

この記事は、The Parallel Universe Magazine 50 号に掲載されている「Deep Learning Model Optimizations Made Easier」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

ディープラーニングの AI モデルは過去 10年で大きく成長し、この急速な成長とともに計算リソース要件も急増しています。モデルが大きくなるほど、多くの計算リソースが必要となり、さまざまなメモリー階層への読み書きやシステム間でのビットの移動も多くなります。
持続可能な AI とディープラーニングの最適化が重要な理由
2020年1月、Wired は「AI Can Do Great Things – if It Doesn’t Burn the Planet (AI は素晴らしいことができる ― もし地球を燃やさないなら)」 (英語) という記事を掲載しました。最近では、MIT Technology Review が「These Simple Changes Can Make AI Research More Energy Efficient (AI 研究のエネルギー効率を改善するシンプルな変更点)」 (英語) という記事で、Allen Institute for AI、Microsoft、Hugging Face、およびいくつかの大学が提携して行っている、再生可能エネルギーが利用できる時間にワークロードを実行することで排出量を削減する方法を理解する取り組みについて取り上げています。私は以前、持続可能な AI について考え、従来のディープラーニング・ニューラル・ネットワークに代わるいくつかのハードウェア/ソフトウェアについて、「注目の新しい AI テクノロジー」 (英語) を執筆しました。特に持続可能性に注目したわけではありませんが、これらのテクノロジーはすべて、特定のドメインでディープラーニング・モデルと同様の問題を、より少ない計算リソースで解決できる可能性があります。
モデル最適化の素晴らしいところは、パフォーマンスを向上するだけでなく、コストや電力消費を軽減できることです。以下の手法を利用することで、興味深い問題をより速く、より安く、より持続可能な方法で解決することができます。
一般的なディープラーニングの最適化
知識蒸留
その名が示すように、知識蒸留の目的は、あるモデルから機能を取り出し、それを別のモデルに移行することです。ある問題に対する解決策であるモデルを活用することで、同じタスクを実行できる、それほど複雑でない類似のモデルを作成できます。もちろん、蒸留を成功させるには、より小さなモデルが同様の精度で動作する必要があります。このテーマに関する最近の多くの文献では、知識蒸留の学習モデルがどのように機能するかを説明するため、教師と生徒を例えとして使用しています。大きな教師モデルは、小さな生徒モデルのトレーニングを支援するため、応答、特徴、関係に基づく知識という 3 つの異なる方法を使用します (図 1)。
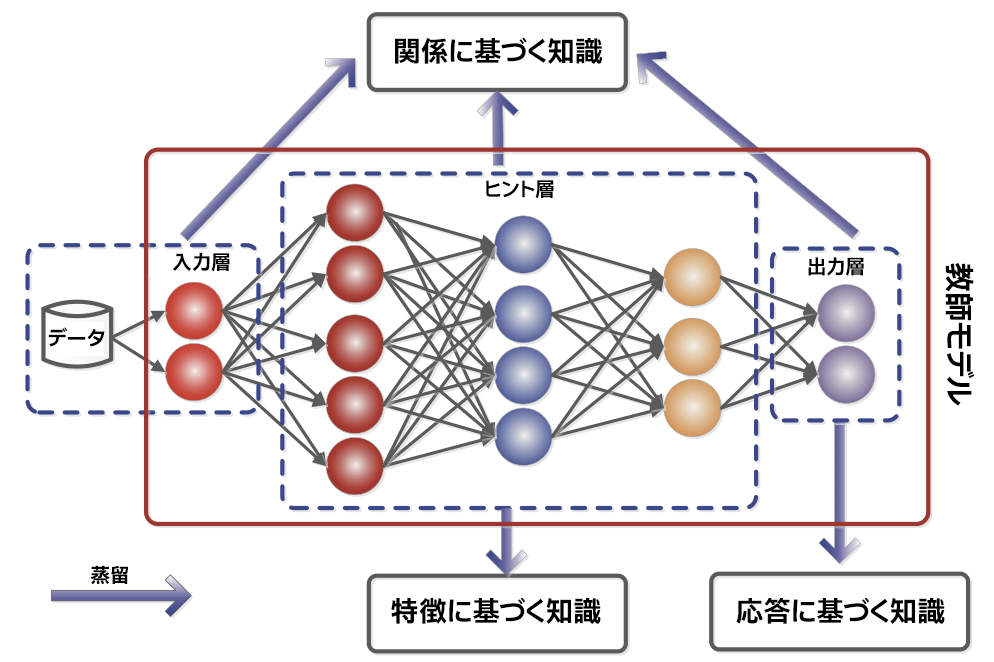
図 1. 知識はどこから来るのか? (出典: Knowledge Distillation: A Survey (英語))
応答に基づく知識は、教師モデルの出力を見て生徒モデルをトレーニングするのに役立ちます。これは、より小さなモデルを作成する最も一般的な方法です。大きなモデルの出力から、同じまたは類似の入力に基づく小さなモデルで同じ出力の動作を得ようとします。
特徴に基づく知識は、中間層に教師モデルの振る舞いを模倣させることで、生徒モデルのトレーニングを支援します。モデルの中間特徴の活性化を捉えることは容易とは限らないため、困難な場合もあります。しかし、この分野では中間特徴の振る舞いを捉えるさまざまな取り組みが行われており、特徴に基づく知識蒸留を可能にしています。
関係に基づく知識の伝達は、教師ネットワークでは、ネットワークの著しく異なる部分の出力が連携して出力を促進する可能性があるという考えに基づいています。これは、トレーニングを支援するアルゴリズムを定義するのに直感的とは言えませんが、基本的な考え方は、一般に特徴マップとして知られているノードのさまざまなグループを受け取り、親の特徴マップと同様の出力を提供するように生徒ノードをトレーニングします。
これら 3 つの手法を組み合わせることで、非常に大きなモデルをより小さな表現に移行できることが示されています。その中で最も有名な DistilBERT (英語) は、「BERT と比較して 97% の言語理解度を維持しながら、40% 小さいモデルで 60% の高速化」を実現できます。
