

この記事は、The Parallel Universe Magazine 50 号に掲載されている「Maintain Performant AI in Production」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

マシンラーニング (ML) アプリケーションを研究開発環境から運用環境に移行する際に、MLOps* は重要なコンポーネントでありながら見落とされがちです。この課題には、通常、ケースバイケースで取り組むのがベストです。この記事では、オープンソースのツールを使ってクラウド上に MLOps* 環境を構築し、ハイパフォーマンスなモデルの開発と展開を確実に行う一般的なブループリントを提示します (図 1)。ML コンポーネントのバックボーンとして、インテル® AI アナリティクス・ツールキット、特にインテル® ディストリビューションの Python* と PyTorch* 向けインテル® エクステンションを活用して、トレーニングと推論のパフォーマンスを向上します。この記事を読むことで、モデルの実験、管理、展開を高速に行う仕組みを、サーバーレスのクラウド環境で自由に使えるようになります。
図 1. 本記事で紹介する MLOps* ブループリントを利用したソリューションのサーバーサイド、運用サイド、クライアント・サイドの各コンポーネントの役割を担う各種ツール。ここでは、Docker*、GitHub*、およびフロントエンド・コンポーネントは取り上げません。
MLOps *—モデルの目標パフォーマンス
MLOps* は、ML と DevOps の俊敏性と回復力を結びつけ、ML アセットを CI/CD パイプラインに関連付けて、運用環境への安定した展開を実現します。これにより、モデルの鮮度とドリフトの懸念に対応した、統一されたリリースプロセスを構築します。適切な MLOps* パイプラインがなければ、ML アプリケーション・エンジニアは高品質の ML アセットを事業部門に提供できず、研究開発部門の中で大きな科学実験を行っているだけになってしまいます。
MLOps* への投資が進まない主な理由は、モデル/データドリフトの影響と、それが運用環境のアプリケーションにどのような影響を与えるかについての理解が不十分であることに起因しています。モデルドリフトとは、データの変化や入力変数と出力変数の関係によって、モデルのパフォーマンスが低下することを指します。データドリフトはモデルドリフトの一種で、独立変数の性質が変化するものです。データドリフトの例として、季節性によるデータの変化、消費者の嗜好の変化、新製品の追加などが挙げられます。確立された MLOps* パイプラインは、データ環境に最適なモデルを展開することで、これらの影響を軽減できます。目標は、運用環境で常に最もパフォーマンスの高いモデルを導入することです。
MLOps* ソリューション—MLflow*
MLflow* は、オープンソースの ML ライフサイクル管理プラットフォームです (図 2)。MLflow* は、クラウド上で動作するあらゆる ML ライブラリーと連携可能で、ビッグデータのワークフローにも容易に対応できる拡張性を備えています。MLflow* は 4 つの部分から構成されています。
- MLflow* Tracking は、モデルのトレーニング・プロセスのコード、データ、設定、結果を記録し、照会できるようにします。
- MLflow* Projects は、データ・サイエンス・コードをパッケージ化して再展開することで、あらゆるプラットフォームで再現性を確保します。
- MLflow* Models は、さまざまな環境にモデルを容易に展開するための API です。
- MLflow* Model Registry は、中央のリポジトリーにモデルを保存し、アノテーションを付け、管理できるようにします。
この記事では、チーム全体で利用可能なパスワードで保護された MLflow* サーバーをセットアップする方法を説明します。
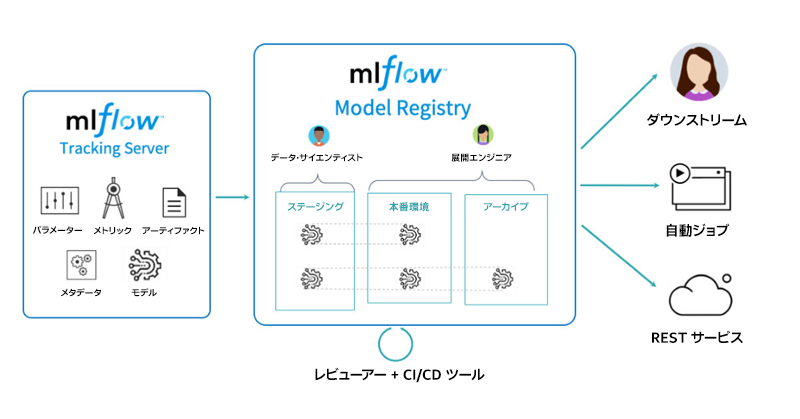
図 2. MLflow* のトラッキングとレジストリー・コンポーネント (出典: Databricks)
