
この記事は、The Parallel Universe Magazine 48 号に掲載されている「Optimize Artificial Intelligence Applications」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

データ・サイエンティストは、AI アプリケーションのパフォーマンスを向上させる方法を常に探しています。純正のパッケージではなく、最適化されたマシンラーニング・ソフトウェアを使用することは、これを実現する簡単な方法です。SigOpt (英語) のような AutoML ベースのプラットフォームを使用してモデルのハイパーパラメーターをチューニングするのもその 1 つです。ここでは、Kaggle の PLAsTiCC Classification Challenge (英語) を使用して、パフォーマンスの可能性について説明します。
PLAsTiCC は、等級の異なる天体を分類するオープン・データ・チャレンジです。チリ北部に設置される大型可視光赤外線望遠鏡による観測に備え、シミュレーションされた天文時系列データを使用します。このチャレンジでは、各天体が 14 クラスの天文フィルターのいずれかに属する確率を、小さなトレーニング・セット (140 万行) から非常に大きなテストセット (1 億 8,900 万行) へとスケーリングして決定します。
このコードは 3 つのフェーズに分けられます。
- Readcsv: CSV 形式のトレーニング・データとテストデータ、およびそれに対応するメタデータを pandas* のデータフレームに読み込みます。
- ETL: トレーニング・アルゴリズムに入力するデータフレームを操作、変換、処理します。
- ML: XGBoost ライブラリーのヒストグラム・ツリー法を使用して分類モデルをトレーニングします。モデルは交差検証され、トレーニング済みモデルは膨大なテストセット内のオブジェクトの分類に使用されます。
下図は、これらの各フェーズで使用される純正および最適化されたソフトウェアと、ハイパーパラメーターのチューニングに使用する SigOpt を示したものです。

インテル® ディストリビューションの Modin (英語) は、Readcsv と ETL のパフォーマンスを向上させるために使用されます。この並列分散データフレーム・ライブラリーは、pandas* API を使用します。1 行のコードを変更するだけで、データフレーム操作のパフォーマンスを大幅に向上できます。PLAsTiCC ML のパフォーマンスを向上させるため、インテル® アーキテクチャー向けに最適化された XGBoost パッケージがメインブランチにアップストリームされています。これは、XGBoost の最新バージョン (英語) をインストールすると利用できます (「Distributed XGBoost with Modin on Ray (Ray 上での Modin を使用した分散 XGBoost)」 (英語) を参照してください)。
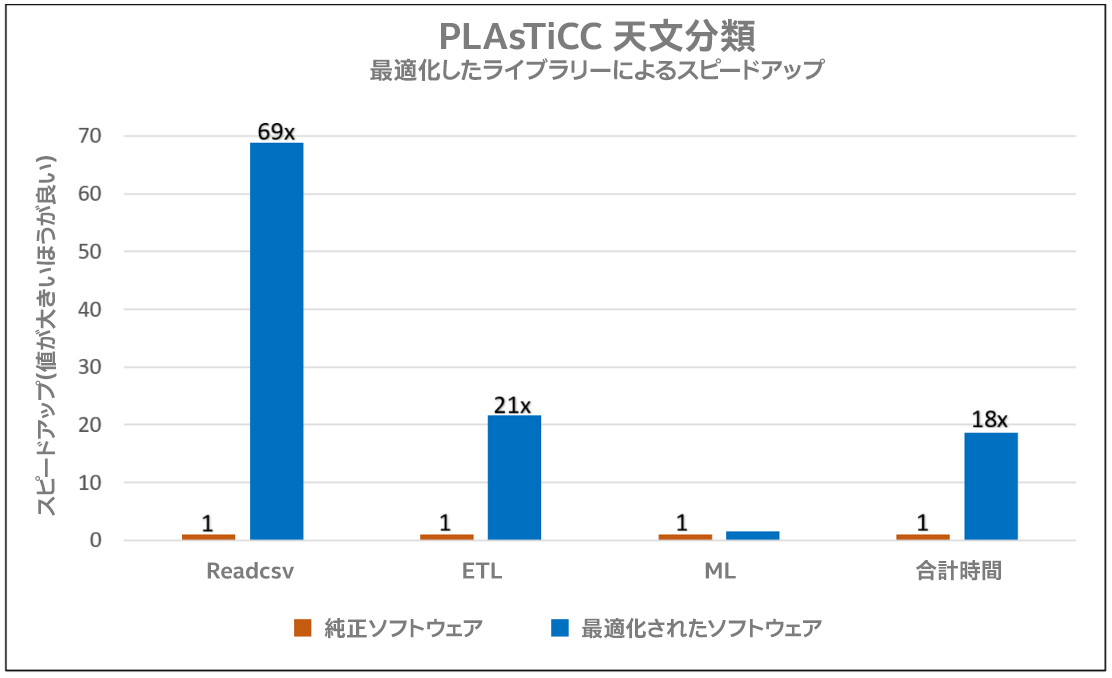
以下の棒グラフは、PLAsTiCC の各フェーズにおいて、最適化されたソフトウェア・スタック(青色で表示) を使用した場合、純正ソフトウェア(オレンジ色で表示) よりも高速化されることを示しています。最適化されたソフトウェアを使用することで、エンドツーエンドで 18 倍という大幅なスピードアップを達成しています。インテル® ディストリビューションの Modin は、pandas* とは異なり、軽量かつ堅牢なデータフレームと Readcsv の操作を実行し、コア数に応じて効率良くスケーリングします。XGBoost カーネルは、インテル® アーキテクチャー上でキャッシュ効率、リモート・メモリー・レイテンシー、メモリー・アクセス・パターンを最適化し、高いプロセッサー周波数、キャッシュサイズ、キャッシュ帯域幅を最適に使用します。
マシンラーニング・モデルのハイパーパラメーターを調整することで、エンドツーエンドのワークロードのパフォーマンスをさらに向上できます。SigOpt は、これを簡単に実現するモデル開発用プラットフォームです。トレーニング実験を追跡し、トレーニングを可視化するツールを提供し、あらゆるタイプのモデルに対してハイパーパラメーターの最適化をスケーリングします。
SigOpt はモデルの最適なパラメーター値を見つけ、最適化ループの中で定義されているメトリック全体を最適化します。PLAsTiCC では、精度とタイミングのメトリックを最適化し、目的を達成するため、モデルのハイパーパラメーター (XGBoost の並列スレッド数、木の本数、学習率、最大深度、L1/L2 正規化など) を計算します。目的関数の大域的な最大値または最小値を求めるには、最小限の観測を実行する必要があり、実験回数を実験中のパラメーター数の 10~20 倍に設定すると、ほとんどの場合、収束が見られます。
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細については、www.Intel.com/PerformanceIndex (英語) を参照してください。
