

この記事は、https://www.oneapi.io/spec/ で 2023年9月14日に公開された『oneAPI 1.3 Provisional Specification Rev. 1』 (HTML、PDF) をベースにしています。原文は2000 ページ近くあり、翻訳の時間とリソースも限られるため、全文翻訳ではなく、記事形式で区切った仕様とその解説を提供することにしました。
この回では、『oneAPI 1.3 Provisional Specification Rev. 1』の「oneDNN」の「Concat」と「Convolution and Deconvolution」の節を取り上げています。
結合 (Concat)
データを任意の次元で結合するプリミティブです。
結合プリミティブは、concat_dimension (ここでは C として示されます) 上で N テンソルを結合します。次にように定義されます。
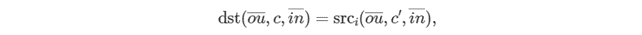
説明:
- c = C1 + … + Ci−1 + c′
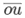 は最外のインデックス (結合軸の左側) です。
は最外のインデックス (結合軸の左側) です。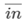 は最内のインデックス (結合軸の右) です。
は最内のインデックス (結合軸の右) です。
変数名は標準の規則 (英語) に従います。
順方向と逆方向
結合プリミティブには、順方向と逆方向の伝播の概念がありません。結合操作の逆伝播は、単純な単位元操作です。
実行引数
実行時に入力と出力は、次の表で示す実行引数インデックスにマップする必要があります。
| プリミティブの入力/出力 | 実行引数インデックス |
|---|---|
src |
DNNL_ARG_MULTIPLE_SRC |
dst |
DNNL_ARG_DST |
操作の詳細
dstメモリー形式は、ユーザーが指定することも、プリミティブによって取得することもできます。推奨される方法は、プリミティブが最も適切な形式を選択できるようにすることです。結合プリミティブでは、
concat_dimensionを除いて、すべてのソースとデスティネーション・テンソルが同一形状でなければなりません。concat_dimensionのデスティネーションは、ソースのconcat_dimension次元の合計と等しくなければなりません (つまり C=∑iCi)。暗黙のブロードキャストはサポートされません。
サポートされるデータタイプ
結合プリミティブは、ソーステンソルとデスティネーション・テンソルの任意のデータタイプをサポートします。ただし、すべてのソーステンソルは同一のデータタイプである必要があります (デスティネーション・テンソルのデータタイプとは必ずしも一致する必要はありません)。
データ表現
結合プリミティブは、関連する論理次元に対し特別な意味は持ちません。
post-ops と属性
結合プリミティブは post-ops や属性をサポートしません。
API
API については、こちら (英語) をご覧ください。
畳み込みと逆畳み込み
畳み込みおよび逆畳み込みプリミティブは、バイアス付きの 1D、2D、または 3D 空間データに対するバッチ畳み込みまたは逆畳み込み操作の順方向、逆方向、もしくは重み更新を計算します。
操作は次の式で定義されます。高次元と低次元のケースでは、一般化が容易な 2D 空間データの式のみを示します。変数名は標準の規則 (英語) に従います。
順方向 (前方)
src、weights、および dst をそれぞれ N×IC×IH×IW、OC×IC×KH×KW、N×OC×OH×OW テンソルとし、bias を OC 要素を持つ 1D テンソルとします。
さらに、残りの畳み込みパラメーターを次のようにします。
| パラメーター | 深さ | 高さ | 幅 | コメント |
|---|---|---|---|---|
| パディング: front、top、left | PDL | PHL | PWL | API padding_l は、対応するパディングのベクトルを示します (_l は left を表します) |
| パディング: back、bottom、right | PDR | PHR | PWR | API padding_r は、対応するパディングのベクトルを示します (_r は right を表します) |
| ストライド | SD | SH | SW | ストライドのない畳み込みは、ストライド・パラメーターを 1 に設定して定義できます。 |
| 膨張 | DD | DH | DW | 非膨張畳み込みは、膨張パラメーターを 0 に設定して定義できます。 |
次の式は、oneDNN における畳み込みの計算方法を示します。説明を簡単にするためいくつかのタイプに分類していますが、実際には畳み込みタイプを組み合わせます。
式をさらに単純化するため、ih<0、ih≥IH、iw<0、または iw≥IW の場合、src(n,ic,ih,iw)=0 と仮定します。
通常の畳み込み
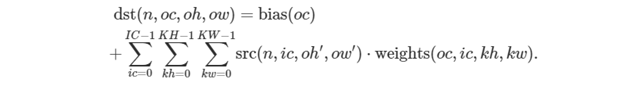
ここでは以下が成り立ちます。
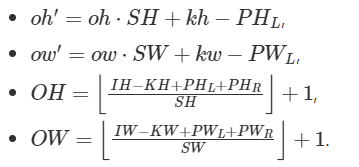
グループとの畳み込み
oneDNN は、重みテンソルを表すメモリー・オブジェクトに別のグループの次元を追加し、グループと 2D 畳み込みの場合、重みを G×OCG×ICG×KH×KW 5D テンソルとします。
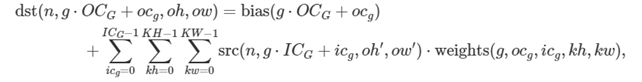
ここでは以下が成り立ちます。
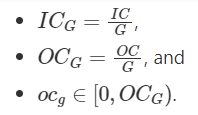
OCG = ICG = 1 の場合、深さ方向の畳み込みとも呼ばれます。
膨張を伴う畳み込み
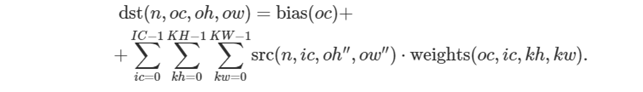
ここでは以下が成り立ちます。
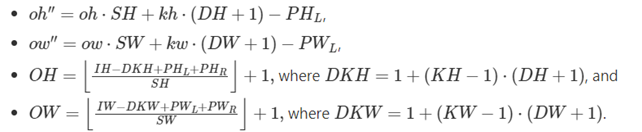
逆畳み込み (転置畳み込み)
逆畳み込み (フラクショナル・ストライド畳み込み、または転置畳み込みとも呼ばれます) は、畳み込みの前方パスと後方パスを入れ替えることで定義できます。言い変えると、重みが畳み込みを定義していることに注意してください。直接畳み込みであるか転置畳み込みであるかは、順方向と逆方向パスの計算方法によって決定されます。
順方向トレーニングと順方向推論の違い
forward_training と forward_inference 伝播の種類に違いはありません。
逆方向 (後方)
逆方向伝播は、diff_dst と weights に基づいて diff_src を計算します。
重みの更新では、diff_dst と src に基づいて diff_weights と diff_bias が計算されます。
注: 最適化されたメモリー形式の src と weights は、順方向伝播、逆方向伝播、および重みの更新で異なることがあります。
実行引数
実行時に入力と出力は、次の表で示す実行引数インデックスにマップする必要があります。
| プリミティブの入力/出力 | 実行引数インデックス |
|---|---|
src |
DNNL_ARG_SRC |
weights |
DNNL_ARG_WEIGHTS |
bias |
DNNL_ARG_BIAS |
dst |
DNNL_ARG_DST |
diff_src |
DNNL_ARG_DIFF_SRC |
diff_weights |
DNNL_ARG_DIFF_WEIGHTS |
diff_bias |
DNNL_ARG_DIFF_BIAS |
diff_dst |
DNNL_ARG_DIFF_DST |
操作の詳細
なし
サポートされるデータタイプ
畳み込みプリミティブは、ソース、デスティネーション、および重みメモリー・オブジェクトのデータタイプで次の組み合わせをサポートします。
注: この節では、可読性のためデータタイプの名称を省略しています。例えば、dnnl::memory::data_type::f32 は f32 に省略されます。
| 伝播 | ソース | 重み | デスティネーション | バイアス |
|---|---|---|---|---|
| 順方向/逆方向 | f32 |
f32 |
f32 |
f32 |
| 順方向 | f16 |
f16 |
f16 |
f16 |
| 順方向 | u8、s8 |
s8 |
u8、s8、s32、f32 |
u8、s8、s32、f32 |
| 順方向 | bf16 |
bf16 |
f32、bf16 |
f32、bf16 |
| 逆方向 | f32、bf16 |
bf16 |
bf16 |
|
| 重み更新 | bf16 |
f32、bf16 |
bf16 |
f32、bf16 |
データ表現
ほかの CNN プリミティブと同様に、畳み込みプリミティブは次のテンソルを想定します。
| 空間 | ソース/デスティネーション | 重み |
|---|---|---|
| 1D | N×C×W | [G×] OC×IC×KW |
| 2D | N×C×H×W | [G×] OC×IC×KH×KW |
| 3D | N×C×D×H×W | [G×] OC×IC×KD×KH×KW |
データのメモリー形式とメモリー・オブジェクトの重みは、畳み込みプリミティブのパフォーマンスに重要です。oneDNN プログラミング・モデルは、畳み込みはプレースホルダー・メモリー形式タグ any をサポートするプリミティブの 1 つであり、プリミティブのパラメーターに基づいてデータとメモリー・オブジェクト形式を定義できます。any を使用する場合、最初に畳み込みプリミティブ記述子を作成してから、実際のデータと重みメモリー・オブジェクト形式を照会する必要があります。
畳み込みプリミティブは、明示的に指定されたメモリー形式によって作成できますが、パフォーマンスは最適ではない可能性があります。
次の表は、畳み込みプリミティブが最適化されるプレーンメモリー形式の組み合わせを示します。
| 空間 | 畳み込みタイプ | データ/重み論理テンソル | メモリー形式向けに最適化された実装 |
| 1D、2D、3D | any |
最適化済み | |
| 1D | f32、bf16 | NCW/OIW、GOIW |
ncw (abc)/oiw (abc)、goiw (abcd) |
| 1D | f32、bf16 | NCW/OIW、GOIW |
nwc (acb)/wio (cba)、wigo (dcab) |
| 1D | int8 | NCW/OIW |
nwc (acb)/wio (cba) |
| 2D | f32、bf16 | NCHW/OIHW、GOIHW |
nchw (abcd)/oihw (abcd)、goihw (abcde) |
| 2D | f32、bf16 | NCHW/OIHW、GOIHW |
nhwc (acdb)/hwio (cdba)、hwigo (decab) |
| 2D | int8 | NCHW/OIHW、GOIHW |
nhwc (acdb)/hwio (cdba)、hwigo (decab) |
| 3D | f32、bf16 | NCDHW/OIDHW、GOIDHW |
ncdhw (abcde)/oidhw (abcde)、goidhw (abcdef) |
| 3D | f32、bf16 | NCDHW/OIDHW、GOIDHW |
ndhwc (acdeb)/dhwio (cdeba)、dhwigo (defcab) |
| 3D | int8 | NCDHW/OIDHW |
ndhwc (acdeb)/dhwio (cdeba) |
post-ops と属性
post-ops と属性を使用すると、プリミティブの結果に量子化パラメーターを適用し、プリミティブの後に特定の操作を結合することで畳み込みプリミティブの動作を変更できます。次の属性と post-op がサポートされます。
| タイプ | 操作 | 説明 | 制限事項 |
|---|---|---|---|
| 属性 | scales |
対応するテンソルのスケールを設定します。 | Int8 計算のみ |
| 属性 | zero points |
対応するテンソルのゼロポイントを設定します。 | Int8 計算のみ |
| post-op | eltwise |
結果に要素ごとの操作を適用します。 | |
| post-op | binary |
結果にバイナリー操作を適用します。 | |
| post-op | sum |
演算結果を上書きせずに、デスティネーション・テンソルに加算します。 |
プリミティブは、実行時スケールを介した動的な量子化をサポートします。ユーザーは、プリミティブ記述子の作成時にスケールとゼロポイント属性を設定できます。ユーザーは、実行時に引数 DNNL_ARG_ATTR_SCALES および DNNL_ARG_ATTR_ZERO_POINTS を使用して、追加の入力メモリー・オブジェクトとしてスケールとゼロポイントを設定する必要があります (詳細は「量子化」 (英語) の節で説明します)。
注: ライブラリーは、トレーニングで post-ops の使用を妨げるものではありませんが、すべての post-ops がトレーニングに適しているわけではありません。例えば、非ゼロの負の勾配パラメーターで ReLU を post-op として使用しても、逆伝播を正しく計算するために必要な出力 workspace は作成されません。したがって、状況によってはトレーニングに個別の畳み込みプリミティブと要素ごとのプリミティブを使用する必要があります。
次の post-ops チェーンがライブラリーでサポートされる必要があります。
| 畳み込みタイプ | サポートされる post-ops シーケンス |
|---|---|
| f32 と bf16 畳み込み | eltwise、sum、sum -> eltwise |
| int8 畳み込み | eltwise、sum、sum -> eltwise、eltwise -> sum |
属性と post-ops 適用中の操作は、単精度浮動小数点データタイプで実行されます。実際のデスティネーション・データタイプへの変換は、保存の直前に行われます。
例 1
次の疑似コードについて考えてみます。
attribute attr;
attr.set_post_ops({
{ sum={scale=beta} },
{ eltwise={scale=gamma, type=tanh, alpha=ignore, beta=ignored }
});
convolution_forward(src, weights, dst, attr)
以下が導き出されます。

例 2
次の疑似コードについて考えてみます
attribute attr;
attr.set_output_scale(alpha);
attr.set_post_ops({
{ eltwise={scale=gamma, type=relu, alpha=eta, beta=ignored }
{ sum={scale=beta} },
});
convolution_forward(src, weights, dst, attr)
以下が導き出されます。

アルゴリズム
oneDNN の実装では、ユーザーが選択可能ないくつかの異なるアルゴリズムを使用して畳み込みプリミティブを実装できます。
Direct (
dnnl::algorithm::convolution_direct)。畳み込み操作は、SIMD 命令によって直接計算されます。これには、ワークスペースを必要とする暗黙的な GEMM 公式も含まれます。Winograd (
dnnl::algorithm::convolution_winograd)。このアルゴリズムは、精度の低下とメモリー操作の増加と引き換えに、畳み込みの計算の複雑性を軽減します。実装は、A. Lavin および S. GrayFast 共著の「Algorithms for Convolutional Neural Networks」(英語) に基づいています。Winograd アルゴリズムは、高いパフォーマンスをもたらしますが、特定の形状でのみ利用できます。また、int8 と f32 データタイプのみをサポートします。Auto (
dnnl::algorithm::convolution_auto)。このアルゴリズムでは、ライブラリーはテンソルの形状と利用可能な論理プロセッサー数を考慮したヒューリスティックに基づいて、最適なアルゴリズムを自動的に選択します。
API
API については、こちら (英語) をご覧ください。
法務上の注意書き
The content of this oneAPI Specification is licensed under the Creative Commons Attribution 4.0 International License (英語). Unless stated otherwise, the sample code examples in this document are released to you under the MIT license (英語).
This specification is a continuation of Intel’s decades-long history of working with standards groups and industry/academia initiatives such as The Khronos Group*, to create and define specifications in an open and fair process to achieve interoperability and interchangeability. oneAPI is intended to be an open specification and we encourage you to help us make it better. Your feedback is optional, but to enable Intel to incorporate any feedback you may provide to this specification, and to further upstream your feedback to other standards bodies, including The Khronos Group SYCL* specification, please submit your feedback under the terms and conditions below. Any contribution of your feedback to the oneAPI Specification does not prohibit you from also contributing your feedback directly to other standard bodies, including The Khronos Group under their respective submission policies.
By opening an issue, providing feedback, or otherwise contributing to the specification, you agree that Intel will be free to use, disclose, reproduce, modify, license, or otherwise distribute your feedback at its sole discretion without any obligations or restrictions of any kind, including without limitation, intellectual property rights or licensing obligations.
This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice.
© Intel Corporation. Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
