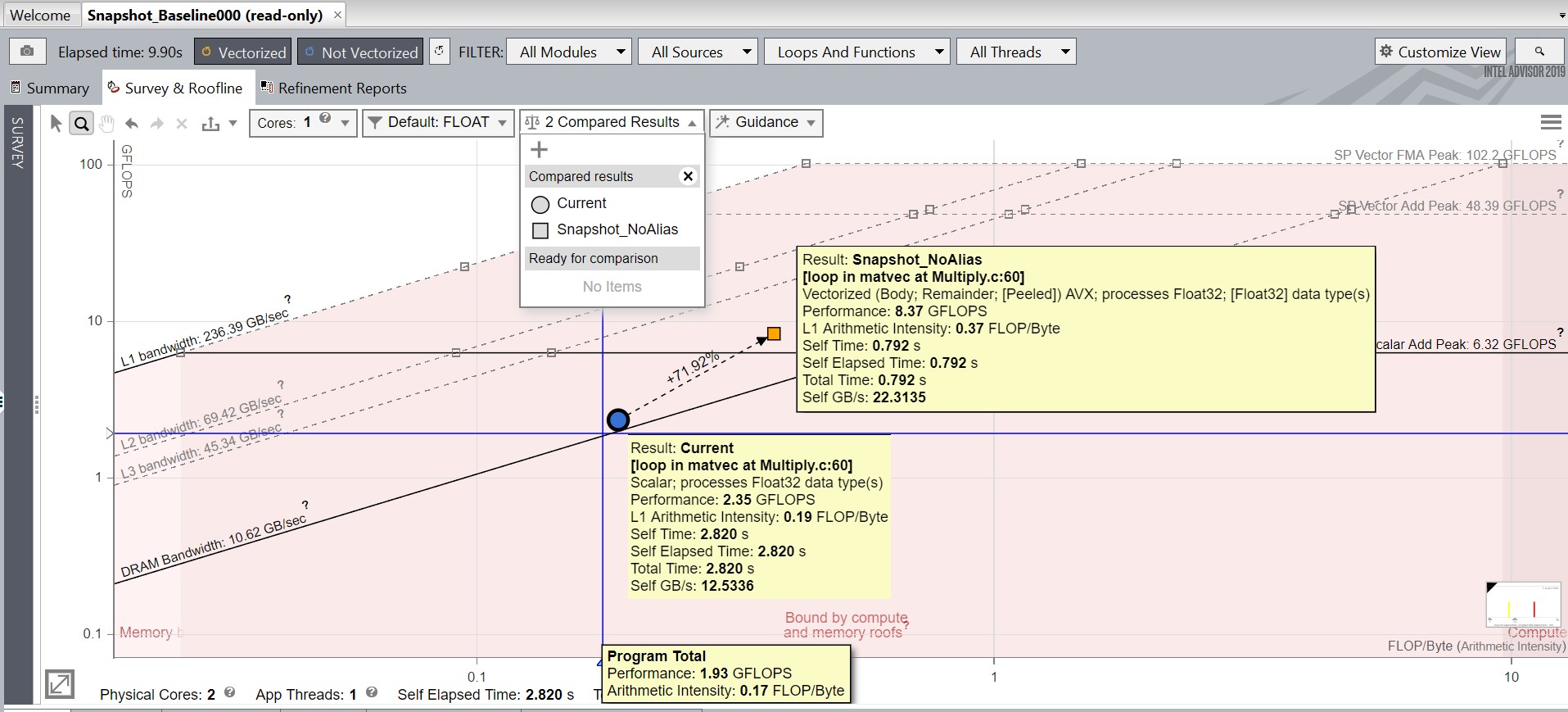
- ルーフライン・グラフで matvec の Multiply.c:60 にあるループは、Snapshot_Baseline ではスカラーで、Snapshot_NoAlias ではベクトル化されているため、色が変わっていることに注目してください。
- ルーフラインの比較機能は、両方のスナップショットにある同一のループを自動的に識別します。関連するループを破線でつなぎ、ループ間のパフォーマンスの差 (FLOPS、INTOPS、OPS) と合計時間を表示します。

- 結果から同じループを検出するため、インテル® Advisor はループのタイプ、入れ子レベル、ソースコードのファイル名と行、関数名など、ループの特性を比較します。類似するまたは同等の特性が特定のしきい値に達すると、2 つのループは同一であると見なされ破線で接続されます。
- しかし、この方法にはいくつかの制限があります。ソースコードが最適化、並列化、または元のコードから 4 行以上移動された場合、同一のループと見なされないことがあります。
- インテル® Advisor は、一致するソースコードの変更と誤検知のバランスを維持しようとします。
ΔFLOPS (データ型に応じて INTOPS または OPS となります) は、比較するループと現在のループのパフォーマンスの差を意味します。上の図では、パフォーマンスが 2.35 ユニットから 8.37 ユニットに増加したため、比較したループの計算パフォーマンスは 6.02 ユニット* 向上したことを示しています。パーセントでは、次のように示すことができます。
- 71.92% = 6.02 ユニット / 8.37 ユニット * 100%
- 8.37 GFLOPS – 比較したループのパフォーマンス値
- 2.35 GFLOPS – 現在のループのパフォーマンス値
* 単位は、データ型に応じて GFLOPS/GINTOPS/ギガ混在 OPS になります。上記の結果の単位は GFLOPS です。
Δt は、比較したループと現在のループの合計時間の差を意味します。上記の例では、比較したループの合計時間が 2.028 秒 (2.820 秒から 0.792 秒に) 減少していることが分かります。
この例では差が負 (-2.028) であることに注目してください。これは、どちらの Δ (FLOPS、時間) メトリックも比較するループの値から現在のループの値を減算するためです。そのため、選択したループに応じて、パフォーマンスの向上と低下の両方を確認できます。
パーセントで表すと、合計時間の差は次のようになります。
- -71.91% = -2.028 秒 / 2.820 秒 * 100%
- 0.792 秒 – 比較したループの合計時間値
- 2.820 秒 – 現在のループの合計時間値
破線は、2 つのループ間の最大パフォーマンス値のパーセンテージとしてパフォーマンスの差 (この例では ΔFLOPS) を表示します。
- サーベイレポートとルーフラインの比較グラフを並べて表示して、サーベイレポートのそれぞれのループをクリックすると、ルーフライン・グラフの対応するループが強調表示され、同一のループを結ぶ破線も強調されます。上記の図では、これを分かりやすくするため、選択範囲のフィルター処理をクリアしています。
- Snapshot_NoAlias のルーフライン・スナップショットとサーベイレポートから、ループにはまだ改善の余地があることが分かります。
さらなる最適化
QxHost オプションは、コンパイルを行うホスト・プロセッサーで利用可能な最上位の命令セットを使用したコードを生成するようにコンパイラーに指示します。/QxHost オプションを追加してソリューションを再ビルドすると、利用するプロセッサー・アーキテクチャーに応じてパフォーマンスをさらに高めることができます。
コンパイラーは、データの依存関係を想定する際に保守的になり、常に最悪のシナリオを採用します。リファインメント・レポートを使用して、ループ内の実際の依存関係を確認できます。以前の結果では、コンパイラーが依存関係を想定したため、matvec の Multiply.c:82 にあるループはベクトル化されませんでした。実際の依存関係が検出されると、解析は依存関係を解決するのに役立つ詳細情報を提供します。
依存関係解析の実行
- サーベイレポートのドロップ
 カラムで、matvec の Multiply.c:82 にあるループのチェックボックスをオンにします。
カラムで、matvec の Multiply.c:82 にあるループのチェックボックスをオンにします。 - [ベクトル化ワークフロー] ペインで、[依存関係の確認] にある [Collect] ボタン
![インテル® Advisor の [Collect] ボタン](https://www.isus.jp/wp-content/uploads/D62E323D-960C-48FB-A4C4-3CD92CB746AA.gif) をクリックして、依存関係レポートを作成します。
をクリックして、依存関係レポートを作成します。 - 通常、依存関係解析のレポート生成には時間がかかります。この例では、解析時間が長い場合、サイトカバレッジの進行状況バーで 1/1 サイトが表示されたら、[依存関係の確認] の下にある [停止] ボタン
 をクリックして解析を停止できます。これにより、それまでに収集された結果を表示できます。ただし、この例以外では、すべての依存関係を検出できないリスクがあることに注意してください (選択したサイクルに複数の呼び出しがある場合など)。
をクリックして解析を停止できます。これにより、それまでに収集された結果を表示できます。ただし、この例以外では、すべての依存関係を検出できないリスクがあることに注意してください (選択したサイクルに複数の呼び出しがある場合など)。
依存関係を評価
[リファインメント・レポート] ウィンドウの上にあるペインで、インテル® Advisor が matvec の Multiply.c:82 にあるループで、RAW および WAW 依存関係を報告していることに注目してください。下部にある [依存関係レポート] タブには、依存関係があるソースが表示され、ここでは sumx 変数の加算であることが分かります。
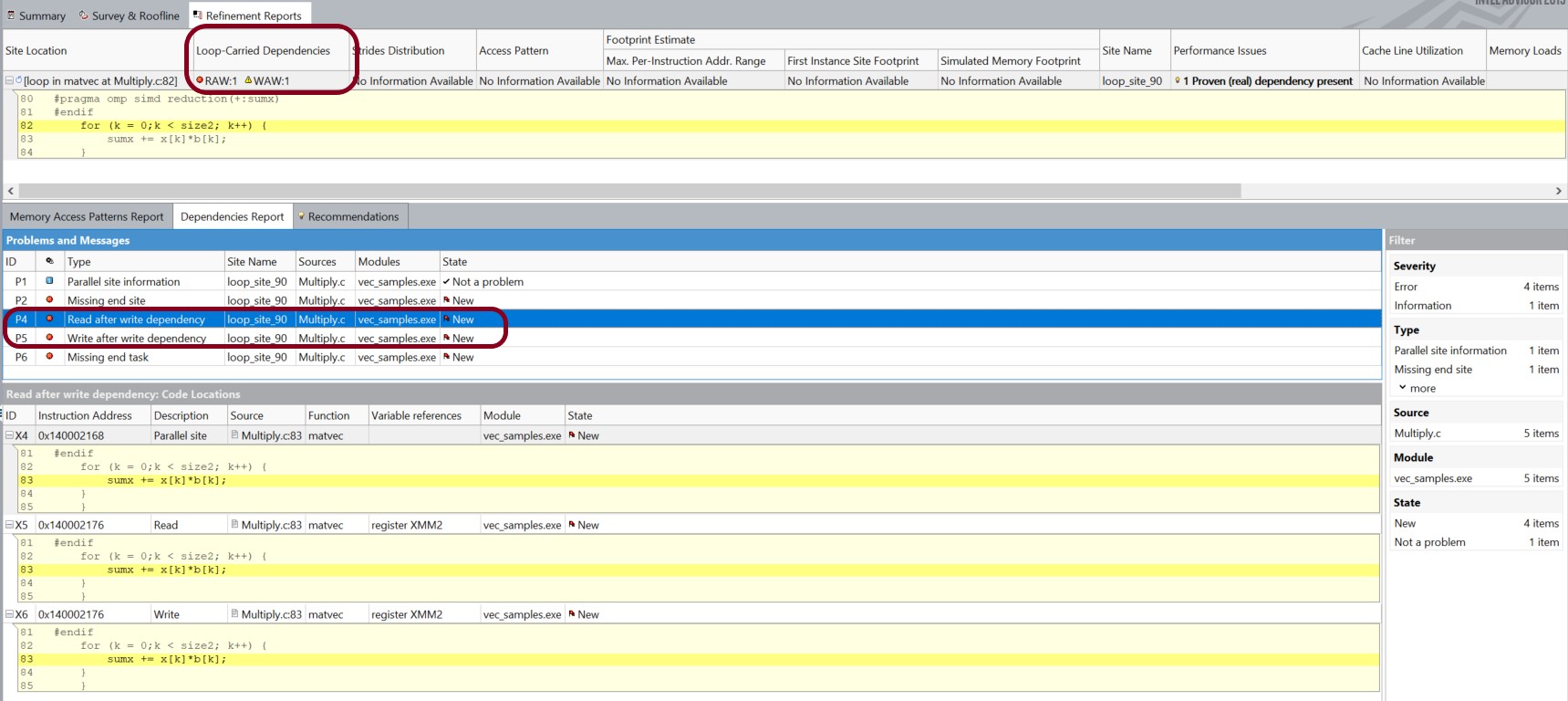
matvec の Multiply.c:82 にあるループは、sumx の加算によるリダクションの依存関係があるためベクトル化できませんでした。依存関係解析を実行して、実際に依存関係があることを確認できました。OpenMP* SIMD ディレクティブの redunction 節は、SIMD レーンごとに個別の合計を計算し、最後にそれらを結合します (redunction 節なしで OpenMP* SIMD ディレクティブを使用すると、誤ったコードが生成されます)。
- /DREDUCTION オプションを使用してソリューションをリビルドします。ルーフライン解析を再実行して、結果を Snapshot_xHost_Reduction として保存します。
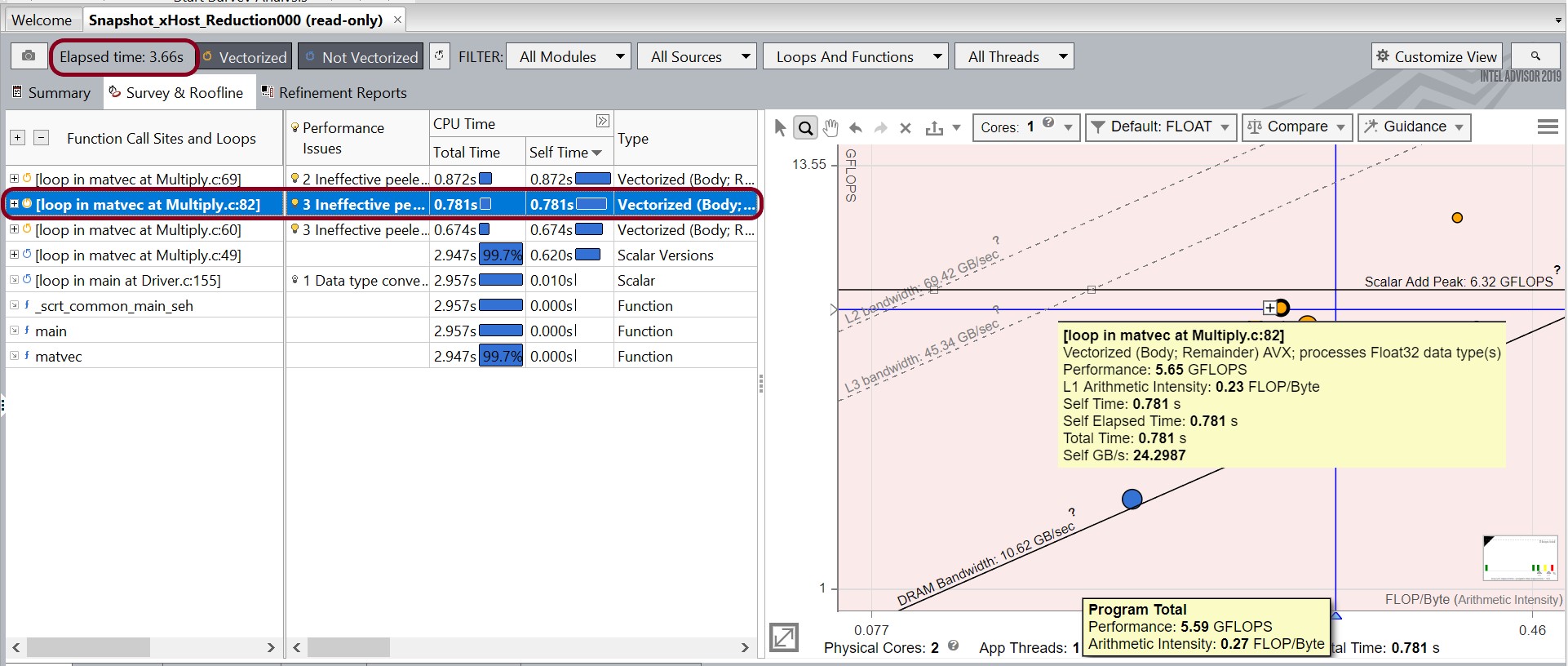
- matvec の Multiply.c:82 にあるループがベクトル化されたことが分かります。[経過時間] も改善されています。
- Snapshot_Baseline 結果を開いて、ルーフライン比較機能を使用し、比較対象に Snapshot_NoAlias と Snapshot_xHost_Reduction を追加します。
以下の図は結果を示します。パフォーマンスが全体的に改善されています。三角形と四角形のシンボル ( と
と  ) はそれぞれ、Snapshot_xHost_Reduction と Snapshot_NoAlias のループを示します。[選択をフィルターイン] 機能を使用して、Snapshot_Baseline の最大のホットスポットである matvec の Multiply.c:60 にあるループに注目します。最後に行った最適化により、ループはさらにルーフラインの上方向に移動しました。これは、ループの実行時間が改善されたことを示し、コード全体の経過時間にも反映されています。
) はそれぞれ、Snapshot_xHost_Reduction と Snapshot_NoAlias のループを示します。[選択をフィルターイン] 機能を使用して、Snapshot_Baseline の最大のホットスポットである matvec の Multiply.c:60 にあるループに注目します。最後に行った最適化により、ループはさらにルーフラインの上方向に移動しました。これは、ループの実行時間が改善されたことを示し、コード全体の経過時間にも反映されています。
要約
- インテル® Advisor のルーフライン・グラフを使用して、ハードウェアの制限 (メモリー帯域幅と計算ピーク) に関連するアプリケーションのパフォーマンスを視覚的に表現できます。
- インテル® Advisor 2019 では、ルーフラインの比較と呼ばれる新しい機能がサポートされています。これは、最適化前後のループと関数のパフォーマンスの差を確認するために使用できます。この機能により、開発者は最適化の作業を定量化して視覚化できるため、最適化の敷居がかなり低くなりました。
関連情報
- インテル® Advisor のルーフライン
- インテル® Advisor のルーフライン機能の使い方
https://software.intel.com/en-us/articles/getting-started-with-intel-advisor-roofline-feature - インテル® Advisor の整数ルーフライン・モデル
- インテル® Advisor 2017 のルーフライン解析
https://software.intel.com/en-us/videos/roofline-analysis-in-intel-advisor-2017
(英語ビデオ)
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
