
この記事は、インテル® デベロッパー・ゾーンに公開されている「How to Use Loop Blocking to Optimize Memory Use on 32-Bit Intel® Architecture」(https://software.intel.com/en-us/articles/how-to-use-loop-blocking-to-optimize-memory-use-on-32-bit-intel-architecture) の日本語参考訳です。
課題
ループ・ブロッキングによってメモリー利用率を改善します。ループ・ブロッキングの主な目的は、できるだけ多くのキャッシュミスを排除することです。ブロッキングを適用する前の、以下のコードをご覧ください。
float A[MAX, MAX], B[MAX, MAX]
for (i=0; i< MAX; i++) {
for (j=0; j< MAX; j++) {
A[i,j] = A[i,j] + B[j, i];
}
}
解決方法
メモリー領域全体をシーケンシャルに横断するのではなく、特定のメモリー領域を小さいブロックに変換します。各ブロックは、データを最大限に再利用できるように、特定の計算に使用されるすべてのデータがキャッシュに納まる程度に小さくされます。ループ・ブロッキングは、2 次元またはそれ以上の次元におけるストリップマイニングと見なすことができます。
2 次元配列 A は、まず j (列) 方向に、その後、i (行) 方向に参照されます (列優先順)。配列 B は逆の順序で参照されます (行優先順)。メモリー配置が列優先順であると仮定します。したがって、このコードの配列 A と B のアクセスのストライドは、それぞれ、1 と MAX になります。
以下のコードは、ブロッキングを適用したループを示しています。
float A[MAX, MAX], B[MAX, MAX];
for (i=0; i< MAX; i+=block_size) {
for (j=0; j< MAX; j+=block_size) {
for (ii=i; ii<i+block_size; ii++) {
for (jj=j; jj<j+block_size; jj++) {
A[ii,jj] = A[ii,jj] + B[jj, ii];
}
}
}
}
内側のループの最初の反復では、配列 B にアクセスするたびにキャッシュミスが発生します。配列 A の 1 行のサイズ (つまり A[2, 0:MAX-1]) が十分に大きい場合、2 回目の反復が始まるまで、配列 B にアクセスするたびに必ずキャッシュミスが発生します。例えば、float 型の変数は 4 バイト、各キャッシュラインは 32 バイトであるため、最初の反復で、B[0,0] が参照されると、B[0, 0:7] を含むキャッシュラインがキャッシュに格納されます。キャッシュの容量には制限があるため、このラインは内側のループが終わりに達する前に、競合ミスのために排出されます。外側のループの次の反復では、B[0,1]. を参照すると、次のキャッシュミスが発生します。このように、配列 B の各要素が参照されるたびに、1 回のキャッシュミスが起こります。つまり、配列 B については、キャッシュ内のデータは全く再利用されていません。
キャッシュのサイズを考慮してループをブロック化すれば、この状態を避けることができます。次の図では、ループ・ブロッキング係数として block_size が選択されています。block_size が 8 である場合、各配列の変換後のブロックのサイズは 8 キャッシュラインになります (各ラインが 32 バイトに相当)。内側のループの最初の反復では、A[0, 0:7] と B[0, 0:7] がキャッシュに取り込まれます。B[0, 0:7] は、外側のループの最初の反復ですべて参照されます。したがって、B[0, 0:7] のキャッシュミスは、元のアルゴリズムでは 8 回発生していましたが、ループ・ブロッキングの最適化を適用した後のアルゴリズムでは 1 回しか発生しません。図に示すように、配列 A と配列 B は、A と B 変換後の 2 つのブロックの合計サイズがキャッシュのサイズより小さくなるように、小さな矩形のブロックに変換されます。これによって、データを最大限に再利用できます。
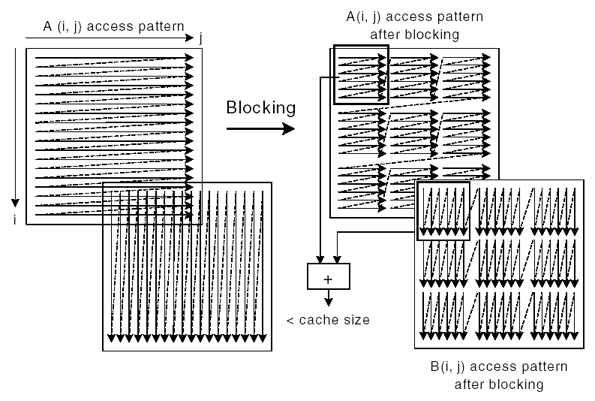
このように、ループ・ブロッキング手法を適用すると、すべての冗長なキャッシュミスを排除できます。MAX 非常に大きい場合は、ループ・ブロッキングによって、DTLB (データ・トランスレーション・ルックルックアサイド・バッファー) のミスによるペナルティーも軽減できます。また、この最適化手法は、キャッシュとメモリーのパフォーマンスを向上させるだけでなく、外部バス帯域幅の節約にもなります。
次の記事がこれに関連しています。
参考文献
インテル® 64 および IA-32 アーキテクチャー最適化リファレンス・マニュアル
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
