
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Advisor Cookbook」の「Identify Bottlenecks Iteratively: Cache-Aware Roofline」(https://software.intel.com/en-us/advisor-cookbook-identify-bottlenecks-iteratively-cache-aware-roofline) の章の日本語参考訳です。
アプリケーションのパフォーマンス改善は、多くの場合、複数の手順からなる作業です。インテル® Advisor のキャッシュを考慮したルーフライン機能とサポートする解析タイプを使用して、段階的で体系的な最適化を実行できます。ボトルネックを特定して対処し、解析を再実行して、作業ごとにコードがどのように改善されるか確認します。ここでは、[推奨事項] タブ、[コード解析] タブ、[リファインメント] レポート、およびそのほかの機能を利用して、コードに影響を与える可能性がある、実際の問題に対処するワークフローの例を示します。
シナリオ
インテル® Advisor ルーフライン機能の最初のバージョンは、浮動小数点演算のみをサポートしていましたが、インテル® Advisor 2019 では整数演算のサポートが追加され、マシンラーニングのような整数処理が多いアプリケーションに有用性を拡大しました。
ルーフライン機能によりアプリケーションを最適化する手順は、浮動小数点と整数タイプの両者で操作は基本的に同じですが、このレシピのアルゴリズムは整数データを使用しています。これは、標準的な行列乗算を行うアプリケーションであり、いくつかのパフォーマンス・ボトルネックの影響を受けます。
for (i = 0; i < msize; i++) {
for (j = 0; j < msize; j++) {
for (k = 0; k < msize; k++) {
c[i][j] += a[i][k] * b[k][j];
}
}
}
次の図に示すように、ボトルネックを繰り返し処理するプロセスでは、インテル® Advisor GUI 全体で複数の解析タイプとレポートを使用します。
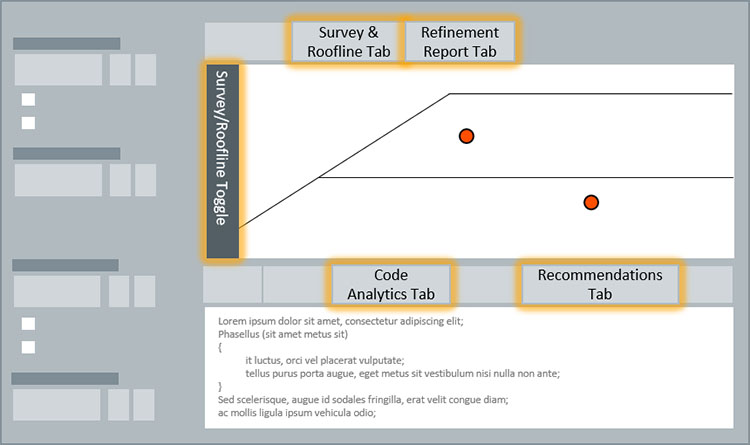
コンポーネント
ここでは、このレシピで示される特定の結果を得るために使用されたハードウェアとソフトウェアをリストします。
- パフォーマンス解析ツール: インテル® Advisor 2019 Update 3
最新バージョンは、https://www.isus.jp/intel-advisor-xe/ からダウンロードできます。 - アプリケーション: シナリオで説明されている行列乗算アプリケーション。
ダウンロードは提供されません。 - コンパイラー: インテル® C++ コンパイラー 19.0.3 (2019 Update 3)
- オペレーティング・システム: Microsoft* Windows* 10 Enterprise
- CPU: インテル® Core™ i5-6300U プロセッサー
ベースラインの結果を収集
- コンパイルしたアプリケーションでスタンドアロン・ルーフライン解析を実行して、結果を GUI で表示します。
- 必要に応じてルーフライン・グラフの設定を変更します。この場合、データ型を INT に設定し、コア数を 1 にします (このアプリケーションの 2 番目のスレッドは、起動とセットアップ用のスレッドです)。
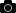 (結果のスナップショットを作成) ボタンを使用して、結果を保存します。
(結果のスナップショットを作成) ボタンを使用して、結果を保存します。
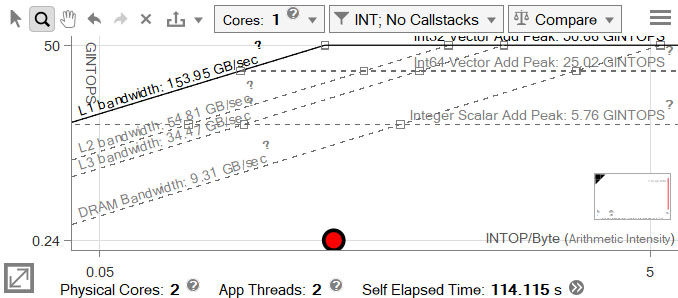
大きな赤いドットは、実行におよそ 166 秒を費やす行列乗算ループです。
ループをベクトル化
グラフ上のループの位置は、スカラー加算ピークまたは DRAM 帯域幅のルーフがボトルネックである可能性を示しています。
- 最初に対処すべき問題に関するヒントは、[推奨事項] タブで確認できます。

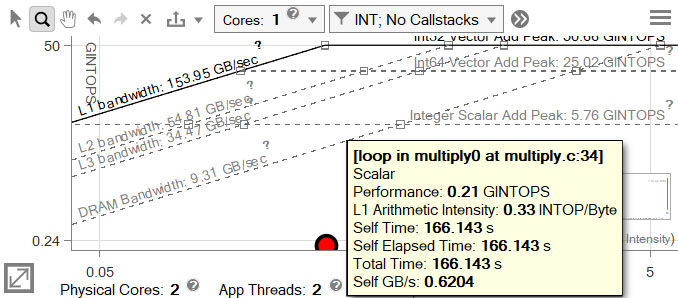
- 安全にベクトル化できることを確認するため、ループの依存関係解析を実行します。
結果は、[リファインメント] レポートに表示されます。依存関係が報告されていますが、[推奨事項] タブには解決方法が示されています。
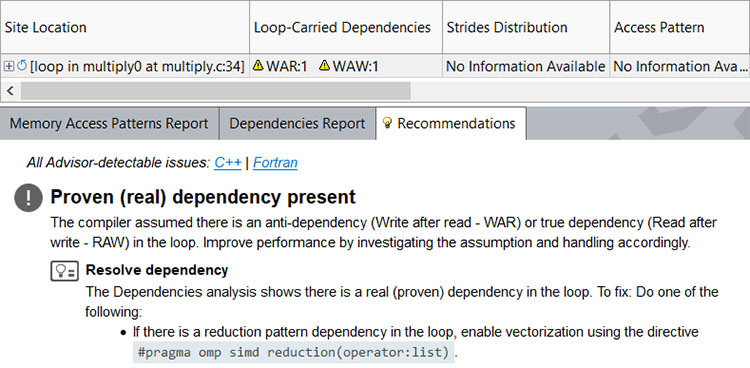
- インテル® Advisor が推奨するように、コードにリダクションを明示する #pragma omp simd ディレクティブを追加します。
for (i = 0; i < msize; i++) { for (j = 0; j < msize; j++) { #pragma omp simd reduction(+:c[i][j]) for (k = 0; k < msize; k++) { c[i][j] += a[i][k] * b[k][j]; } } } - 再コンパイルしてルーフラインを実行し、結果を確認します。
変更しましたが結果はほとんど変わりません。
行列変換
- 改善不足に関する手がかりは、[サーベイ] レポートで確認できます。
[ベクトル化されたループ] の [効率] バーが灰色で表示され、ループはコンパイラーが推測したスカラー・パフォーマンスよりも低速であることを示しています。[パフォーマンス問題] に、非効率なメモリー・アクセス・パターンが報告されています。
![サーベイレポートの [効率] バーと [パフォーマンス問題] カラム](https://www.isus.jp/wp-content/uploads/ACF882FC-30C6-4E04-BCF4-C29AF66C9A78.jpg)
- [推奨事項] タブをクリックして、パフォーマンス問題の詳細を確認します。

- ループのメモリー・アクセス・パターン解析を実行します。
[リファインメント] レポートで、行列の 1 つが列アクセスであることが分かります。これにより、32768 回のストライドが連続していません。
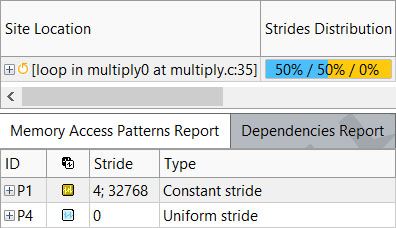
- 行列 b を列アクセスではなく行アクセスに変換したバージョンを作成します。
for (i = 0; i < msize; i++) { for (j = 0; j < msize; j++) { t[i][j] = b[j][i]; } } for (i = 0; i < msize; i++) { for (j = 0; j < msize; j++) { #pragma omp simd reduction(+:c[i][j]) for (k = 0; k < msize; k++) { c[i][j] += a[i][k] * t[j][k]; } } } - 再コンパイルしてルーフラインを再度実行します。
パフォーマンスは大幅に改善されましたが、ベクトル化したにもかかわらず、ループはスカラー加算ピークの下にあります。
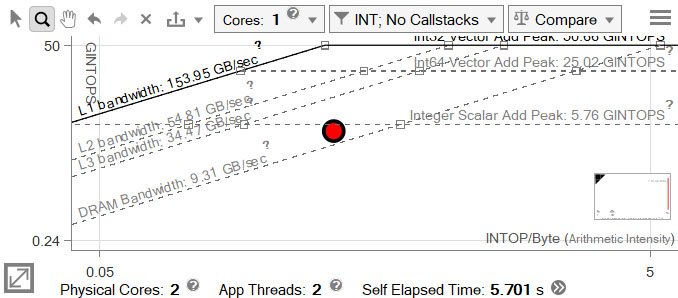
インテル® AVX2 命令セットを使用
- [サーベイ] レポートの [ベクトル化されたループ] カラムをチェックします。
効率が高くなりましたが、ループはインテル® SSE2 命令のみで構成されています。これは、コンパイラーのデフォルト命令セットです。インテル® Advisor は、上位の命令セットが利用可能であることを示しています。

- インテル® AVX2 命令セットを使用して再コンパイルし、ルーフラインを再度実行します。
ループは 1 秒以上高速に実行されました。

L2 キャッシュのブロッキング
スカラー加算ピークには完全に達しています。次のルーフは、L3 と L2 帯域幅のルーフです。
- 入れ子になった 3 つのループすべてでメモリー・アクセス・パターン解析を実行して、メモリー使用量を評価します。
外側 2 つのループのメモリー使用量は、このマシンに搭載されている CPU のキャッシュよりもはるかに大きくなります。

- 計算を L2 キャッシュのサイズに合わせてブロック化し、キャッシュにロードされたデータに対するワークの量を最大化します。
for (i = 0; i < msize; i++) { for (j = 0; j < msize; j++) { t[i][j] = b[j][i]; } } for (ichunk = 0; ichunk < msize; ichunk += CHUNK_SIZE) { for (jchunk = 0; jchunk < msize; jchunk += CHUNK_SIZE) { for (i = 0; i < CHUNK_SIZE; i++) { ci = ichunk + i; for (j = 0; j < CHUNK_SIZE; j++) { cj = jchunk + j; #pragma omp simd reduction(+:c[ci][cj]) for (k = 0; k < msize; k++) { c[ci][cj] += a[ci][k] * t[cj][k]; } } } } } - 再コンパイルしてルーフラインを再度実行します。
ドットの位置はそれほど変わりませんが、経過時間はほぼ半分に短縮されています。
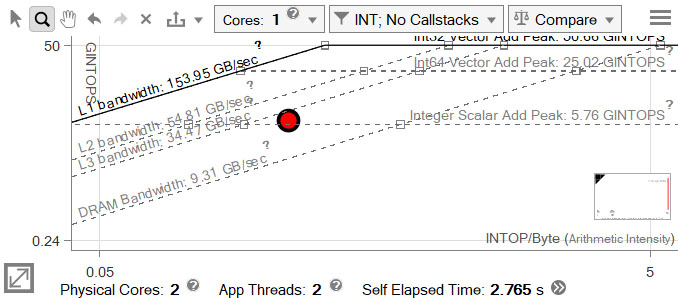
データをアライメント
- 推奨事項はありませんが、[コード解析] タブを確認してみます。
[ベクトル化できない理由] には、データがアライメントされていないことが示されています。これにより、命令の混在に表示されるように、過度なメモリーアクセスが発生する可能性があります。
![[コード解析] タブの [ベクトル化できない理由]](https://www.isus.jp/wp-content/uploads/84C124DA-4067-48E2-8813-5A52C0B87209.jpg)
- _mm_malloc() などの適切にアライメントを要求するメモリー割り当てを使用し、データを割り当てます。#pragma vector aligned をループに追加し、/Oa または -fno-alias オプションを使用して再コンパイルします。
for (i = 0; i < msize; i++) { for (j = 0; j < msize; j++) { t[i][j] = b[j][i]; } } for (ichunk = 0; ichunk < msize; ichunk += CHUNK_SIZE) { for (jchunk = 0; jchunk < msize; jchunk += CHUNK_SIZE) { for (i = 0; i < CHUNK_SIZE; i++) { ci = ichunk + i; for (j = 0; j < CHUNK_SIZE; j++) { cj = jchunk + j; #pragma vector aligned #pragma omp simd reduction(+:c[ci][cj]) for (k = 0; k < msize; k++) { c[ci][cj] += a[ci][k] * t[cj][k]; } } } } } - 再コンパイルしてルーフラインを実行し、[比較] 機能を使用してベースラインの結果をロードします。
ループの時間は、元の 166 秒からおよそ 1 秒に短縮されました。
![ルーフラインの [比較] 機能を使用してループの時間を比較](https://www.isus.jp/wp-content/uploads/8E9584BF-BA9D-445B-9264-42596A6790B4.jpg)
関連情報
- インテル® Advisor のルーフライン機能の使い方
https://software.intel.com/en-us/articles/getting-started-with-intel-advisor-roofline-feature - インテル® Advisor の整数ルーフライン・モデル
- インテル® Advisor のルーフライン
- インテル® Advisor 2017 のルーフライン解析
https://software.intel.com/en-us/videos/roofline-analysis-in-intel-advisor-2017
(英語ビデオ)
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
